 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models
May 07, 2026World model-based policy evaluation is a practical proxy for testing real-world robot control by rolling out candidate actions in action-conditioned video diffusion models. As these models increasingly adopt latent diffusion modeling (LDM), choosing the right latent space becomes critical. While the status quo uses autoencoding latent spaces like VAEs that are primarily trained for pixel reconstruction, recent work suggests benefits from pretrained encoders with representation-aligned semantic latent spaces. We systematically evaluate these latent spaces for action-conditioned LDM by comparing six reconstruction and semantic encoders to train world model variants under a fixed protocol on BridgeV2 dataset, and show effective world model training in high-dimensional representation spaces with and without dimension compression. We then propose three axes to assess robotic world model performance: visual fidelity, planning and downstream policy performance, and latent representation quality. Our results show visual fidelity alone is insufficient for world model selection. While reconstruction encoders like VAE and Cosmos achieve strong pixel-level scores, semantic encoders such as V-JEPA 2.1 (strongest overall on policy), Web-DINO, and SigLIP 2 generally excel across the other two axes at all model scales. Our study advocates semantic latent space as stronger foundation for policy-relevant robotics diffusion world models.
Squeezing More from the Stream : Learning Representation Online for Streaming Reinforcement Learning
Feb 10, 2026In streaming Reinforcement Learning (RL), transitions are observed and discarded immediately after a single update. While this minimizes resource usage for on-device applications, it makes agents notoriously sample-inefficient, since value-based losses alone struggle to extract meaningful representations from transient data. We propose extending Self-Predictive Representations (SPR) to the streaming pipeline to maximize the utility of every observed frame. However, due to the highly correlated samples induced by the streaming regime, naively applying this auxiliary loss results in training instabilities. Thus, we introduce orthogonal gradient updates relative to the momentum target and resolve gradient conflicts arising from streaming-specific optimizers. Validated across the Atari, MinAtar, and Octax suites, our approach systematically outperforms existing streaming baselines. Latent-space analysis, including t-SNE visualizations and effective-rank measurements, confirms that our method learns significantly richer representations, bridging the performance gap caused by the absence of a replay buffer, while remaining efficient enough to train on just a few CPU cores.
BRIDGE: Predicting Human Task Completion Time From Model Performance
Feb 06, 2026Evaluating the real-world capabilities of AI systems requires grounding benchmark performance in human-interpretable measures of task difficulty. Existing approaches that rely on direct human task completion time annotations are costly, noisy, and difficult to scale across benchmarks. In this work, we propose BRIDGE, a unified psychometric framework that learns the latent difficulty scale from model responses and anchors it to human task completion time. Using a two-parameter logistic Item Response Theory model, we jointly estimate latent task difficulty and model capability from model performance data across multiple benchmarks. We demonstrate that latent task difficulty varies linearly with the logarithm of human completion time, allowing human task completion time to be inferred for new benchmarks from model performance alone. Leveraging this alignment, we forecast frontier model capabilities in terms of human task length and independently reproduce METR's exponential scaling results, with the 50% solvable task horizon doubling approximately every 6 months.
Barrier Functions Inspired Reward Shaping for Reinforcement Learning
Mar 03, 2024
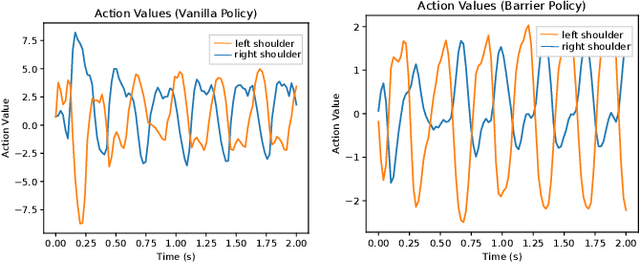
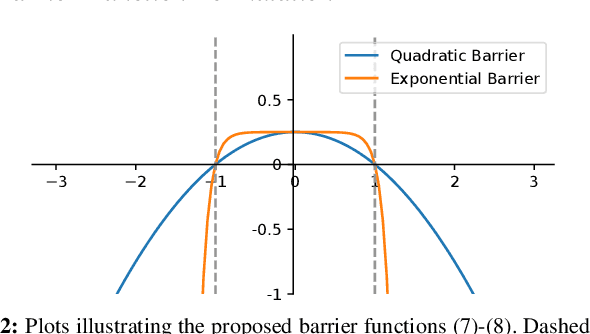
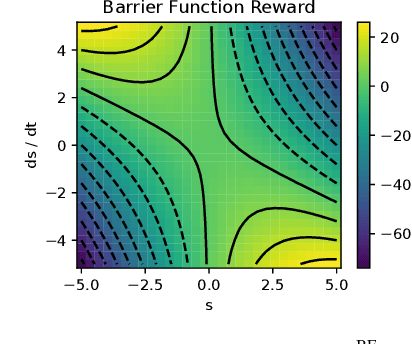
Reinforcement Learning (RL) has progressed from simple control tasks to complex real-world challenges with large state spaces. While RL excels in these tasks, training time remains a limitation. Reward shaping is a popular solution, but existing methods often rely on value functions, which face scalability issues. This paper presents a novel safety-oriented reward-shaping framework inspired by barrier functions, offering simplicity and ease of implementation across various environments and tasks. To evaluate the effectiveness of the proposed reward formulations, we conduct simulation experiments on CartPole, Ant, and Humanoid environments, along with real-world deployment on the Unitree Go1 quadruped robot. Our results demonstrate that our method leads to 1.4-2.8 times faster convergence and as low as 50-60% actuation effort compared to the vanilla reward. In a sim-to-real experiment with the Go1 robot, we demonstrated better control and dynamics of the bot with our reward framework.