 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurVAE Flows: Surjections to Bridge the Gap between VAEs and Flows
Jul 06, 2020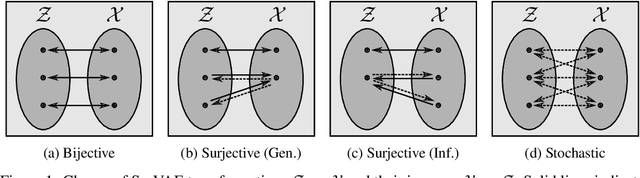


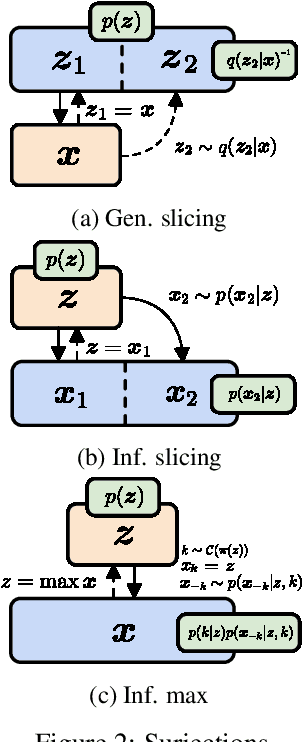
Normalizing flows and variational autoencoders are powerful generative models that can represent complicated density functions. However, they both impose constraints on the models: Normalizing flows use bijective transformations to model densities whereas VAEs learn stochastic transformations that are non-invertible and thus typically do not provide tractable estimates of the marginal likelihood. In this paper, we introduce SurVAE Flows: A modular framework of composable transformations that encompasses VAEs and normalizing flows. SurVAE Flows bridge the gap between normalizing flows and VAEs with surjective transformations, wherein the transformations are deterministic in one direction -- thereby allowing exact likelihood computation, and stochastic in the reverse direction -- hence providing a lower bound on the corresponding likelihood. We show that several recently proposed methods, including dequantization and augmented normalizing flows, can be expressed as SurVAE Flows. Finally, we introduce common operations such as the max value, the absolute value, sorting and stochastic permutation as composable layers in SurVAE Flows.
Closing the Dequantization Gap: PixelCNN as a Single-Layer Flow
Feb 06, 2020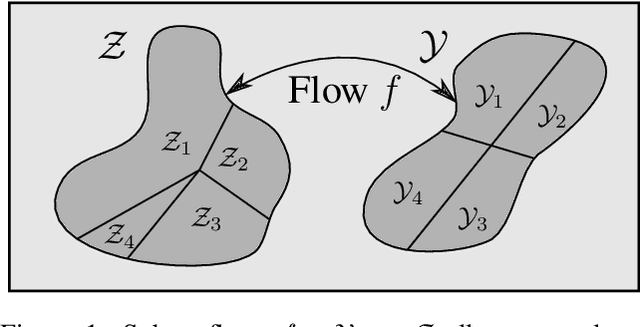
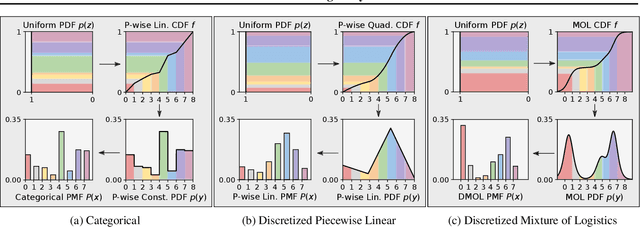
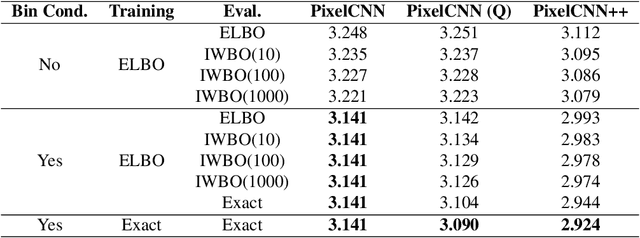
Flow models have recently made great progress at modeling quantized sensor data such as images and audio. Due to the continuous nature of flow models, dequantization is typically applied when using them for such quantized data. In this paper, we propose subset flows, a class of flows which can tractably transform subsets of the input space in one pass. As a result, they can be applied directly to quantized data without the need for dequantization. Based on this class of flows, we present a novel interpretation of several existing autoregressive models, including WaveNet and PixelCNN, as single-layer flow models defined through an invertible transformation between uniform noise and data samples. This interpretation suggests that these existing models, 1) admit a latent representation of data and 2) can be stacked in multiple flow layers. We demonstrate this by exploring the latent space of a PixelCNN and by stacking PixelCNNs in multiple flow layers.
LAVAE: Disentangling Location and Appearance
Sep 27, 2019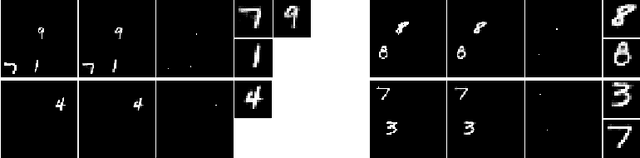



We propose a probabilistic generative model for unsupervised learning of structured, interpretable, object-based representations of visual scenes. We use amortized variational inference to train the generative model end-to-end. The learned representations of object location and appearance are fully disentangled, and objects are represented independently of each other in the latent space. Unlike previous approaches that disentangle location and appearance, ours generalizes seamlessly to scenes with many more objects than encountered in the training regime. We evaluate the proposed model on multi-MNIST and multi-dSprites data sets.
BIVA: A Very Deep Hierarchy of Latent Variables for Generative Modeling
Feb 06, 2019

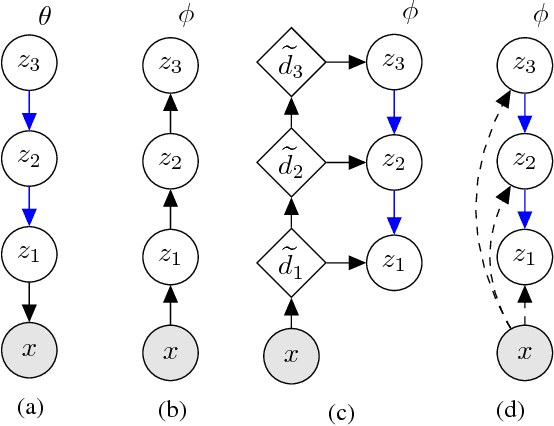

With the introduction of the variational autoencoder (VAE), probabilistic latent variable models have received renewed attention as powerful generative models. However, their performance in terms of test likelihood and quality of generated samples has been surpassed by autoregressive models without stochastic units. Furthermore, flow-based models have recently been shown to be an attractive alternative that scales well to high-dimensional data. In this paper we close the performance gap by constructing VAE models that can effectively utilize a deep hierarchy of stochastic variables and model complex covariance structures. We introduce the Bidirectional-Inference Variational Autoencoder (BIVA), characterized by a skip-connected generative model and an inference network formed by a bidirectional stochastic inference path. We show that BIVA reaches state-of-the-art test likelihoods, generates sharp and coherent natural images, and uses the hierarchy of latent variables to capture different aspects of the data distribution. We observe that BIVA, in contrast to recent results, can be used for anomaly detection. We attribute this to the hierarchy of latent variables which is able to extract high-level semantic features. Finally, we extend BIVA to semi-supervised classification tasks and show that it performs comparably to state-of-the-art results by generative adversarial networks.
Attend, Copy, Parse - End-to-end information extraction from documents
Dec 18, 2018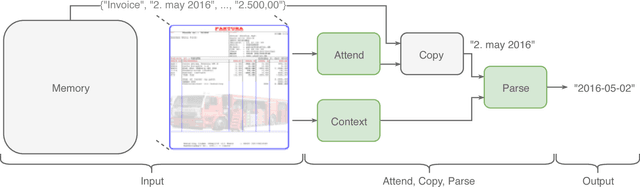
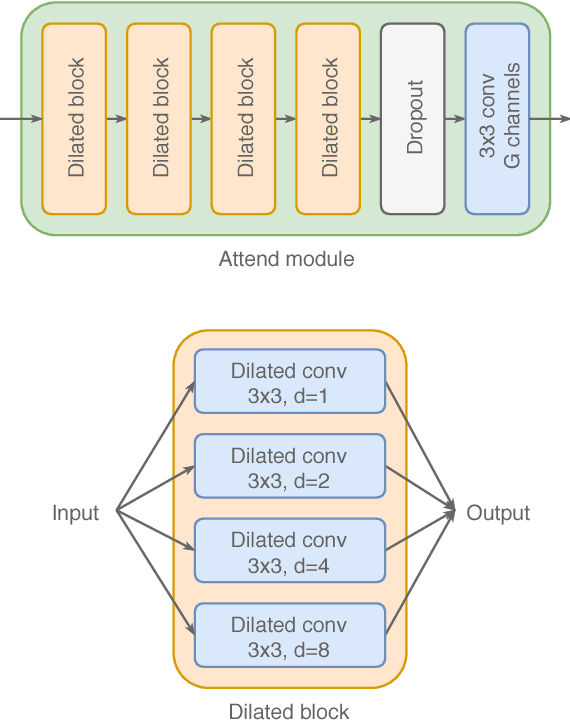
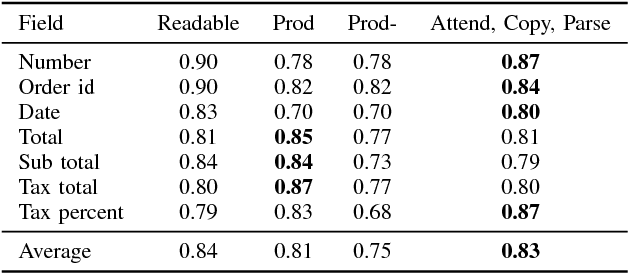
Document information extraction tasks performed by humans create data consisting of a PDF or document image input, and extracted string outputs. This end-to-end data is naturally consumed and produced when performing the task because it is valuable in and of itself. It is naturally available, at no additional cost. Unfortunately, state-of-the-art word classification methods for information extraction cannot use this data, instead requiring word-level labels which are expensive to create and consequently not available for many real life tasks. In this paper we propose the Attend, Copy, Parse architecture, a deep neural network model that can be trained directly on end-to-end data, bypassing the need for word-level labels. We evaluate the proposed architecture on a large diverse set of invoices, and outperform a state-of-the-art production system based on word classification. We believe our proposed architecture can be used on many real life information extraction tasks where word classification cannot be used due to a lack of the required word-level labels.
Recurrent Relational Networks
Oct 16, 2018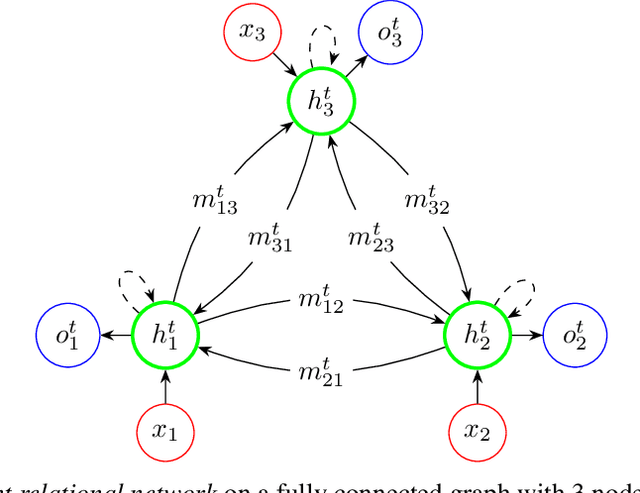
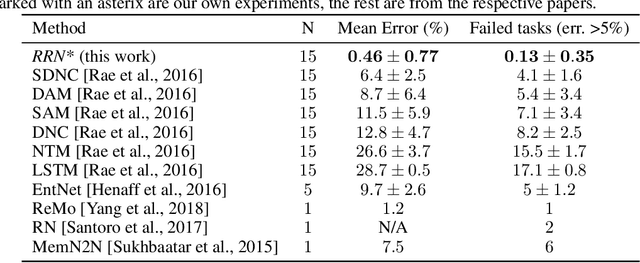
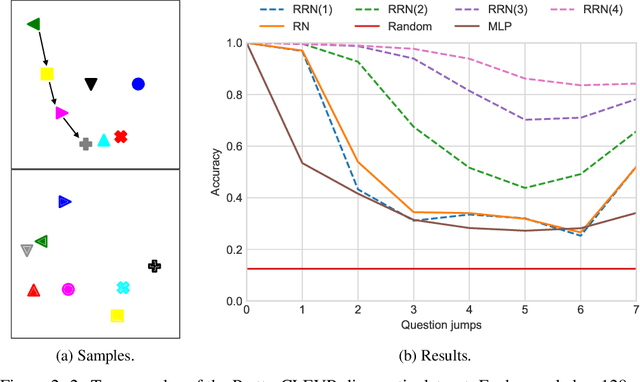

This paper is concerned with learning to solve tasks that require a chain of interdependent steps of relational inference, like answering complex questions about the relationships between objects, or solving puzzles where the smaller elements of a solution mutually constrain each other. We introduce the recurrent relational network, a general purpose module that operates on a graph representation of objects. As a generalization of Santoro et al. [2017]'s relational network, it can augment any neural network model with the capacity to do many-step relational reasoning. We achieve state of the art results on the bAbI textual question-answering dataset with the recurrent relational network, consistently solving 20/20 tasks. As bAbI is not particularly challenging from a relational reasoning point of view, we introduce Pretty-CLEVR, a new diagnostic dataset for relational reasoning. In the Pretty-CLEVR set-up, we can vary the question to control for the number of relational reasoning steps that are required to obtain the answer. Using Pretty-CLEVR, we probe the limitations of multi-layer perceptrons, relational and recurrent relational networks. Finally, we show how recurrent relational networks can learn to solve Sudoku puzzles from supervised training data, a challenging task requiring upwards of 64 steps of relational reasoning. We achieve state-of-the-art results amongst comparable methods by solving 96.6% of the hardest Sudoku puzzles.
Bayesian inference for spatio-temporal spike-and-slab priors
Dec 01, 2017
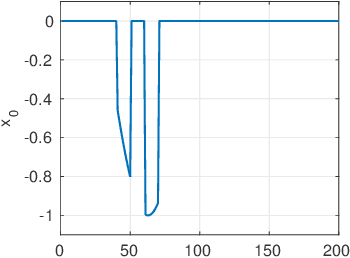
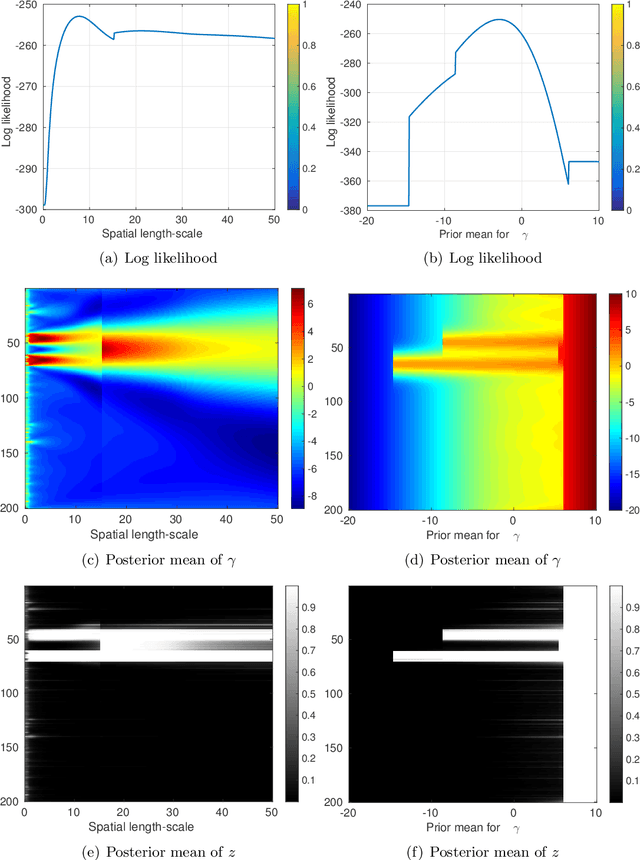
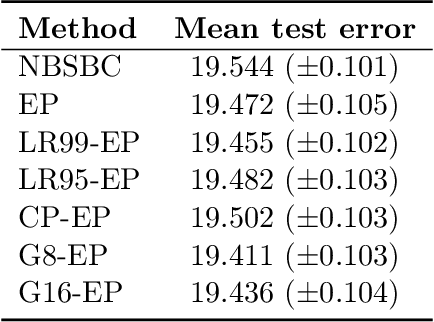
In this work, we address the problem of solving a series of underdetermined linear inverse problems subject to a sparsity constraint. We generalize the spike-and-slab prior distribution to encode a priori correlation of the support of the solution in both space and time by imposing a transformed Gaussian process on the spike-and-slab probabilities. An expectation propagation (EP) algorithm for posterior inference under the proposed model is derived. For large scale problems, the standard EP algorithm can be prohibitively slow. We therefore introduce three different approximation schemes to reduce the computational complexity. Finally, we demonstrate the proposed model using numerical experiments based on both synthetic and real data sets.
* 58 pages, 17 figures
A Disentangled Recognition and Nonlinear Dynamics Model for Unsupervised Learning
Oct 30, 2017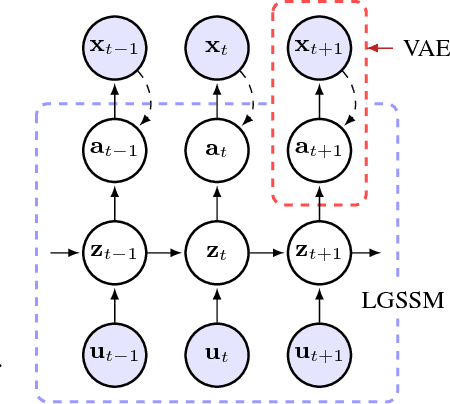
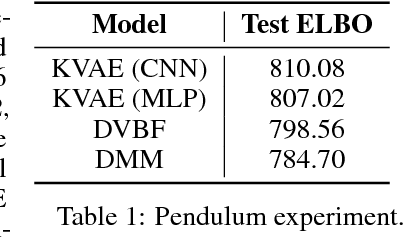
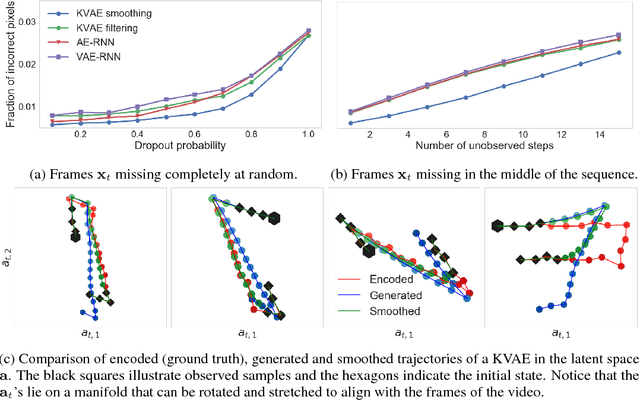
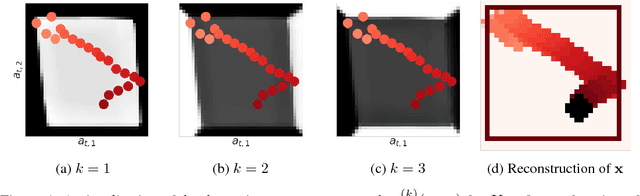
This paper takes a step towards temporal reasoning in a dynamically changing video, not in the pixel space that constitutes its frames, but in a latent space that describes the non-linear dynamics of the objects in its world. We introduce the Kalman variational auto-encoder, a framework for unsupervised learning of sequential data that disentangles two latent representations: an object's representation, coming from a recognition model, and a latent state describing its dynamics. As a result, the evolution of the world can be imagined and missing data imputed, both without the need to generate high dimensional frames at each time step. The model is trained end-to-end on videos of a variety of simulated physical systems, and outperforms competing methods in generative and missing data imputation tasks.
Hash Embeddings for Efficient Word Representations
Sep 12, 2017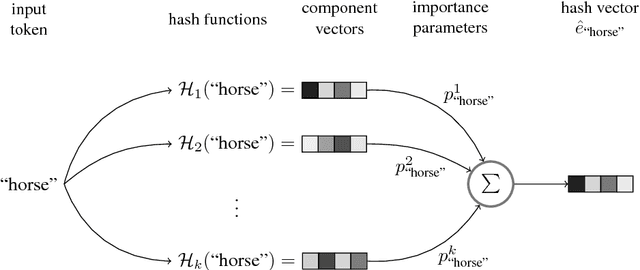
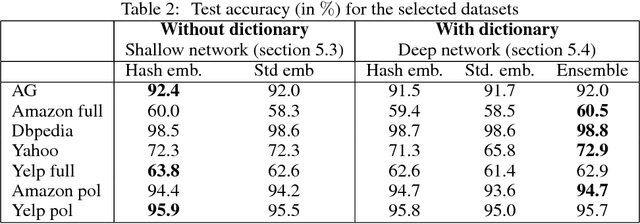
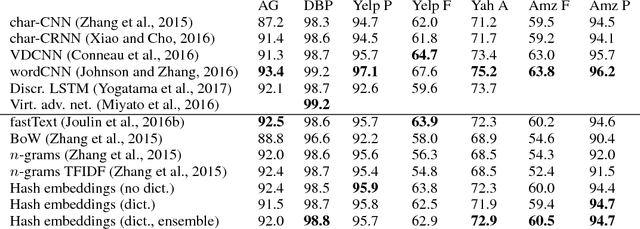
We present hash embeddings, an efficient method for representing words in a continuous vector form. A hash embedding may be seen as an interpolation between a standard word embedding and a word embedding created using a random hash function (the hashing trick). In hash embeddings each token is represented by $k$ $d$-dimensional embeddings vectors and one $k$ dimensional weight vector. The final $d$ dimensional representation of the token is the product of the two. Rather than fitting the embedding vectors for each token these are selected by the hashing trick from a shared pool of $B$ embedding vectors. Our experiments show that hash embeddings can easily deal with huge vocabularies consisting of millions of tokens. When using a hash embedding there is no need to create a dictionary before training nor to perform any kind of vocabulary pruning after training. We show that models trained using hash embeddings exhibit at least the same level of performance as models trained using regular embeddings across a wide range of tasks. Furthermore, the number of parameters needed by such an embedding is only a fraction of what is required by a regular embedding. Since standard embeddings and embeddings constructed using the hashing trick are actually just special cases of a hash embedding, hash embeddings can be considered an extension and improvement over the existing regular embedding types.
CloudScan - A configuration-free invoice analysis system using recurrent neural networks
Aug 24, 2017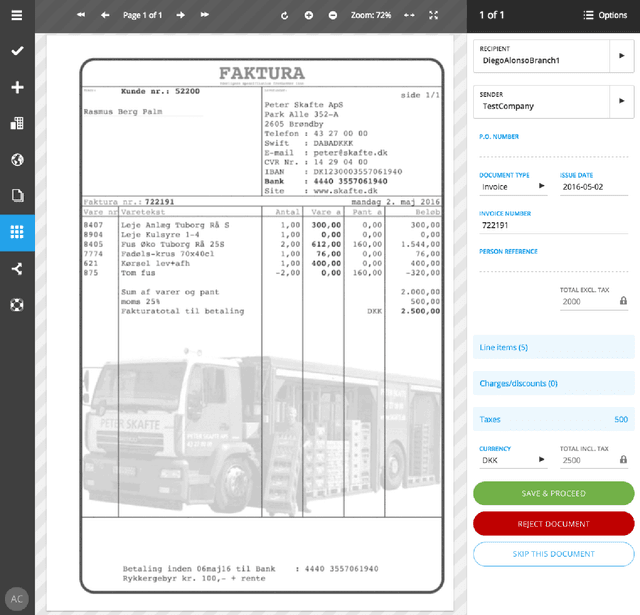

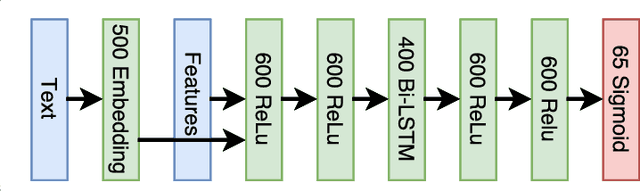
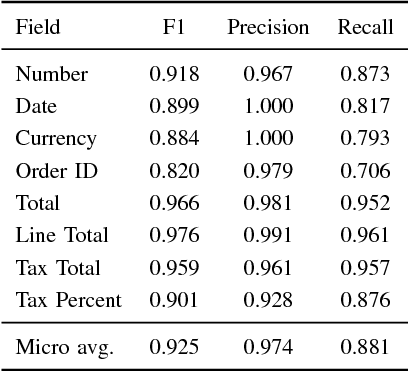
We present CloudScan; an invoice analysis system that requires zero configuration or upfront annotation. In contrast to previous work, CloudScan does not rely on templates of invoice layout, instead it learns a single global model of invoices that naturally generalizes to unseen invoice layouts. The model is trained using data automatically extracted from end-user provided feedback. This automatic training data extraction removes the requirement for users to annotate the data precisely. We describe a recurrent neural network model that can capture long range context and compare it to a baseline logistic regression model corresponding to the current CloudScan production system. We train and evaluate the system on 8 important fields using a dataset of 326,471 invoices. The recurrent neural network and baseline model achieve 0.891 and 0.887 average F1 scores respectively on seen invoice layouts. For the harder task of unseen invoice layouts, the recurrent neural network model outperforms the baseline with 0.840 average F1 compared to 0.788.