 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Place-Based Compromises Between Two Points of View
Apr 27, 2026Large Language Models (LLMs) excel academically but struggle with social intelligence tasks, such as creating good compromises. In this paper, we present methods for generating empathically neutral compromises between two opposing viewpoints. We first compared four different prompt engineering methods using Claude 3 Opus and a dataset of 2,400 contrasting views on shared places. A subset of the gen erated compromises was evaluated for acceptability in a 50-participant study. We found that the best method for generating compromises between two views used external empathic similarity between a compromise and each viewpoint as iterative feedback, outperforming stan dard Chain of Thought (CoT) reasoning. The results indicate that the use of empathic neutrality improves the acceptability of compromises. The dataset of generated compromises was then used to train two smaller foundation models via margin-based alignment of human preferences, improving efficiency and removing the need for empathy estimation during inference.
Training Towards Critical Use: Learning to Situate AI Predictions Relative to Human Knowledge
Aug 30, 2023
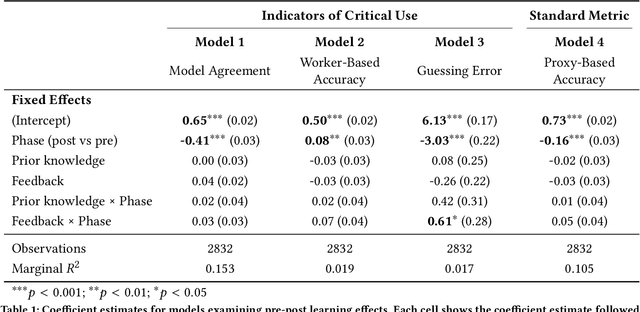
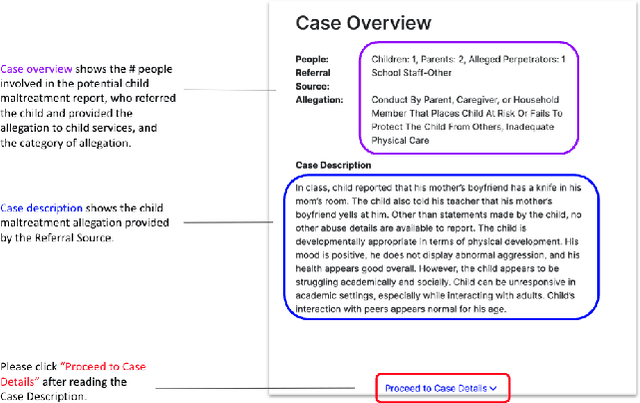
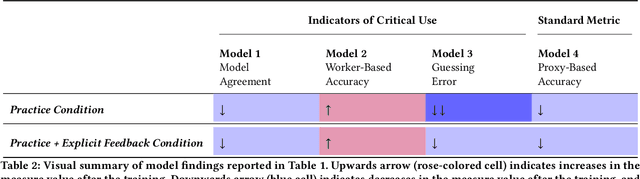
A growing body of research has explored how to support humans in making better use of AI-based decision support, including via training and onboarding. Existing research has focused on decision-making tasks where it is possible to evaluate "appropriate reliance" by comparing each decision against a ground truth label that cleanly maps to both the AI's predictive target and the human decision-maker's goals. However, this assumption does not hold in many real-world settings where AI tools are deployed today (e.g., social work, criminal justice, and healthcare). In this paper, we introduce a process-oriented notion of appropriate reliance called critical use that centers the human's ability to situate AI predictions against knowledge that is uniquely available to them but unavailable to the AI model. To explore how training can support critical use, we conduct a randomized online experiment in a complex social decision-making setting: child maltreatment screening. We find that, by providing participants with accelerated, low-stakes opportunities to practice AI-assisted decision-making in this setting, novices came to exhibit patterns of disagreement with AI that resemble those of experienced workers. A qualitative examination of participants' explanations for their AI-assisted decisions revealed that they drew upon qualitative case narratives, to which the AI model did not have access, to learn when (not) to rely on AI predictions. Our findings open new questions for the study and design of training for real-world AI-assisted decision-making.