 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultispectral Self-Supervised Learning with Viewmaker Networks
Feb 11, 2023



Contrastive learning methods have been applied to a range of domains and modalities by training models to identify similar ``views'' of data points. However, specialized scientific modalities pose a challenge for this paradigm, as identifying good views for each scientific instrument is complex and time-intensive. In this paper, we focus on applying contrastive learning approaches to a variety of remote sensing datasets. We show that Viewmaker networks, a recently proposed method for generating views, are promising for producing views in this setting without requiring extensive domain knowledge and trial and error. We apply Viewmaker to four multispectral imaging problems, each with a different format, finding that Viewmaker can outperform cropping- and reflection-based methods for contrastive learning in every case when evaluated on downstream classification tasks. This provides additional evidence that domain-agnostic methods can empower contrastive learning to scale to real-world scientific domains. Open source code can be found at https://github.com/jbayrooti/divmaker.
Task Ambiguity in Humans and Language Models
Dec 20, 2022



Language models have recently achieved strong performance across a wide range of NLP benchmarks. However, unlike benchmarks, real world tasks are often poorly specified, and agents must deduce the user's intended behavior from a combination of context, instructions, and examples. We investigate how both humans and models behave in the face of such task ambiguity by proposing AmbiBench, a new benchmark of six ambiguously-specified classification tasks. We evaluate humans and models on AmbiBench by seeing how well they identify the intended task using 1) instructions with varying degrees of ambiguity, and 2) different numbers of labeled examples. We find that the combination of model scaling (to 175B parameters) and training with human feedback data enables models to approach or exceed the accuracy of human participants across tasks, but that either one alone is not sufficient. In addition, we show how to dramatically improve the accuracy of language models trained without large-scale human feedback training by finetuning on a small number of ambiguous in-context examples, providing a promising direction for teaching models to generalize well in the face of ambiguity.
Feature Dropout: Revisiting the Role of Augmentations in Contrastive Learning
Dec 16, 2022



What role do augmentations play in contrastive learning? Recent work suggests that good augmentations are label-preserving with respect to a specific downstream task. We complicate this picture by showing that label-destroying augmentations can be useful in the foundation model setting, where the goal is to learn diverse, general-purpose representations for multiple downstream tasks. We perform contrastive learning experiments on a range of image and audio datasets with multiple downstream tasks (e.g. for digits superimposed on photographs, predicting the class of one vs. the other). We find that Viewmaker Networks, a recently proposed model for learning augmentations for contrastive learning, produce label-destroying augmentations that stochastically destroy features needed for different downstream tasks. These augmentations are interpretable (e.g. altering shapes, digits, or letters added to images) and surprisingly often result in better performance compared to expert-designed augmentations, despite not preserving label information. To support our empirical results, we theoretically analyze a simple contrastive learning setting with a linear model. In this setting, label-destroying augmentations are crucial for preventing one set of features from suppressing the learning of features useful for another downstream task. Our results highlight the need for analyzing the interaction between multiple downstream tasks when trying to explain the success of foundation models.
Assistive Teaching of Motor Control Tasks to Humans
Nov 25, 2022



Recent works on shared autonomy and assistive-AI technologies, such as assistive robot teleoperation, seek to model and help human users with limited ability in a fixed task. However, these approaches often fail to account for humans' ability to adapt and eventually learn how to execute a control task themselves. Furthermore, in applications where it may be desirable for a human to intervene, these methods may inhibit their ability to learn how to succeed with full self-control. In this paper, we focus on the problem of assistive teaching of motor control tasks such as parking a car or landing an aircraft. Despite their ubiquitous role in humans' daily activities and occupations, motor tasks are rarely taught in a uniform way due to their high complexity and variance. We propose an AI-assisted teaching algorithm that leverages skill discovery methods from reinforcement learning (RL) to (i) break down any motor control task into teachable skills, (ii) construct novel drill sequences, and (iii) individualize curricula to students with different capabilities. Through an extensive mix of synthetic and user studies on two motor control tasks -- parking a car with a joystick and writing characters from the Balinese alphabet -- we show that assisted teaching with skills improves student performance by around 40% compared to practicing full trajectories without skills, and practicing with individualized drills can result in up to 25% further improvement. Our source code is available at https://github.com/Stanford-ILIAD/teaching
LEMMA: Bootstrapping High-Level Mathematical Reasoning with Learned Symbolic Abstractions
Nov 16, 2022Humans tame the complexity of mathematical reasoning by developing hierarchies of abstractions. With proper abstractions, solutions to hard problems can be expressed concisely, thus making them more likely to be found. In this paper, we propose Learning Mathematical Abstractions (LEMMA): an algorithm that implements this idea for reinforcement learning agents in mathematical domains. LEMMA augments Expert Iteration with an abstraction step, where solutions found so far are revisited and rewritten in terms of new higher-level actions, which then become available to solve new problems. We evaluate LEMMA on two mathematical reasoning tasks--equation solving and fraction simplification--in a step-by-step fashion. In these two domains, LEMMA improves the ability of an existing agent, both solving more problems and generalizing more effectively to harder problems than those seen during training.
Psychologically-informed chain-of-thought prompts for metaphor understanding in large language models
Sep 16, 2022
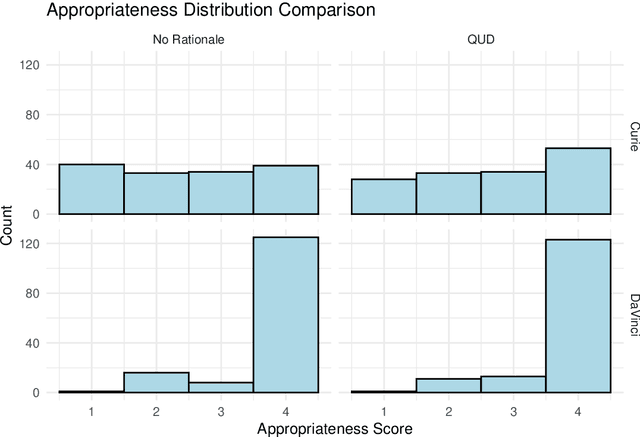


Probabilistic models of language understanding are interpretable and structured, for instance models of metaphor understanding describe inference about latent topics and features. However, these models are manually designed for a specific task. Large language models (LLMs) can perform many tasks through in-context learning, but they lack the clear structure of probabilistic models. In this paper, we use chain-of-thought prompts to introduce structures from probabilistic models into LLMs. These prompts lead the model to infer latent variables and reason about their relationships to choose appropriate paraphrases for metaphors. The latent variables and relationships chosen are informed by theories of metaphor understanding from cognitive psychology. We apply these prompts to the two largest versions of GPT-3 and show that they can improve paraphrase selection.
Foundation Posteriors for Approximate Probabilistic Inference
May 19, 2022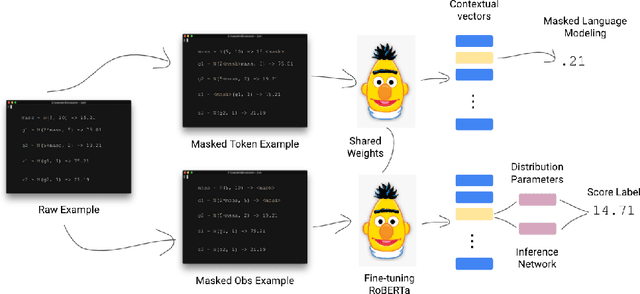
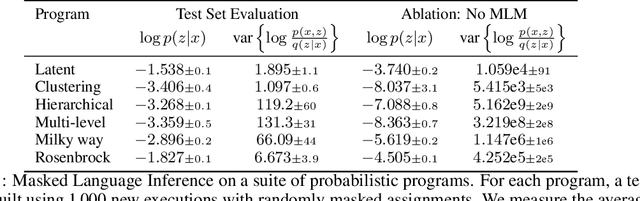
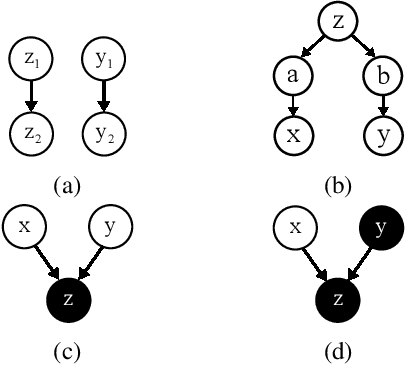

Probabilistic programs provide an expressive representation language for generative models. Given a probabilistic program, we are interested in the task of posterior inference: estimating a latent variable given a set of observed variables. Existing techniques for inference in probabilistic programs often require choosing many hyper-parameters, are computationally expensive, and/or only work for restricted classes of programs. Here we formulate inference as masked language modeling: given a program, we generate a supervised dataset of variables and assignments, and randomly mask a subset of the assignments. We then train a neural network to unmask the random values, defining an approximate posterior distribution. By optimizing a single neural network across a range of programs we amortize the cost of training, yielding a ``foundation'' posterior able to do zero-shot inference for new programs. The foundation posterior can also be fine-tuned for a particular program and dataset by optimizing a variational inference objective. We show the efficacy of the approach, zero-shot and fine-tuned, on a benchmark of STAN programs.
Mixed-effects transformers for hierarchical adaptation
May 03, 2022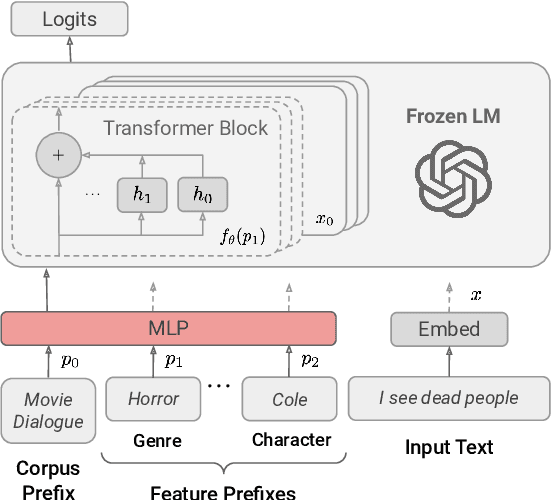
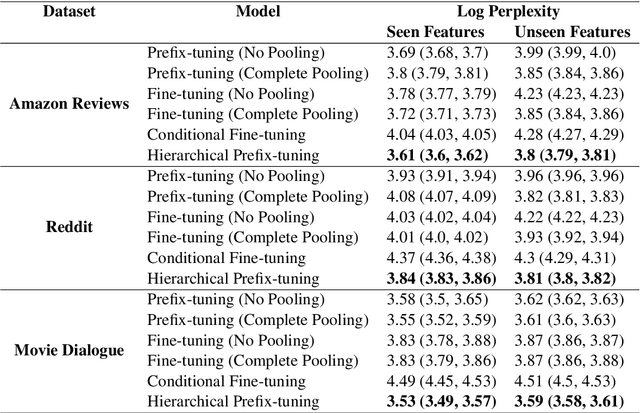
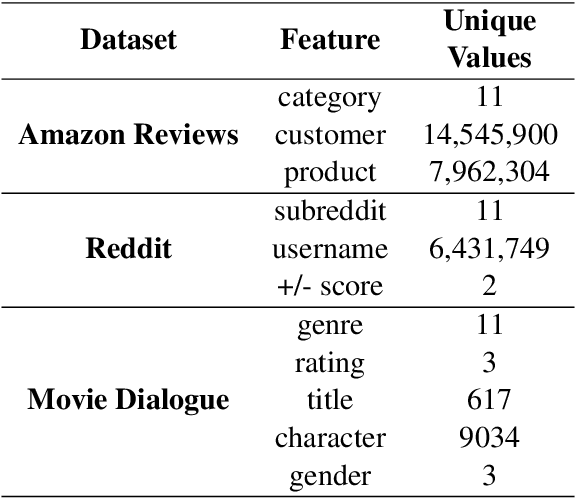
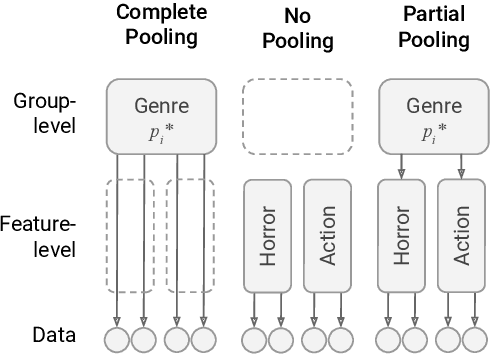
Language use differs dramatically from context to context. To some degree, modern language models like GPT-3 are able to account for such variance by conditioning on a string of previous input text, or prompt. Yet prompting is ineffective when contexts are sparse, out-of-sample, or extra-textual; for instance, accounting for when and where the text was produced or who produced it. In this paper, we introduce the mixed-effects transformer (MET), a novel approach for learning hierarchically-structured prefixes -- lightweight modules prepended to the input -- to account for structured variation. Specifically, we show how the popular class of mixed-effects models may be extended to transformer-based architectures using a regularized prefix-tuning procedure with dropout. We evaluate this approach on several domain-adaptation benchmarks, finding that it efficiently adapts to novel contexts with minimal data while still effectively generalizing to unseen contexts.
Know Thy Student: Interactive Learning with Gaussian Processes
Apr 26, 2022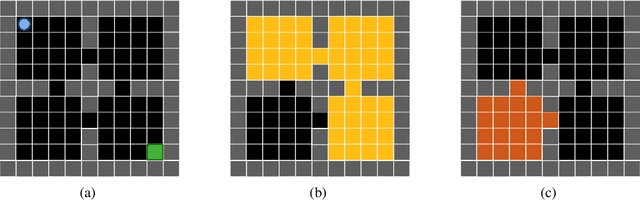
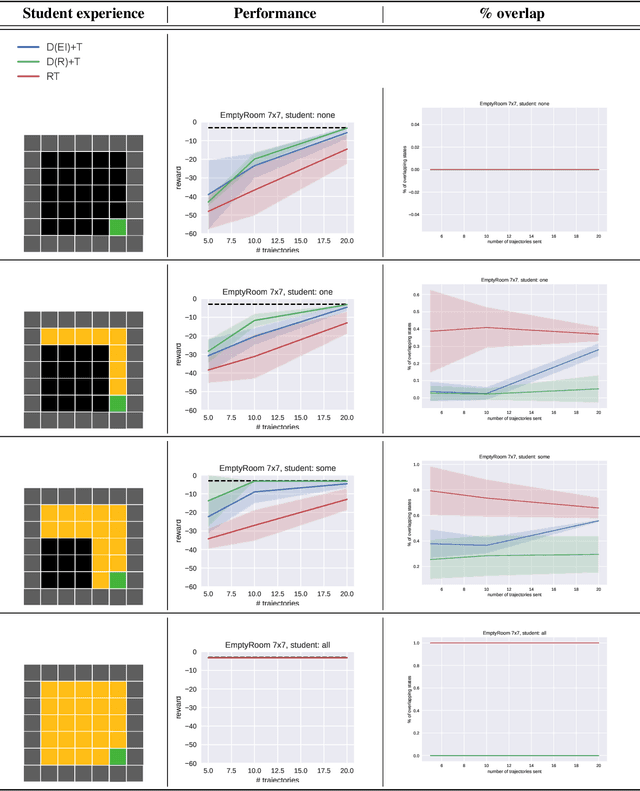

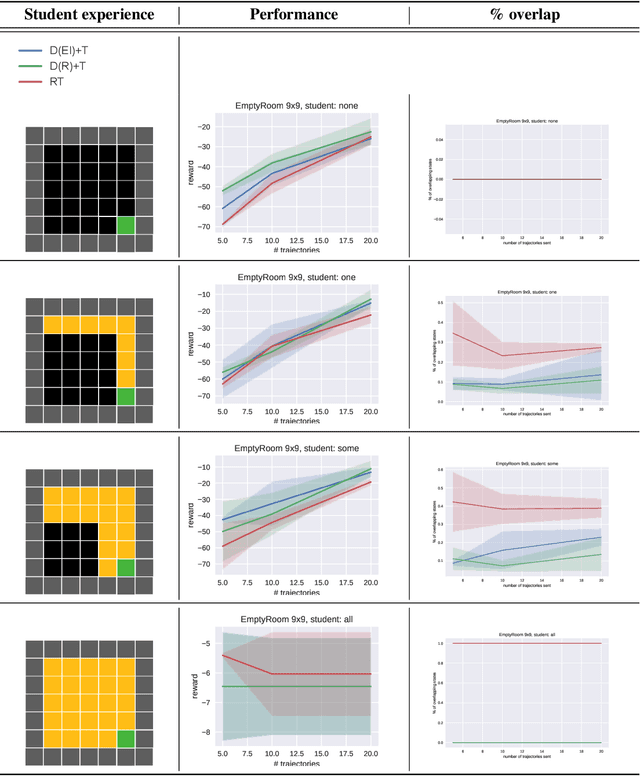
Learning often involves interaction between multiple agents. Human teacher-student settings best illustrate how interactions result in efficient knowledge passing where the teacher constructs a curriculum based on their students' abilities. Prior work in machine teaching studies how the teacher should construct optimal teaching datasets assuming the teacher knows everything about the student. However, in the real world, the teacher doesn't have complete information about the student. The teacher must interact and diagnose the student, before teaching. Our work proposes a simple diagnosis algorithm which uses Gaussian processes for inferring student-related information, before constructing a teaching dataset. We apply this to two settings. One is where the student learns from scratch and the teacher must figure out the student's learning algorithm parameters, eg. the regularization parameters in ridge regression or support vector machines. Two is where the student has partially explored the environment and the teacher must figure out the important areas the student has not explored; we study this in the offline reinforcement learning setting where the teacher must provide demonstrations to the student and avoid sending redundant trajectories. Our experiments highlight the importance of diagosing before teaching and demonstrate how students can learn more efficiently with the help of an interactive teacher. We conclude by outlining where diagnosing combined with teaching would be more desirable than passive learning.
Active Learning Helps Pretrained Models Learn the Intended Task
Apr 18, 2022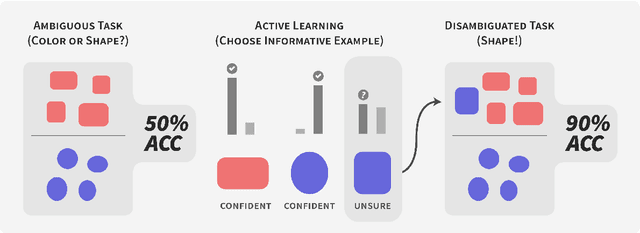
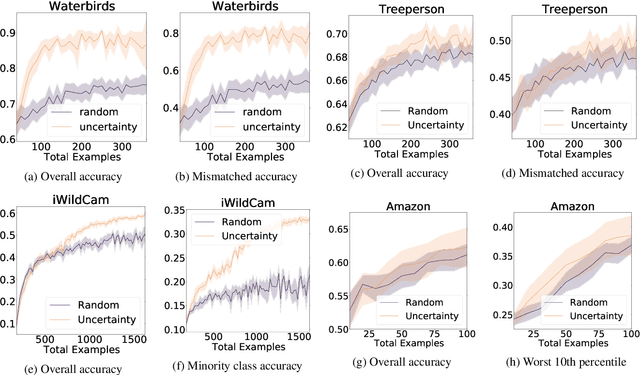
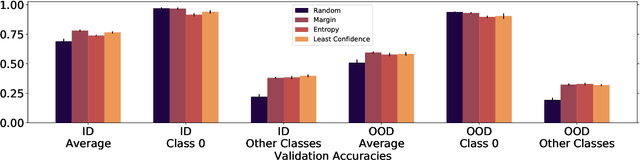
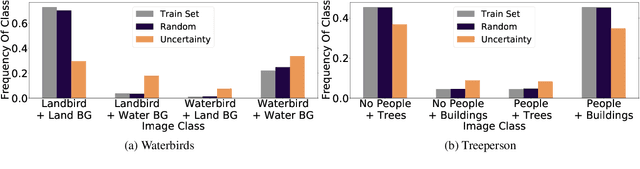
Models can fail in unpredictable ways during deployment due to task ambiguity, when multiple behaviors are consistent with the provided training data. An example is an object classifier trained on red squares and blue circles: when encountering blue squares, the intended behavior is undefined. We investigate whether pretrained models are better active learners, capable of disambiguating between the possible tasks a user may be trying to specify. Intriguingly, we find that better active learning is an emergent property of the pretraining process: pretrained models require up to 5 times fewer labels when using uncertainty-based active learning, while non-pretrained models see no or even negative benefit. We find these gains come from an ability to select examples with attributes that disambiguate the intended behavior, such as rare product categories or atypical backgrounds. These attributes are far more linearly separable in pretrained model's representation spaces vs non-pretrained models, suggesting a possible mechanism for this behavior.