 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Object Detection with Transformers
May 28, 2020
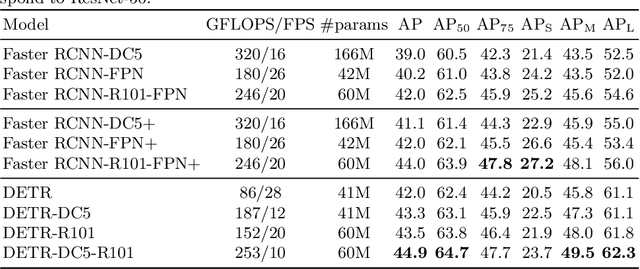
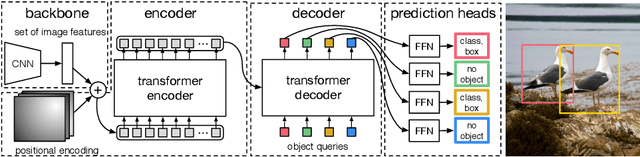
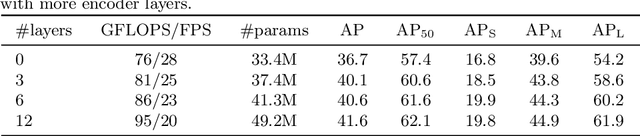
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive baselines. Training code and pretrained models are available at https://github.com/facebookresearch/detr.
Learning Adaptive Exploration Strategies in Dynamic Environments Through Informed Policy Regularization
May 06, 2020

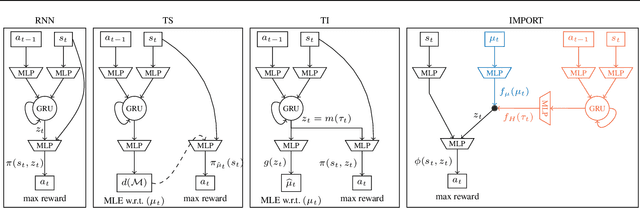
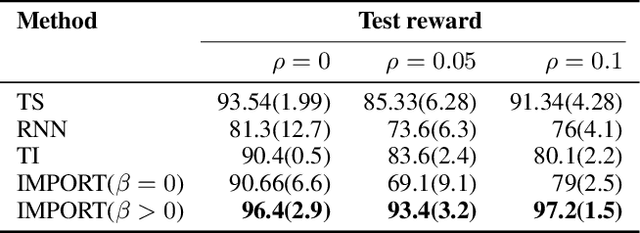
We study the problem of learning exploration-exploitation strategies that effectively adapt to dynamic environments, where the task may change over time. While RNN-based policies could in principle represent such strategies, in practice their training time is prohibitive and the learning process often converges to poor solutions. In this paper, we consider the case where the agent has access to a description of the task (e.g., a task id or task parameters) at training time, but not at test time. We propose a novel algorithm that regularizes the training of an RNN-based policy using informed policies trained to maximize the reward in each task. This dramatically reduces the sample complexity of training RNN-based policies, without losing their representational power. As a result, our method learns exploration strategies that efficiently balance between gathering information about the unknown and changing task and maximizing the reward over time. We test the performance of our algorithm in a variety of environments where tasks may vary within each episode.
Tensor Decompositions for temporal knowledge base completion
Apr 10, 2020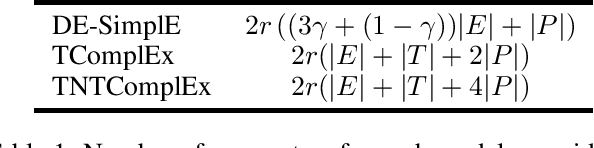
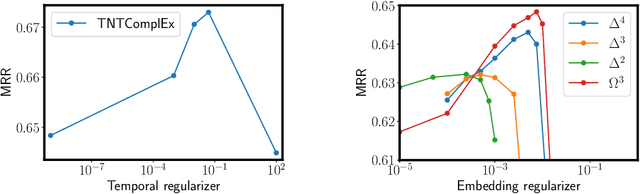
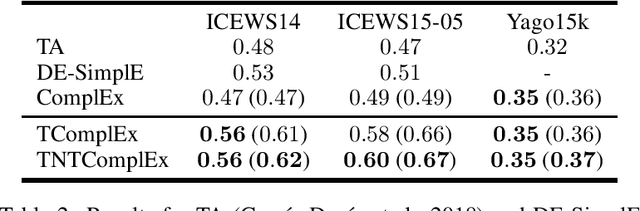
Most algorithms for representation learning and link prediction in relational data have been designed for static data. However, the data they are applied to usually evolves with time, such as friend graphs in social networks or user interactions with items in recommender systems. This is also the case for knowledge bases, which contain facts such as (US, has president, B. Obama, [2009-2017]) that are valid only at certain points in time. For the problem of link prediction under temporal constraints, i.e., answering queries such as (US, has president, ?, 2012), we propose a solution inspired by the canonical decomposition of tensors of order 4. We introduce new regularization schemes and present an extension of ComplEx (Trouillon et al., 2016) that achieves state-of-the-art performance. Additionally, we propose a new dataset for knowledge base completion constructed from Wikidata, larger than previous benchmarks by an order of magnitude, as a new reference for evaluating temporal and non-temporal link prediction methods.
On the Convergence of Adam and Adagrad
Mar 05, 2020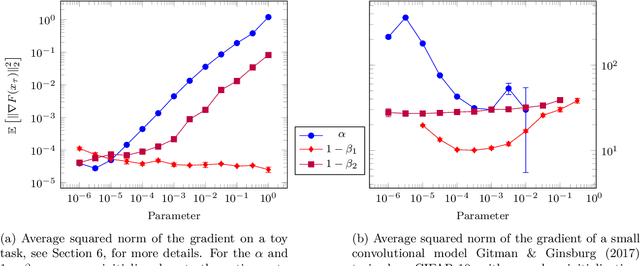
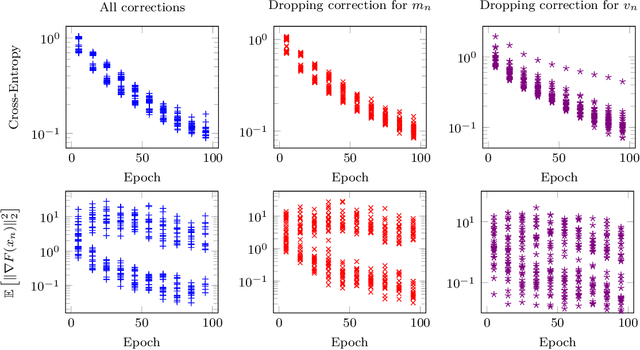
We provide a simple proof of the convergence of the optimization algorithms Adam and Adagrad with the assumptions of smooth gradients and almost sure uniform bound on the $\ell_\infty$ norm of the gradients. This work builds on the techniques introduced by Ward et al. (2019) and extends them to the Adam optimizer. We show that in expectation, the squared norm of the objective gradient averaged over the trajectory has an upper-bound which is explicit in the constants of the problem, parameters of the optimizer and the total number of iterations N. This bound can be made arbitrarily small. In particular, Adam with a learning rate $\alpha=1/\sqrt{N}$ and a momentum parameter on squared gradients $\beta_2=1 - 1/N$ achieves the same rate of convergence $O(\ln(N)/\sqrt{N})$ as Adagrad. Thus, it is possible to use Adam as a finite horizon version of Adagrad, much like constant step size SGD can be used instead of its asymptotically converging decaying step size version.
Music Source Separation in the Waveform Domain
Nov 27, 2019



Source separation for music is the task of isolating contributions, or stems, from different instruments recorded individually and arranged together to form a song. Such components include voice, bass, drums and any other accompaniments. Contrarily to many audio synthesis tasks where the best performances are achieved by models that directly generate the waveform, the state-of-the-art in source separation for music is to compute masks on the magnitude spectrum. In this paper, we first show that an adaptation of Conv-Tasnet (Luo \& Mesgarani, 2019), a waveform-to-waveform model for source separation for speech, significantly beats the state-of-the-art on the MusDB dataset, the standard benchmark of multi-instrument source separation. Second, we observe that Conv-Tasnet follows a masking approach on the input signal, which has the potential drawback of removing parts of the relevant source without the capacity to reconstruct it. We propose Demucs, a new waveform-to-waveform model, which has an architecture closer to models for audio generation with more capacity on the decoder. Experiments on the MusDB dataset show that Demucs beats previously reported results in terms of signal to distortion ratio (SDR), but lower than Conv-Tasnet. Human evaluations show that Demucs has significantly higher quality (as assessed by mean opinion score) than Conv-Tasnet, but slightly more contamination from other sources, which explains the difference in SDR. Additional experiments with a larger dataset suggest that the gap in SDR between Demucs and Conv-Tasnet shrinks, showing that our approach is promising.
A Structured Prediction Approach for Generalization in Cooperative Multi-Agent Reinforcement Learning
Oct 19, 2019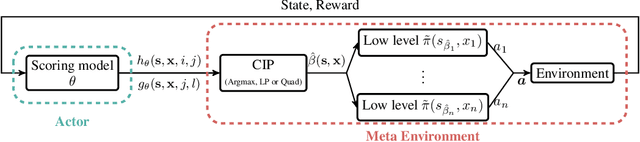
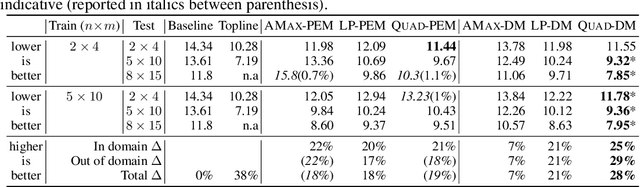
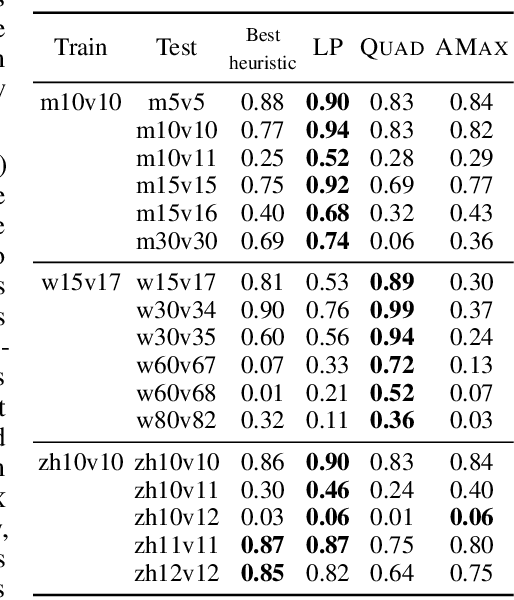
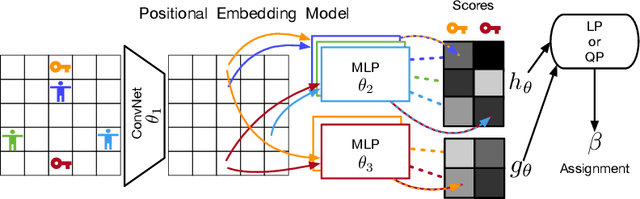
Effective coordination is crucial to solve multi-agent collaborative (MAC) problems. While centralized reinforcement learning methods can optimally solve small MAC instances, they do not scale to large problems and they fail to generalize to scenarios different from those seen during training. In this paper, we consider MAC problems with some intrinsic notion of locality (e.g., geographic proximity) such that interactions between agents and tasks are locally limited. By leveraging this property, we introduce a novel structured prediction approach to assign agents to tasks. At each step, the assignment is obtained by solving a centralized optimization problem (the inference procedure) whose objective function is parameterized by a learned scoring model. We propose different combinations of inference procedures and scoring models able to represent coordination patterns of increasing complexity. The resulting assignment policy can be efficiently learned on small problem instances and readily reused in problems with more agents and tasks (i.e., zero-shot generalization). We report experimental results on a toy search and rescue problem and on several target selection scenarios in StarCraft: Brood War, in which our model significantly outperforms strong rule-based baselines on instances with 5 times more agents and tasks than those seen during training.
Demucs: Deep Extractor for Music Sources with extra unlabeled data remixed
Sep 03, 2019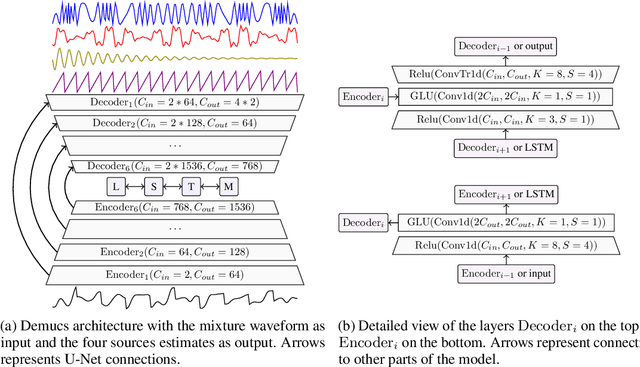
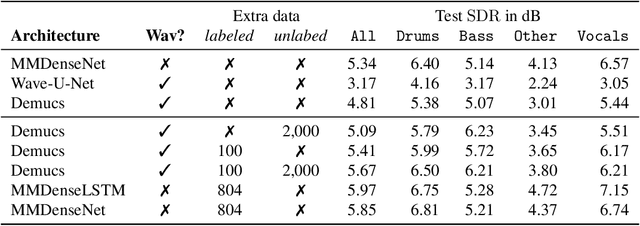
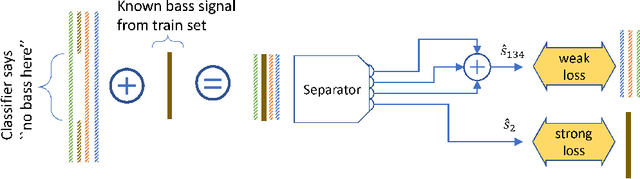
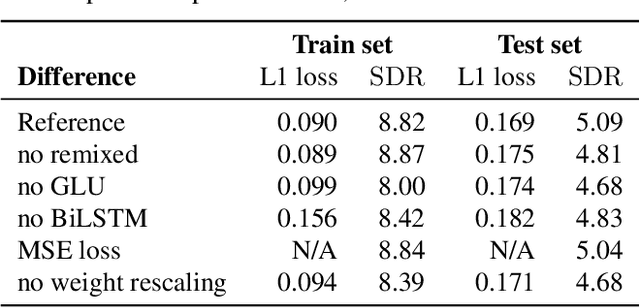
We study the problem of source separation for music using deep learning with four known sources: drums, bass, vocals and other accompaniments. State-of-the-art approaches predict soft masks over mixture spectrograms while methods working on the waveform are lagging behind as measured on the standard MusDB benchmark. Our contribution is two fold. (i) We introduce a simple convolutional and recurrent model that outperforms the state-of-the-art model on waveforms, that is, Wave-U-Net, by 1.6 points of SDR (signal to distortion ratio). (ii) We propose a new scheme to leverage unlabeled music. We train a first model to extract parts with at least one source silent in unlabeled tracks, for instance without bass. We remix this extract with a bass line taken from the supervised dataset to form a new weakly supervised training example. Combining our architecture and scheme, we show that waveform methods can play in the same ballpark as spectrogram ones.
Growing Action Spaces
Jun 28, 2019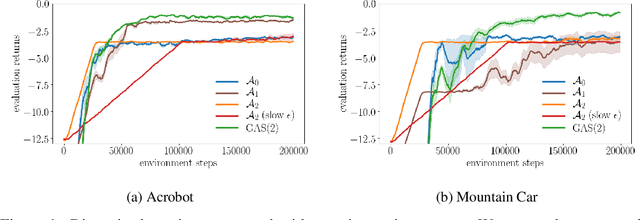
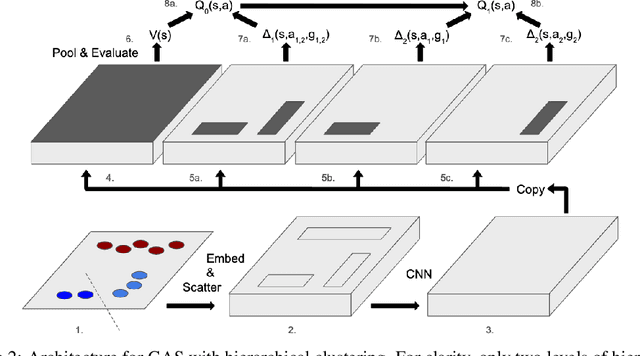
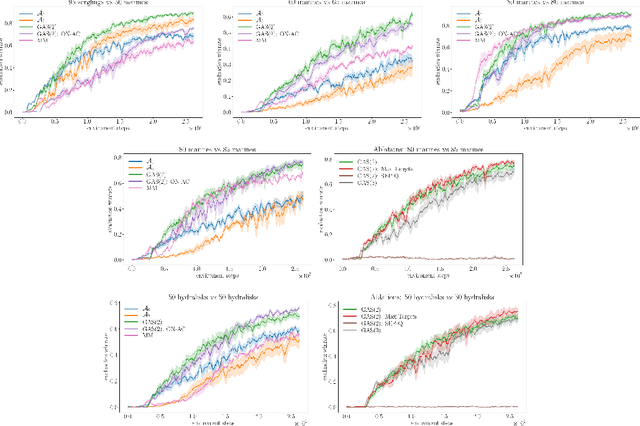

In complex tasks, such as those with large combinatorial action spaces, random exploration may be too inefficient to achieve meaningful learning progress. In this work, we use a curriculum of progressively growing action spaces to accelerate learning. We assume the environment is out of our control, but that the agent may set an internal curriculum by initially restricting its action space. Our approach uses off-policy reinforcement learning to estimate optimal value functions for multiple action spaces simultaneously and efficiently transfers data, value estimates, and state representations from restricted action spaces to the full task. We show the efficacy of our approach in proof-of-concept control tasks and on challenging large-scale StarCraft micromanagement tasks with large, multi-agent action spaces.
Fully Convolutional Speech Recognition
Dec 17, 2018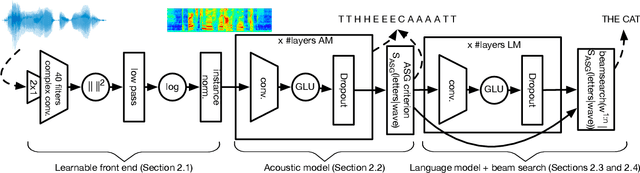

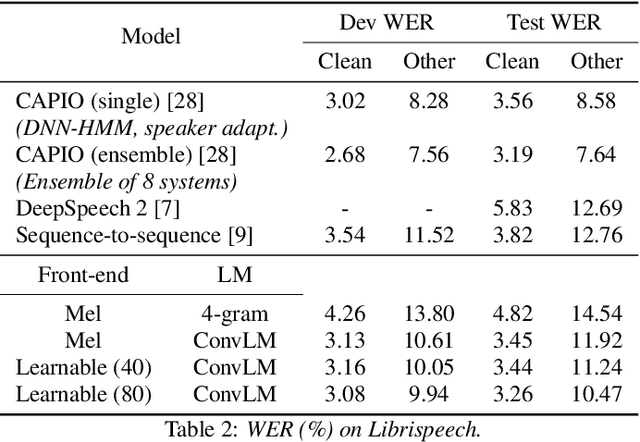
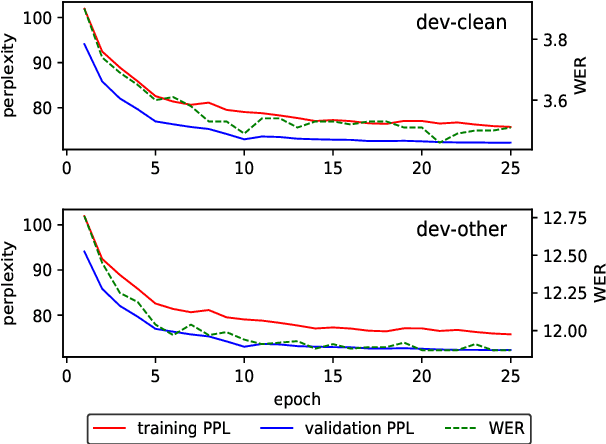
Current state-of-the-art speech recognition systems build on recurrent neural networks for acoustic and/or language modeling, and rely on feature extraction pipelines to extract mel-filterbanks or cepstral coefficients. In this paper we present an alternative approach based solely on convolutional neural networks, leveraging recent advances in acoustic models from the raw waveform and language modeling. This fully convolutional approach is trained end-to-end to predict characters from the raw waveform, removing the feature extraction step altogether. An external convolutional language model is used to decode words. On Wall Street Journal, our model matches the current state-of-the-art. On Librispeech, we report state-of-the-art performance among end-to-end models, including Deep Speech 2 trained with 12 times more acoustic data and significantly more linguistic data.
To Reverse the Gradient or Not: An Empirical Comparison of Adversarial and Multi-task Learning in Speech Recognition
Dec 13, 2018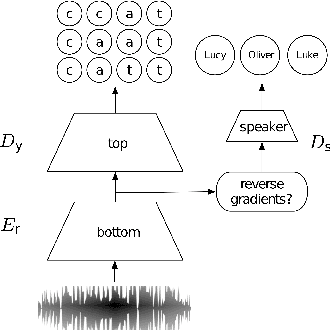
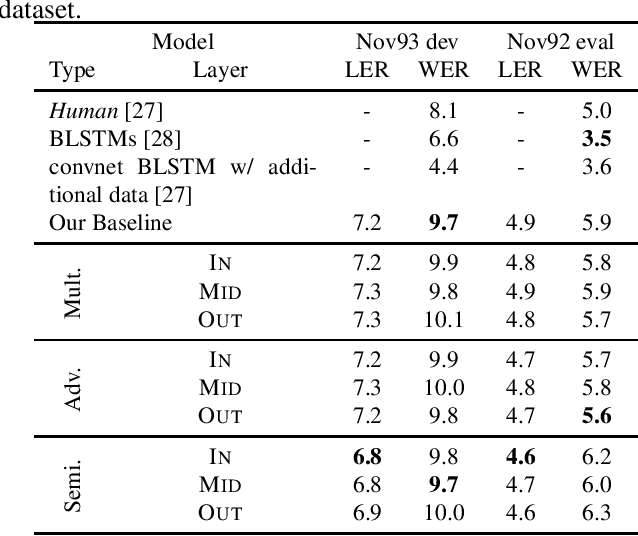
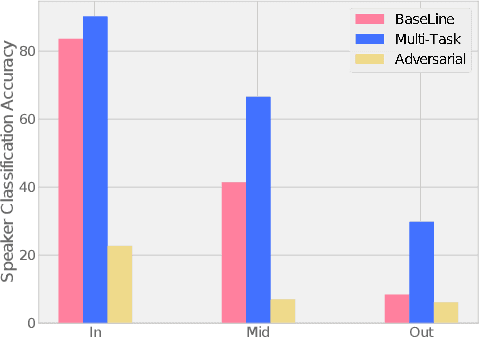
Transcribed datasets typically contain speaker identity for each instance in the data. We investigate two ways to incorporate this information during training: Multi-Task Learning and Adversarial Learning. In multi-task learning, the goal is speaker prediction; we expect a performance improvement with this joint training if the two tasks of speech recognition and speaker recognition share a common set of underlying features. In contrast, adversarial learning is a means to learn representations invariant to the speaker. We then expect better performance if this learnt invariance helps generalizing to new speakers. While the two approaches seem natural in the context of speech recognition, they are incompatible because they correspond to opposite gradients back-propagated to the model. In order to better understand the effect of these approaches in terms of error rates, we compare both strategies in controlled settings. Moreover, we explore the use of additional untranscribed data in a semi-supervised, adversarial learning manner to improve error rates. Our results show that deep models trained on big datasets already develop invariant representations to speakers without any auxiliary loss. When considering adversarial learning and multi-task learning, the impact on the acoustic model seems minor. However, models trained in a semi-supervised manner can improve error-rates.