 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Hashing with Hash-Consistent Large Margin Proxy Embeddings
Jul 27, 2020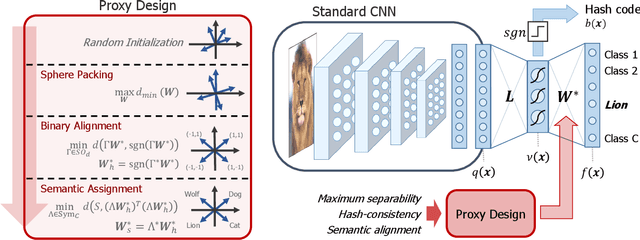
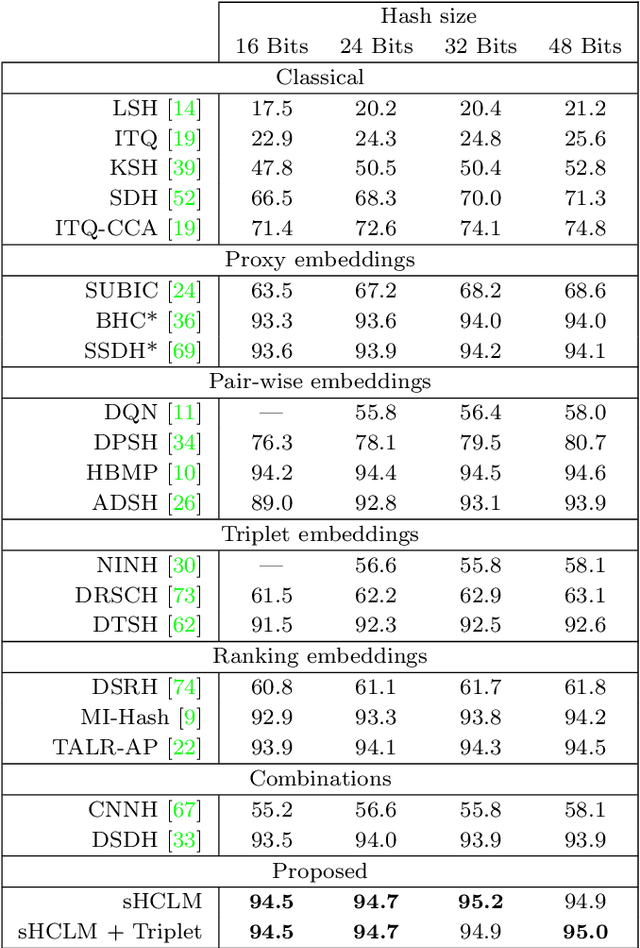
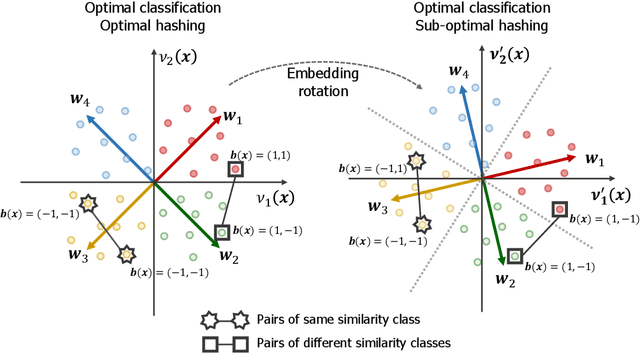
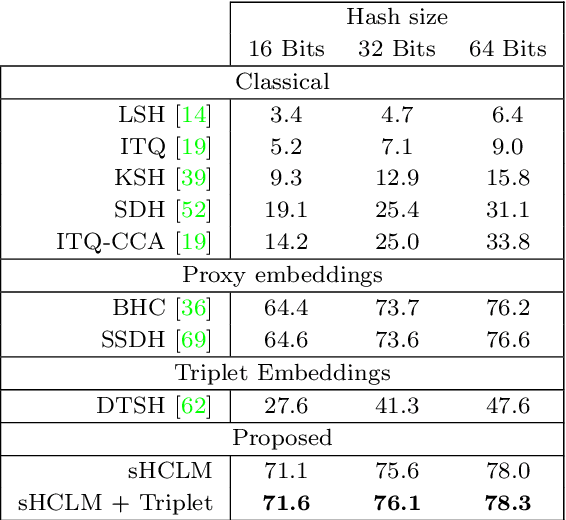
Image hash codes are produced by binarizing the embeddings of convolutional neural networks (CNN) trained for either classification or retrieval. While proxy embeddings achieve good performance on both tasks, they are non-trivial to binarize, due to a rotational ambiguity that encourages non-binary embeddings. The use of a fixed set of proxies (weights of the CNN classification layer) is proposed to eliminate this ambiguity, and a procedure to design proxy sets that are nearly optimal for both classification and hashing is introduced. The resulting hash-consistent large margin (HCLM) proxies are shown to encourage saturation of hashing units, thus guaranteeing a small binarization error, while producing highly discriminative hash-codes. A semantic extension (sHCLM), aimed to improve hashing performance in a transfer scenario, is also proposed. Extensive experiments show that sHCLM embeddings achieve significant improvements over state-of-the-art hashing procedures on several small and large datasets, both within and beyond the set of training classes.
Solving Long-tailed Recognition with Deep Realistic Taxonomic Classifier
Jul 20, 2020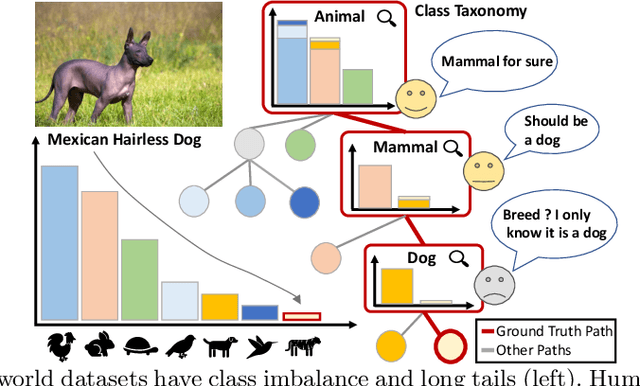
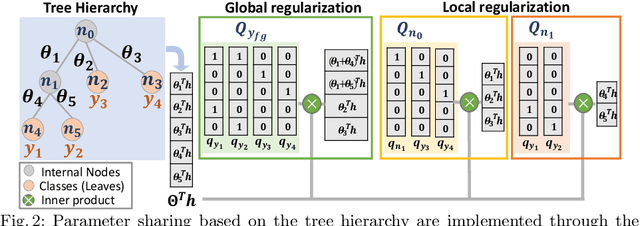
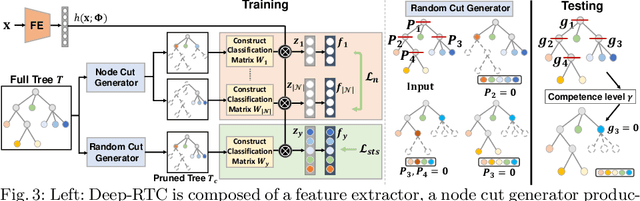
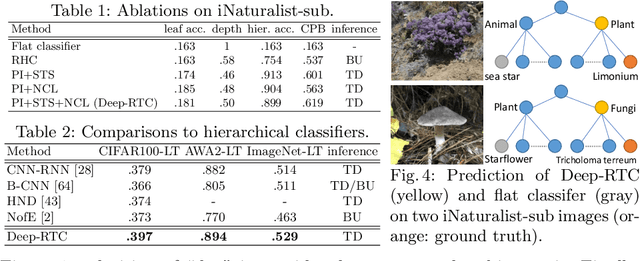
Long-tail recognition tackles the natural non-uniformly distributed data in real-world scenarios. While modern classifiers perform well on populated classes, its performance degrades significantly on tail classes. Humans, however, are less affected by this since, when confronted with uncertain examples, they simply opt to provide coarser predictions. Motivated by this, a deep realistic taxonomic classifier (Deep-RTC) is proposed as a new solution to the long-tail problem, combining realism with hierarchical predictions. The model has the option to reject classifying samples at different levels of the taxonomy, once it cannot guarantee the desired performance. Deep-RTC is implemented with a stochastic tree sampling during training to simulate all possible classification conditions at finer or coarser levels and a rejection mechanism at inference time. Experiments on the long-tailed version of four datasets, CIFAR100, AWA2, Imagenet, and iNaturalist, demonstrate that the proposed approach preserves more information on all classes with different popularity levels. Deep-RTC also outperforms the state-of-the-art methods in longtailed recognition, hierarchical classification, and learning with rejection literature using the proposed correctly predicted bits (CPB) metric.
Few-Shot Open-Set Recognition using Meta-Learning
Jun 07, 2020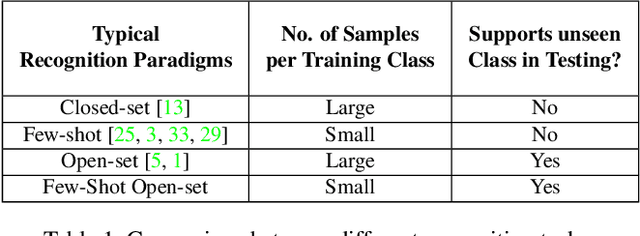
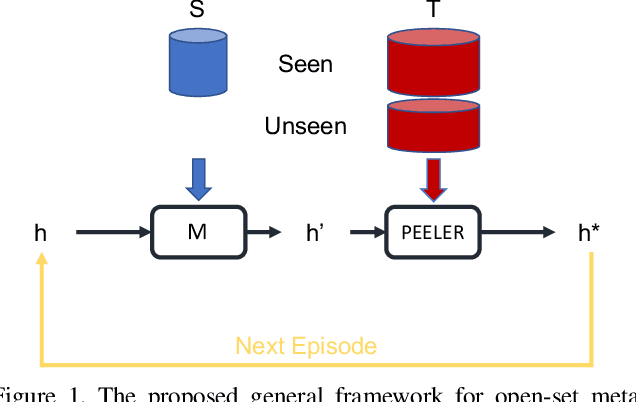
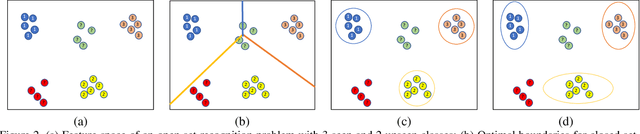
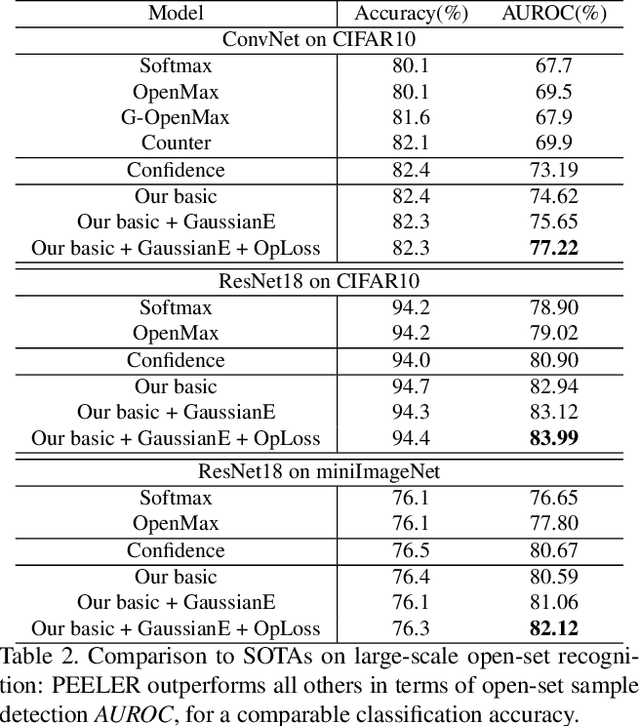
The problem of open-set recognition is considered. While previous approaches only consider this problem in the context of large-scale classifier training, we seek a unified solution for this and the low-shot classification setting. It is argued that the classic softmax classifier is a poor solution for open-set recognition, since it tends to overfit on the training classes. Randomization is then proposed as a solution to this problem. This suggests the use of meta-learning techniques, commonly used for few-shot classification, for the solution of open-set recognition. A new oPen sEt mEta LEaRning (PEELER) algorithm is then introduced. This combines the random selection of a set of novel classes per episode, a loss that maximizes the posterior entropy for examples of those classes, and a new metric learning formulation based on the Mahalanobis distance. Experimental results show that PEELER achieves state of the art open set recognition performance for both few-shot and large-scale recognition. On CIFAR and miniImageNet, it achieves substantial gains in seen/unseen class detection AUROC for a given seen-class classification accuracy.
Audio-Visual Instance Discrimination with Cross-Modal Agreement
Apr 27, 2020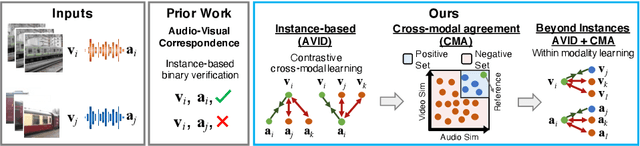

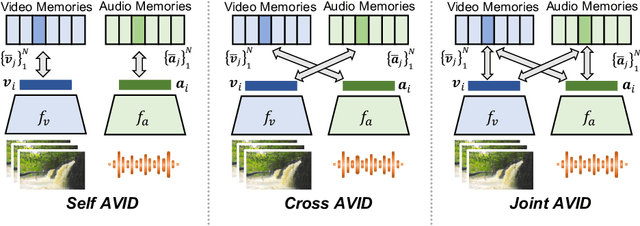
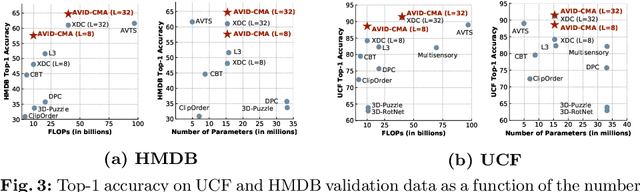
We present a self-supervised learning approach to learn audio-visual representations from video and audio. Our method uses contrastive learning for cross-modal discrimination of video from audio and vice versa. We show that optimizing for cross-modal discrimination, rather than within-modal discrimination, is important to learn good representations from video and audio. With this simple but powerful insight, our method achieves state-of-the-art results when finetuned on action recognition tasks. While recent work in contrastive learning defines positive and negative samples as individual instances, we generalize this definition by exploring cross-modal agreement. We group together multiple instances as positives by measuring their similarity in both the video and the audio feature spaces. Cross-modal agreement creates better positive and negative sets, and allows us to calibrate visual similarities by seeking within-modal discrimination of positive instances.
SCOUT: Self-aware Discriminant Counterfactual Explanations
Apr 16, 2020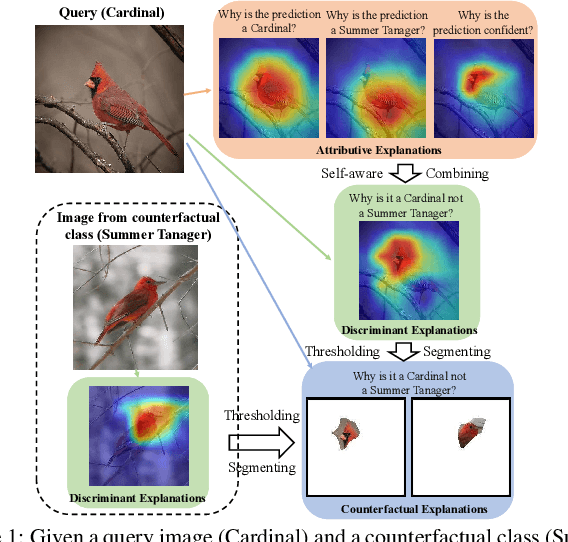
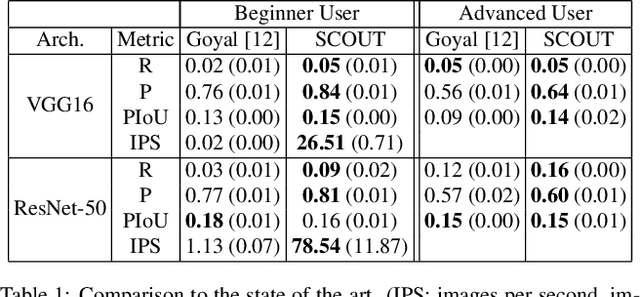
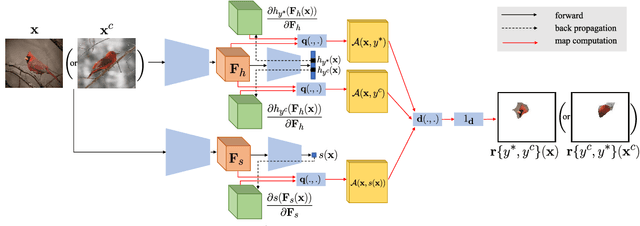
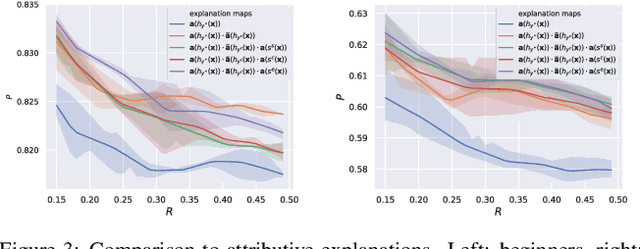
The problem of counterfactual visual explanations is considered. A new family of discriminant explanations is introduced. These produce heatmaps that attribute high scores to image regions informative of a classifier prediction but not of a counter class. They connect attributive explanations, which are based on a single heat map, to counterfactual explanations, which account for both predicted class and counter class. The latter are shown to be computable by combination of two discriminant explanations, with reversed class pairs. It is argued that self-awareness, namely the ability to produce classification confidence scores, is important for the computation of discriminant explanations, which seek to identify regions where it is easy to discriminate between prediction and counter class. This suggests the computation of discriminant explanations by the combination of three attribution maps. The resulting counterfactual explanations are optimization free and thus much faster than previous methods. To address the difficulty of their evaluation, a proxy task and set of quantitative metrics are also proposed. Experiments under this protocol show that the proposed counterfactual explanations outperform the state of the art while achieving much higher speeds, for popular networks. In a human-learning machine teaching experiment, they are also shown to improve mean student accuracy from chance level to 95\%.
Rethinking Differentiable Search for Mixed-Precision Neural Networks
Apr 13, 2020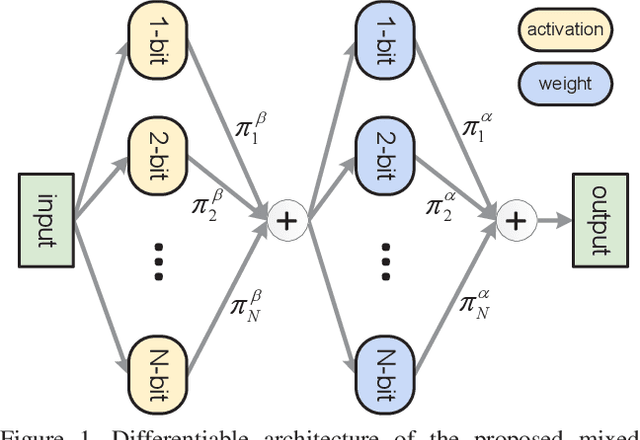
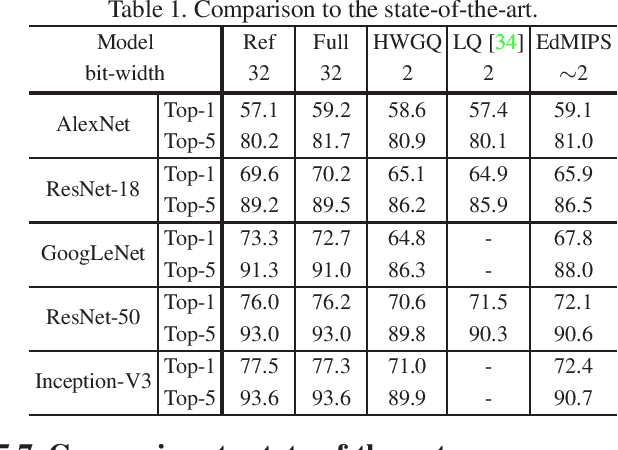
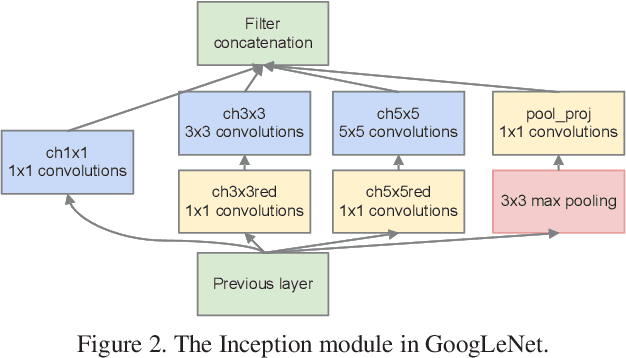
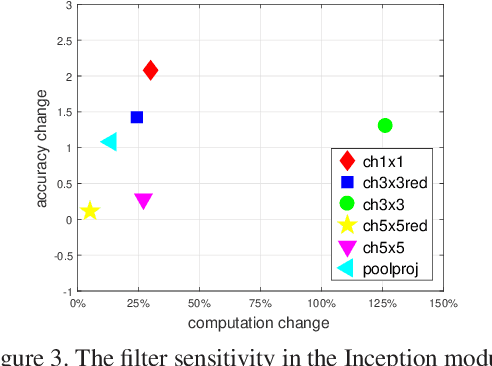
Low-precision networks, with weights and activations quantized to low bit-width, are widely used to accelerate inference on edge devices. However, current solutions are uniform, using identical bit-width for all filters. This fails to account for the different sensitivities of different filters and is suboptimal. Mixed-precision networks address this problem, by tuning the bit-width to individual filter requirements. In this work, the problem of optimal mixed-precision network search (MPS) is considered. To circumvent its difficulties of discrete search space and combinatorial optimization, a new differentiable search architecture is proposed, with several novel contributions to advance the efficiency by leveraging the unique properties of the MPS problem. The resulting Efficient differentiable MIxed-Precision network Search (EdMIPS) method is effective at finding the optimal bit allocation for multiple popular networks, and can search a large model, e.g. Inception-V3, directly on ImageNet without proxy task in a reasonable amount of time. The learned mixed-precision networks significantly outperform their uniform counterparts.
Volumetric Attention for 3D Medical Image Segmentation and Detection
Apr 04, 2020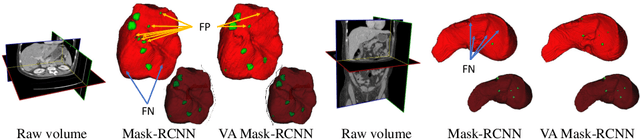
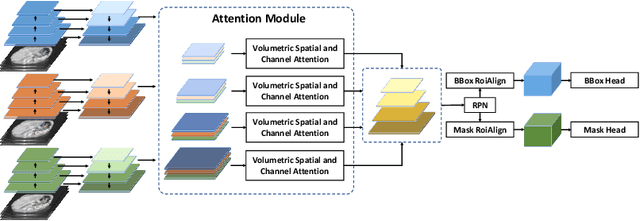
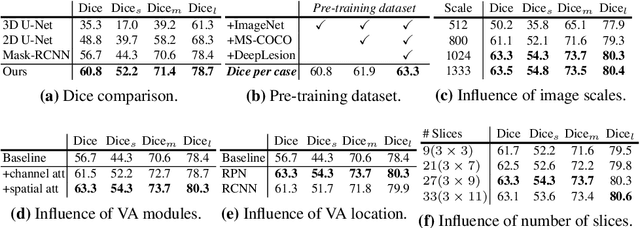
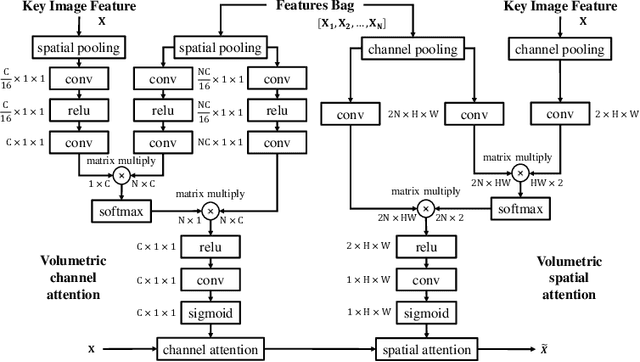
A volumetric attention(VA) module for 3D medical image segmentation and detection is proposed. VA attention is inspired by recent advances in video processing, enables 2.5D networks to leverage context information along the z direction, and allows the use of pretrained 2D detection models when training data is limited, as is often the case for medical applications. Its integration in the Mask R-CNN is shown to enable state-of-the-art performance on the Liver Tumor Segmentation (LiTS) Challenge, outperforming the previous challenge winner by 3.9 points and achieving top performance on the LiTS leader board at the time of paper submission. Detection experiments on the DeepLesion dataset also show that the addition of VA to existing object detectors enables a 69.1 sensitivity at 0.5 false positive per image, outperforming the best published results by 6.6 points.
* Accepted by MICCAI 2019
Exploit Clues from Views: Self-Supervised and Regularized Learning for Multiview Object Recognition
Mar 28, 2020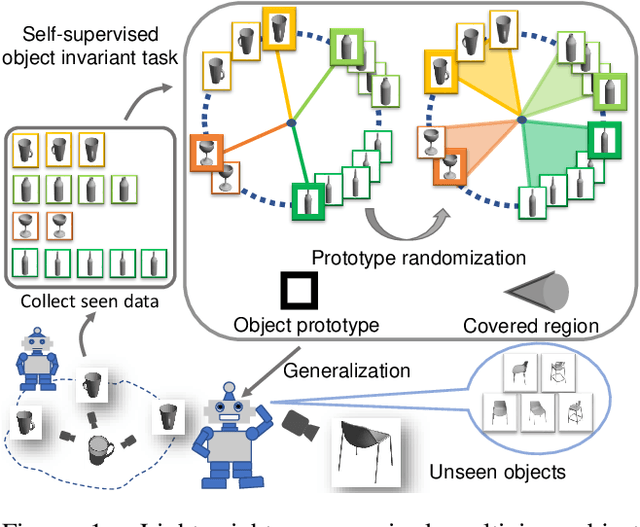
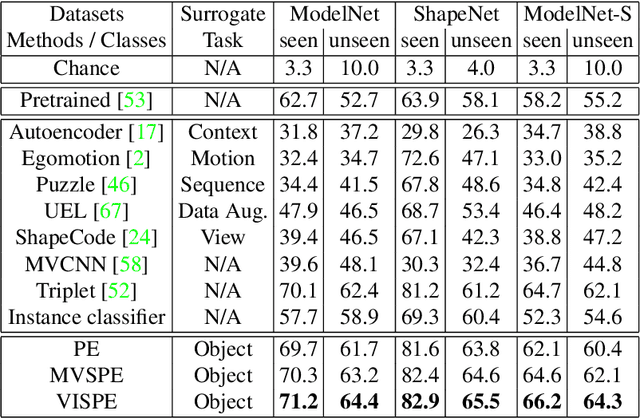
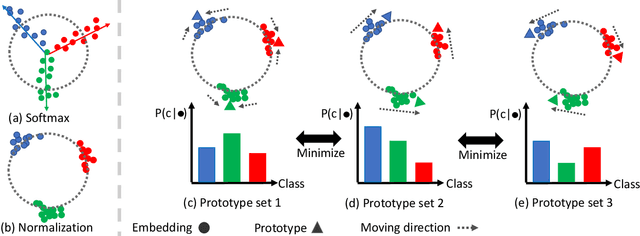
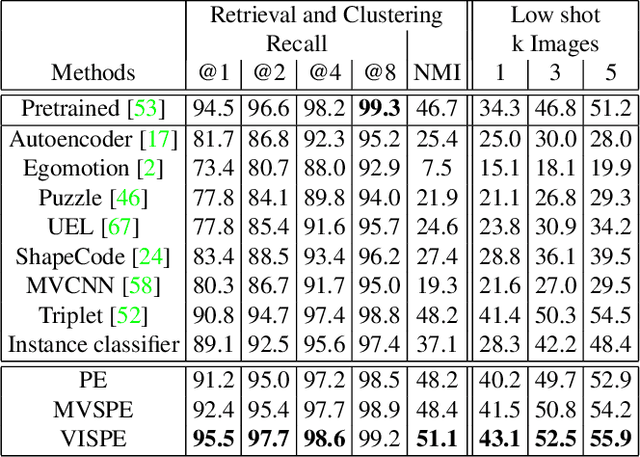
Multiview recognition has been well studied in the literature and achieves decent performance in object recognition and retrieval task. However, most previous works rely on supervised learning and some impractical underlying assumptions, such as the availability of all views in training and inference time. In this work, the problem of multiview self-supervised learning (MV-SSL) is investigated, where only image to object association is given. Given this setup, a novel surrogate task for self-supervised learning is proposed by pursuing "object invariant" representation. This is solved by randomly selecting an image feature of an object as object prototype, accompanied with multiview consistency regularization, which results in view invariant stochastic prototype embedding (VISPE). Experiments shows that the recognition and retrieval results using VISPE outperform that of other self-supervised learning methods on seen and unseen data. VISPE can also be applied to semi-supervised scenario and demonstrates robust performance with limited data available. Code is available at https://github.com/chihhuiho/VISPE
Explainable Object-induced Action Decision for Autonomous Vehicles
Mar 20, 2020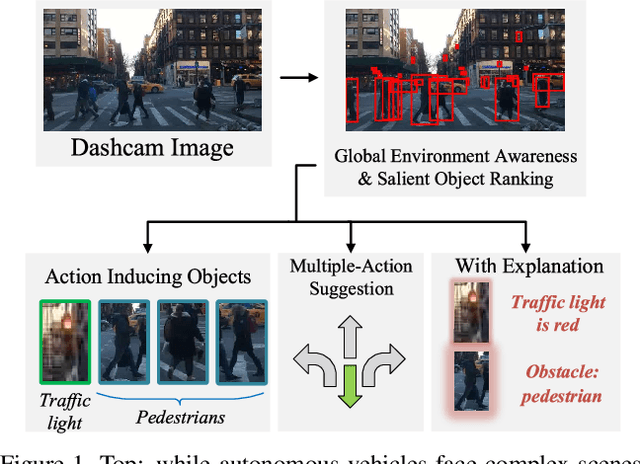
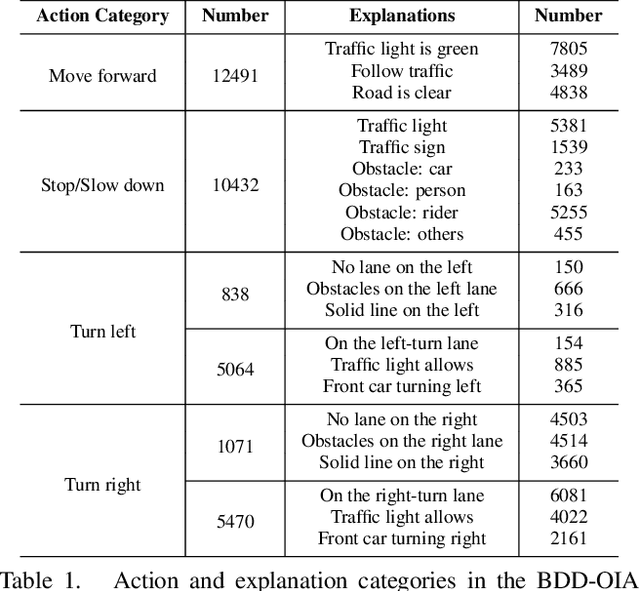
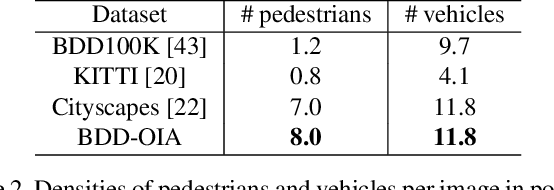

A new paradigm is proposed for autonomous driving. The new paradigm lies between the end-to-end and pipelined approaches, and is inspired by how humans solve the problem. While it relies on scene understanding, the latter only considers objects that could originate hazard. These are denoted as action-inducing, since changes in their state should trigger vehicle actions. They also define a set of explanations for these actions, which should be produced jointly with the latter. An extension of the BDD100K dataset, annotated for a set of 4 actions and 21 explanations, is proposed. A new multi-task formulation of the problem, which optimizes the accuracy of both action commands and explanations, is then introduced. A CNN architecture is finally proposed to solve this problem, by combining reasoning about action inducing objects and global scene context. Experimental results show that the requirement of explanations improves the recognition of action-inducing objects, which in turn leads to better action predictions.
Robust Deep Sensing Through Transfer Learning in Cognitive Radio
Aug 01, 2019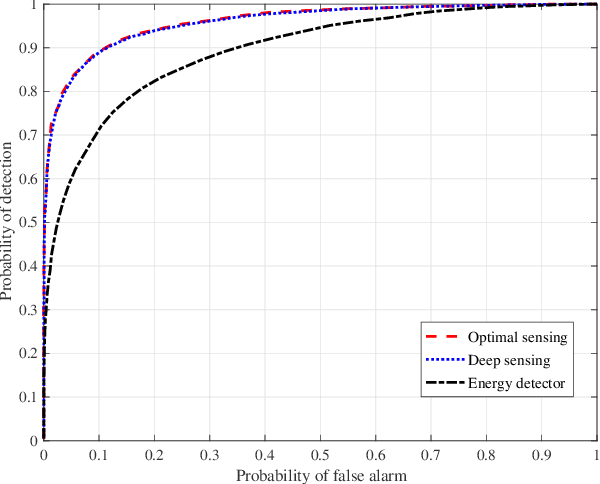
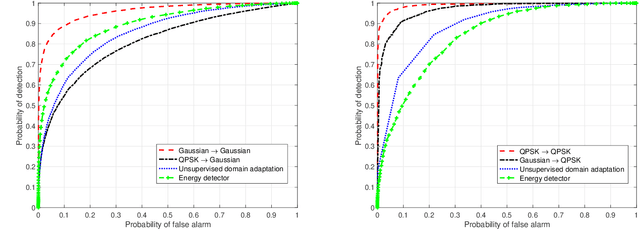
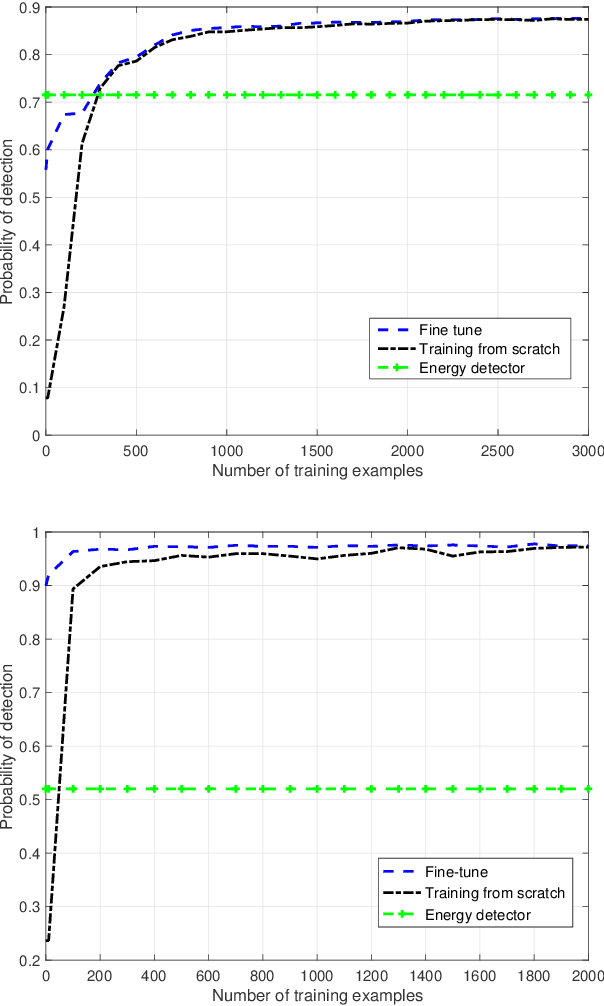
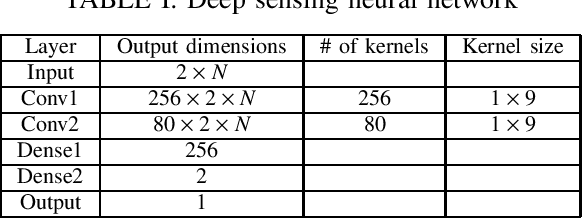
We propose a robust spectrum sensing framework based on deep learning. The received signals at the secondary user's receiver are filtered, sampled and then directly fed into a convolutional neural network. Although this deep sensing is effective when operating in the same scenario as the collected training data, the sensing performance is degraded when it is applied in a different scenario with different wireless signals and propagation. We incorporate transfer learning into the framework to improve the robustness. Results validate the effectiveness as well as the robustness of the proposed deep spectrum sensing framework.