 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Filtering for Efficient Dimensionality Reduction of Streaming Manifold Data
Jan 13, 2026Many areas in science and engineering now have access to technologies that enable the rapid collection of overwhelming data volumes. While these datasets are vital for understanding phenomena from physical to biological and social systems, the sheer magnitude of the data makes even simple storage, transmission, and basic processing highly challenging. To enable efficient and accurate execution of these data processing tasks, we require new dimensionality reduction tools that 1) do not need expensive, time-consuming training, and 2) preserve the underlying geometry of the data that has the information required to understand the measured system. Specifically, the geometry to be preserved is that induced by the fact that in many applications, streaming high-dimensional data evolves on a low-dimensional attractor manifold. Importantly, we may not know the exact structure of this manifold a priori. To solve these challenges, we present randomized filtering (RF), which leverages a specific instantiation of randomized dimensionality reduction to provably preserve non-linear manifold structure in the embedded space while remaining data-independent and computationally efficient. In this work we build on the rich theoretical promise of randomized dimensionality reduction to develop RF as a real, practical approach. We introduce novel methods, analysis, and experimental verification to illuminate the practicality of RF in diverse scientific applications, including several simulated and real-data examples that showcase the tangible benefits of RF.
LINOCS: Lookahead Inference of Networked Operators for Continuous Stability
Apr 28, 2024Identifying latent interactions within complex systems is key to unlocking deeper insights into their operational dynamics, including how their elements affect each other and contribute to the overall system behavior. For instance, in neuroscience, discovering neuron-to-neuron interactions is essential for understanding brain function; in ecology, recognizing the interactions among populations is key for understanding complex ecosystems. Such systems, often modeled as dynamical systems, typically exhibit noisy high-dimensional and non-stationary temporal behavior that renders their identification challenging. Existing dynamical system identification methods often yield operators that accurately capture short-term behavior but fail to predict long-term trends, suggesting an incomplete capture of the underlying process. Methods that consider extended forecasts (e.g., recurrent neural networks) lack explicit representations of element-wise interactions and require substantial training data, thereby failing to capture interpretable network operators. Here we introduce Lookahead-driven Inference of Networked Operators for Continuous Stability (LINOCS), a robust learning procedure for identifying hidden dynamical interactions in noisy time-series data. LINOCS integrates several multi-step predictions with adaptive weights during training to recover dynamical operators that can yield accurate long-term predictions. We demonstrate LINOCS' ability to recover the ground truth dynamical operators underlying synthetic time-series data for multiple dynamical systems models (including linear, piece-wise linear, time-changing linear systems' decomposition, and regularized linear time-varying systems) as well as its capability to produce meaningful operators with robust reconstructions through various real-world examples.
Decomposed Linear Dynamical Systems (dLDS) for learning the latent components of neural dynamics
Jun 07, 2022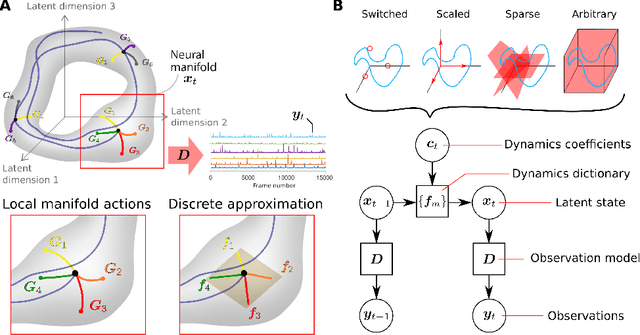

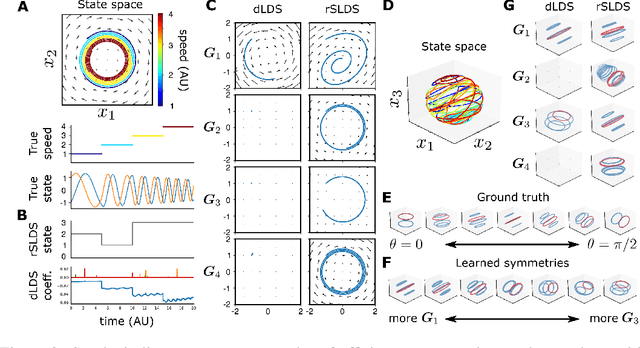
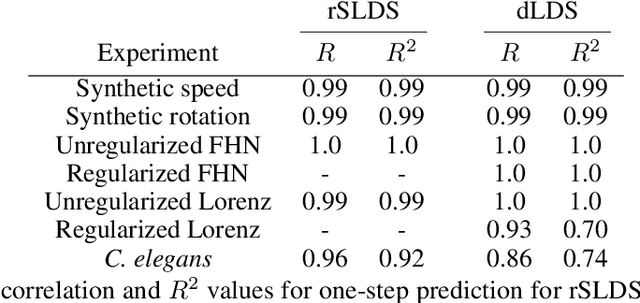
Learning interpretable representations of neural dynamics at a population level is a crucial first step to understanding how neural activity relates to perception and behavior. Models of neural dynamics often focus on either low-dimensional projections of neural activity, or on learning dynamical systems that explicitly relate to the neural state over time. We discuss how these two approaches are interrelated by considering dynamical systems as representative of flows on a low-dimensional manifold. Building on this concept, we propose a new decomposed dynamical system model that represents complex non-stationary and nonlinear dynamics of time-series data as a sparse combination of simpler, more interpretable components. The decomposed nature of the dynamics generalizes over previous switched approaches and enables modeling of overlapping and non-stationary drifts in the dynamics. We further present a dictionary learning-driven approach to model fitting, where we leverage recent results in tracking sparse vectors over time. We demonstrate that our model can learn efficient representations and smooth transitions between dynamical modes in both continuous-time and discrete-time examples. We show results on low-dimensional linear and nonlinear attractors to demonstrate that our decomposed dynamical systems model can well approximate nonlinear dynamics. Additionally, we apply our model to C. elegans data, illustrating a diversity of dynamics that is obscured when classified into discrete states.
Prospective Learning: Back to the Future
Jan 19, 2022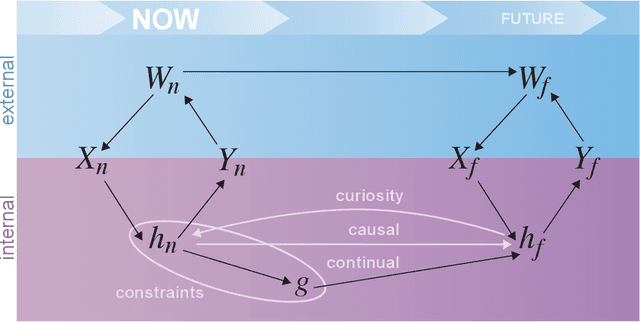

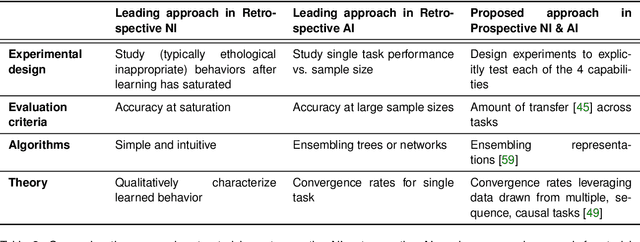
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.