 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA One-Inclusion Graph Approach to Multi-Group Learning
Mar 24, 2026We prove the tightest-known upper bounds on the sample complexity of multi-group learning. Our algorithm extends the one-inclusion graph prediction strategy using a generalization of bipartite $b$-matching. In the group-realizable setting, we provide a lower bound confirming that our algorithm's $\log n / n$ convergence rate is optimal in general. If one relaxes the learning objective such that the group on which we are evaluated is chosen obliviously of the sample, then our algorithm achieves the optimal $1/n$ convergence rate under group-realizability.
t-SNE Exaggerates Clusters, Provably
Oct 09, 2025Central to the widespread use of t-distributed stochastic neighbor embedding (t-SNE) is the conviction that it produces visualizations whose structure roughly matches that of the input. To the contrary, we prove that (1) the strength of the input clustering, and (2) the extremity of outlier points, cannot be reliably inferred from the t-SNE output. We demonstrate the prevalence of these failure modes in practice as well.
ClusterSC: Advancing Synthetic Control with Donor Selection
Mar 27, 2025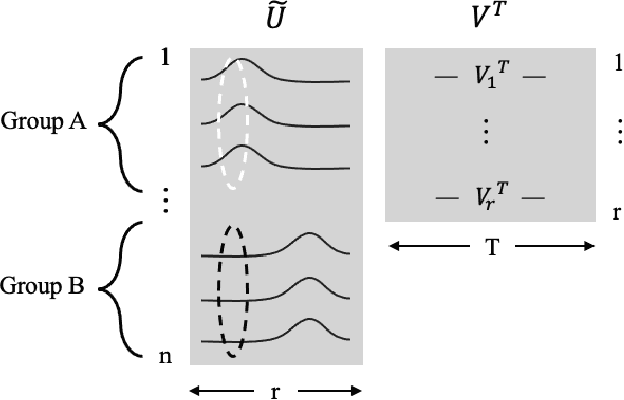
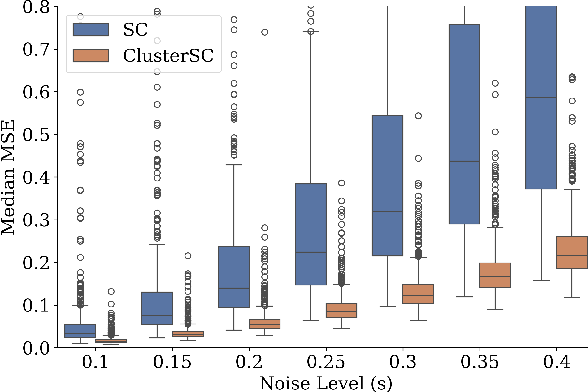
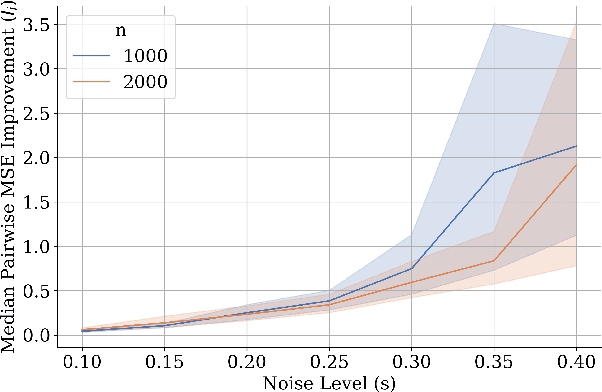
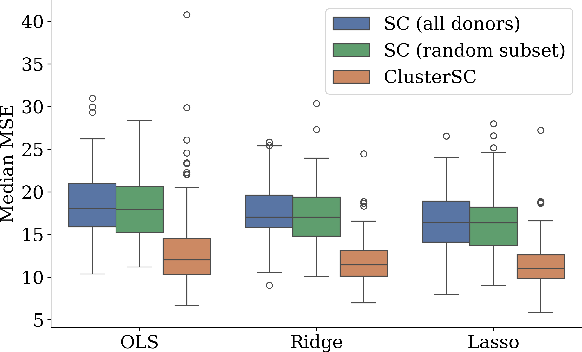
In causal inference with observational studies, synthetic control (SC) has emerged as a prominent tool. SC has traditionally been applied to aggregate-level datasets, but more recent work has extended its use to individual-level data. As they contain a greater number of observed units, this shift introduces the curse of dimensionality to SC. To address this, we propose Cluster Synthetic Control (ClusterSC), based on the idea that groups of individuals may exist where behavior aligns internally but diverges between groups. ClusterSC incorporates a clustering step to select only the relevant donors for the target. We provide theoretical guarantees on the improvements induced by ClusterSC, supported by empirical demonstrations on synthetic and real-world datasets. The results indicate that ClusterSC consistently outperforms classical SC approaches.
Confidence-Calibrated Ensemble Dense Phrase Retrieval
Jun 28, 2023In this paper, we consider the extent to which the transformer-based Dense Passage Retrieval (DPR) algorithm, developed by (Karpukhin et. al. 2020), can be optimized without further pre-training. Our method involves two particular insights: we apply the DPR context encoder at various phrase lengths (e.g. one-sentence versus five-sentence segments), and we take a confidence-calibrated ensemble prediction over all of these different segmentations. This somewhat exhaustive approach achieves start-of-the-art results on benchmark datasets such as Google NQ and SQuAD. We also apply our method to domain-specific datasets, and the results suggest how different granularities are optimal for different domains
Legal and Political Stance Detection of SCOTUS Language
Nov 21, 2022



We analyze publicly available US Supreme Court documents using automated stance detection. In the first phase of our work, we investigate the extent to which the Court's public-facing language is political. We propose and calculate two distinct ideology metrics of SCOTUS justices using oral argument transcripts. We then compare these language-based metrics to existing social scientific measures of the ideology of the Supreme Court and the public. Through this cross-disciplinary analysis, we find that justices who are more responsive to public opinion tend to express their ideology during oral arguments. This observation provides a new kind of evidence in favor of the attitudinal change hypothesis of Supreme Court justice behavior. As a natural extension of this political stance detection, we propose the more specialized task of legal stance detection with our new dataset SC-stance, which matches written opinions to legal questions. We find competitive performance on this dataset using language adapters trained on legal documents.