 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Provenance Verification should be Treated as Labor Infrastructure in AI-Saturated Markets
May 04, 2026We argue that AI-saturated markets are likely to create Veblen-good premiums, which we term human-provenance premiums, for verified human presence, and hence AI governance should treat human-provenance verification as labor infrastructure. Generative and agentic AI systems lower the cost of many standardized cognitive, creative, and coordination tasks, weakening the scarcity premiums that have supported much middle-tier knowledge work. We argue that this pressure may produce an asymmetric barbell-shaped structure of value capture in advanced economies: high-volume synthetic production controlled by owners of AI infrastructure at one pole, and scarce, high-status human labor valued for verified human presence at the other. We advance three claims. First, AI compresses the value of standardized middle-tier labor by making good-enough synthetic substitutes scalable at low marginal cost, hollowing out the middle of the skill distribution currently categorized by knowledge work. Second, this compression reallocates demand for human labor toward work valued for its visible human character. We term this performative humanity and distinguish three forms of labor: relational presence, aesthetic provenance, and accountability. Third, as these premiums depend on credible verification, AI governance should treat human-provenance systems as labor infrastructure rather than as luxury authenticity labels. To evaluate hybrid human-AI work, we propose constitutive human presence as the relevant standard: human labor retains premium value when human judgment, attention, accountability, authorship, or relational participation is not incidental to the output but constitutive of what is being purchased.
Adversarial Suffix Filtering: a Defense Pipeline for LLMs
May 14, 2025Large Language Models (LLMs) are increasingly embedded in autonomous systems and public-facing environments, yet they remain susceptible to jailbreak vulnerabilities that may undermine their security and trustworthiness. Adversarial suffixes are considered to be the current state-of-the-art jailbreak, consistently outperforming simpler methods and frequently succeeding even in black-box settings. Existing defenses rely on access to the internal architecture of models limiting diverse deployment, increase memory and computation footprints dramatically, or can be bypassed with simple prompt engineering methods. We introduce $\textbf{Adversarial Suffix Filtering}$ (ASF), a lightweight novel model-agnostic defensive pipeline designed to protect LLMs against adversarial suffix attacks. ASF functions as an input preprocessor and sanitizer that detects and filters adversarially crafted suffixes in prompts, effectively neutralizing malicious injections. We demonstrate that ASF provides comprehensive defense capabilities across both black-box and white-box attack settings, reducing the attack efficacy of state-of-the-art adversarial suffix generation methods to below 4%, while only minimally affecting the target model's capabilities in non-adversarial scenarios.
Watermarking Needs Input Repetition Masking
Apr 16, 2025



Recent advancements in Large Language Models (LLMs) raised concerns over potential misuse, such as for spreading misinformation. In response two counter measures emerged: machine learning-based detectors that predict if text is synthetic, and LLM watermarking, which subtly marks generated text for identification and attribution. Meanwhile, humans are known to adjust language to their conversational partners both syntactically and lexically. By implication, it is possible that humans or unwatermarked LLMs could unintentionally mimic properties of LLM generated text, making counter measures unreliable. In this work we investigate the extent to which such conversational adaptation happens. We call the concept $\textit{mimicry}$ and demonstrate that both humans and LLMs end up mimicking, including the watermarking signal even in seemingly improbable settings. This challenges current academic assumptions and suggests that for long-term watermarking to be reliable, the likelihood of false positives needs to be significantly lower, while longer word sequences should be used for seeding watermarking mechanisms.
"I am bad": Interpreting Stealthy, Universal and Robust Audio Jailbreaks in Audio-Language Models
Feb 02, 2025



The rise of multimodal large language models has introduced innovative human-machine interaction paradigms but also significant challenges in machine learning safety. Audio-Language Models (ALMs) are especially relevant due to the intuitive nature of spoken communication, yet little is known about their failure modes. This paper explores audio jailbreaks targeting ALMs, focusing on their ability to bypass alignment mechanisms. We construct adversarial perturbations that generalize across prompts, tasks, and even base audio samples, demonstrating the first universal jailbreaks in the audio modality, and show that these remain effective in simulated real-world conditions. Beyond demonstrating attack feasibility, we analyze how ALMs interpret these audio adversarial examples and reveal them to encode imperceptible first-person toxic speech - suggesting that the most effective perturbations for eliciting toxic outputs specifically embed linguistic features within the audio signal. These results have important implications for understanding the interactions between different modalities in multimodal models, and offer actionable insights for enhancing defenses against adversarial audio attacks.
Complexity Matters: Effective Dimensionality as a Measure for Adversarial Robustness
Oct 24, 2024Quantifying robustness in a single measure for the purposes of model selection, development of adversarial training methods, and anticipating trends has so far been elusive. The simplest metric to consider is the number of trainable parameters in a model but this has previously been shown to be insufficient at explaining robustness properties. A variety of other metrics, such as ones based on boundary thickness and gradient flatness have been proposed but have been shown to be inadequate proxies for robustness. In this work, we investigate the relationship between a model's effective dimensionality, which can be thought of as model complexity, and its robustness properties. We run experiments on commercial-scale models that are often used in real-world environments such as YOLO and ResNet. We reveal a near-linear inverse relationship between effective dimensionality and adversarial robustness, that is models with a lower dimensionality exhibit better robustness. We investigate the effect of a variety of adversarial training methods on effective dimensionality and find the same inverse linear relationship present, suggesting that effective dimensionality can serve as a useful criterion for model selection and robustness evaluation, providing a more nuanced and effective metric than parameter count or previously-tested measures.
Scaling Laws for Data Poisoning in LLMs
Aug 06, 2024



Recent work shows that LLMs are vulnerable to data poisoning, in which they are trained on partially corrupted or harmful data. Poisoned data is hard to detect, breaks guardrails, and leads to undesirable and harmful behavior. Given the intense efforts by leading labs to train and deploy increasingly larger and more capable LLMs, it is critical to ask if the risk of data poisoning will be naturally mitigated by scale, or if it is an increasing threat. We consider three threat models by which data poisoning can occur: malicious fine-tuning, imperfect data curation, and intentional data contamination. Our experiments evaluate the effects of data poisoning on 23 frontier LLMs ranging from 1.5-72 billion parameters on three datasets which speak to each of our threat models. We find that larger LLMs are increasingly vulnerable, learning harmful behavior -- including sleeper agent behavior -- significantly more quickly than smaller LLMs with even minimal data poisoning. These results underscore the need for robust safeguards against data poisoning in larger LLMs.
QBI: Quantile-based Bias Initialization for Efficient Private Data Reconstruction in Federated Learning
Jun 26, 2024



Federated learning enables the training of machine learning models on distributed data without compromising user privacy, as data remains on personal devices and only model updates, such as gradients, are shared with a central coordinator. However, recent research has shown that the central entity can perfectly reconstruct private data from shared model updates by maliciously initializing the model's parameters. In this paper, we propose QBI, a novel bias initialization method that significantly enhances reconstruction capabilities. This is accomplished by directly solving for bias values yielding sparse activation patterns. Further, we propose PAIRS, an algorithm that builds on QBI. PAIRS can be deployed when a separate dataset from the target domain is available to further increase the percentage of data that can be fully recovered. Measured by the percentage of samples that can be perfectly reconstructed from batches of various sizes, our approach achieves significant improvements over previous methods with gains of up to 50% on ImageNet and up to 60% on the IMDB sentiment analysis text dataset. Furthermore, we establish theoretical limits for attacks leveraging stochastic gradient sparsity, providing a foundation for understanding the fundamental constraints of these attacks. We empirically assess these limits using synthetic datasets. Finally, we propose and evaluate AGGP, a defensive framework designed to prevent gradient sparsity attacks, contributing to the development of more secure and private federated learning systems.
Human-Producible Adversarial Examples
Sep 30, 2023Visual adversarial examples have so far been restricted to pixel-level image manipulations in the digital world, or have required sophisticated equipment such as 2D or 3D printers to be produced in the physical real world. We present the first ever method of generating human-producible adversarial examples for the real world that requires nothing more complicated than a marker pen. We call them $\textbf{adversarial tags}$. First, building on top of differential rendering, we demonstrate that it is possible to build potent adversarial examples with just lines. We find that by drawing just $4$ lines we can disrupt a YOLO-based model in $54.8\%$ of cases; increasing this to $9$ lines disrupts $81.8\%$ of the cases tested. Next, we devise an improved method for line placement to be invariant to human drawing error. We evaluate our system thoroughly in both digital and analogue worlds and demonstrate that our tags can be applied by untrained humans. We demonstrate the effectiveness of our method for producing real-world adversarial examples by conducting a user study where participants were asked to draw over printed images using digital equivalents as guides. We further evaluate the effectiveness of both targeted and untargeted attacks, and discuss various trade-offs and method limitations, as well as the practical and ethical implications of our work. The source code will be released publicly.
Markpainting: Adversarial Machine Learning meets Inpainting
Jun 01, 2021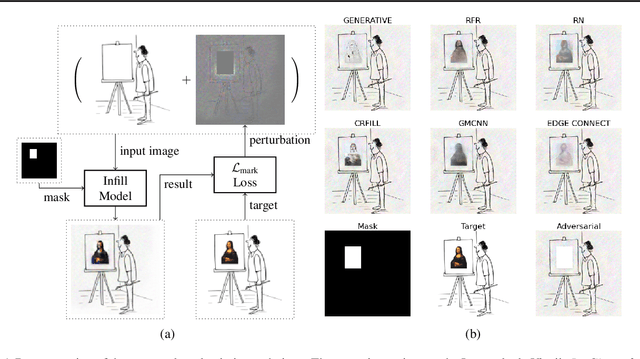
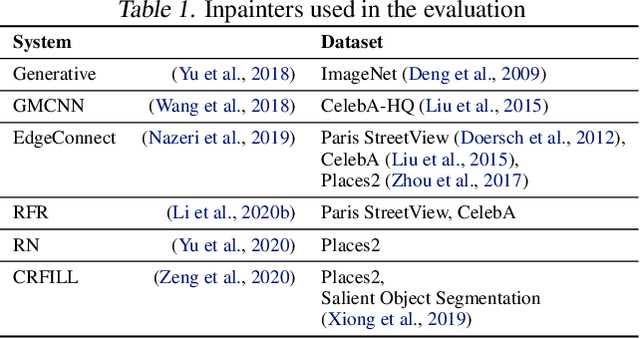

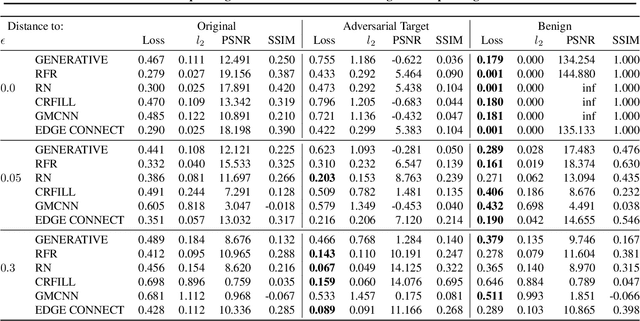
Inpainting is a learned interpolation technique that is based on generative modeling and used to populate masked or missing pieces in an image; it has wide applications in picture editing and retouching. Recently, inpainting started being used for watermark removal, raising concerns. In this paper we study how to manipulate it using our markpainting technique. First, we show how an image owner with access to an inpainting model can augment their image in such a way that any attempt to edit it using that model will add arbitrary visible information. We find that we can target multiple different models simultaneously with our technique. This can be designed to reconstitute a watermark if the editor had been trying to remove it. Second, we show that our markpainting technique is transferable to models that have different architectures or were trained on different datasets, so watermarks created using it are difficult for adversaries to remove. Markpainting is novel and can be used as a manipulation alarm that becomes visible in the event of inpainting.