 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Tuning with Renyi Differential Privacy
Oct 07, 2021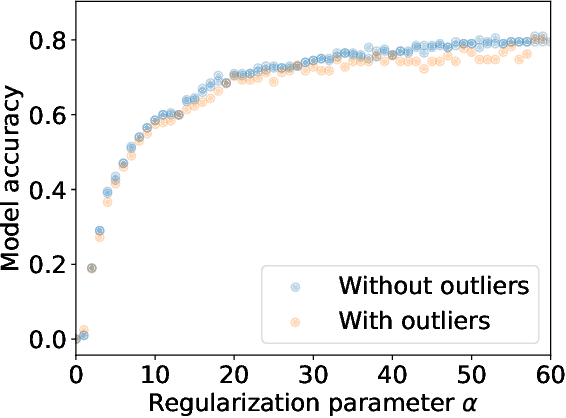
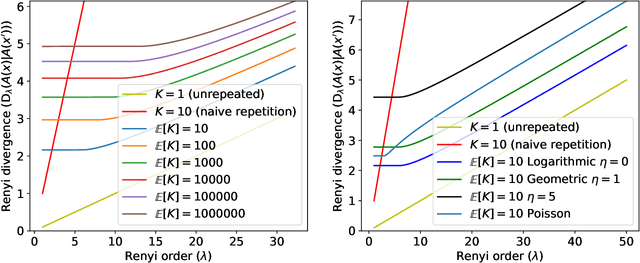
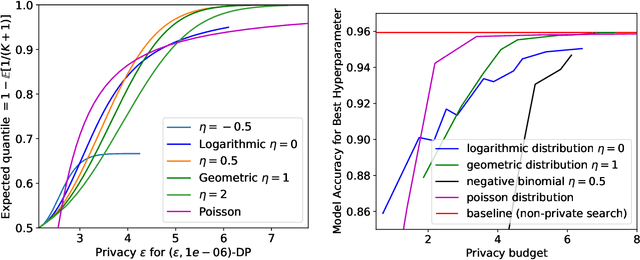
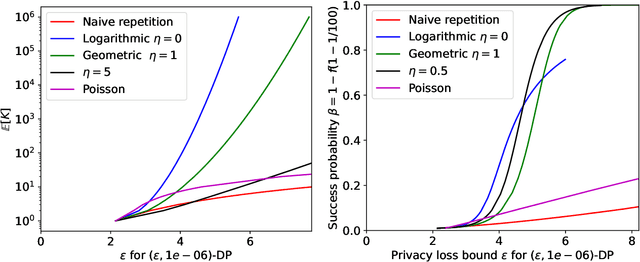
For many differentially private algorithms, such as the prominent noisy stochastic gradient descent (DP-SGD), the analysis needed to bound the privacy leakage of a single training run is well understood. However, few studies have reasoned about the privacy leakage resulting from the multiple training runs needed to fine tune the value of the training algorithm's hyperparameters. In this work, we first illustrate how simply setting hyperparameters based on non-private training runs can leak private information. Motivated by this observation, we then provide privacy guarantees for hyperparameter search procedures within the framework of Renyi Differential Privacy. Our results improve and extend the work of Liu and Talwar (STOC 2019). Our analysis supports our previous observation that tuning hyperparameters does indeed leak private information, but we prove that, under certain assumptions, this leakage is modest, as long as each candidate training run needed to select hyperparameters is itself differentially private.
Unrolling SGD: Understanding Factors Influencing Machine Unlearning
Sep 27, 2021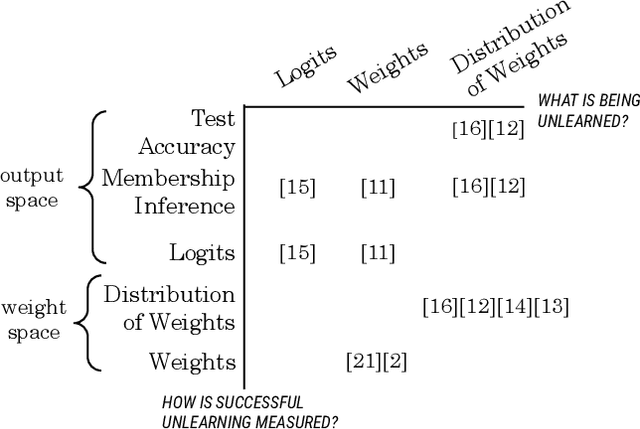
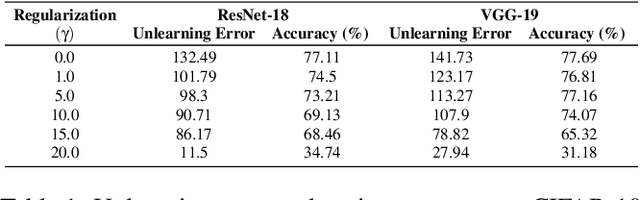
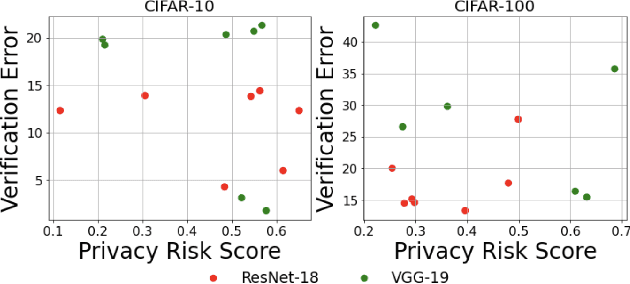
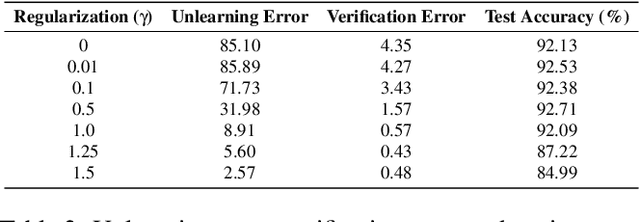
Machine unlearning is the process through which a deployed machine learning model forgets about one of its training data points. While naively retraining the model from scratch is an option, it is almost always associated with a large computational effort for deep learning models. Thus, several approaches to approximately unlearn have been proposed along with corresponding metrics that formalize what it means for a model to forget about a data point. In this work, we first taxonomize approaches and metrics of approximate unlearning. As a result, we identify verification error, i.e., the L2 difference between the weights of an approximately unlearned and a naively retrained model, as a metric approximate unlearning should optimize for as it implies a large class of other metrics. We theoretically analyze the canonical stochastic gradient descent (SGD) training algorithm to surface the variables which are relevant to reducing the verification error of approximate unlearning for SGD. From this analysis, we first derive an easy-to-compute proxy for verification error (termed unlearning error). The analysis also informs the design of a new training objective penalty that limits the overall change in weights during SGD and as a result facilitates approximate unlearning with lower verification error. We validate our theoretical work through an empirical evaluation on CIFAR-10, CIFAR-100, and IMDB sentiment analysis.
Interpretability in Safety-Critical FinancialTrading Systems
Sep 24, 2021
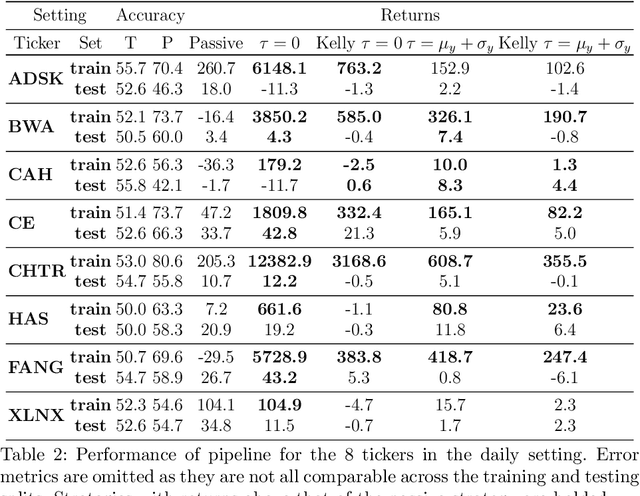

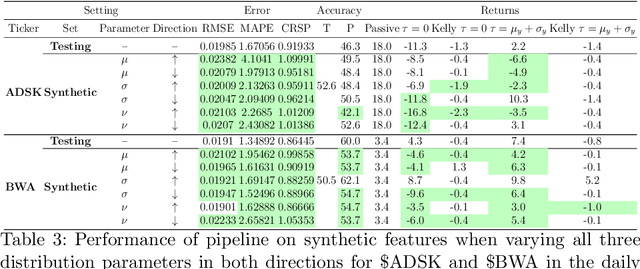
Sophisticated machine learning (ML) models to inform trading in the financial sector create problems of interpretability and risk management. Seemingly robust forecasting models may behave erroneously in out of distribution settings. In 2020, some of the world's most sophisticated quant hedge funds suffered losses as their ML models were first underhedged, and then overcompensated. We implement a gradient-based approach for precisely stress-testing how a trading model's forecasts can be manipulated, and their effects on downstream tasks at the trading execution level. We construct inputs -- whether in changes to sentiment or market variables -- that efficiently affect changes in the return distribution. In an industry-standard trading pipeline, we perturb model inputs for eight S&P 500 stocks. We find our approach discovers seemingly in-sample input settings that result in large negative shifts in return distributions. We provide the financial community with mechanisms to interpret ML forecasts in trading systems. For the security community, we provide a compelling application where studying ML robustness necessitates that one capture an end-to-end system's performance rather than study a ML model in isolation. Indeed, we show in our evaluation that errors in the forecasting model's predictions alone are not sufficient for trading decisions made based on these forecasts to yield a negative return.
SoK: Machine Learning Governance
Sep 20, 2021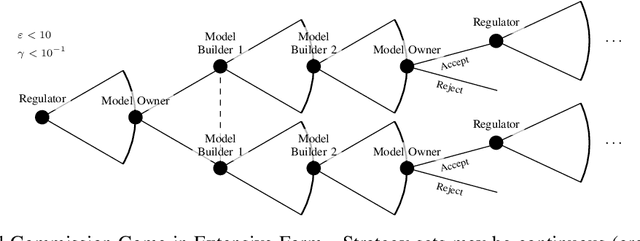
The application of machine learning (ML) in computer systems introduces not only many benefits but also risks to society. In this paper, we develop the concept of ML governance to balance such benefits and risks, with the aim of achieving responsible applications of ML. Our approach first systematizes research towards ascertaining ownership of data and models, thus fostering a notion of identity specific to ML systems. Building on this foundation, we use identities to hold principals accountable for failures of ML systems through both attribution and auditing. To increase trust in ML systems, we then survey techniques for developing assurance, i.e., confidence that the system meets its security requirements and does not exhibit certain known failures. This leads us to highlight the need for techniques that allow a model owner to manage the life cycle of their system, e.g., to patch or retire their ML system. Put altogether, our systematization of knowledge standardizes the interactions between principals involved in the deployment of ML throughout its life cycle. We highlight opportunities for future work, e.g., to formalize the resulting game between ML principals.
On the Exploitability of Audio Machine Learning Pipelines to Surreptitious Adversarial Examples
Aug 03, 2021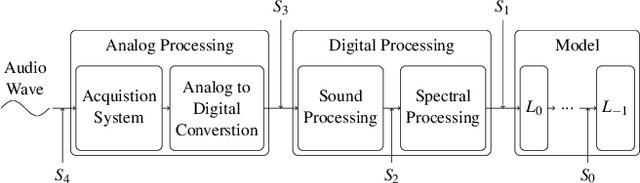
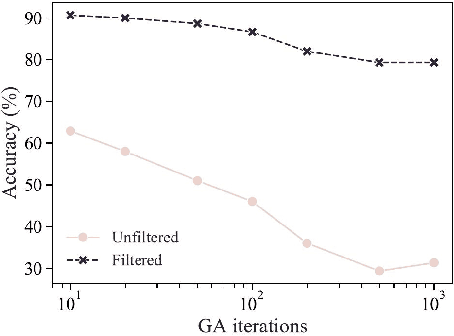
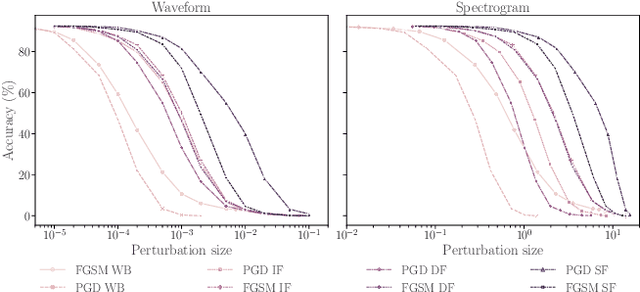
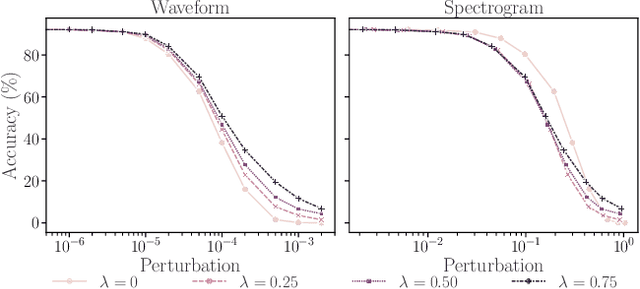
Machine learning (ML) models are known to be vulnerable to adversarial examples. Applications of ML to voice biometrics authentication are no exception. Yet, the implications of audio adversarial examples on these real-world systems remain poorly understood given that most research targets limited defenders who can only listen to the audio samples. Conflating detectability of an attack with human perceptibility, research has focused on methods that aim to produce imperceptible adversarial examples which humans cannot distinguish from the corresponding benign samples. We argue that this perspective is coarse for two reasons: 1. Imperceptibility is impossible to verify; it would require an experimental process that encompasses variations in listener training, equipment, volume, ear sensitivity, types of background noise etc, and 2. It disregards pipeline-based detection clues that realistic defenders leverage. This results in adversarial examples that are ineffective in the presence of knowledgeable defenders. Thus, an adversary only needs an audio sample to be plausible to a human. We thus introduce surreptitious adversarial examples, a new class of attacks that evades both human and pipeline controls. In the white-box setting, we instantiate this class with a joint, multi-stage optimization attack. Using an Amazon Mechanical Turk user study, we show that this attack produces audio samples that are more surreptitious than previous attacks that aim solely for imperceptibility. Lastly we show that surreptitious adversarial examples are challenging to develop in the black-box setting.
Bad Characters: Imperceptible NLP Attacks
Jun 18, 2021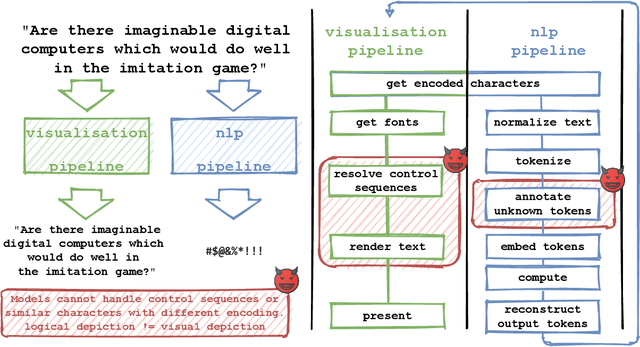
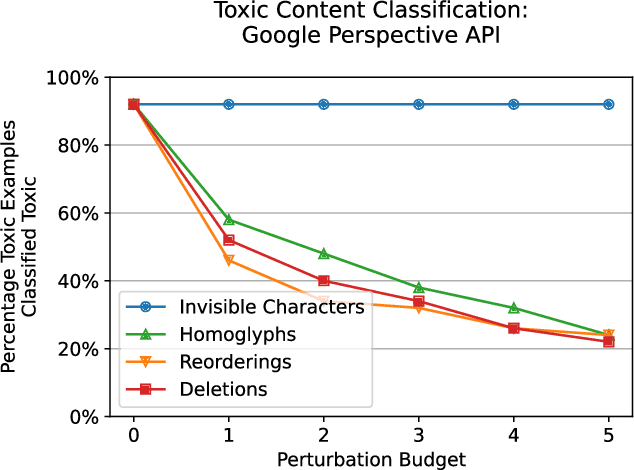
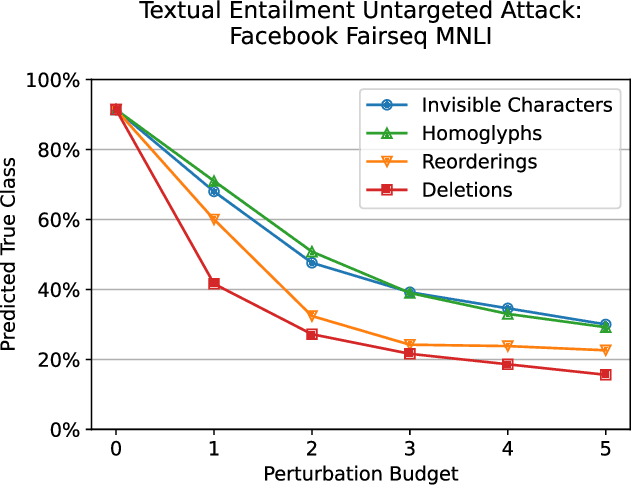
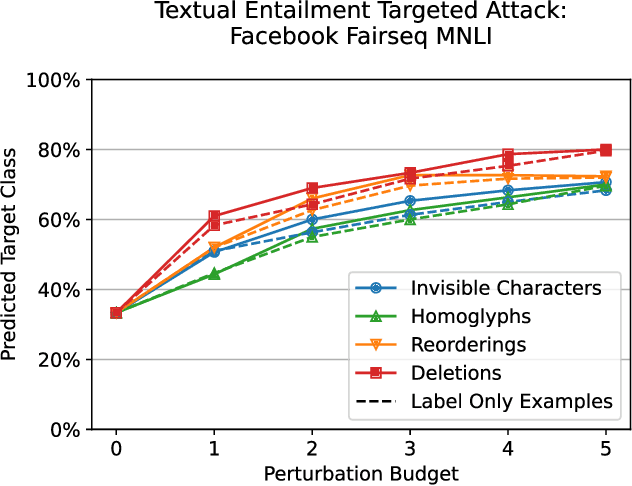
Several years of research have shown that machine-learning systems are vulnerable to adversarial examples, both in theory and in practice. Until now, such attacks have primarily targeted visual models, exploiting the gap between human and machine perception. Although text-based models have also been attacked with adversarial examples, such attacks struggled to preserve semantic meaning and indistinguishability. In this paper, we explore a large class of adversarial examples that can be used to attack text-based models in a black-box setting without making any human-perceptible visual modification to inputs. We use encoding-specific perturbations that are imperceptible to the human eye to manipulate the outputs of a wide range of Natural Language Processing (NLP) systems from neural machine-translation pipelines to web search engines. We find that with a single imperceptible encoding injection -- representing one invisible character, homoglyph, reordering, or deletion -- an attacker can significantly reduce the performance of vulnerable models, and with three injections most models can be functionally broken. Our attacks work against currently-deployed commercial systems, including those produced by Microsoft and Google, in addition to open source models published by Facebook and IBM. This novel series of attacks presents a significant threat to many language processing systems: an attacker can affect systems in a targeted manner without any assumptions about the underlying model. We conclude that text-based NLP systems require careful input sanitization, just like conventional applications, and that given such systems are now being deployed rapidly at scale, the urgent attention of architects and operators is required.
Markpainting: Adversarial Machine Learning meets Inpainting
Jun 01, 2021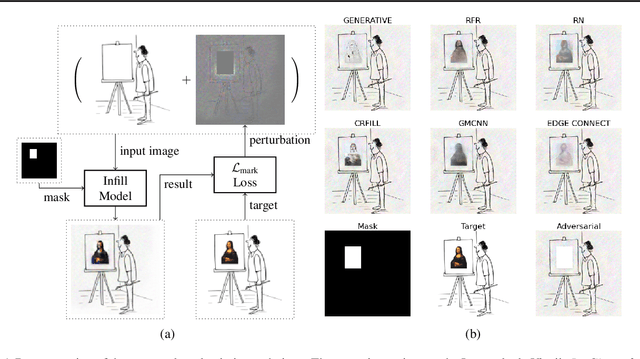
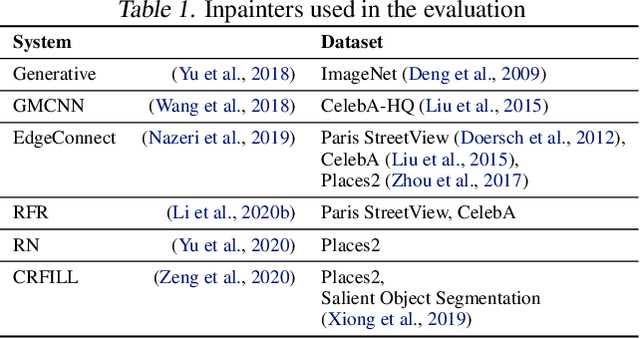

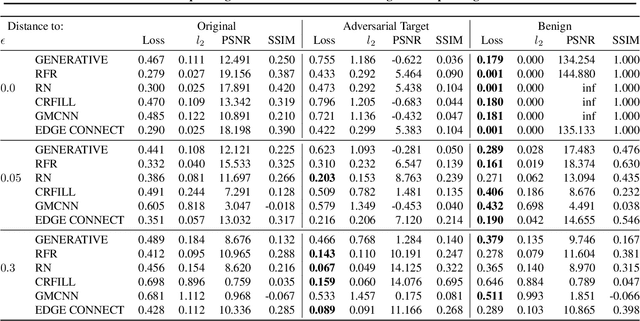
Inpainting is a learned interpolation technique that is based on generative modeling and used to populate masked or missing pieces in an image; it has wide applications in picture editing and retouching. Recently, inpainting started being used for watermark removal, raising concerns. In this paper we study how to manipulate it using our markpainting technique. First, we show how an image owner with access to an inpainting model can augment their image in such a way that any attempt to edit it using that model will add arbitrary visible information. We find that we can target multiple different models simultaneously with our technique. This can be designed to reconstitute a watermark if the editor had been trying to remove it. Second, we show that our markpainting technique is transferable to models that have different architectures or were trained on different datasets, so watermarks created using it are difficult for adversaries to remove. Markpainting is novel and can be used as a manipulation alarm that becomes visible in the event of inpainting.
Dataset Inference: Ownership Resolution in Machine Learning
Apr 21, 2021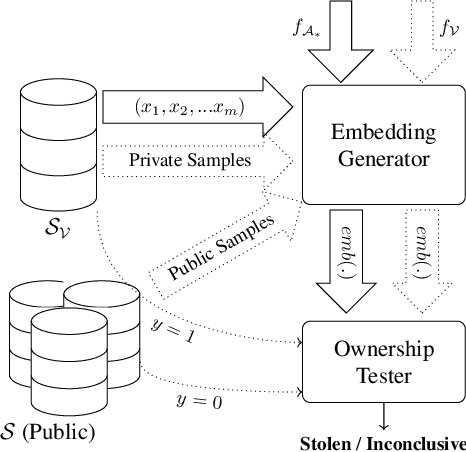
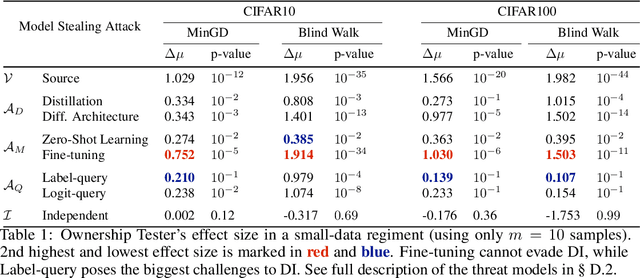
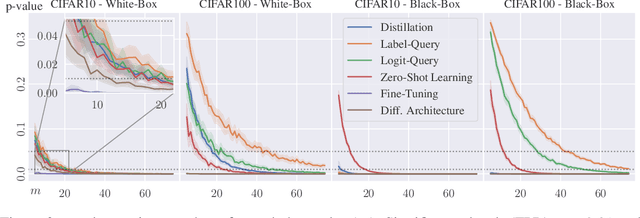
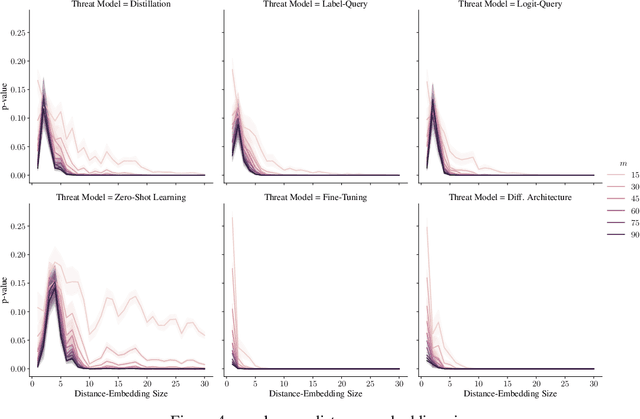
With increasingly more data and computation involved in their training, machine learning models constitute valuable intellectual property. This has spurred interest in model stealing, which is made more practical by advances in learning with partial, little, or no supervision. Existing defenses focus on inserting unique watermarks in a model's decision surface, but this is insufficient: the watermarks are not sampled from the training distribution and thus are not always preserved during model stealing. In this paper, we make the key observation that knowledge contained in the stolen model's training set is what is common to all stolen copies. The adversary's goal, irrespective of the attack employed, is always to extract this knowledge or its by-products. This gives the original model's owner a strong advantage over the adversary: model owners have access to the original training data. We thus introduce $dataset$ $inference$, the process of identifying whether a suspected model copy has private knowledge from the original model's dataset, as a defense against model stealing. We develop an approach for dataset inference that combines statistical testing with the ability to estimate the distance of multiple data points to the decision boundary. Our experiments on CIFAR10, SVHN, CIFAR100 and ImageNet show that model owners can claim with confidence greater than 99% that their model (or dataset as a matter of fact) was stolen, despite only exposing 50 of the stolen model's training points. Dataset inference defends against state-of-the-art attacks even when the adversary is adaptive. Unlike prior work, it does not require retraining or overfitting the defended model.
Manipulating SGD with Data Ordering Attacks
Apr 19, 2021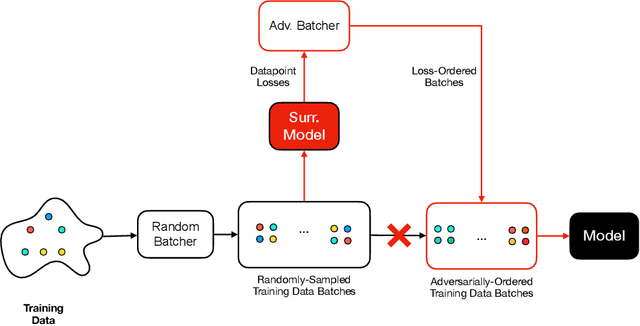
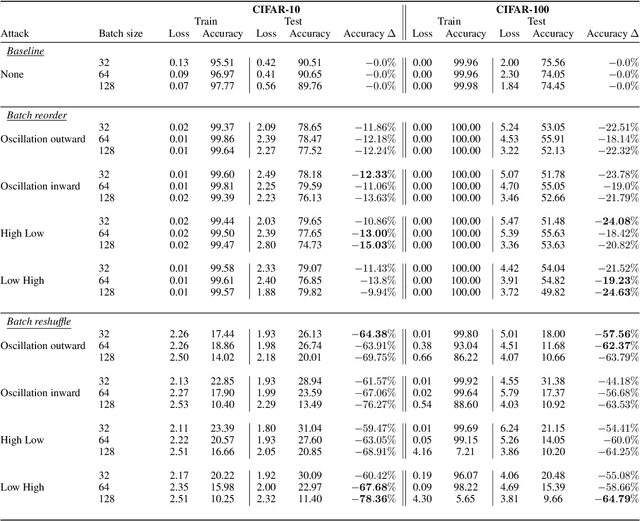
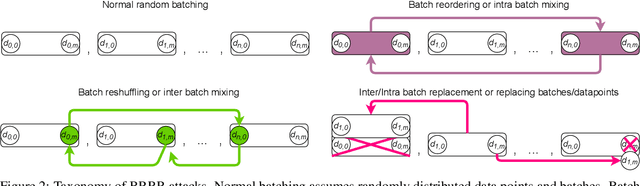
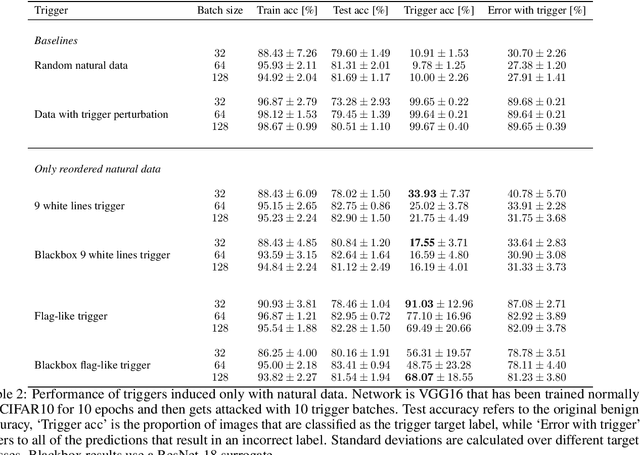
Machine learning is vulnerable to a wide variety of different attacks. It is now well understood that by changing the underlying data distribution, an adversary can poison the model trained with it or introduce backdoors. In this paper we present a novel class of training-time attacks that require no changes to the underlying model dataset or architecture, but instead only change the order in which data are supplied to the model. In particular, an attacker can disrupt the integrity and availability of a model by simply reordering training batches, with no knowledge about either the model or the dataset. Indeed, the attacks presented here are not specific to the model or dataset, but rather target the stochastic nature of modern learning procedures. We extensively evaluate our attacks to find that the adversary can disrupt model training and even introduce backdoors. For integrity we find that the attacker can either stop the model from learning, or poison it to learn behaviours specified by the attacker. For availability we find that a single adversarially-ordered epoch can be enough to slow down model learning, or even to reset all of the learning progress. Such attacks have a long-term impact in that they decrease model performance hundreds of epochs after the attack took place. Reordering is a very powerful adversarial paradigm in that it removes the assumption that an adversary must inject adversarial data points or perturbations to perform training-time attacks. It reminds us that stochastic gradient descent relies on the assumption that data are sampled at random. If this randomness is compromised, then all bets are off.
Proof-of-Learning: Definitions and Practice
Mar 09, 2021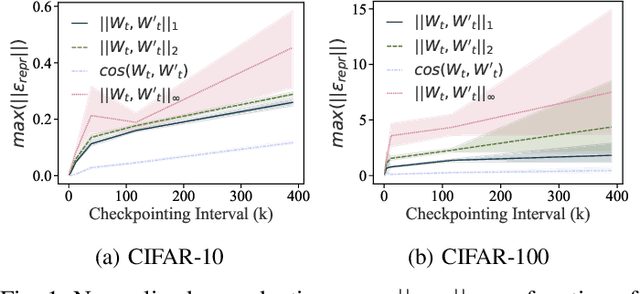
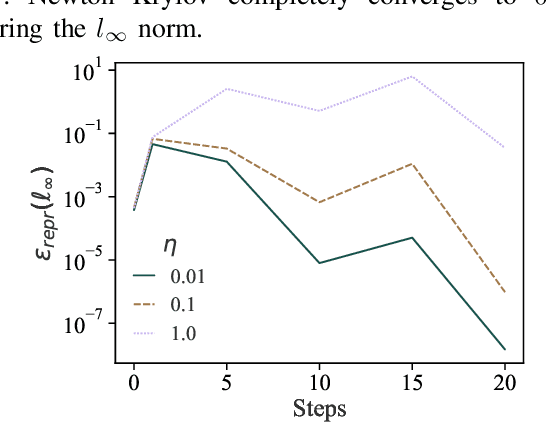
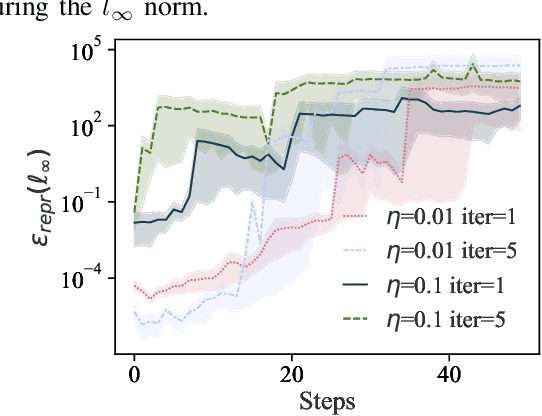
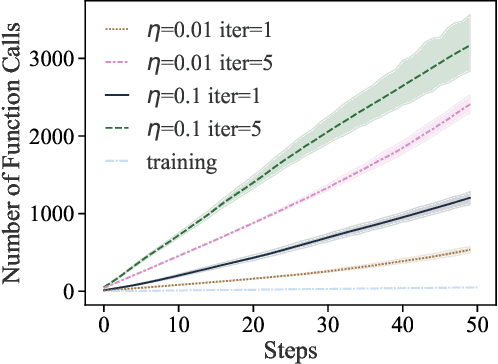
Training machine learning (ML) models typically involves expensive iterative optimization. Once the model's final parameters are released, there is currently no mechanism for the entity which trained the model to prove that these parameters were indeed the result of this optimization procedure. Such a mechanism would support security of ML applications in several ways. For instance, it would simplify ownership resolution when multiple parties contest ownership of a specific model. It would also facilitate the distributed training across untrusted workers where Byzantine workers might otherwise mount a denial-of-service by returning incorrect model updates. In this paper, we remediate this problem by introducing the concept of proof-of-learning in ML. Inspired by research on both proof-of-work and verified computations, we observe how a seminal training algorithm, stochastic gradient descent, accumulates secret information due to its stochasticity. This produces a natural construction for a proof-of-learning which demonstrates that a party has expended the compute require to obtain a set of model parameters correctly. In particular, our analyses and experiments show that an adversary seeking to illegitimately manufacture a proof-of-learning needs to perform *at least* as much work than is needed for gradient descent itself. We also instantiate a concrete proof-of-learning mechanism in both of the scenarios described above. In model ownership resolution, it protects the intellectual property of models released publicly. In distributed training, it preserves availability of the training procedure. Our empirical evaluation validates that our proof-of-learning mechanism is robust to variance induced by the hardware (ML accelerators) and software stacks.