 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Autonomous Shuttles in Urban Traffic Images Using Adaptive Residual Context
Mar 16, 2026The progressive automation of transport promises to enhance safety and sustainability through shared mobility. Like other vehicles and road users, and even more so for such a new technology, it requires monitoring to understand how it interacts in traffic and to evaluate its safety. This can be done with fixed cameras and video object detection. However, the addition of new detection targets generally requires a fine-tuning approach for regular detection methods. Unfortunately, this implementation strategy will lead to a phenomenon known as catastrophic forgetting, which causes a degradation in scene understanding. In road safety applications, preserving contextual scene knowledge is of the utmost importance for protecting road users. We introduce the Adaptive Residual Context (ARC) architecture to address this. ARC links a frozen context branch and trainable task-specific branches through a Context-Guided Bridge, utilizing attention to transfer spatial features while preserving pre-trained representations. Experiments on a custom dataset show that ARC matches fine-tuned baselines while significantly improving knowledge retention, offering a data-efficient solution to add new vehicle categories for complex urban environments.
PMMA: The Polytechnique Montreal Mobility Aids Dataset
Feb 10, 2026This study introduces a new object detection dataset of pedestrians using mobility aids, named PMMA. The dataset was collected in an outdoor environment, where volunteers used wheelchairs, canes, and walkers, resulting in nine categories of pedestrians: pedestrians, cane users, two types of walker users, whether walking or resting, five types of wheelchair users, including wheelchair users, people pushing empty wheelchairs, and three types of users pushing occupied wheelchairs, including the entire pushing group, the pusher and the person seated on the wheelchair. To establish a benchmark, seven object detection models (Faster R-CNN, CenterNet, YOLOX, DETR, Deformable DETR, DINO, and RT-DETR) and three tracking algorithms (ByteTrack, BOT-SORT, and OC-SORT) were implemented under the MMDetection framework. Experimental results show that YOLOX, Deformable DETR, and Faster R-CNN achieve the best detection performance, while the differences among the three trackers are relatively small. The PMMA dataset is publicly available at https://doi.org/10.5683/SP3/XJPQUG, and the video processing and model training code is available at https://github.com/DatasetPMMA/PMMA.
Measuring the State of Open Science in Transportation Using Large Language Models
Jan 20, 2026Open science initiatives have strengthened scientific integrity and accelerated research progress across many fields, but the state of their practice within transportation research remains under-investigated. Key features of open science, defined here as data and code availability, are difficult to extract due to the inherent complexity of the field. Previous work has either been limited to small-scale studies due to the labor-intensive nature of manual analysis or has relied on large-scale bibliometric approaches that sacrifice contextual richness. This paper introduces an automatic and scalable feature-extraction pipeline to measure data and code availability in transportation research. We employ Large Language Models (LLMs) for this task and validate their performance against a manually curated dataset and through an inter-rater agreement analysis. We applied this pipeline to examine 10,724 research articles published in the Transportation Research Part series of journals between 2019 and 2024. Our analysis found that only 5% of quantitative papers shared a code repository, 4% of quantitative papers shared a data repository, and about 3% of papers shared both, with trends differing across journals, topics, and geographic regions. We found no significant difference in citation counts or review duration between papers that provided data and code and those that did not, suggesting a misalignment between open science efforts and traditional academic metrics. Consequently, encouraging these practices will likely require structural interventions from journals and funding agencies to supplement the lack of direct author incentives. The pipeline developed in this study can be readily scaled to other journals, representing a critical step toward the automated measurement and monitoring of open science practices in transportation research.
How good are deep learning methods for automated road safety analysis using video data? An experimental study
Mar 12, 2025Image-based multi-object detection (MOD) and multi-object tracking (MOT) are advancing at a fast pace. A variety of 2D and 3D MOD and MOT methods have been developed for monocular and stereo cameras. Road safety analysis can benefit from those advancements. As crashes are rare events, surrogate measures of safety (SMoS) have been developed for safety analyses. (Semi-)Automated safety analysis methods extract road user trajectories to compute safety indicators, for example, Time-to-Collision (TTC) and Post-encroachment Time (PET). Inspired by the success of deep learning in MOD and MOT, we investigate three MOT methods, including one based on a stereo-camera, using the annotated KITTI traffic video dataset. Two post-processing steps, IDsplit and SS, are developed to improve the tracking results and investigate the factors influencing the TTC. The experimental results show that, despite some advantages in terms of the numbers of interactions or similarity to the TTC distributions, all the tested methods systematically over-estimate the number of interactions and under-estimate the TTC: they report more interactions and more severe interactions, making the road user interactions appear less safe than they are. Further efforts will be directed towards testing more methods and more data, in particular from roadside sensors, to verify the results and improve the performance.
Learning Data Association for Multi-Object Tracking using Only Coordinates
Mar 12, 2024



We propose a novel Transformer-based module to address the data association problem for multi-object tracking. From detections obtained by a pretrained detector, this module uses only coordinates from bounding boxes to estimate an affinity score between pairs of tracks extracted from two distinct temporal windows. This module, named TWiX, is trained on sets of tracks with the objective of discriminating pairs of tracks coming from the same object from those which are not. Our module does not use the intersection over union measure, nor does it requires any motion priors or any camera motion compensation technique. By inserting TWiX within an online cascade matching pipeline, our tracker C-TWiX achieves state-of-the-art performance on the DanceTrack and KITTIMOT datasets, and gets competitive results on the MOT17 dataset. The code will be made available upon publication.
Detection of Micromobility Vehicles in Urban Traffic Videos
Feb 28, 2024



Urban traffic environments present unique challenges for object detection, particularly with the increasing presence of micromobility vehicles like e-scooters and bikes. To address this object detection problem, this work introduces an adapted detection model that combines the accuracy and speed of single-frame object detection with the richer features offered by video object detection frameworks. This is done by applying aggregated feature maps from consecutive frames processed through motion flow to the YOLOX architecture. This fusion brings a temporal perspective to YOLOX detection abilities, allowing for a better understanding of urban mobility patterns and substantially improving detection reliability. Tested on a custom dataset curated for urban micromobility scenarios, our model showcases substantial improvement over existing state-of-the-art methods, demonstrating the need to consider spatio-temporal information for detecting such small and thin objects. Our approach enhances detection in challenging conditions, including occlusions, ensuring temporal consistency, and effectively mitigating motion blur.
Laplacian Convolutional Representation for Traffic Time Series Imputation
Dec 18, 2022Spatiotemporal traffic data imputation is of great significance in intelligent transportation systems and data-driven decision-making processes. To make an accurate reconstruction from partially observed traffic data, we assert the importance of characterizing both global and local trends in traffic time series. In the literature, substantial prior works have demonstrated the effectiveness of utilizing low-rankness property of traffic data by matrix/tensor completion models. In this study, we first introduce a Laplacian kernel to temporal regularization for characterizing local trends in traffic time series, which can be formulated in the form of circular convolution. Then, we develop a low-rank Laplacian convolutional representation (LCR) model by putting the nuclear norm of a circulant matrix and the Laplacian temporal regularization together, which is proved to meet a unified framework that takes a fast Fourier transform (FFT) solution in a relatively low time complexity. Through extensive experiments on some traffic datasets, we demonstrate the superiority of LCR for imputing traffic time series of various time series behaviors (e.g., data noises and strong/weak periodicity). The proposed LCR model is an efficient and effective solution to large-scale traffic data imputation over the existing baseline models. Despite the LCR's application to time series data, the key modeling idea lies in bridging the low-rank models and the Laplacian regularization through FFT, which is also applicable to image inpainting. The adapted datasets and Python implementation are publicly available at https://github.com/xinychen/transdim.
Spatiotemporal Residual Regularization with Dynamic Mixtures for Traffic Forecasting
Dec 15, 2022



Existing deep learning-based traffic forecasting models are mainly trained with MSE (or MAE) as the loss function, assuming that residuals/errors follow independent and isotropic Gaussian (or Laplacian) distribution for simplicity. However, this assumption rarely holds for real-world traffic forecasting tasks, where the unexplained residuals are often correlated in both space and time. In this study, we propose Spatiotemporal Residual Regularization by modeling residuals with a dynamic (e.g., time-varying) mixture of zero-mean multivariate Gaussian distribution with learnable spatiotemporal covariance matrices. This approach allows us to directly capture spatiotemporally correlated residuals. For scalability, we model the spatiotemporal covariance for each mixture component using a Kronecker product structure, which significantly reduces the number of parameters and computation complexity. We evaluate the performance of the proposed method on a traffic speed forecasting task. Our results show that, by properly modeling residual distribution, the proposed method not only improves the model performance but also provides interpretable structures.
Discovering Dynamic Patterns from Spatiotemporal Data with Time-Varying Low-Rank Autoregression
Nov 28, 2022The problem of broad practical interest in spatiotemporal data analysis, i.e., discovering interpretable dynamic patterns from spatiotemporal data, is studied in this paper. Towards this end, we develop a time-varying reduced-rank vector autoregression (VAR) model whose coefficient matrices are parameterized by low-rank tensor factorization. Benefiting from the tensor factorization structure, the proposed model can simultaneously achieve model compression and pattern discovery. In particular, the proposed model allows one to characterize nonstationarity and time-varying system behaviors underlying spatiotemporal data. To evaluate the proposed model, extensive experiments are conducted on various spatiotemporal data representing different nonlinear dynamical systems, including fluid dynamics, sea surface temperature, USA surface temperature, and NYC taxi trips. Experimental results demonstrate the effectiveness of modeling spatiotemporal data and characterizing spatial/temporal patterns with the proposed model. In the spatial context, the spatial patterns can be automatically extracted and intuitively characterized by the spatial modes. In the temporal context, the complex time-varying system behaviors can be revealed by the temporal modes in the proposed model. Thus, our model lays an insightful foundation for understanding complex spatiotemporal data in real-world dynamical systems. The adapted datasets and Python implementation are publicly available at https://github.com/xinychen/vars.
ActAR: Actor-Driven Pose Embeddings for Video Action Recognition
Apr 19, 2022

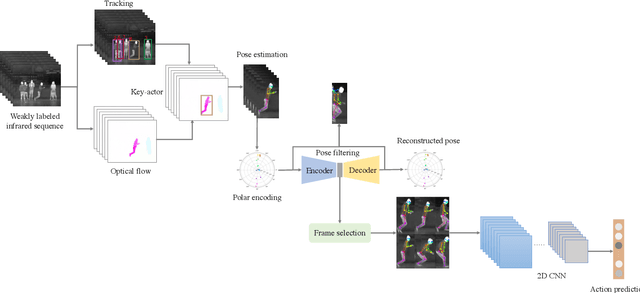
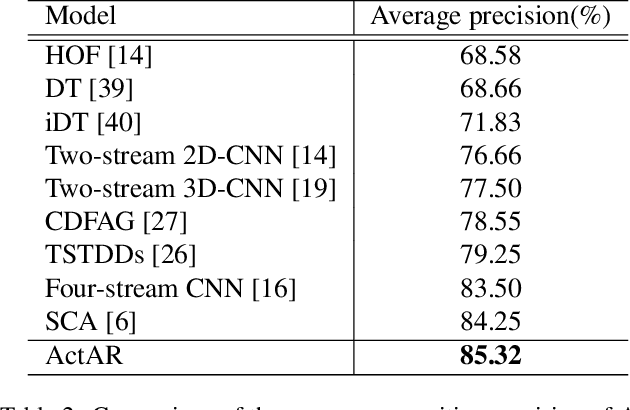
Human action recognition (HAR) in videos is one of the core tasks of video understanding. Based on video sequences, the goal is to recognize actions performed by humans. While HAR has received much attention in the visible spectrum, action recognition in infrared videos is little studied. Accurate recognition of human actions in the infrared domain is a highly challenging task because of the redundant and indistinguishable texture features present in the sequence. Furthermore, in some cases, challenges arise from the irrelevant information induced by the presence of multiple active persons not contributing to the actual action of interest. Therefore, most existing methods consider a standard paradigm that does not take into account these challenges, which is in some part due to the ambiguous definition of the recognition task in some cases. In this paper, we propose a new method that simultaneously learns to recognize efficiently human actions in the infrared spectrum, while automatically identifying the key-actors performing the action without using any prior knowledge or explicit annotations. Our method is composed of three stages. In the first stage, optical flow-based key-actor identification is performed. Then for each key-actor, we estimate key-poses that will guide the frame selection process. A scale-invariant encoding process along with embedded pose filtering are performed in order to enhance the quality of action representations. Experimental results on InfAR dataset show that our proposed model achieves promising recognition performance and learns useful action representations.