 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Capability of LLMs in Solving POSCOMP Questions
May 24, 2025Recent advancements in Large Language Models (LLMs) have significantly expanded the capabilities of artificial intelligence in natural language processing tasks. Despite this progress, their performance in specialized domains such as computer science remains relatively unexplored. Understanding the proficiency of LLMs in these domains is critical for evaluating their practical utility and guiding future developments. The POSCOMP, a prestigious Brazilian examination used for graduate admissions in computer science promoted by the Brazlian Computer Society (SBC), provides a challenging benchmark. This study investigates whether LLMs can match or surpass human performance on the POSCOMP exam. Four LLMs - ChatGPT-4, Gemini 1.0 Advanced, Claude 3 Sonnet, and Le Chat Mistral Large - were initially evaluated on the 2022 and 2023 POSCOMP exams. The assessments measured the models' proficiency in handling complex questions typical of the exam. LLM performance was notably better on text-based questions than on image interpretation tasks. In the 2022 exam, ChatGPT-4 led with 57 correct answers out of 69 questions, followed by Gemini 1.0 Advanced (49), Le Chat Mistral (48), and Claude 3 Sonnet (44). Similar trends were observed in the 2023 exam. ChatGPT-4 achieved the highest performance, surpassing all students who took the POSCOMP 2023 exam. LLMs, particularly ChatGPT-4, show promise in text-based tasks on the POSCOMP exam, although image interpretation remains a challenge. Given the rapid evolution of LLMs, we expanded our analysis to include more recent models - o1, Gemini 2.5 Pro, Claude 3.7 Sonnet, and o3-mini-high - evaluated on the 2022-2024 POSCOMP exams. These newer models demonstrate further improvements and consistently surpass both the average and top-performing human participants across all three years.
Learning Syntactic Program Transformations from Examples
Aug 31, 2016
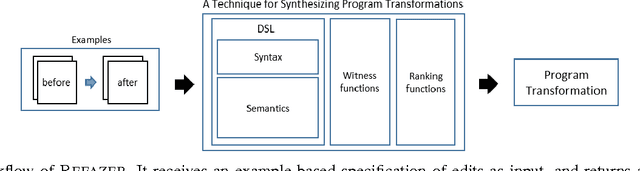
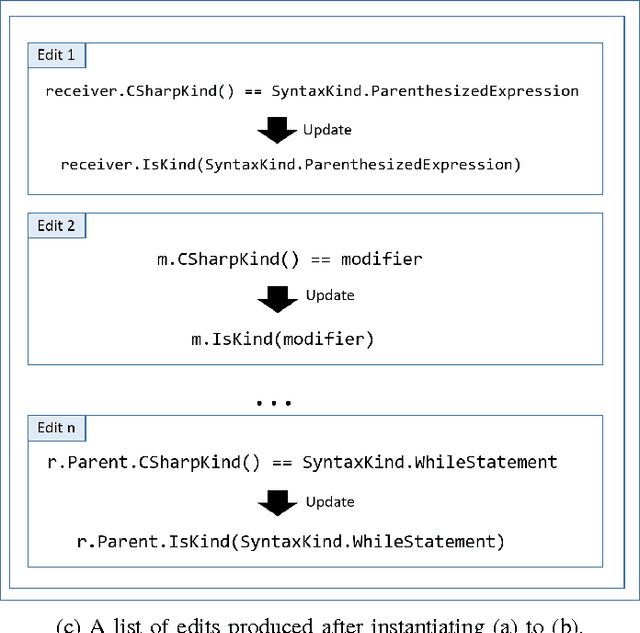
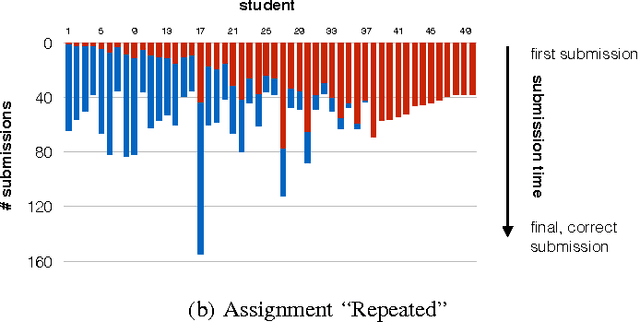
IDEs, such as Visual Studio, automate common transformations, such as Rename and Extract Method refactorings. However, extending these catalogs of transformations is complex and time-consuming. A similar phenomenon appears in intelligent tutoring systems where instructors have to write cumbersome code transformations that describe "common faults" to fix similar student submissions to programming assignments. We present REFAZER, a technique for automatically generating program transformations. REFAZER builds on the observation that code edits performed by developers can be used as examples for learning transformations. Example edits may share the same structure but involve different variables and subexpressions, which must be generalized in a transformation at the right level of abstraction. To learn transformations, REFAZER leverages state-of-the-art programming-by-example methodology using the following key components: (a) a novel domain-specific language (DSL) for describing program transformations, (b) domain-specific deductive algorithms for synthesizing transformations in the DSL, and (c) functions for ranking the synthesized transformations. We instantiate and evaluate REFAZER in two domains. First, given examples of edits used by students to fix incorrect programming assignment submissions, we learn transformations that can fix other students' submissions with similar faults. In our evaluation conducted on 4 programming tasks performed by 720 students, our technique helped to fix incorrect submissions for 87% of the students. In the second domain, we use repetitive edits applied by developers to the same project to synthesize a program transformation that applies these edits to other locations in the code. In our evaluation conducted on 59 scenarios of repetitive edits taken from 3 C# open-source projects, REFAZER learns the intended program transformation in 83% of the cases.