 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReXInTheWild: A Unified Benchmark for Medical Photograph Understanding
Mar 19, 2026Everyday photographs taken with ordinary cameras are already widely used in telemedicine and other online health conversations, yet no comprehensive benchmark evaluates whether vision-language models can interpret their medical content. Analyzing these images requires both fine-grained natural image understanding and domain-specific medical reasoning, a combination that challenges both general-purpose and specialized models. We introduce ReXInTheWild, a benchmark of 955 clinician-verified multiple-choice questions spanning seven clinical topics across 484 photographs sourced from the biomedical literature. When evaluated on ReXInTheWild, leading multimodal large language models show substantial performance variation: Gemini-3 achieves 78% accuracy, followed by Claude Opus 4.5 (72%) and GPT-5 (68%), while the medical specialist model MedGemma reaches only 37%. A systematic error analysis also reveals four categories of common errors, ranging from low-level geometric errors to high-level reasoning failures and requiring different mitigation strategies. ReXInTheWild provides a challenging, clinically grounded benchmark at the intersection of natural image understanding and medical reasoning. The dataset is available on HuggingFace.
Machine learning-based clinical prediction modeling -- A practical guide for clinicians
Jun 23, 2020
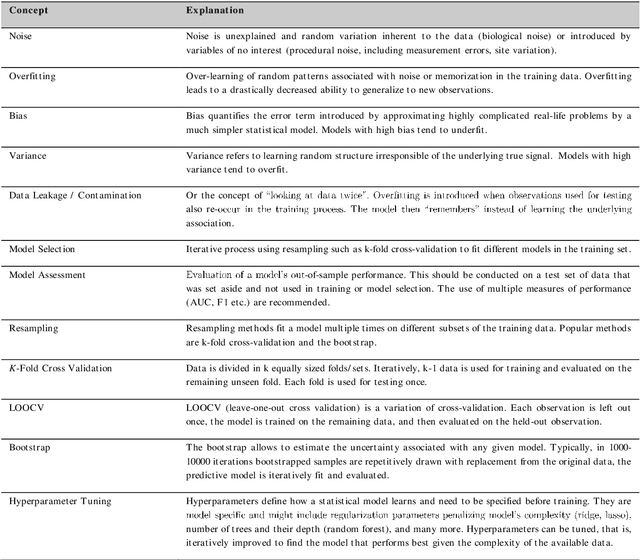

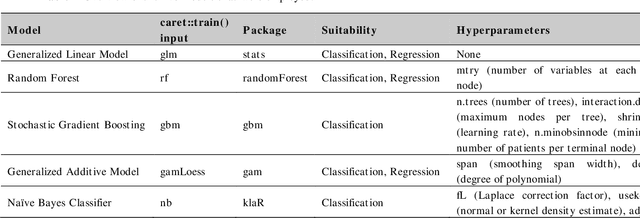
In the emerging era of big data, larger available clinical datasets and computational advances have sparked a massive interest in machine learning-based approaches. The number of manuscripts related to machine learning or artificial intelligence has exponentially increased over the past years. As analytical machine learning tools become readily available for clinicians to use, the understanding of key concepts and the awareness of analytical pitfalls are increasingly required for clinicians, investigators, reviewers and editors, who even as experts in their clinical field, sometimes find themselves insufficiently equipped to evaluate machine learning methodologies. In the first section, we provide explanations on the general principles of machine learning, as well as analytical steps required for successful machine learning-based predictive modelling - which is the focus of this series. In further sections, we review the importance of resampling, overfitting and model generalizability as well as feature reduction and selection (Part II), strategies for model evaluation, reporting and discussion of common caveats and other points of significance (Part III), as well as offer a practical guide to classification (Part IV) and regression modelling (Part V), with a complete coding pipeline. Methodological rigor and clarity as well as understanding of the underlying reasoning of the internal workings of a machine learning approach are required, otherwise predictive applications despite being strong analytical tools are not well accepted into the clinical routine. Going forward, machine learning and artificial intelligence shape and influence modern medicine across disciplines including the field of neurosurgery.