 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Text-to-SQL Generation with Execution-Guided Decoding
Sep 13, 2018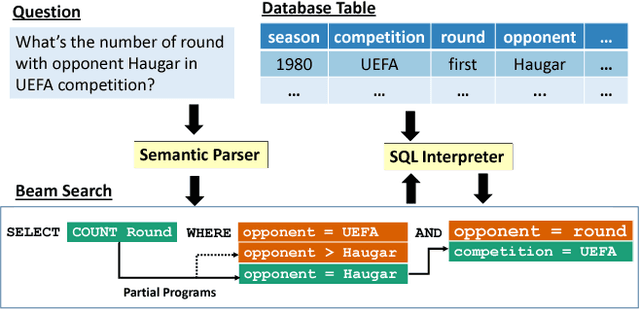
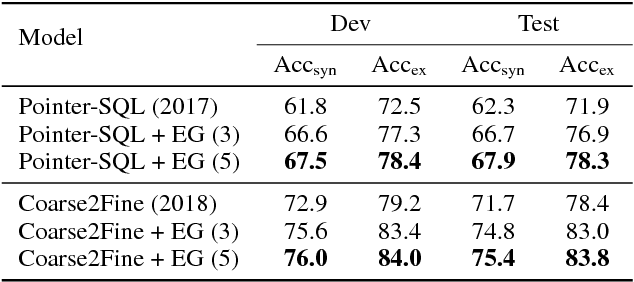
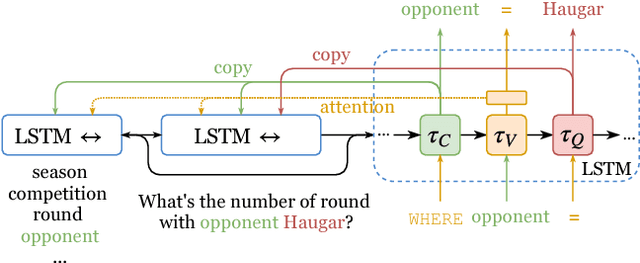
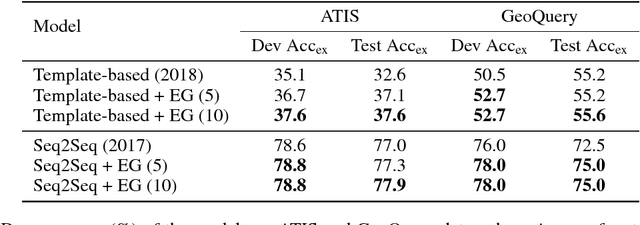
We consider the problem of neural semantic parsing, which translates natural language questions into executable SQL queries. We introduce a new mechanism, execution guidance, to leverage the semantics of SQL. It detects and excludes faulty programs during the decoding procedure by conditioning on the execution of partially generated program. The mechanism can be used with any autoregressive generative model, which we demonstrate on four state-of-the-art recurrent or template-based semantic parsing models. We demonstrate that execution guidance universally improves model performance on various text-to-SQL datasets with different scales and query complexity: WikiSQL, ATIS, and GeoQuery. As a result, we achieve new state-of-the-art execution accuracy of 83.8% on WikiSQL.
Neural-Guided Deductive Search for Real-Time Program Synthesis from Examples
Sep 09, 2018


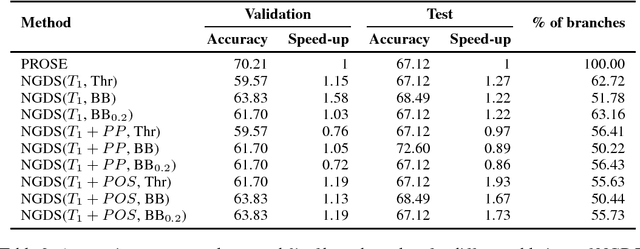
Synthesizing user-intended programs from a small number of input-output examples is a challenging problem with several important applications like spreadsheet manipulation, data wrangling and code refactoring. Existing synthesis systems either completely rely on deductive logic techniques that are extensively hand-engineered or on purely statistical models that need massive amounts of data, and in general fail to provide real-time synthesis on challenging benchmarks. In this work, we propose Neural Guided Deductive Search (NGDS), a hybrid synthesis technique that combines the best of both symbolic logic techniques and statistical models. Thus, it produces programs that satisfy the provided specifications by construction and generalize well on unseen examples, similar to data-driven systems. Our technique effectively utilizes the deductive search framework to reduce the learning problem of the neural component to a simple supervised learning setup. Further, this allows us to both train on sparingly available real-world data and still leverage powerful recurrent neural network encoders. We demonstrate the effectiveness of our method by evaluating on real-world customer scenarios by synthesizing accurate programs with up to 12x speed-up compared to state-of-the-art systems.
Generative Code Modeling with Graphs
May 22, 2018
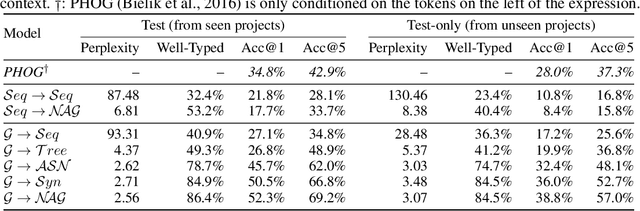
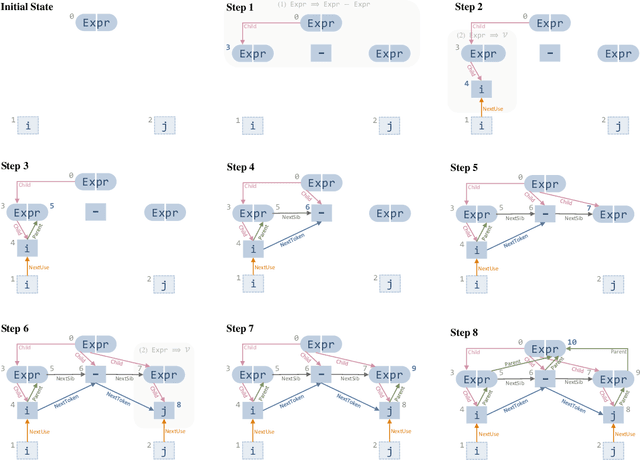

Generative models for source code are an interesting structured prediction problem, requiring to reason about both hard syntactic and semantic constraints as well as about natural, likely programs. We present a novel model for this problem that uses a graph to represent the intermediate state of the generated output. The generative procedure interleaves grammar-driven expansion steps with graph augmentation and neural message passing steps. An experimental evaluation shows that our new model can generate semantically meaningful expressions, outperforming a range of strong baselines.
FlashProfile: Interactive Synthesis of Syntactic Profiles
Sep 17, 2017

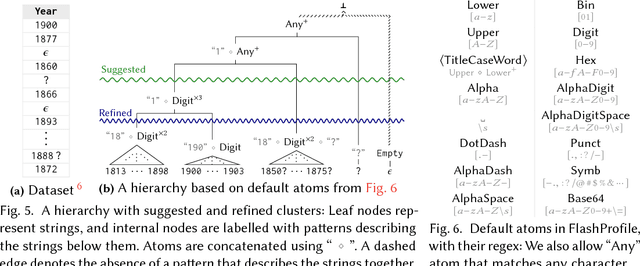
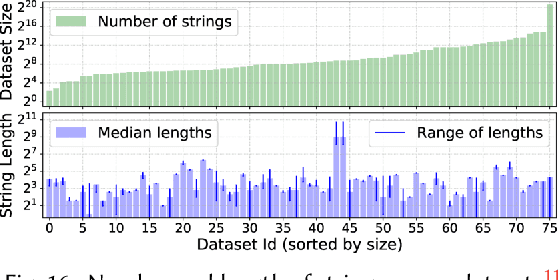
We address the problem of learning comprehensive syntactic profiles for a set of strings. Real-world datasets, typically curated from multiple sources, often contain data in various formats. Thus any data processing task is preceded by the critical step of data format identification. However, manual inspection of data to identify various formats is infeasible in standard big-data scenarios. We present a technique for generating comprehensive syntactic profiles in terms of user-defined patterns that also allows for interactive refinement. We define a syntactic profile as a set of succinct patterns that describe the entire dataset. Our approach efficiently learns such profiles, and allows refinement by exposing a desired number of patterns. Our implementation, FlashProfile, shows a median profiling time of 0.7s over 142 tasks on 74 real datasets. We also show that access to the generated data profiles allow for more accurate synthesis of programs, using fewer examples in programming-by-example workflows.
Learning Syntactic Program Transformations from Examples
Aug 31, 2016
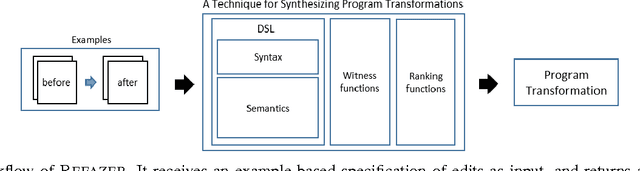
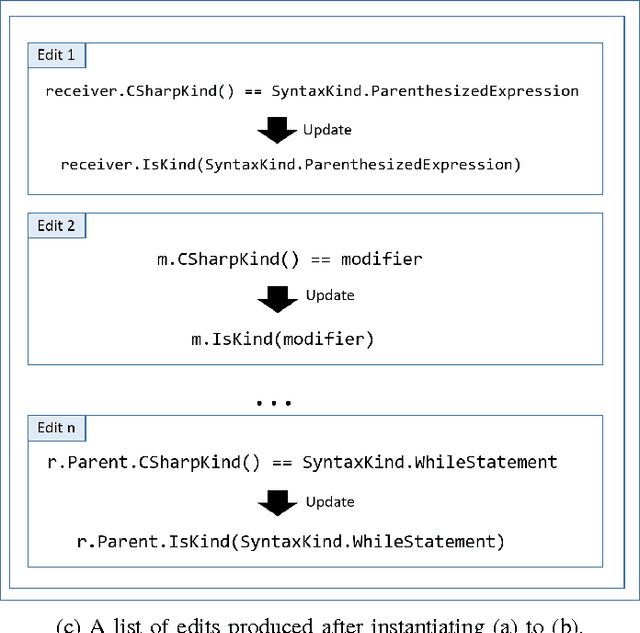
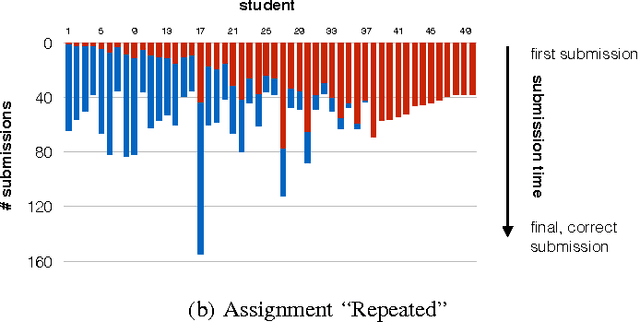
IDEs, such as Visual Studio, automate common transformations, such as Rename and Extract Method refactorings. However, extending these catalogs of transformations is complex and time-consuming. A similar phenomenon appears in intelligent tutoring systems where instructors have to write cumbersome code transformations that describe "common faults" to fix similar student submissions to programming assignments. We present REFAZER, a technique for automatically generating program transformations. REFAZER builds on the observation that code edits performed by developers can be used as examples for learning transformations. Example edits may share the same structure but involve different variables and subexpressions, which must be generalized in a transformation at the right level of abstraction. To learn transformations, REFAZER leverages state-of-the-art programming-by-example methodology using the following key components: (a) a novel domain-specific language (DSL) for describing program transformations, (b) domain-specific deductive algorithms for synthesizing transformations in the DSL, and (c) functions for ranking the synthesized transformations. We instantiate and evaluate REFAZER in two domains. First, given examples of edits used by students to fix incorrect programming assignment submissions, we learn transformations that can fix other students' submissions with similar faults. In our evaluation conducted on 4 programming tasks performed by 720 students, our technique helped to fix incorrect submissions for 87% of the students. In the second domain, we use repetitive edits applied by developers to the same project to synthesize a program transformation that applies these edits to other locations in the code. In our evaluation conducted on 59 scenarios of repetitive edits taken from 3 C# open-source projects, REFAZER learns the intended program transformation in 83% of the cases.