 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025



Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
CRAG -- Comprehensive RAG Benchmark
Jun 07, 2024



Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)'s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
Early Stratification of Patients at Risk for Postoperative Complications after Elective Colectomy
Nov 29, 2018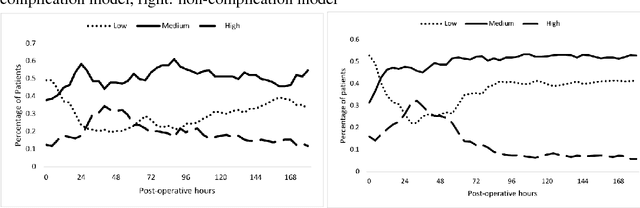
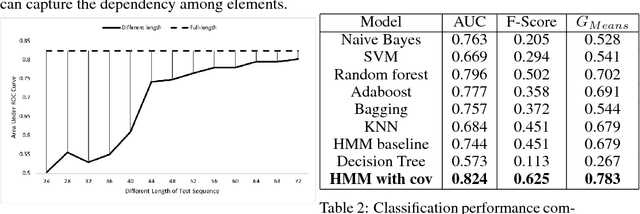
Stratifying patients at risk for postoperative complications may facilitate timely and accurate workups and reduce the burden of adverse events on patients and the health system. Currently, a widely-used surgical risk calculator created by the American College of Surgeons, NSQIP, uses 21 preoperative covariates to assess risk of postoperative complications, but lacks dynamic, real-time capabilities to accommodate postoperative information. We propose a new Hidden Markov Model sequence classifier for analyzing patients' postoperative temperature sequences that incorporates their time-invariant characteristics in both transition probability and initial state probability in order to develop a postoperative "real-time" complication detector. Data from elective Colectomy surgery indicate that our method has improved classification performance compared to 8 other machine learning classifiers when using the full temperature sequence associated with the patients' length of stay. Additionally, within 44 hours after surgery, the performance of the model is close to that of full-length temperature sequence.