 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif Prediction with Graph Neural Networks
Jun 05, 2021
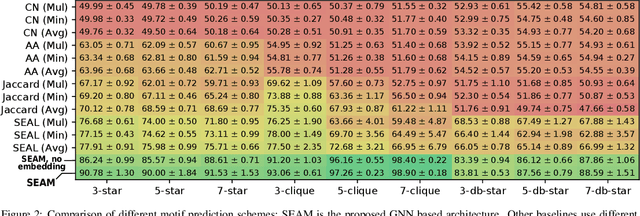
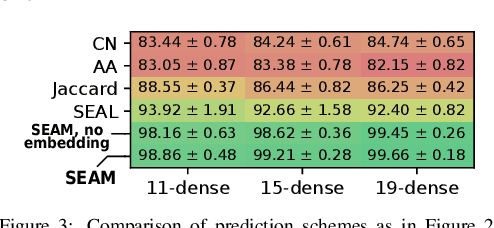
Link prediction is one of the central problems in graph mining. However, recent studies highlight the importance of higher-order network analysis, where complex structures called motifs are the first-class citizens. We first show that existing link prediction schemes fail to effectively predict motifs. To alleviate this, we establish a general motif prediction problem and we propose several heuristics that assess the chances for a specified motif to appear. To make the scores realistic, our heuristics consider - among others - correlations between links, i.e., the potential impact of some arriving links on the appearance of other links in a given motif. Finally, for highest accuracy, we develop a graph neural network (GNN) architecture for motif prediction. Our architecture offers vertex features and sampling schemes that capture the rich structural properties of motifs. While our heuristics are fast and do not need any training, GNNs ensure highest accuracy of predicting motifs, both for dense (e.g., k-cliques) and for sparse ones (e.g., k-stars). We consistently outperform the best available competitor by more than 10% on average and up to 32% in area under the curve. Importantly, the advantages of our approach over schemes based on uncorrelated link prediction increase with the increasing motif size and complexity. We also successfully apply our architecture for predicting more arbitrary clusters and communities, illustrating its potential for graph mining beyond motif analysis.
Sparsity in Deep Learning: Pruning and growth for efficient inference and training in neural networks
Jan 31, 2021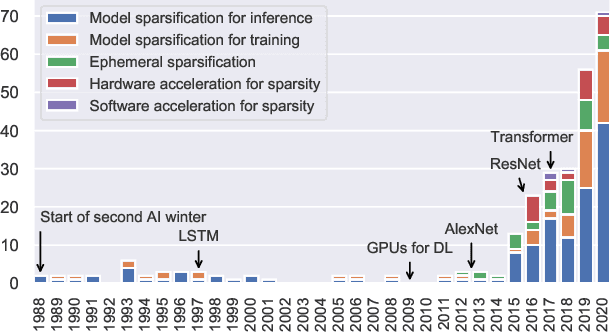
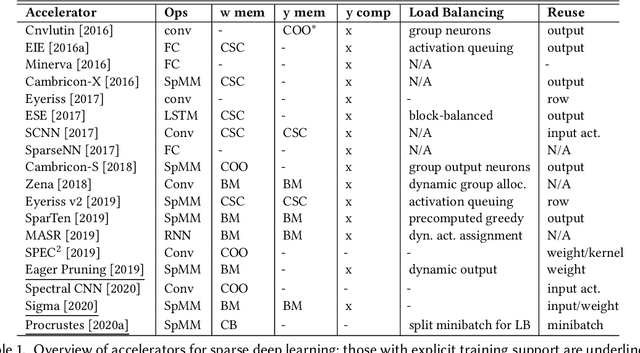
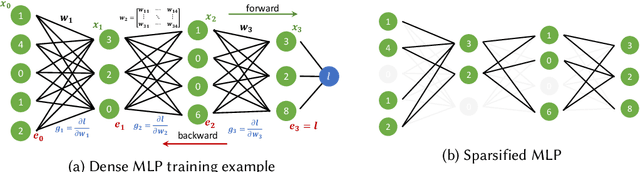
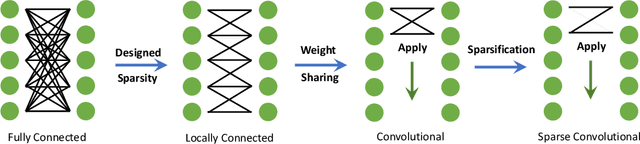
The growing energy and performance costs of deep learning have driven the community to reduce the size of neural networks by selectively pruning components. Similarly to their biological counterparts, sparse networks generalize just as well, if not better than, the original dense networks. Sparsity can reduce the memory footprint of regular networks to fit mobile devices, as well as shorten training time for ever growing networks. In this paper, we survey prior work on sparsity in deep learning and provide an extensive tutorial of sparsification for both inference and training. We describe approaches to remove and add elements of neural networks, different training strategies to achieve model sparsity, and mechanisms to exploit sparsity in practice. Our work distills ideas from more than 300 research papers and provides guidance to practitioners who wish to utilize sparsity today, as well as to researchers whose goal is to push the frontier forward. We include the necessary background on mathematical methods in sparsification, describe phenomena such as early structure adaptation, the intricate relations between sparsity and the training process, and show techniques for achieving acceleration on real hardware. We also define a metric of pruned parameter efficiency that could serve as a baseline for comparison of different sparse networks. We close by speculating on how sparsity can improve future workloads and outline major open problems in the field.
Clairvoyant Prefetching for Distributed Machine Learning I/O
Jan 21, 2021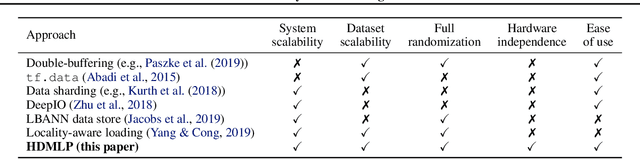
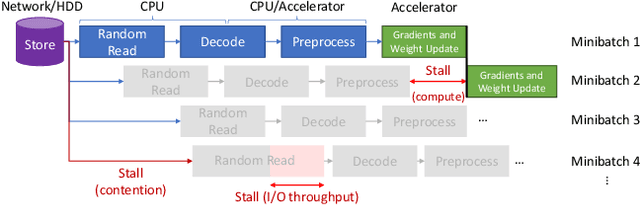
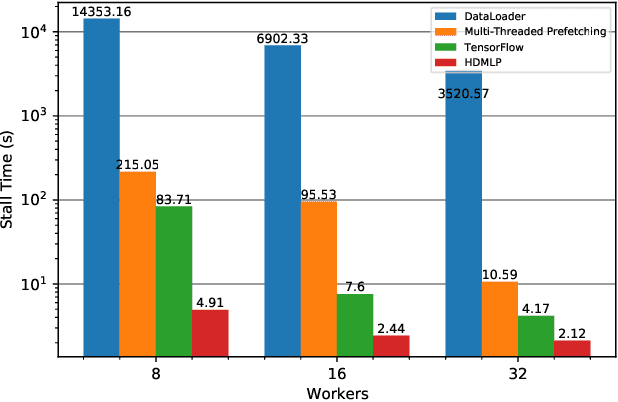
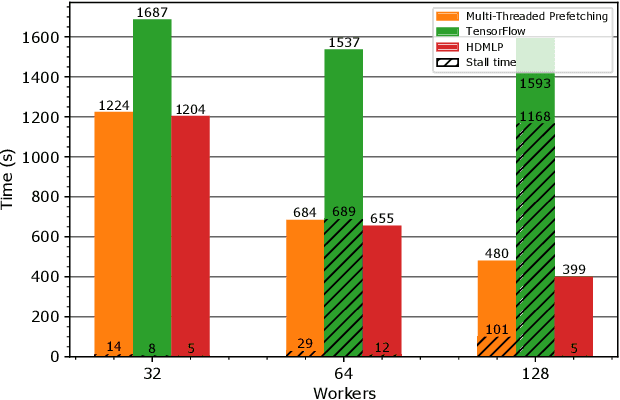
I/O is emerging as a major bottleneck for machine learning training, especially in distributed environments such as clouds and supercomputers. Optimal data ingestion pipelines differ between systems, and increasing efficiency requires a delicate balance between access to local storage, external filesystems, and remote workers; yet existing frameworks fail to efficiently utilize such resources. We observe that, given the seed generating the random access pattern for training with SGD, we have clairvoyance and can exactly predict when a given sample will be accessed. We combine this with a theoretical analysis of access patterns in training and performance modeling to produce a novel machine learning I/O middleware, HDMLP, to tackle the I/O bottleneck. HDMLP provides an easy-to-use, flexible, and scalable solution that delivers better performance than state-of-the-art approaches while requiring very few changes to existing codebases and supporting a broad range of environments.
The Case for Strong Scaling in Deep Learning: Training Large 3D CNNs with Hybrid Parallelism
Jul 25, 2020We present scalable hybrid-parallel algorithms for training large-scale 3D convolutional neural networks. Deep learning-based emerging scientific workflows often require model training with large, high-dimensional samples, which can make training much more costly and even infeasible due to excessive memory usage. We solve these challenges by extensively applying hybrid parallelism throughout the end-to-end training pipeline, including both computations and I/O. Our hybrid-parallel algorithm extends the standard data parallelism with spatial parallelism, which partitions a single sample in the spatial domain, realizing strong scaling beyond the mini-batch dimension with a larger aggregated memory capacity. We evaluate our proposed training algorithms with two challenging 3D CNNs, CosmoFlow and 3D U-Net. Our comprehensive performance studies show that good weak and strong scaling can be achieved for both networks using up 2K GPUs. More importantly, we enable training of CosmoFlow with much larger samples than previously possible, realizing an order-of-magnitude improvement in prediction accuracy.
Data Movement Is All You Need: A Case Study on Optimizing Transformers
Jul 02, 2020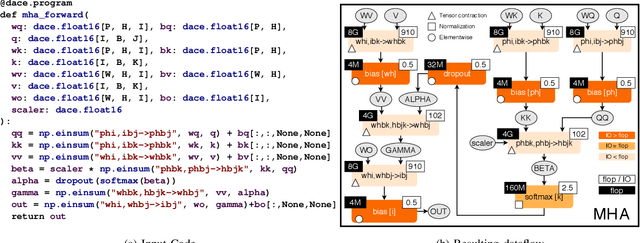
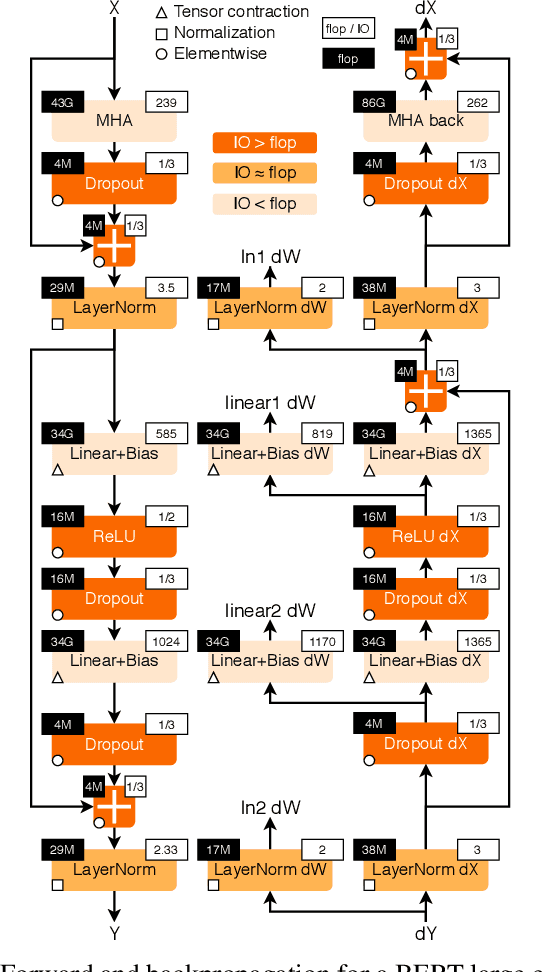
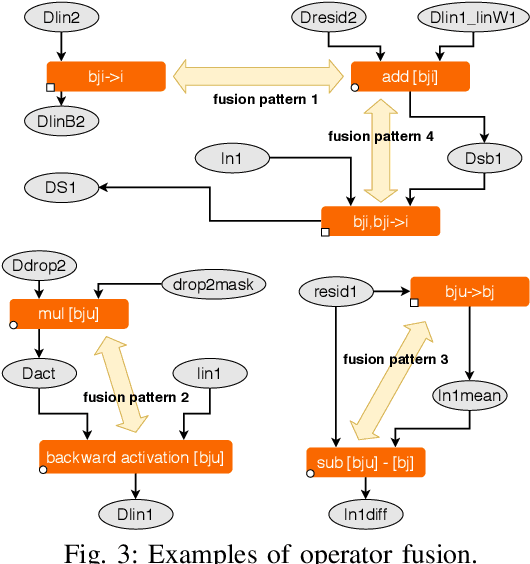
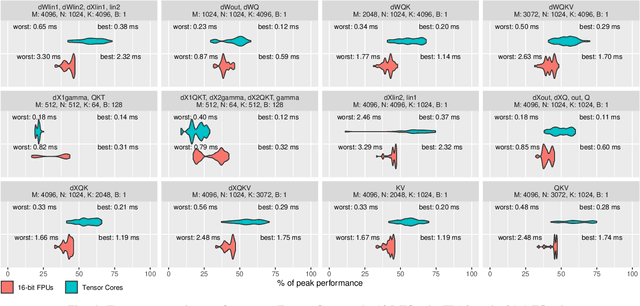
Transformers have become widely used for language modeling and sequence learning tasks, and are one of the most important machine learning workloads today. Training one is a very compute-intensive task, often taking days or weeks, and significant attention has been given to optimizing transformers. Despite this, existing implementations do not efficiently utilize GPUs. We find that data movement is the key bottleneck when training. Due to Amdahl's Law and massive improvements in compute performance, training has now become memory-bound. Further, existing frameworks use suboptimal data layouts. Using these insights, we present a recipe for globally optimizing data movement in transformers. We reduce data movement by up to 22.91% and overall achieve a 1.30x performance improvement over state-of-the-art frameworks when training BERT. Our approach is applicable more broadly to optimizing deep neural networks, and offers insight into how to tackle emerging performance bottlenecks.
Shapeshifter Networks: Cross-layer Parameter Sharing for Scalable and Effective Deep Learning
Jun 18, 2020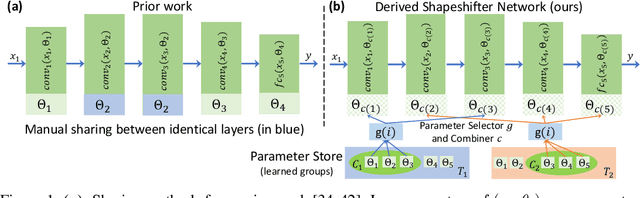
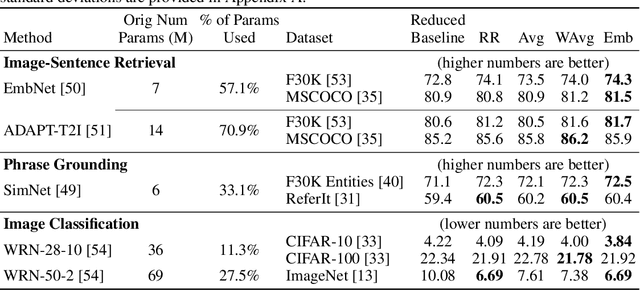
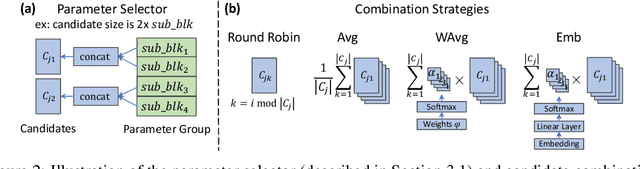
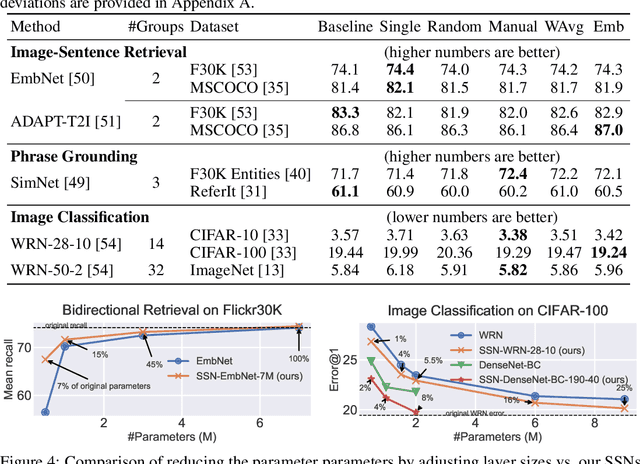
We present Shapeshifter Networks (SSNs), a flexible neural network framework that improves performance and reduces memory requirements on a diverse set of scenarios over standard neural networks. Our approach is based on the observation that many neural networks are severely overparameterized, resulting in significant waste in computational resources as well as being susceptible to overfitting. SSNs address this by learning where and how to share parameters between layers in a neural network while avoiding degenerate solutions that result in underfitting. Specifically, we automatically construct parameter groups that identify where parameter sharing is most beneficial. Then, we map each group's weights to construct layers with learned combinations of candidates from a shared parameter pool. SSNs can share parameters across layers even when they have different sizes, perform different operations, and/or operate on features from different modalities. We evaluate our approach on a diverse set of tasks, including image classification, bidirectional image-sentence retrieval, and phrase grounding, creating high performing models even when using as little as 1% of the parameters. We also apply SSNs to knowledge distillation, where we obtain state-of-the-art results when combined with traditional distillation methods.
Deep Learning for Post-Processing Ensemble Weather Forecasts
May 18, 2020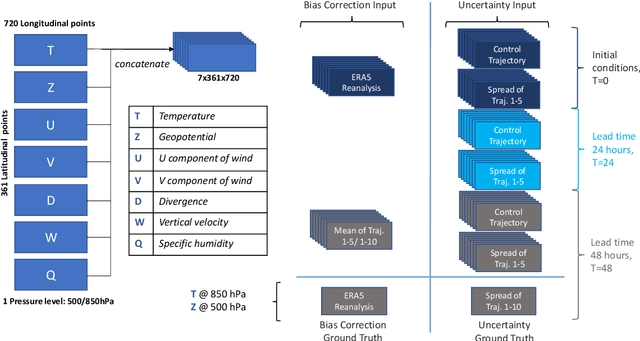

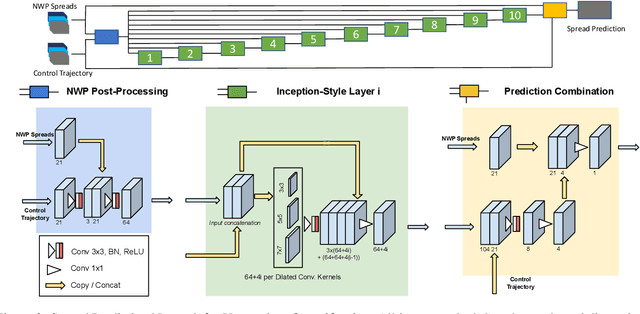

Quantifying uncertainty in weather forecasts typically employs ensemble prediction systems, which consist of many perturbed trajectories run in parallel. These systems are associated with a high computational cost and often include statistical post-processing steps to inexpensively improve their raw prediction qualities. We propose a mixed prediction and post-processing model based on a subset of the original trajectories. In the model, we implement methods from deep learning to account for non-linear relationships that are not captured by current numerical models or other post-processing methods. Applied to global data, our mixed models achieve a relative improvement of the ensemble forecast skill of over 13%. We demonstrate that this is especially the case for extreme weather events on selected case studies, where we see an improvement in predictions by up to 26%. In addition, by using only half the trajectories, the computational costs of ensemble prediction systems can potentially be reduced, allowing weather forecasting pipelines to run higher resolution trajectories, and resulting in even more accurate raw ensemble forecasts.
Breaking (Global) Barriers in Parallel Stochastic Optimization with Wait-Avoiding Group Averaging
Apr 30, 2020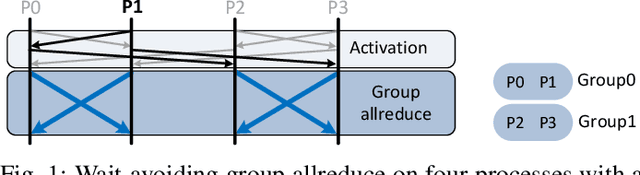
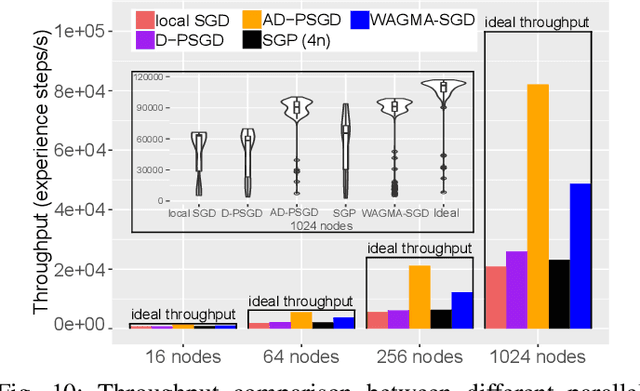
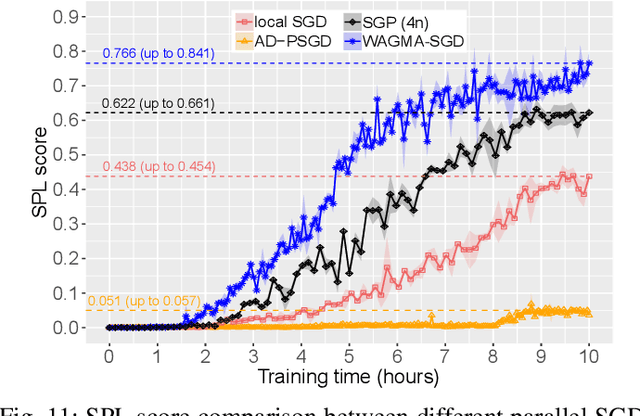
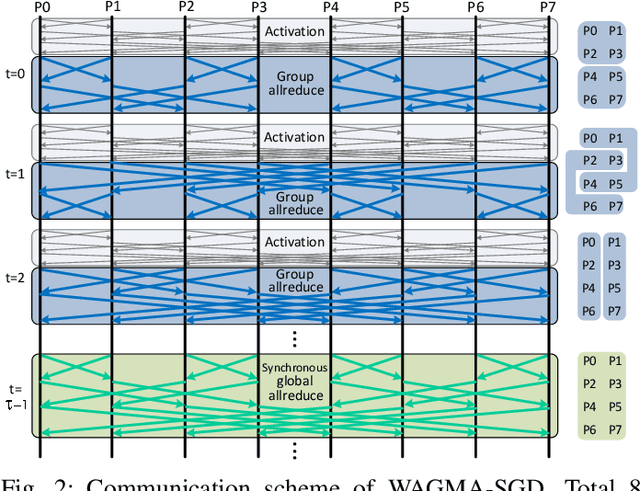
Deep learning at scale is dominated by communication time. Distributing samples across nodes usually yields the best performance, but poses scaling challenges due to global information dissemination and load imbalance across uneven sample lengths. State-of-the-art decentralized optimizers mitigate the problem, but require more iterations to achieve the same accuracy as their globally-communicating counterparts. We present Wait-Avoiding Group Model Averaging (WAGMA) SGD, a wait-avoiding stochastic optimizer that reduces global communication via subgroup weight exchange. The key insight is a combination of algorithmic changes to the averaging scheme and the use of a group allreduce operation. We prove the convergence of WAGMA-SGD, and empirically show that it retains convergence rates equivalent to Allreduce-SGD. For evaluation, we train ResNet-50 on ImageNet; Transformer for machine translation; and deep reinforcement learning for navigation at scale. Compared with state-of-the-art decentralized SGD, WAGMA-SGD significantly improves training throughput (by 2.1x on 1,024 GPUs) and achieves the fastest time-to-solution.
Predicting Weather Uncertainty with Deep Convnets
Dec 04, 2019
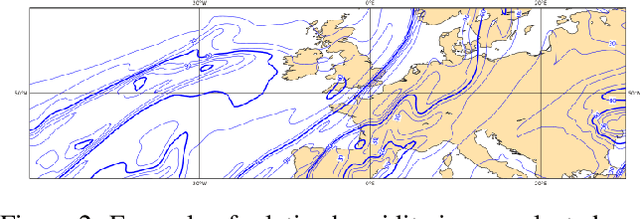
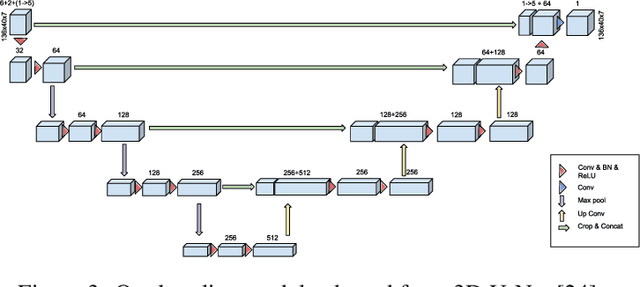
Modern weather forecast models perform uncertainty quantification using ensemble prediction systems, which collect nonparametric statistics based on multiple perturbed simulations. To provide accurate estimation, dozens of such computationally intensive simulations must be run. We show that deep neural networks can be used on a small set of numerical weather simulations to estimate the spread of a weather forecast, significantly reducing computational cost. To train the system, we both modify the 3D U-Net architecture and explore models that incorporate temporal data. Our models serve as a starting point to improve uncertainty quantification in current real-time weather forecasting systems, which is vital for predicting extreme events.
Improving Strong-Scaling of CNN Training by Exploiting Finer-Grained Parallelism
Mar 15, 2019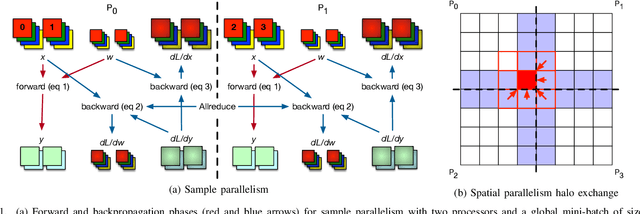
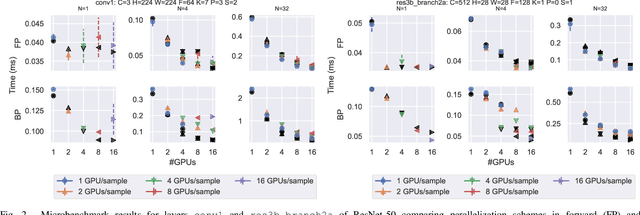
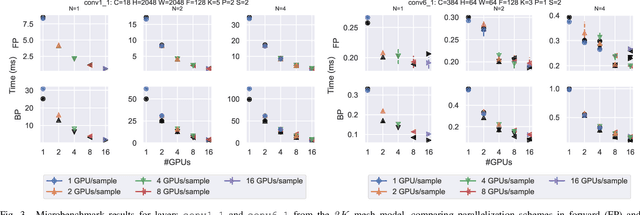
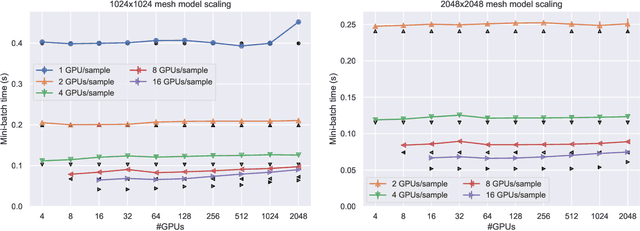
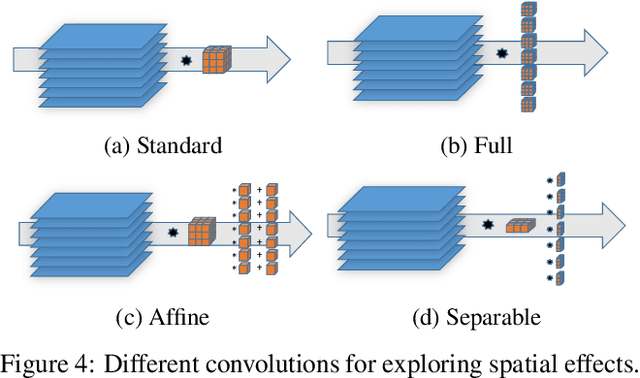
Scaling CNN training is necessary to keep up with growing datasets and reduce training time. We also see an emerging need to handle datasets with very large samples, where memory requirements for training are large. Existing training frameworks use a data-parallel approach that partitions samples within a mini-batch, but limits to scaling the mini-batch size and memory consumption makes this untenable for large samples. We describe and implement new approaches to convolution, which parallelize using spatial decomposition or a combination of sample and spatial decomposition. This introduces many performance knobs for a network, so we develop a performance model for CNNs and present a method for using it to automatically determine efficient parallelization strategies. We evaluate our algorithms with microbenchmarks and image classification with ResNet-50. Our algorithms allow us to prototype a model for a mesh-tangling dataset, where sample sizes are very large. We show that our parallelization achieves excellent strong and weak scaling and enables training for previously unreachable datasets.