 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Integration of Labels across Categories for Component Identification (MILCCI)
Feb 04, 2026Many fields collect large-scale temporal data through repeated measurements (trials), where each trial is labeled with a set of metadata variables spanning several categories. For example, a trial in a neuroscience study may be linked to a value from category (a): task difficulty, and category (b): animal choice. A critical challenge in time-series analysis is to understand how these labels are encoded within the multi-trial observations, and disentangle the distinct effect of each label entry across categories. Here, we present MILCCI, a novel data-driven method that i) identifies the interpretable components underlying the data, ii) captures cross-trial variability, and iii) integrates label information to understand each category's representation within the data. MILCCI extends a sparse per-trial decomposition that leverages label similarities within each category to enable subtle, label-driven cross-trial adjustments in component compositions and to distinguish the contribution of each category. MILCCI also learns each component's corresponding temporal trace, which evolves over time within each trial and varies flexibly across trials. We demonstrate MILCCI's performance through both synthetic and real-world examples, including voting patterns, online page view trends, and neuronal recordings.
Probabilistic Decomposed Linear Dynamical Systems for Robust Discovery of Latent Neural Dynamics
Aug 29, 2024Time-varying linear state-space models are powerful tools for obtaining mathematically interpretable representations of neural signals. For example, switching and decomposed models describe complex systems using latent variables that evolve according to simple locally linear dynamics. However, existing methods for latent variable estimation are not robust to dynamical noise and system nonlinearity due to noise-sensitive inference procedures and limited model formulations. This can lead to inconsistent results on signals with similar dynamics, limiting the model's ability to provide scientific insight. In this work, we address these limitations and propose a probabilistic approach to latent variable estimation in decomposed models that improves robustness against dynamical noise. Additionally, we introduce an extended latent dynamics model to improve robustness against system nonlinearities. We evaluate our approach on several synthetic dynamical systems, including an empirically-derived brain-computer interface experiment, and demonstrate more accurate latent variable inference in nonlinear systems with diverse noise conditions. Furthermore, we apply our method to a real-world clinical neurophysiology dataset, illustrating the ability to identify interpretable and coherent structure where previous models cannot.
Multiway Multislice PHATE: Visualizing Hidden Dynamics of RNNs through Training
Jun 04, 2024



Recurrent neural networks (RNNs) are a widely used tool for sequential data analysis, however, they are still often seen as black boxes of computation. Understanding the functional principles of these networks is critical to developing ideal model architectures and optimization strategies. Previous studies typically only emphasize the network representation post-training, overlooking their evolution process throughout training. Here, we present Multiway Multislice PHATE (MM-PHATE), a novel method for visualizing the evolution of RNNs' hidden states. MM-PHATE is a graph-based embedding using structured kernels across the multiple dimensions spanned by RNNs: time, training epoch, and units. We demonstrate on various datasets that MM-PHATE uniquely preserves hidden representation community structure among units and identifies information processing and compression phases during training. The embedding allows users to look under the hood of RNNs across training and provides an intuitive and comprehensive strategy to understanding the network's internal dynamics and draw conclusions, e.g., on why and how one model outperforms another or how a specific architecture might impact an RNN's learning ability.
CrEIMBO: Cross Ensemble Interactions in Multi-view Brain Observations
May 27, 2024



Modern recordings of neural activity provide diverse observations of neurons across brain areas, behavioral conditions, and subjects -- thus presenting an exciting opportunity to reveal the fundamentals of brain-wide dynamics underlying cognitive function. Current methods, however, often fail to fully harness the richness of such data as they either provide an uninterpretable representation (e.g., via "black box" deep networks) or over-simplify the model (e.g., assume stationary dynamics or analyze each session independently). Here, instead of regarding asynchronous recordings that lack alignment in neural identity or brain areas as a limitation, we exploit these diverse views of the same brain system to learn a unified model of brain dynamics. We assume that brain observations stem from the joint activity of a set of functional neural ensembles (groups of co-active neurons) that are similar in functionality across recordings, and propose to discover the ensemble and their non-stationary dynamical interactions in a new model we term CrEIMBO (Cross-Ensemble Interactions in Multi-view Brain Observations). CrEIMBO identifies the composition of the per-session neural ensembles through graph-driven dictionary learning and models the ensemble dynamics as a latent sparse time-varying decomposition of global sub-circuits, thereby capturing non-stationary dynamics. CrEIMBO identifies multiple co-active sub-circuits while maintaining representation interpretability due to sharing sub-circuits across sessions. CrEIMBO distinguishes session-specific from global (session-invariant) computations by exploring when distinct sub-circuits are active. We demonstrate CrEIMBO's ability to recover ground truth components in synthetic data and uncover meaningful brain dynamics, capturing cross-subject and inter- and intra-area variability, in high-density electrode recordings of humans performing a memory task.
LINOCS: Lookahead Inference of Networked Operators for Continuous Stability
Apr 28, 2024Identifying latent interactions within complex systems is key to unlocking deeper insights into their operational dynamics, including how their elements affect each other and contribute to the overall system behavior. For instance, in neuroscience, discovering neuron-to-neuron interactions is essential for understanding brain function; in ecology, recognizing the interactions among populations is key for understanding complex ecosystems. Such systems, often modeled as dynamical systems, typically exhibit noisy high-dimensional and non-stationary temporal behavior that renders their identification challenging. Existing dynamical system identification methods often yield operators that accurately capture short-term behavior but fail to predict long-term trends, suggesting an incomplete capture of the underlying process. Methods that consider extended forecasts (e.g., recurrent neural networks) lack explicit representations of element-wise interactions and require substantial training data, thereby failing to capture interpretable network operators. Here we introduce Lookahead-driven Inference of Networked Operators for Continuous Stability (LINOCS), a robust learning procedure for identifying hidden dynamical interactions in noisy time-series data. LINOCS integrates several multi-step predictions with adaptive weights during training to recover dynamical operators that can yield accurate long-term predictions. We demonstrate LINOCS' ability to recover the ground truth dynamical operators underlying synthetic time-series data for multiple dynamical systems models (including linear, piece-wise linear, time-changing linear systems' decomposition, and regularized linear time-varying systems) as well as its capability to produce meaningful operators with robust reconstructions through various real-world examples.
SiBBlInGS: Similarity-driven Building-Block Inference using Graphs across States
Jun 07, 2023Interpretable methods for extracting meaningful building blocks (BBs) underlying multi-dimensional time series are vital for discovering valuable insights in complex systems. Existing techniques, however, encounter limitations that restrict their applicability to real-world systems, like reliance on orthogonality assumptions, inadequate incorporation of inter- and intra-state variability, and incapability to handle sessions of varying duration. Here, we present a framework for Similarity-driven Building Block Inference using Graphs across States (SiBBlInGS). SiBBlInGS employs a graph-based dictionary learning approach for BB discovery, simultaneously considers both inter- and intra-state relationships in the data, can extract non-orthogonal components, and allows for variations in session counts and duration across states. Additionally, SiBBlInGS allows for cross-state variations in BB structure and per-trial temporal variability, can identify state-specific vs state-invariant BBs, and offers both supervised and data-driven approaches for controlling the level of BB similarity between states. We demonstrate SiBBlInGS on synthetic and real-world data to highlight its ability to provide insights into the underlying mechanisms of complex phenomena and its applicability to data in various fields.
Multi-Lingual DALL-E Storytime
Dec 22, 2022



While recent advancements in artificial intelligence (AI) language models demonstrate cutting-edge performance when working with English texts, equivalent models do not exist in other languages or do not reach the same performance level. This undesired effect of AI advancements increases the gap between access to new technology from different populations across the world. This unsought bias mainly discriminates against individuals whose English skills are less developed, e.g., non-English speakers children. Following significant advancements in AI research in recent years, OpenAI has recently presented DALL-E: a powerful tool for creating images based on English text prompts. While DALL-E is a promising tool for many applications, its decreased performance when given input in a different language, limits its audience and deepens the gap between populations. An additional limitation of the current DALL-E model is that it only allows for the creation of a few images in response to a given input prompt, rather than a series of consecutive coherent frames that tell a story or describe a process that changes over time. Here, we present an easy-to-use automatic DALL-E storytelling framework that leverages the existing DALL-E model to enable fast and coherent visualizations of non-English songs and stories, pushing the limit of the one-step-at-a-time option DALL-E currently offers. We show that our framework is able to effectively visualize stories from non-English texts and portray the changes in the plot over time. It is also able to create a narrative and maintain interpretable changes in the description across frames. Additionally, our framework offers users the ability to specify constraints on the story elements, such as a specific location or context, and to maintain a consistent style throughout the visualization.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
Decomposed Linear Dynamical Systems (dLDS) for learning the latent components of neural dynamics
Jun 07, 2022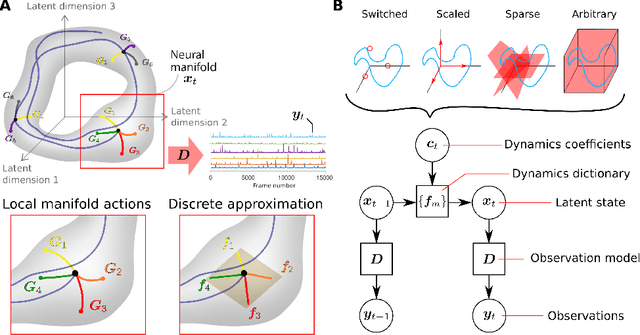

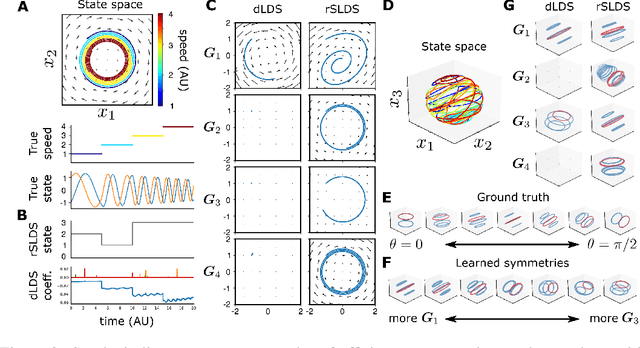
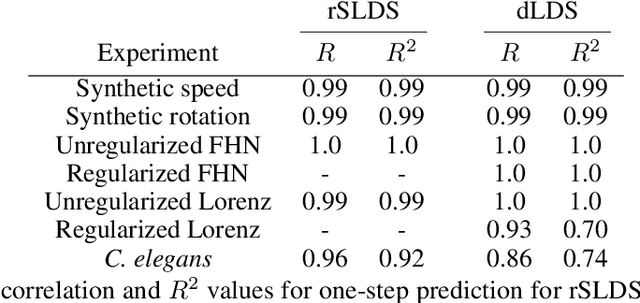
Learning interpretable representations of neural dynamics at a population level is a crucial first step to understanding how neural activity relates to perception and behavior. Models of neural dynamics often focus on either low-dimensional projections of neural activity, or on learning dynamical systems that explicitly relate to the neural state over time. We discuss how these two approaches are interrelated by considering dynamical systems as representative of flows on a low-dimensional manifold. Building on this concept, we propose a new decomposed dynamical system model that represents complex non-stationary and nonlinear dynamics of time-series data as a sparse combination of simpler, more interpretable components. The decomposed nature of the dynamics generalizes over previous switched approaches and enables modeling of overlapping and non-stationary drifts in the dynamics. We further present a dictionary learning-driven approach to model fitting, where we leverage recent results in tracking sparse vectors over time. We demonstrate that our model can learn efficient representations and smooth transitions between dynamical modes in both continuous-time and discrete-time examples. We show results on low-dimensional linear and nonlinear attractors to demonstrate that our decomposed dynamical systems model can well approximate nonlinear dynamics. Additionally, we apply our model to C. elegans data, illustrating a diversity of dynamics that is obscured when classified into discrete states.