 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer Assisted Translation with Neural Quality Estimation and Automatic Post-Editing
Sep 28, 2020
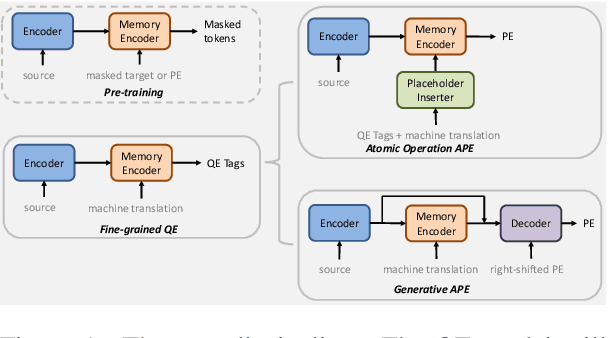

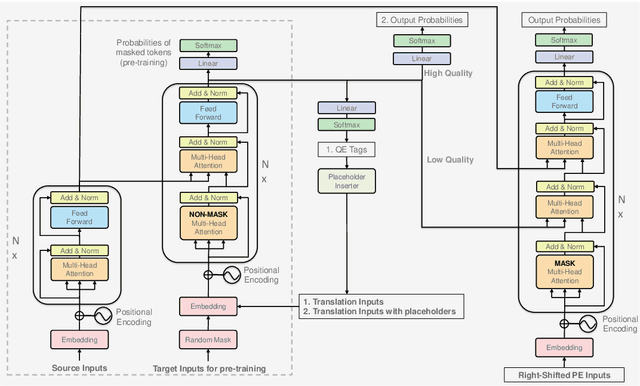
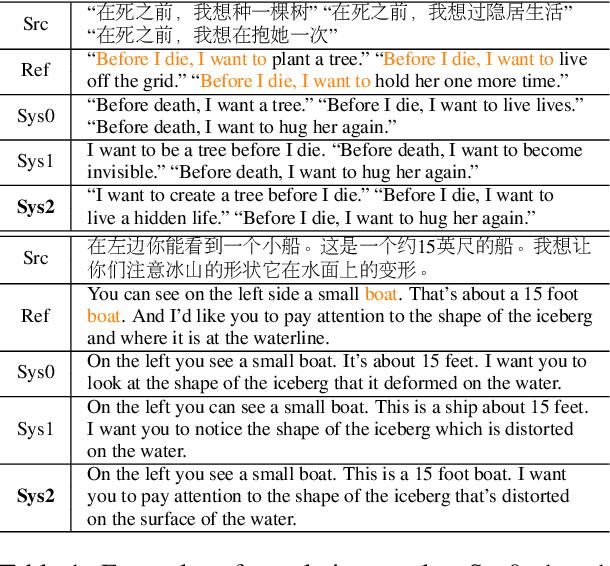
With the advent of neural machine translation, there has been a marked shift towards leveraging and consuming the machine translation results. However, the gap between machine translation systems and human translators needs to be manually closed by post-editing. In this paper, we propose an end-to-end deep learning framework of the quality estimation and automatic post-editing of the machine translation output. Our goal is to provide error correction suggestions and to further relieve the burden of human translators through an interpretable model. To imitate the behavior of human translators, we design three efficient delegation modules -- quality estimation, generative post-editing, and atomic operation post-editing and construct a hierarchical model based on them. We examine this approach with the English--German dataset from WMT 2017 APE shared task and our experimental results can achieve the state-of-the-art performance. We also verify that the certified translators can significantly expedite their post-editing processing with our model in human evaluation.
Long-Short Term Masking Transformer: A Simple but Effective Baseline for Document-level Neural Machine Translation
Sep 19, 2020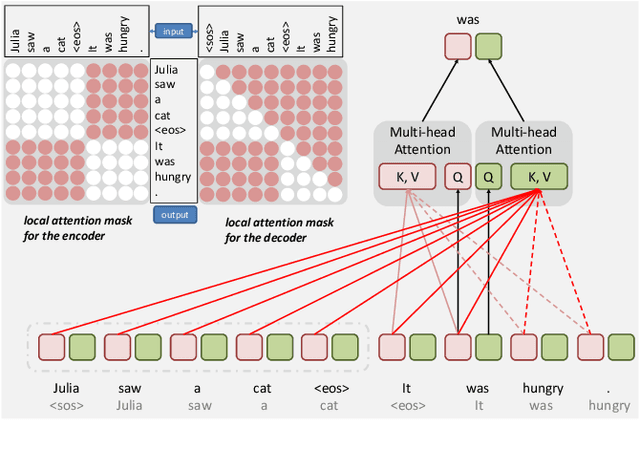
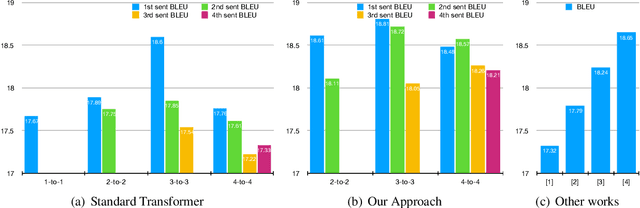
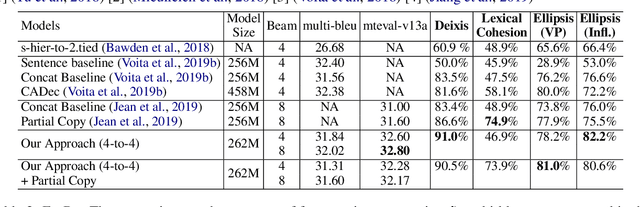
Many document-level neural machine translation (NMT) systems have explored the utility of context-aware architecture, usually requiring an increasing number of parameters and computational complexity. However, few attention is paid to the baseline model. In this paper, we research extensively the pros and cons of the standard transformer in document-level translation, and find that the auto-regressive property can simultaneously bring both the advantage of the consistency and the disadvantage of error accumulation. Therefore, we propose a surprisingly simple long-short term masking self-attention on top of the standard transformer to both effectively capture the long-range dependence and reduce the propagation of errors. We examine our approach on the two publicly available document-level datasets. We can achieve a strong result in BLEU and capture discourse phenomena.
Neural Zero-Inflated Quality Estimation Model For Automatic Speech Recognition System
Oct 03, 2019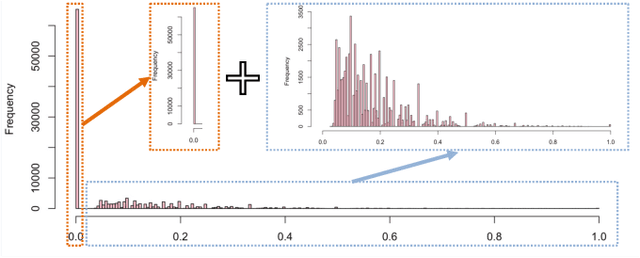

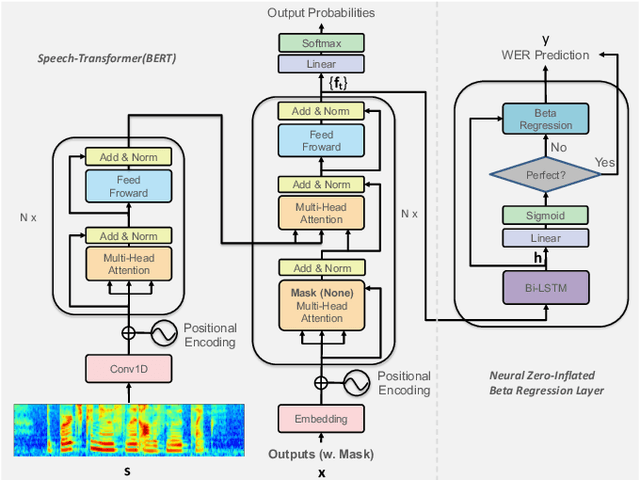

The performances of automatic speech recognition (ASR) systems are usually evaluated by the metric word error rate (WER) when the manually transcribed data are provided, which are, however, expensively available in the real scenario. In addition, the empirical distribution of WER for most ASR systems usually tends to put a significant mass near zero, making it difficult to simulate with a single continuous distribution. In order to address the two issues of ASR quality estimation (QE), we propose a novel neural zero-inflated model to predict the WER of the ASR result without transcripts. We design a neural zero-inflated beta regression on top of a bidirectional transformer language model conditional on speech features (speech-BERT). We adopt the pre-training strategy of token level mask language modeling for speech-BERT as well, and further fine-tune with our zero-inflated layer for the mixture of discrete and continuous outputs. The experimental results show that our approach achieves better performance on WER prediction in the metrics of Pearson and MAE, compared with most existed quality estimation algorithms for ASR or machine translation.
Lattice Transformer for Speech Translation
Jun 13, 2019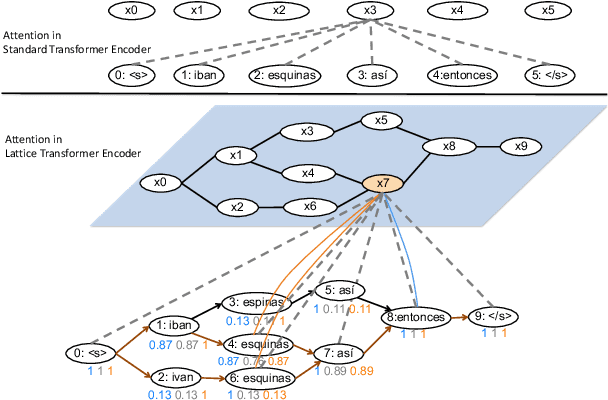

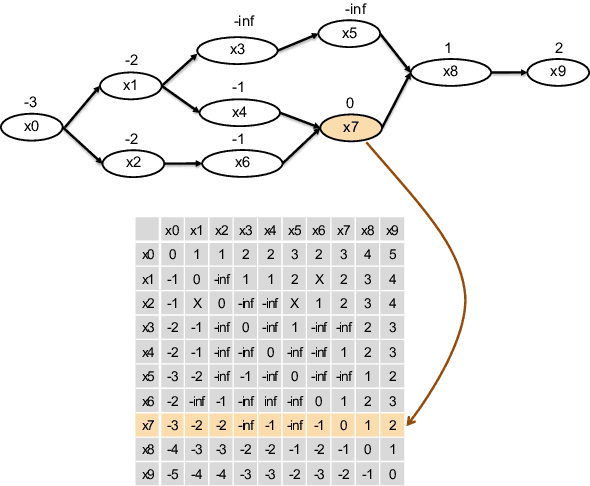
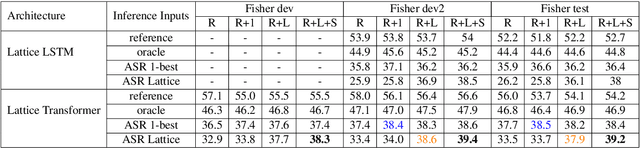
Recent advances in sequence modeling have highlighted the strengths of the transformer architecture, especially in achieving state-of-the-art machine translation results. However, depending on the up-stream systems, e.g., speech recognition, or word segmentation, the input to translation system can vary greatly. The goal of this work is to extend the attention mechanism of the transformer to naturally consume the lattice in addition to the traditional sequential input. We first propose a general lattice transformer for speech translation where the input is the output of the automatic speech recognition (ASR) which contains multiple paths and posterior scores. To leverage the extra information from the lattice structure, we develop a novel controllable lattice attention mechanism to obtain latent representations. On the LDC Spanish-English speech translation corpus, our experiments show that lattice transformer generalizes significantly better and outperforms both a transformer baseline and a lattice LSTM. Additionally, we validate our approach on the WMT 2017 Chinese-English translation task with lattice inputs from different BPE segmentations. In this task, we also observe the improvements over strong baselines.