 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReXInTheWild: A Unified Benchmark for Medical Photograph Understanding
Mar 19, 2026Everyday photographs taken with ordinary cameras are already widely used in telemedicine and other online health conversations, yet no comprehensive benchmark evaluates whether vision-language models can interpret their medical content. Analyzing these images requires both fine-grained natural image understanding and domain-specific medical reasoning, a combination that challenges both general-purpose and specialized models. We introduce ReXInTheWild, a benchmark of 955 clinician-verified multiple-choice questions spanning seven clinical topics across 484 photographs sourced from the biomedical literature. When evaluated on ReXInTheWild, leading multimodal large language models show substantial performance variation: Gemini-3 achieves 78% accuracy, followed by Claude Opus 4.5 (72%) and GPT-5 (68%), while the medical specialist model MedGemma reaches only 37%. A systematic error analysis also reveals four categories of common errors, ranging from low-level geometric errors to high-level reasoning failures and requiring different mitigation strategies. ReXInTheWild provides a challenging, clinically grounded benchmark at the intersection of natural image understanding and medical reasoning. The dataset is available on HuggingFace.
ReXrank: A Public Leaderboard for AI-Powered Radiology Report Generation
Nov 22, 2024



AI-driven models have demonstrated significant potential in automating radiology report generation for chest X-rays. However, there is no standardized benchmark for objectively evaluating their performance. To address this, we present ReXrank, https://rexrank.ai, a public leaderboard and challenge for assessing AI-powered radiology report generation. Our framework incorporates ReXGradient, the largest test dataset consisting of 10,000 studies, and three public datasets (MIMIC-CXR, IU-Xray, CheXpert Plus) for report generation assessment. ReXrank employs 8 evaluation metrics and separately assesses models capable of generating only findings sections and those providing both findings and impressions sections. By providing this standardized evaluation framework, ReXrank enables meaningful comparisons of model performance and offers crucial insights into their robustness across diverse clinical settings. Beyond its current focus on chest X-rays, ReXrank's framework sets the stage for comprehensive evaluation of automated reporting across the full spectrum of medical imaging.
RadFlag: A Black-Box Hallucination Detection Method for Medical Vision Language Models
Nov 01, 2024Generating accurate radiology reports from medical images is a clinically important but challenging task. While current Vision Language Models (VLMs) show promise, they are prone to generating hallucinations, potentially compromising patient care. We introduce RadFlag, a black-box method to enhance the accuracy of radiology report generation. Our method uses a sampling-based flagging technique to find hallucinatory generations that should be removed. We first sample multiple reports at varying temperatures and then use a Large Language Model (LLM) to identify claims that are not consistently supported across samples, indicating that the model has low confidence in those claims. Using a calibrated threshold, we flag a fraction of these claims as likely hallucinations, which should undergo extra review or be automatically rejected. Our method achieves high precision when identifying both individual hallucinatory sentences and reports that contain hallucinations. As an easy-to-use, black-box system that only requires access to a model's temperature parameter, RadFlag is compatible with a wide range of radiology report generation models and has the potential to broadly improve the quality of automated radiology reporting.
ReXamine-Global: A Framework for Uncovering Inconsistencies in Radiology Report Generation Metrics
Aug 29, 2024



Given the rapidly expanding capabilities of generative AI models for radiology, there is a need for robust metrics that can accurately measure the quality of AI-generated radiology reports across diverse hospitals. We develop ReXamine-Global, a LLM-powered, multi-site framework that tests metrics across different writing styles and patient populations, exposing gaps in their generalization. First, our method tests whether a metric is undesirably sensitive to reporting style, providing different scores depending on whether AI-generated reports are stylistically similar to ground-truth reports or not. Second, our method measures whether a metric reliably agrees with experts, or whether metric and expert scores of AI-generated report quality diverge for some sites. Using 240 reports from 6 hospitals around the world, we apply ReXamine-Global to 7 established report evaluation metrics and uncover serious gaps in their generalizability. Developers can apply ReXamine-Global when designing new report evaluation metrics, ensuring their robustness across sites. Additionally, our analysis of existing metrics can guide users of those metrics towards evaluation procedures that work reliably at their sites of interest.
Direct Preference Optimization for Suppressing Hallucinated Prior Exams in Radiology Report Generation
Jun 10, 2024



Recent advances in generative vision-language models (VLMs) have exciting potential implications for AI in radiology, yet VLMs are also known to produce hallucinations, nonsensical text, and other unwanted behaviors that can waste clinicians' time and cause patient harm. Drawing on recent work on direct preference optimization (DPO), we propose a simple method for modifying the behavior of pretrained VLMs performing radiology report generation by suppressing unwanted types of generations. We apply our method to the prevention of hallucinations of prior exams, addressing a long-established problem behavior in models performing chest X-ray report generation. Across our experiments, we find that DPO fine-tuning achieves a 3.2-4.8x reduction in lines hallucinating prior exams while maintaining model performance on clinical accuracy metrics. Our work is, to the best of our knowledge, the first work to apply DPO to medical VLMs, providing a data- and compute- efficient way to suppress problem behaviors while maintaining overall clinical accuracy.
FineRadScore: A Radiology Report Line-by-Line Evaluation Technique Generating Corrections with Severity Scores
May 31, 2024



The current gold standard for evaluating generated chest x-ray (CXR) reports is through radiologist annotations. However, this process can be extremely time-consuming and costly, especially when evaluating large numbers of reports. In this work, we present FineRadScore, a Large Language Model (LLM)-based automated evaluation metric for generated CXR reports. Given a candidate report and a ground-truth report, FineRadScore gives the minimum number of line-by-line corrections required to go from the candidate to the ground-truth report. Additionally, FineRadScore provides an error severity rating with each correction and generates comments explaining why the correction was needed. We demonstrate that FineRadScore's corrections and error severity scores align with radiologist opinions. We also show that, when used to judge the quality of the report as a whole, FineRadScore aligns with radiologists as well as current state-of-the-art automated CXR evaluation metrics. Finally, we analyze FineRadScore's shortcomings to provide suggestions for future improvements.
BenchMD: A Benchmark for Modality-Agnostic Learning on Medical Images and Sensors
Apr 17, 2023



Medical data poses a daunting challenge for AI algorithms: it exists in many different modalities, experiences frequent distribution shifts, and suffers from a scarcity of examples and labels. Recent advances, including transformers and self-supervised learning, promise a more universal approach that can be applied flexibly across these diverse conditions. To measure and drive progress in this direction, we present BenchMD: a benchmark that tests how modality-agnostic methods, including architectures and training techniques (e.g. self-supervised learning, ImageNet pretraining), perform on a diverse array of clinically-relevant medical tasks. BenchMD combines 19 publicly available datasets for 7 medical modalities, including 1D sensor data, 2D images, and 3D volumetric scans. Our benchmark reflects real-world data constraints by evaluating methods across a range of dataset sizes, including challenging few-shot settings that incentivize the use of pretraining. Finally, we evaluate performance on out-of-distribution data collected at different hospitals than the training data, representing naturally-occurring distribution shifts that frequently degrade the performance of medical AI models. Our baseline results demonstrate that no modality-agnostic technique achieves strong performance across all modalities, leaving ample room for improvement on the benchmark. Code is released at https://github.com/rajpurkarlab/BenchMD .
CheXtransfer: Performance and Parameter Efficiency of ImageNet Models for Chest X-Ray Interpretation
Jan 18, 2021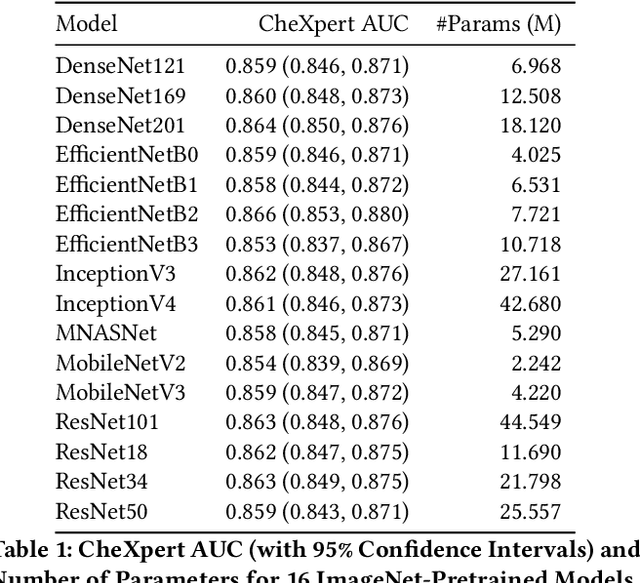
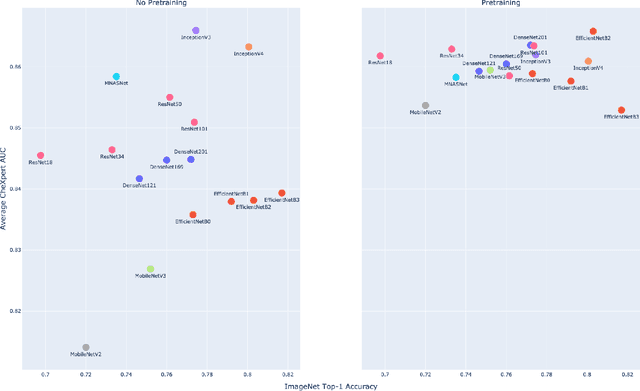
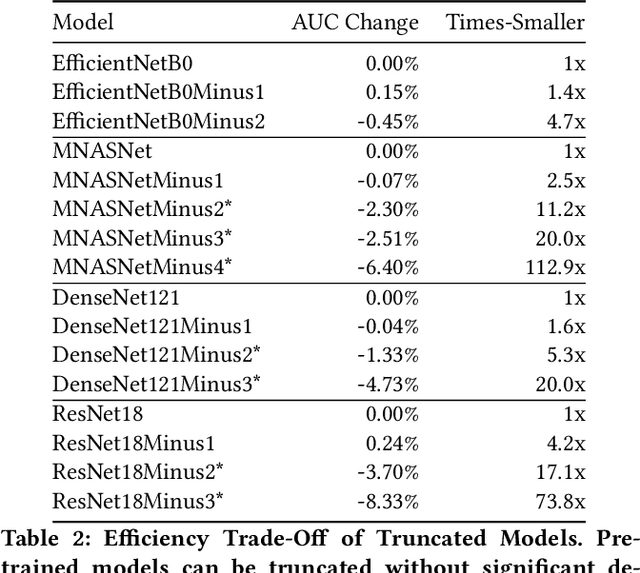
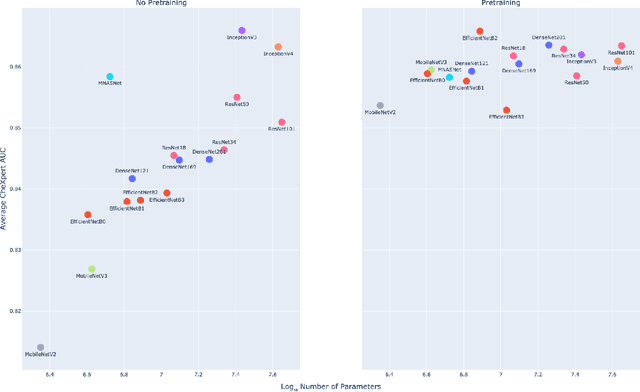
Deep learning methods for chest X-ray interpretation typically rely on pretrained models developed for ImageNet. This paradigm assumes that better ImageNet architectures perform better on chest X-ray tasks and that ImageNet-pretrained weights provide a performance boost over random initialization. In this work, we compare the transfer performance and parameter efficiency of 16 popular convolutional architectures on a large chest X-ray dataset (CheXpert) to investigate these assumptions. First, we find no relationship between ImageNet performance and CheXpert performance for both models without pretraining and models with pretraining. Second, we find that, for models without pretraining, the choice of model family influences performance more than size within a family for medical imaging tasks. Third, we observe that ImageNet pretraining yields a statistically significant boost in performance across architectures, with a higher boost for smaller architectures. Fourth, we examine whether ImageNet architectures are unnecessarily large for CheXpert by truncating final blocks from pretrained models, and find that we can make models 3.25x more parameter-efficient on average without a statistically significant drop in performance. Our work contributes new experimental evidence about the relation of ImageNet to chest x-ray interpretation performance.