 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical tradeoffs between memory, compute, and performance in learned optimizers
Apr 01, 2022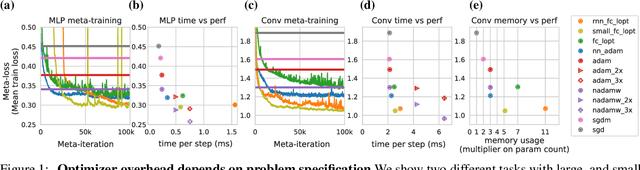

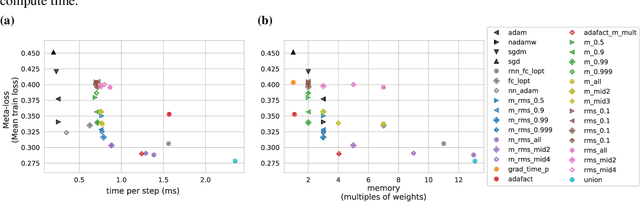
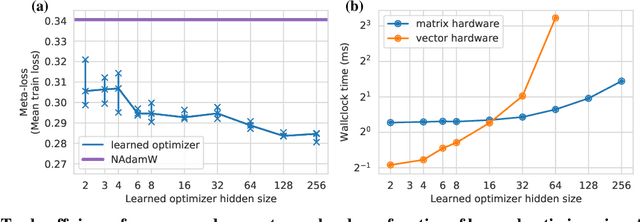
Optimization plays a costly and crucial role in developing machine learning systems. In learned optimizers, the few hyperparameters of commonly used hand-designed optimizers, e.g. Adam or SGD, are replaced with flexible parametric functions. The parameters of these functions are then optimized so that the resulting learned optimizer minimizes a target loss on a chosen class of models. Learned optimizers can both reduce the number of required training steps and improve the final test loss. However, they can be expensive to train, and once trained can be expensive to use due to computational and memory overhead for the optimizer itself. In this work, we identify and quantify the design features governing the memory, compute, and performance trade-offs for many learned and hand-designed optimizers. We further leverage our analysis to construct a learned optimizer that is both faster and more memory efficient than previous work.
Understanding How Encoder-Decoder Architectures Attend
Oct 28, 2021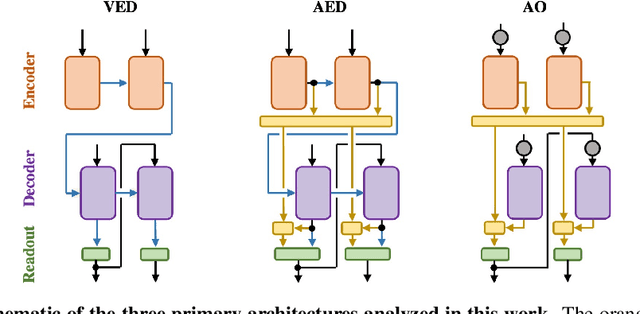
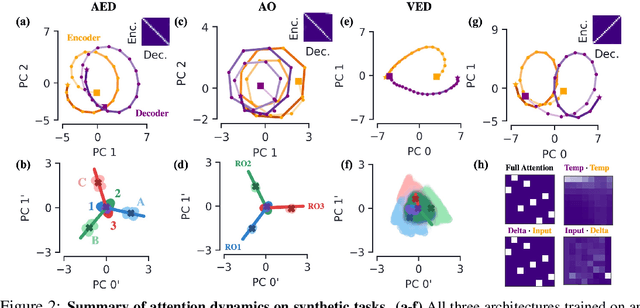
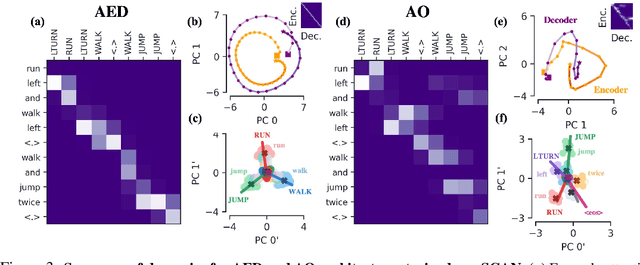
Encoder-decoder networks with attention have proven to be a powerful way to solve many sequence-to-sequence tasks. In these networks, attention aligns encoder and decoder states and is often used for visualizing network behavior. However, the mechanisms used by networks to generate appropriate attention matrices are still mysterious. Moreover, how these mechanisms vary depending on the particular architecture used for the encoder and decoder (recurrent, feed-forward, etc.) are also not well understood. In this work, we investigate how encoder-decoder networks solve different sequence-to-sequence tasks. We introduce a way of decomposing hidden states over a sequence into temporal (independent of input) and input-driven (independent of sequence position) components. This reveals how attention matrices are formed: depending on the task requirements, networks rely more heavily on either the temporal or input-driven components. These findings hold across both recurrent and feed-forward architectures despite their differences in forming the temporal components. Overall, our results provide new insight into the inner workings of attention-based encoder-decoder networks.
Training Learned Optimizers with Randomly Initialized Learned Optimizers
Jan 14, 2021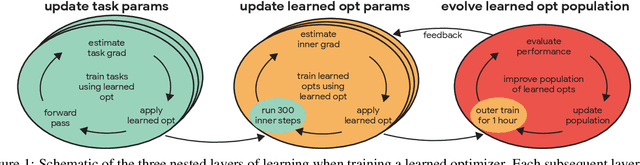
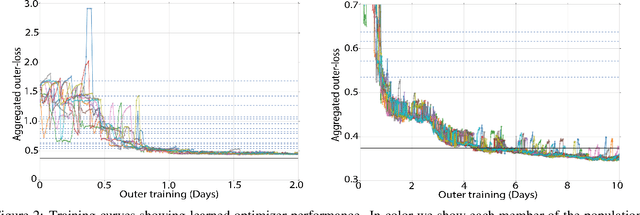
Learned optimizers are increasingly effective, with performance exceeding that of hand designed optimizers such as Adam~\citep{kingma2014adam} on specific tasks \citep{metz2019understanding}. Despite the potential gains available, in current work the meta-training (or `outer-training') of the learned optimizer is performed by a hand-designed optimizer, or by an optimizer trained by a hand-designed optimizer \citep{metz2020tasks}. We show that a population of randomly initialized learned optimizers can be used to train themselves from scratch in an online fashion, without resorting to a hand designed optimizer in any part of the process. A form of population based training is used to orchestrate this self-training. Although the randomly initialized optimizers initially make slow progress, as they improve they experience a positive feedback loop, and become rapidly more effective at training themselves. We believe feedback loops of this type, where an optimizer improves itself, will be important and powerful in the future of machine learning. These methods not only provide a path towards increased performance, but more importantly relieve research and engineering effort.
Reverse engineering learned optimizers reveals known and novel mechanisms
Nov 04, 2020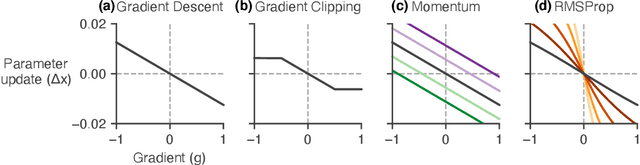
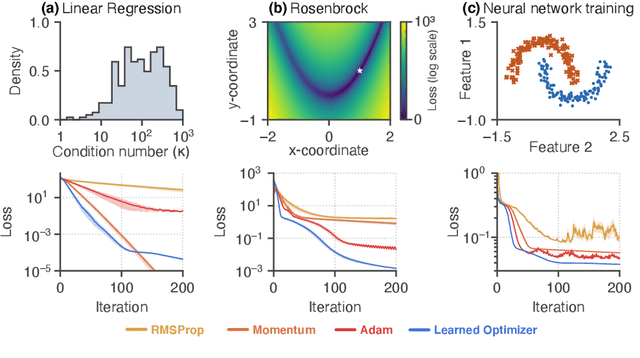
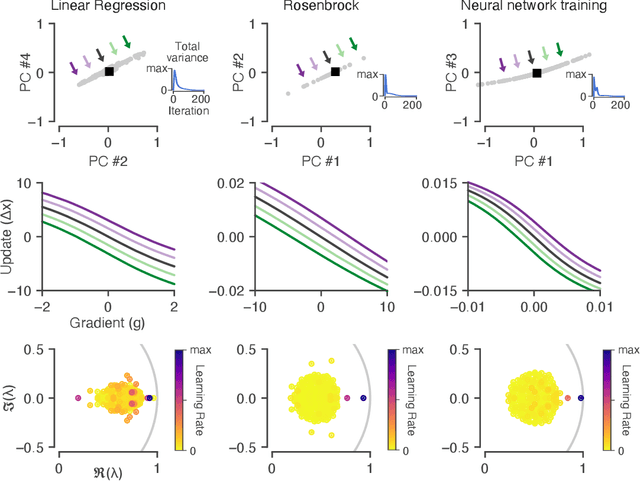
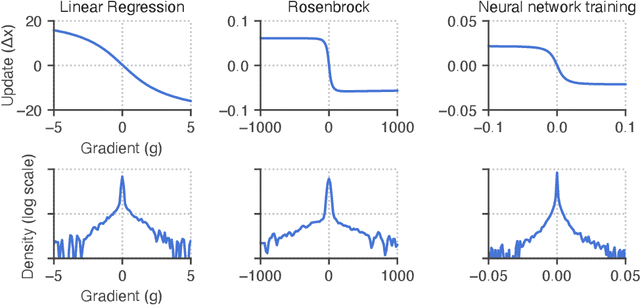
Learned optimizers are algorithms that can themselves be trained to solve optimization problems. In contrast to baseline optimizers (such as momentum or Adam) that use simple update rules derived from theoretical principles, learned optimizers use flexible, high-dimensional, nonlinear parameterizations. Although this can lead to better performance in certain settings, their inner workings remain a mystery. How is a learned optimizer able to outperform a well tuned baseline? Has it learned a sophisticated combination of existing optimization techniques, or is it implementing completely new behavior? In this work, we address these questions by careful analysis and visualization of learned optimizers. We study learned optimizers trained from scratch on three disparate tasks, and discover that they have learned interpretable mechanisms, including: momentum, gradient clipping, learning rate schedules, and a new form of learning rate adaptation. Moreover, we show how the dynamics of learned optimizers enables these behaviors. Our results help elucidate the previously murky understanding of how learned optimizers work, and establish tools for interpreting future learned optimizers.
The geometry of integration in text classification RNNs
Oct 28, 2020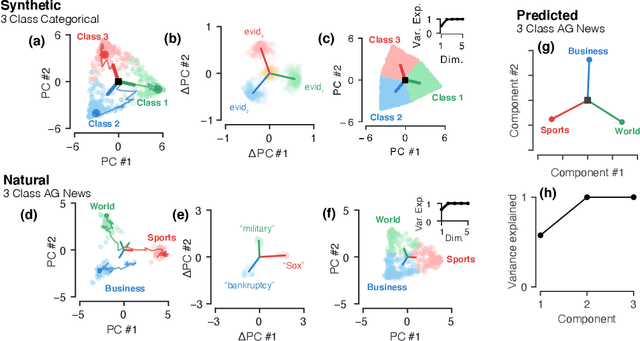
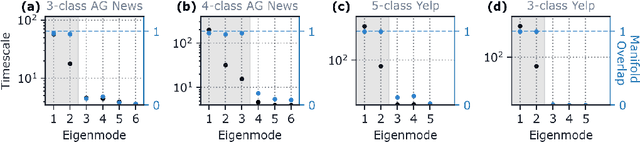
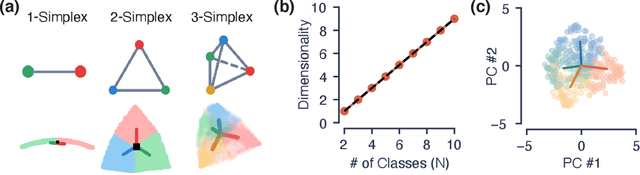
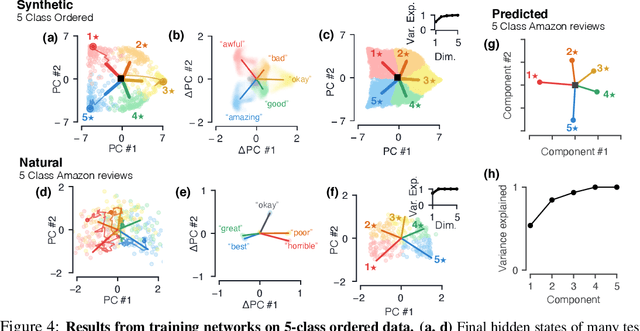
Despite the widespread application of recurrent neural networks (RNNs) across a variety of tasks, a unified understanding of how RNNs solve these tasks remains elusive. In particular, it is unclear what dynamical patterns arise in trained RNNs, and how those patterns depend on the training dataset or task. This work addresses these questions in the context of a specific natural language processing task: text classification. Using tools from dynamical systems analysis, we study recurrent networks trained on a battery of both natural and synthetic text classification tasks. We find the dynamics of these trained RNNs to be both interpretable and low-dimensional. Specifically, across architectures and datasets, RNNs accumulate evidence for each class as they process the text, using a low-dimensional attractor manifold as the underlying mechanism. Moreover, the dimensionality and geometry of the attractor manifold are determined by the structure of the training dataset; in particular, we describe how simple word-count statistics computed on the training dataset can be used to predict these properties. Our observations span multiple architectures and datasets, reflecting a common mechanism RNNs employ to perform text classification. To the degree that integration of evidence towards a decision is a common computational primitive, this work lays the foundation for using dynamical systems techniques to study the inner workings of RNNs.
Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves
Sep 23, 2020
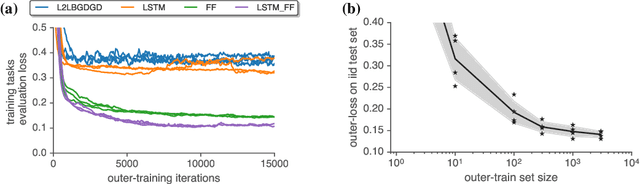
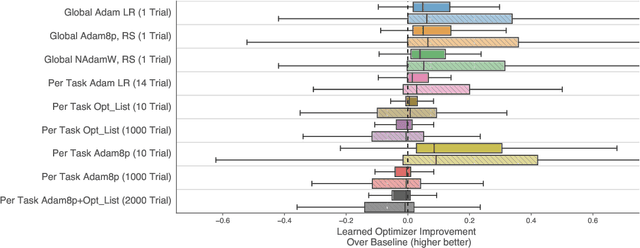
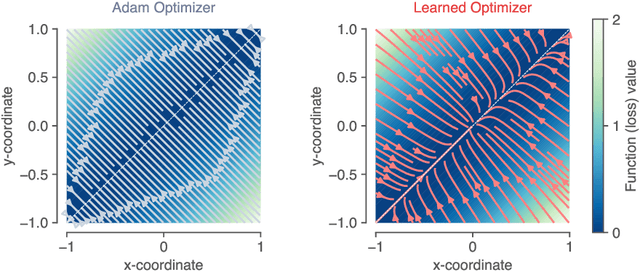
Much as replacing hand-designed features with learned functions has revolutionized how we solve perceptual tasks, we believe learned algorithms will transform how we train models. In this work we focus on general-purpose learned optimizers capable of training a wide variety of problems with no user-specified hyperparameters. We introduce a new, neural network parameterized, hierarchical optimizer with access to additional features such as validation loss to enable automatic regularization. Most learned optimizers have been trained on only a single task, or a small number of tasks. We train our optimizers on thousands of tasks, making use of orders of magnitude more compute, resulting in optimizers that generalize better to unseen tasks. The learned optimizers not only perform well, but learn behaviors that are distinct from existing first order optimizers. For instance, they generate update steps that have implicit regularization and adapt as the problem hyperparameters (e.g. batch size) or architecture (e.g. neural network width) change. Finally, these learned optimizers show evidence of being useful for out of distribution tasks such as training themselves from scratch.
How recurrent networks implement contextual processing in sentiment analysis
Apr 17, 2020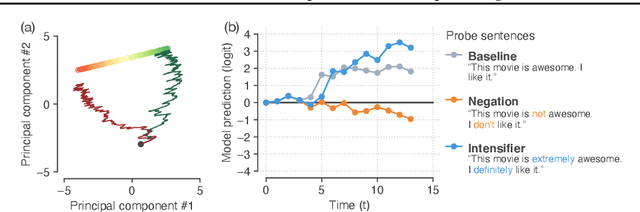
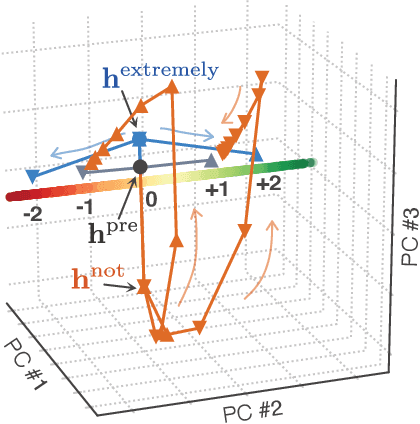
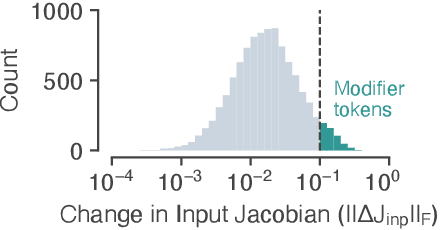
Neural networks have a remarkable capacity for contextual processing--using recent or nearby inputs to modify processing of current input. For example, in natural language, contextual processing is necessary to correctly interpret negation (e.g. phrases such as "not bad"). However, our ability to understand how networks process context is limited. Here, we propose general methods for reverse engineering recurrent neural networks (RNNs) to identify and elucidate contextual processing. We apply these methods to understand RNNs trained on sentiment classification. This analysis reveals inputs that induce contextual effects, quantifies the strength and timescale of these effects, and identifies sets of these inputs with similar properties. Additionally, we analyze contextual effects related to differential processing of the beginning and end of documents. Using the insights learned from the RNNs we improve baseline Bag-of-Words models with simple extensions that incorporate contextual modification, recovering greater than 90% of the RNN's performance increase over the baseline. This work yields a new understanding of how RNNs process contextual information, and provides tools that should provide similar insight more broadly.
Using a thousand optimization tasks to learn hyperparameter search strategies
Mar 11, 2020
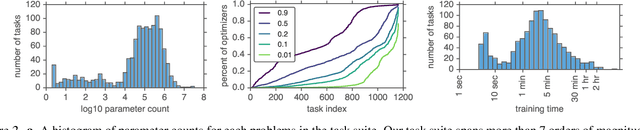
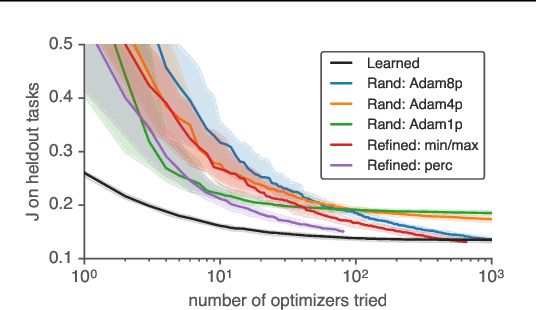
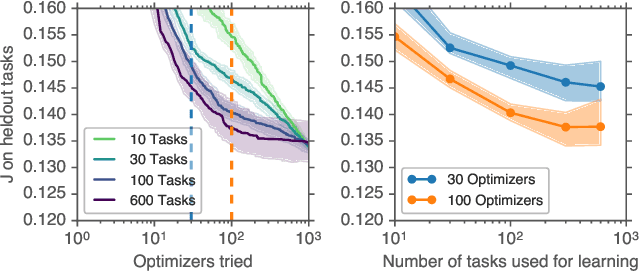
We present TaskSet, a dataset of tasks for use in training and evaluating optimizers. TaskSet is unique in its size and diversity, containing over a thousand tasks ranging from image classification with fully connected or convolutional neural networks, to variational autoencoders, to non-volume preserving flows on a variety of datasets. As an example application of such a dataset we explore meta-learning an ordered list of hyperparameters to try sequentially. By learning this hyperparameter list from data generated using TaskSet we achieve large speedups in sample efficiency over random search. Next we use the diversity of the TaskSet and our method for learning hyperparameter lists to empirically explore the generalization of these lists to new optimization tasks in a variety of settings including ImageNet classification with Resnet50 and LM1B language modeling with transformers. As part of this work we have opensourced code for all tasks, as well as ~29 million training curves for these problems and the corresponding hyperparameters.
From deep learning to mechanistic understanding in neuroscience: the structure of retinal prediction
Dec 12, 2019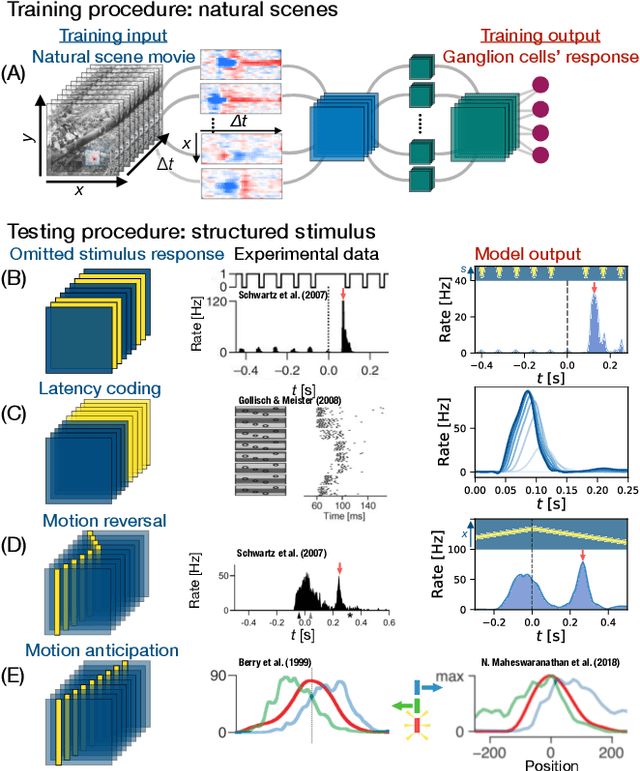
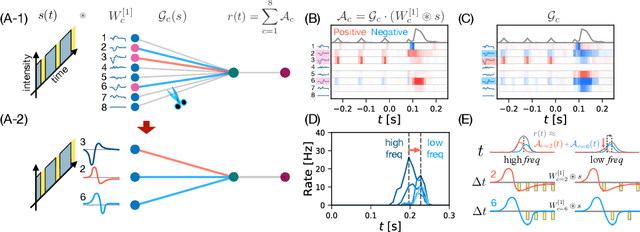
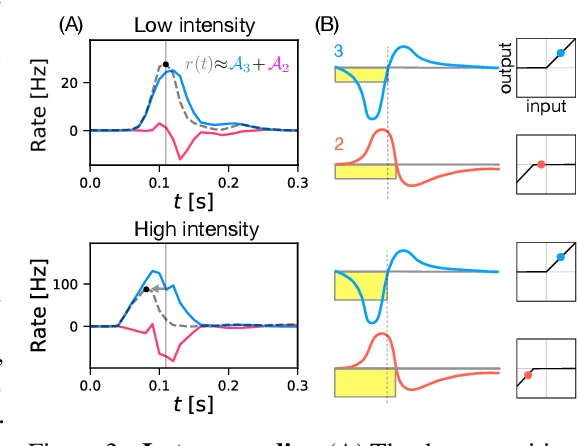
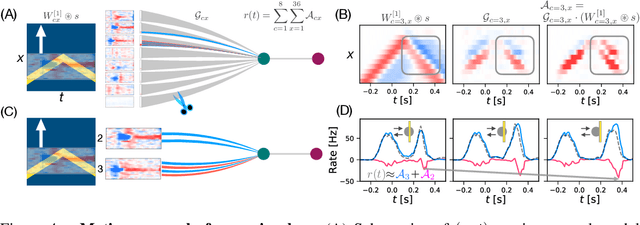
Recently, deep feedforward neural networks have achieved considerable success in modeling biological sensory processing, in terms of reproducing the input-output map of sensory neurons. However, such models raise profound questions about the very nature of explanation in neuroscience. Are we simply replacing one complex system (a biological circuit) with another (a deep network), without understanding either? Moreover, beyond neural representations, are the deep network's computational mechanisms for generating neural responses the same as those in the brain? Without a systematic approach to extracting and understanding computational mechanisms from deep neural network models, it can be difficult both to assess the degree of utility of deep learning approaches in neuroscience, and to extract experimentally testable hypotheses from deep networks. We develop such a systematic approach by combining dimensionality reduction and modern attribution methods for determining the relative importance of interneurons for specific visual computations. We apply this approach to deep network models of the retina, revealing a conceptual understanding of how the retina acts as a predictive feature extractor that signals deviations from expectations for diverse spatiotemporal stimuli. For each stimulus, our extracted computational mechanisms are consistent with prior scientific literature, and in one case yields a new mechanistic hypothesis. Thus overall, this work not only yields insights into the computational mechanisms underlying the striking predictive capabilities of the retina, but also places the framework of deep networks as neuroscientific models on firmer theoretical foundations, by providing a new roadmap to go beyond comparing neural representations to extracting and understand computational mechanisms.
Universality and individuality in neural dynamics across large populations of recurrent networks
Jul 19, 2019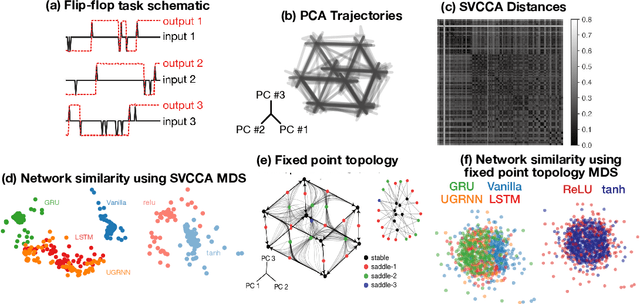
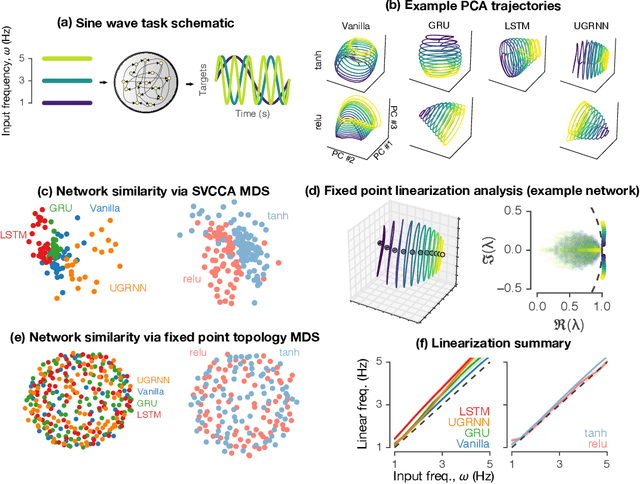
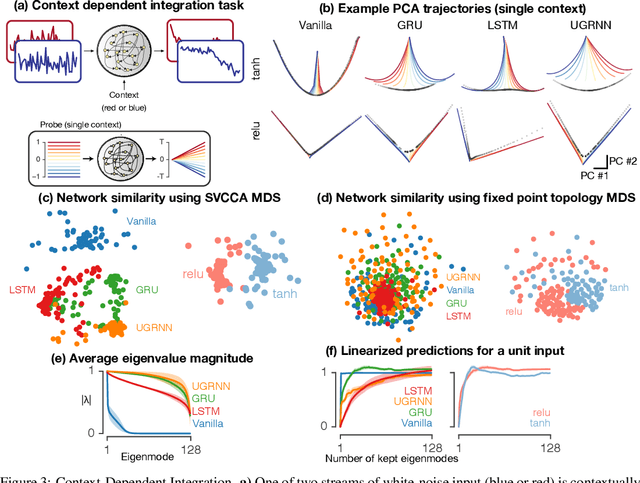
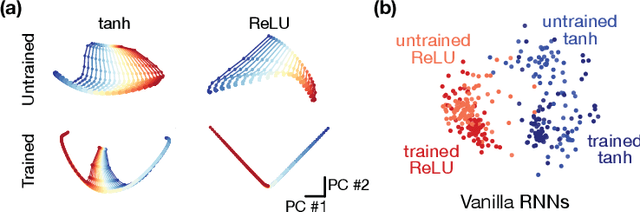
Task-based modeling with recurrent neural networks (RNNs) has emerged as a popular way to infer the computational function of different brain regions. These models are quantitatively assessed by comparing the low-dimensional neural representations of the model with the brain, for example using canonical correlation analysis (CCA). However, the nature of the detailed neurobiological inferences one can draw from such efforts remains elusive. For example, to what extent does training neural networks to solve common tasks uniquely determine the network dynamics, independent of modeling architectural choices? Or alternatively, are the learned dynamics highly sensitive to different model choices? Knowing the answer to these questions has strong implications for whether and how we should use task-based RNN modeling to understand brain dynamics. To address these foundational questions, we study populations of thousands of networks, with commonly used RNN architectures, trained to solve neuroscientifically motivated tasks and characterize their nonlinear dynamics. We find the geometry of the RNN representations can be highly sensitive to different network architectures, yielding a cautionary tale for measures of similarity that rely representational geometry, such as CCA. Moreover, we find that while the geometry of neural dynamics can vary greatly across architectures, the underlying computational scaffold---the topological structure of fixed points, transitions between them, limit cycles, and linearized dynamics---often appears universal across all architectures.