 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast online ranking with fairness of exposure
Sep 13, 2022
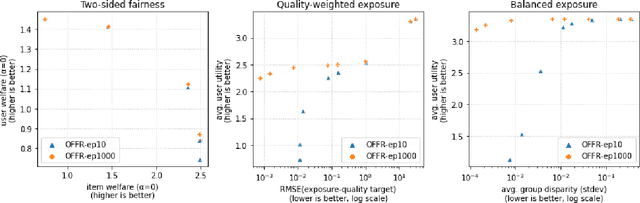
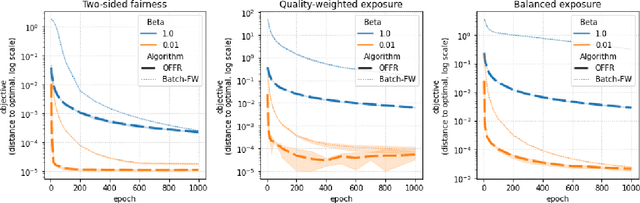
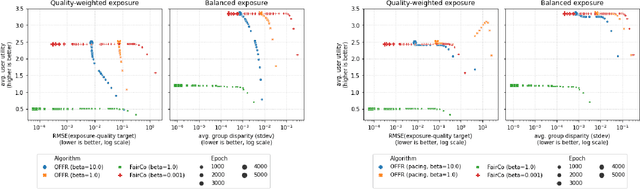
As recommender systems become increasingly central for sorting and prioritizing the content available online, they have a growing impact on the opportunities or revenue of their items producers. For instance, they influence which recruiter a resume is recommended to, or to whom and how much a music track, video or news article is being exposed. This calls for recommendation approaches that not only maximize (a proxy of) user satisfaction, but also consider some notion of fairness in the exposure of items or groups of items. Formally, such recommendations are usually obtained by maximizing a concave objective function in the space of randomized rankings. When the total exposure of an item is defined as the sum of its exposure over users, the optimal rankings of every users become coupled, which makes the optimization process challenging. Existing approaches to find these rankings either solve the global optimization problem in a batch setting, i.e., for all users at once, which makes them inapplicable at scale, or are based on heuristics that have weak theoretical guarantees. In this paper, we propose the first efficient online algorithm to optimize concave objective functions in the space of rankings which applies to every concave and smooth objective function, such as the ones found for fairness of exposure. Based on online variants of the Frank-Wolfe algorithm, we show that our algorithm is computationally fast, generating rankings on-the-fly with computation cost dominated by the sort operation, memory efficient, and has strong theoretical guarantees. Compared to baseline policies that only maximize user-side performance, our algorithm allows to incorporate complex fairness of exposure criteria in the recommendations with negligible computational overhead.
Measuring and signing fairness as performance under multiple stakeholder distributions
Jul 20, 2022As learning machines increase their influence on decisions concerning human lives, analyzing their fairness properties becomes a subject of central importance. Yet, our best tools for measuring the fairness of learning systems are rigid fairness metrics encapsulated as mathematical one-liners, offer limited power to the stakeholders involved in the prediction task, and are easy to manipulate when we exhort excessive pressure to optimize them. To advance these issues, we propose to shift focus from shaping fairness metrics to curating the distributions of examples under which these are computed. In particular, we posit that every claim about fairness should be immediately followed by the tagline "Fair under what examples, and collected by whom?". By highlighting connections to the literature in domain generalization, we propose to measure fairness as the ability of the system to generalize under multiple stress tests -- distributions of examples with social relevance. We encourage each stakeholder to curate one or multiple stress tests containing examples reflecting their (possibly conflicting) interests. The machine passes or fails each stress test by falling short of or exceeding a pre-defined metric value. The test results involve all stakeholders in a discussion about how to improve the learning system, and provide flexible assessments of fairness dependent on context and based on interpretable data. We provide full implementation guidelines for stress testing, illustrate both the benefits and shortcomings of this framework, and introduce a cryptographic scheme to enable a degree of prediction accountability from system providers.
Optimizing generalized Gini indices for fairness in rankings
Apr 14, 2022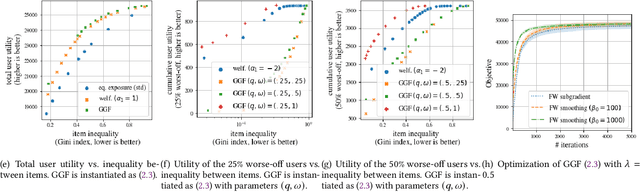
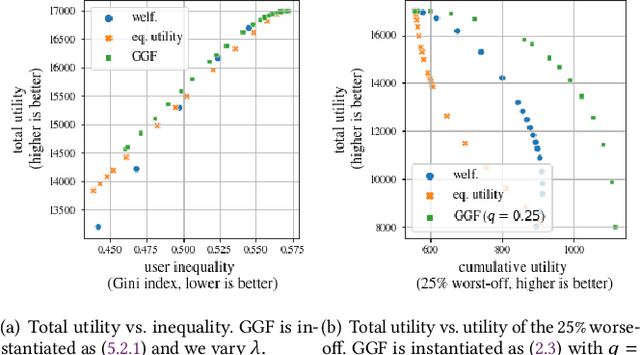
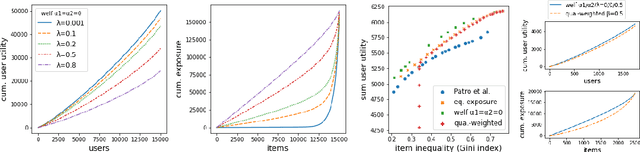
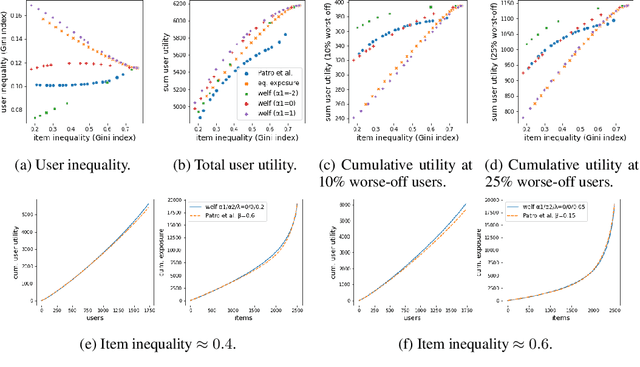
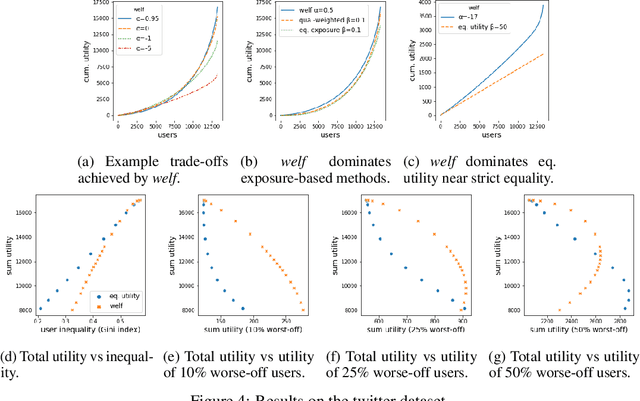
There is growing interest in designing recommender systems that aim at being fair towards item producers or their least satisfied users. Inspired by the domain of inequality measurement in economics, this paper explores the use of generalized Gini welfare functions (GGFs) as a means to specify the normative criterion that recommender systems should optimize for. GGFs weight individuals depending on their ranks in the population, giving more weight to worse-off individuals to promote equality. Depending on these weights, GGFs minimize the Gini index of item exposure to promote equality between items, or focus on the performance on specific quantiles of least satisfied users. GGFs for ranking are challenging to optimize because they are non-differentiable. We resolve this challenge by leveraging tools from non-smooth optimization and projection operators used in differentiable sorting. We present experiments using real datasets with up to 15k users and items, which show that our approach obtains better trade-offs than the baselines on a variety of recommendation tasks and fairness criteria.
Fairness Indicators for Systematic Assessments of Visual Feature Extractors
Feb 15, 2022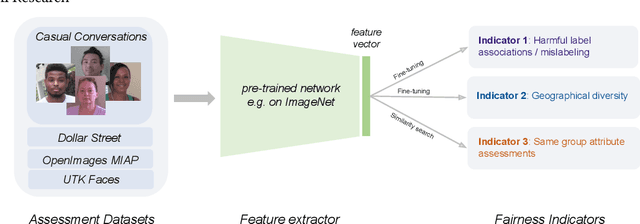


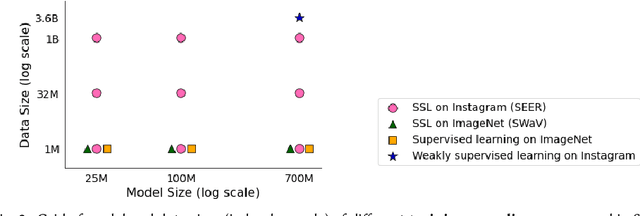
Does everyone equally benefit from computer vision systems? Answers to this question become more and more important as computer vision systems are deployed at large scale, and can spark major concerns when they exhibit vast performance discrepancies between people from various demographic and social backgrounds. Systematic diagnosis of fairness, harms, and biases of computer vision systems is an important step towards building socially responsible systems. To initiate an effort towards standardized fairness audits, we propose three fairness indicators, which aim at quantifying harms and biases of visual systems. Our indicators use existing publicly available datasets collected for fairness evaluations, and focus on three main types of harms and bias identified in the literature, namely harmful label associations, disparity in learned representations of social and demographic traits, and biased performance on geographically diverse images from across the world.We define precise experimental protocols applicable to a wide range of computer vision models. These indicators are part of an ever-evolving suite of fairness probes and are not intended to be a substitute for a thorough analysis of the broader impact of the new computer vision technologies. Yet, we believe it is a necessary first step towards (1) facilitating the widespread adoption and mandate of the fairness assessments in computer vision research, and (2) tracking progress towards building socially responsible models. To study the practical effectiveness and broad applicability of our proposed indicators to any visual system, we apply them to off-the-shelf models built using widely adopted model training paradigms which vary in their ability to whether they can predict labels on a given image or only produce the embeddings. We also systematically study the effect of data domain and model size.
Two-sided fairness in rankings via Lorenz dominance
Oct 28, 2021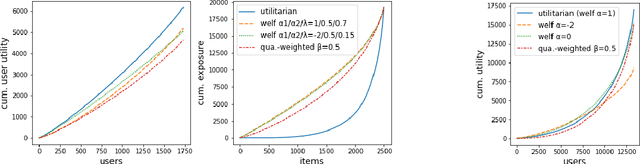
We consider the problem of generating rankings that are fair towards both users and item producers in recommender systems. We address both usual recommendation (e.g., of music or movies) and reciprocal recommendation (e.g., dating). Following concepts of distributive justice in welfare economics, our notion of fairness aims at increasing the utility of the worse-off individuals, which we formalize using the criterion of Lorenz efficiency. It guarantees that rankings are Pareto efficient, and that they maximally redistribute utility from better-off to worse-off, at a given level of overall utility. We propose to generate rankings by maximizing concave welfare functions, and develop an efficient inference procedure based on the Frank-Wolfe algorithm. We prove that unlike existing approaches based on fairness constraints, our approach always produces fair rankings. Our experiments also show that it increases the utility of the worse-off at lower costs in terms of overall utility.
Hierarchical Skills for Efficient Exploration
Oct 20, 2021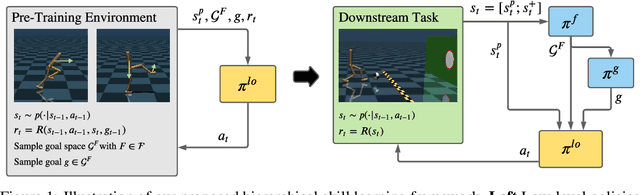
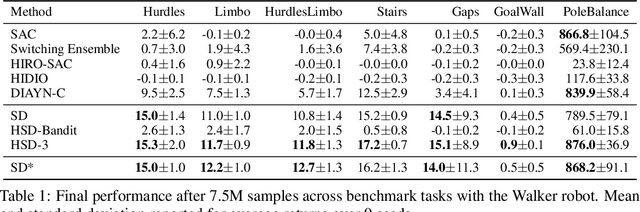


In reinforcement learning, pre-trained low-level skills have the potential to greatly facilitate exploration. However, prior knowledge of the downstream task is required to strike the right balance between generality (fine-grained control) and specificity (faster learning) in skill design. In previous work on continuous control, the sensitivity of methods to this trade-off has not been addressed explicitly, as locomotion provides a suitable prior for navigation tasks, which have been of foremost interest. In this work, we analyze this trade-off for low-level policy pre-training with a new benchmark suite of diverse, sparse-reward tasks for bipedal robots. We alleviate the need for prior knowledge by proposing a hierarchical skill learning framework that acquires skills of varying complexity in an unsupervised manner. For utilization on downstream tasks, we present a three-layered hierarchical learning algorithm to automatically trade off between general and specific skills as required by the respective task. In our experiments, we show that our approach performs this trade-off effectively and achieves better results than current state-of-the-art methods for end- to-end hierarchical reinforcement learning and unsupervised skill discovery. Code and videos are available at https://facebookresearch.github.io/hsd3 .
Online Selection of Diverse Committees
May 19, 2021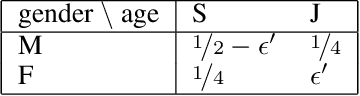
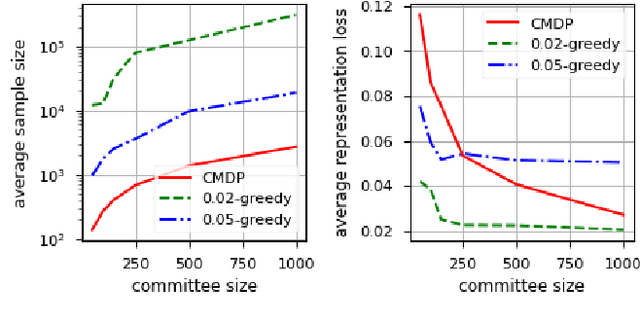
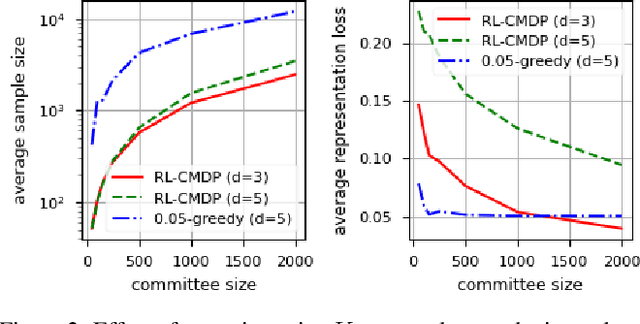
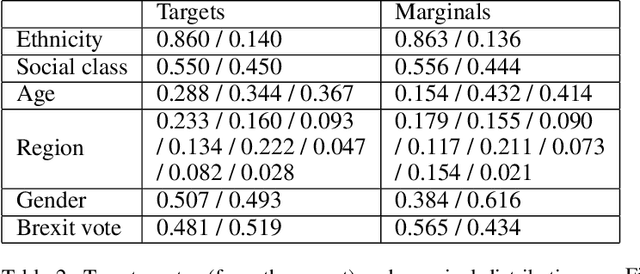
Citizens' assemblies need to represent subpopulations according to their proportions in the general population. These large committees are often constructed in an online fashion by contacting people, asking for the demographic features of the volunteers, and deciding to include them or not. This raises a trade-off between the number of people contacted (and the incurring cost) and the representativeness of the committee. We study three methods, theoretically and experimentally: a greedy algorithm that includes volunteers as long as proportionality is not violated; a non-adaptive method that includes a volunteer with a probability depending only on their features, assuming that the joint feature distribution in the volunteer pool is known; and a reinforcement learning based approach when this distribution is not known a priori but learnt online.
Online certification of preference-based fairness for personalized recommender systems
Apr 29, 2021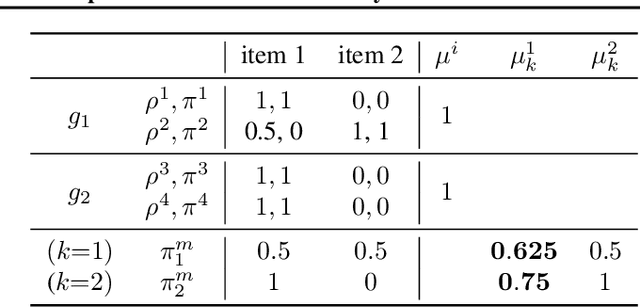
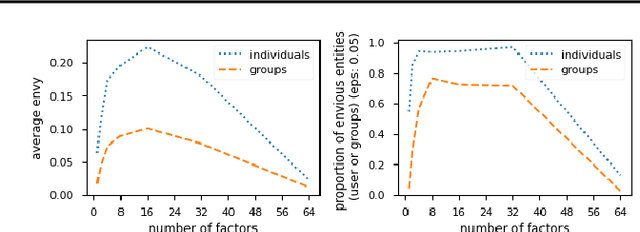
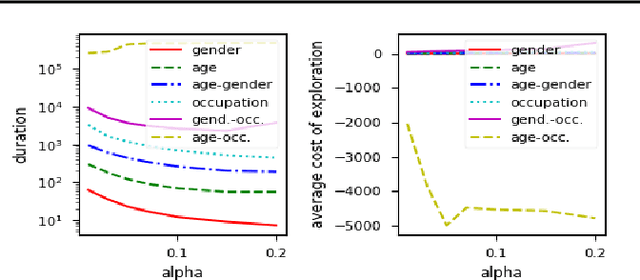
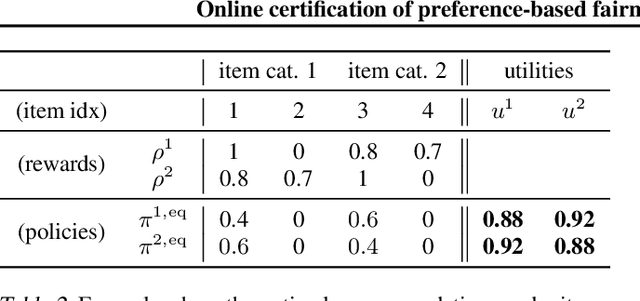
We propose to assess the fairness of personalized recommender systems in the sense of envy-freeness: every (group of) user(s) should prefer their recommendations to the recommendations of other (groups of) users. Auditing for envy-freeness requires probing user preferences to detect potential blind spots, which may deteriorate recommendation performance. To control the cost of exploration, we propose an auditing algorithm based on pure exploration and conservative constraints in multi-armed bandits. We study, both theoretically and empirically, the trade-offs achieved by this algorithm.
Gradient Matching for Domain Generalization
Apr 20, 2021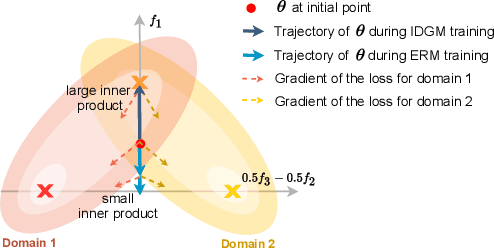


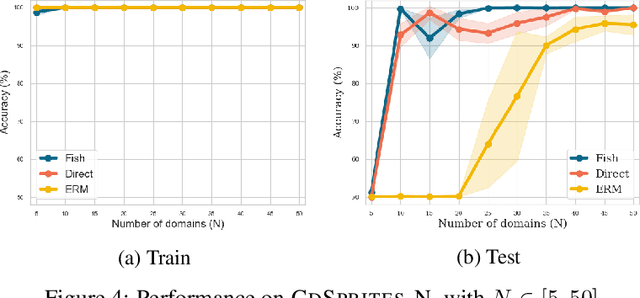
Machine learning systems typically assume that the distributions of training and test sets match closely. However, a critical requirement of such systems in the real world is their ability to generalize to unseen domains. Here, we propose an inter-domain gradient matching objective that targets domain generalization by maximizing the inner product between gradients from different domains. Since direct optimization of the gradient inner product can be computationally prohibitive -- requires computation of second-order derivatives -- we derive a simpler first-order algorithm named Fish that approximates its optimization. We demonstrate the efficacy of Fish on 6 datasets from the Wilds benchmark, which captures distribution shift across a diverse range of modalities. Our method produces competitive results on these datasets and surpasses all baselines on 4 of them. We perform experiments on both the Wilds benchmark, which captures distribution shift in the real world, as well as datasets in DomainBed benchmark that focuses more on synthetic-to-real transfer. Our method produces competitive results on both benchmarks, demonstrating its effectiveness across a wide range of domain generalization tasks.
A Self-Supervised Auxiliary Loss for Deep RL in Partially Observable Settings
Apr 17, 2021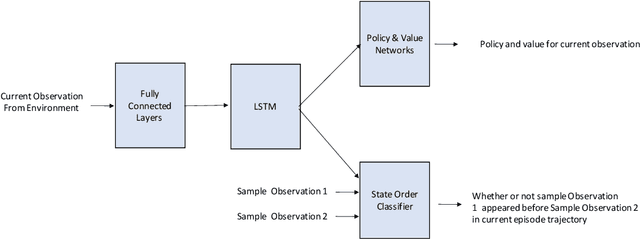


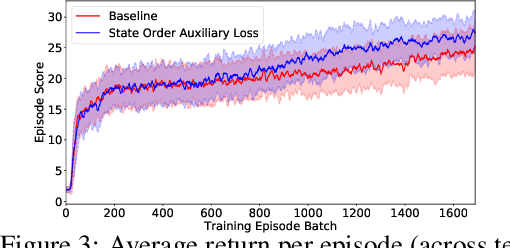
In this work we explore an auxiliary loss useful for reinforcement learning in environments where strong performing agents are required to be able to navigate a spatial environment. The auxiliary loss proposed is to minimize the classification error of a neural network classifier that predicts whether or not a pair of states sampled from the agents current episode trajectory are in order. The classifier takes as input a pair of states as well as the agent's memory. The motivation for this auxiliary loss is that there is a strong correlation with which of a pair of states is more recent in the agents episode trajectory and which of the two states is spatially closer to the agent. Our hypothesis is that learning features to answer this question encourages the agent to learn and internalize in memory representations of states that facilitate spatial reasoning. We tested this auxiliary loss on a navigation task in a gridworld and achieved 9.6% increase in accumulative episode reward compared to a strong baseline approach.