 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESPnet-SLU: Advancing Spoken Language Understanding through ESPnet
Nov 29, 2021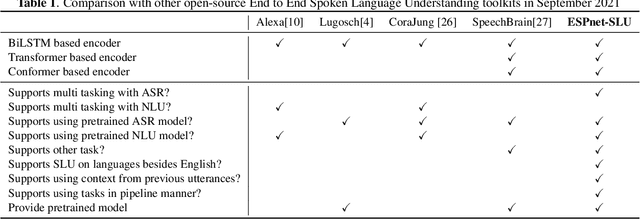
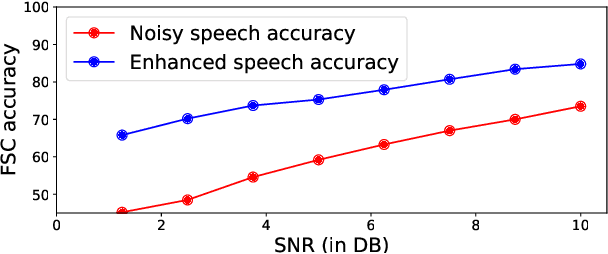
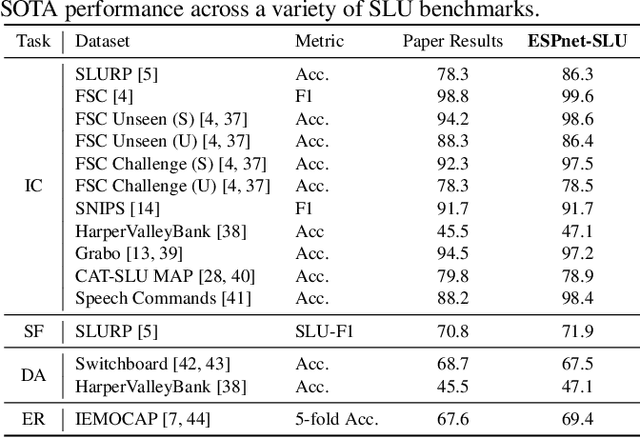

As Automatic Speech Processing (ASR) systems are getting better, there is an increasing interest of using the ASR output to do downstream Natural Language Processing (NLP) tasks. However, there are few open source toolkits that can be used to generate reproducible results on different Spoken Language Understanding (SLU) benchmarks. Hence, there is a need to build an open source standard that can be used to have a faster start into SLU research. We present ESPnet-SLU, which is designed for quick development of spoken language understanding in a single framework. ESPnet-SLU is a project inside end-to-end speech processing toolkit, ESPnet, which is a widely used open-source standard for various speech processing tasks like ASR, Text to Speech (TTS) and Speech Translation (ST). We enhance the toolkit to provide implementations for various SLU benchmarks that enable researchers to seamlessly mix-and-match different ASR and NLU models. We also provide pretrained models with intensively tuned hyper-parameters that can match or even outperform the current state-of-the-art performances. The toolkit is publicly available at https://github.com/espnet/espnet.
Does External Knowledge Help Explainable Natural Language Inference? Automatic Evaluation vs. Human Ratings
Oct 13, 2021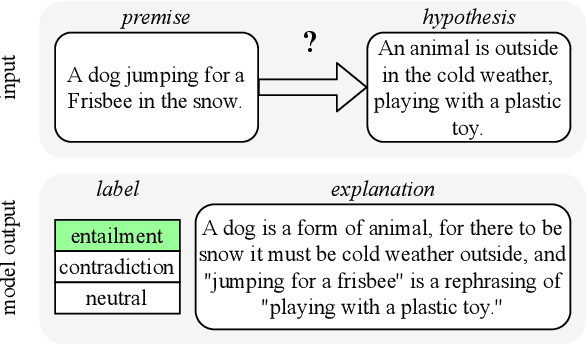
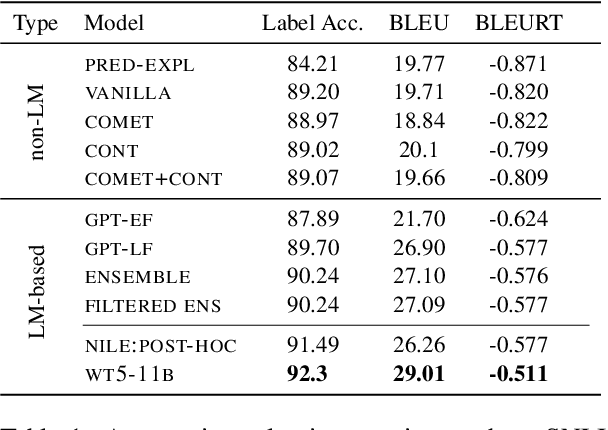
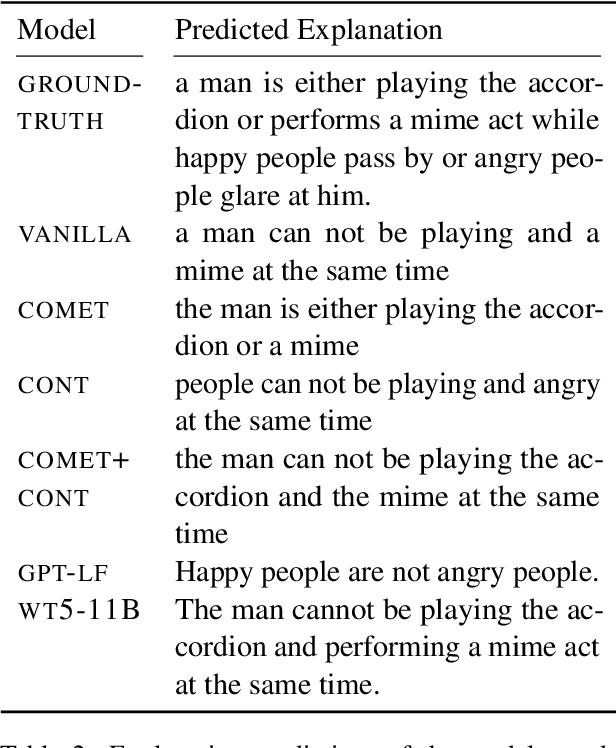
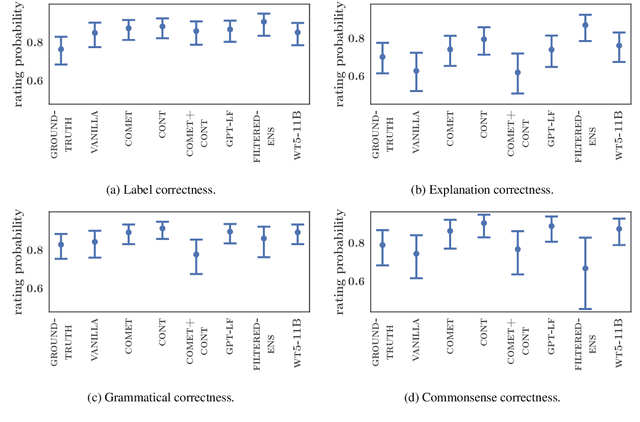
Natural language inference (NLI) requires models to learn and apply commonsense knowledge. These reasoning abilities are particularly important for explainable NLI systems that generate a natural language explanation in addition to their label prediction. The integration of external knowledge has been shown to improve NLI systems, here we investigate whether it can also improve their explanation capabilities. For this, we investigate different sources of external knowledge and evaluate the performance of our models on in-domain data as well as on special transfer datasets that are designed to assess fine-grained reasoning capabilities. We find that different sources of knowledge have a different effect on reasoning abilities, for example, implicit knowledge stored in language models can hinder reasoning on numbers and negations. Finally, we conduct the largest and most fine-grained explainable NLI crowdsourcing study to date. It reveals that even large differences in automatic performance scores do neither reflect in human ratings of label, explanation, commonsense nor grammar correctness.
Beyond Accuracy: A Consolidated Tool for Visual Question Answering Benchmarking
Oct 11, 2021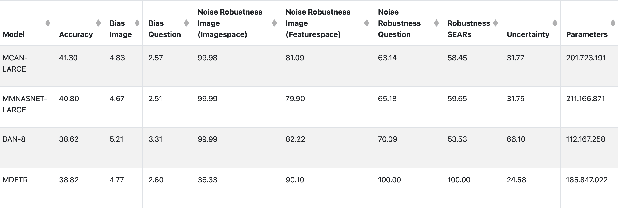
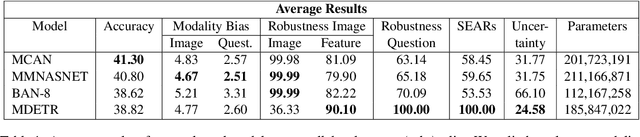
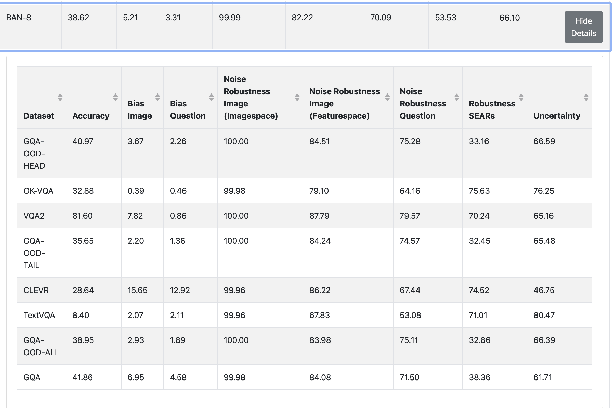

On the way towards general Visual Question Answering (VQA) systems that are able to answer arbitrary questions, the need arises for evaluation beyond single-metric leaderboards for specific datasets. To this end, we propose a browser-based benchmarking tool for researchers and challenge organizers, with an API for easy integration of new models and datasets to keep up with the fast-changing landscape of VQA. Our tool helps test generalization capabilities of models across multiple datasets, evaluating not just accuracy, but also performance in more realistic real-world scenarios such as robustness to input noise. Additionally, we include metrics that measure biases and uncertainty, to further explain model behavior. Interactive filtering facilitates discovery of problematic behavior, down to the data sample level. As proof of concept, we perform a case study on four models. We find that state-of-the-art VQA models are optimized for specific tasks or datasets, but fail to generalize even to other in-domain test sets, for example they cannot recognize text in images. Our metrics allow us to quantify which image and question embeddings provide most robustness to a model. All code is publicly available.
Investigations on Speech Recognition Systems for Low-Resource Dialectal Arabic-English Code-Switching Speech
Aug 29, 2021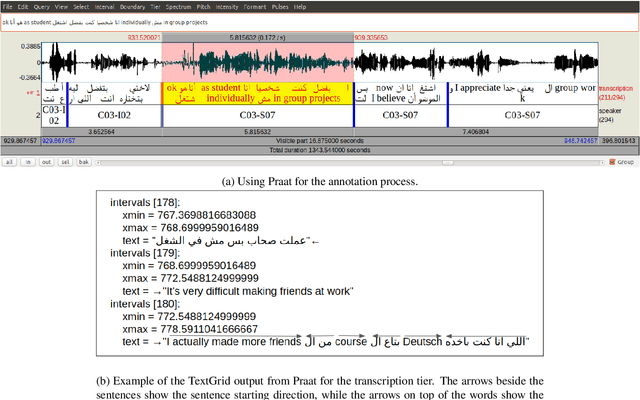
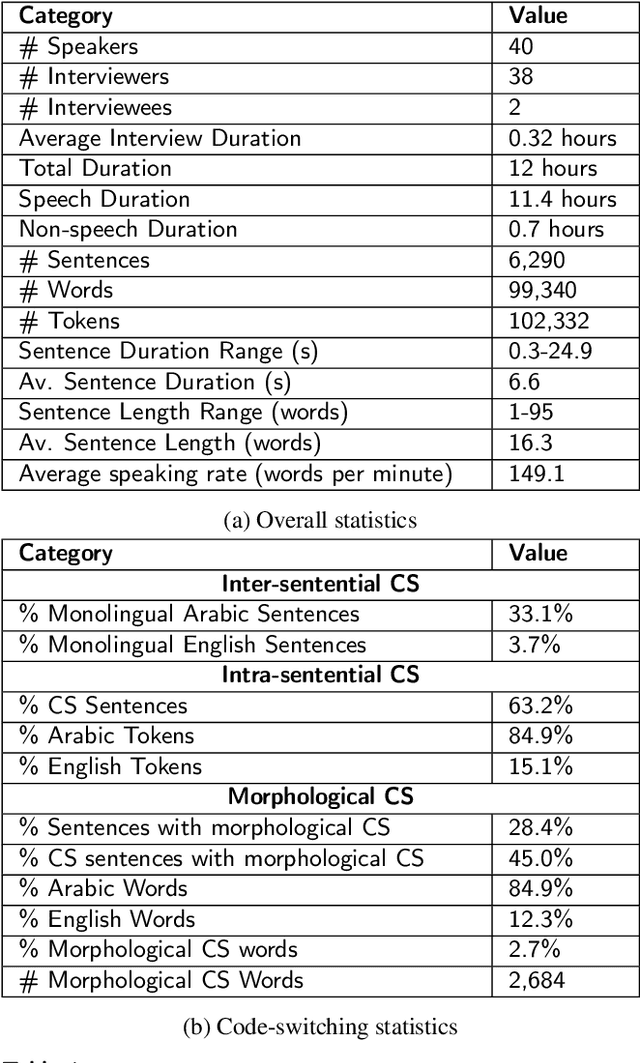
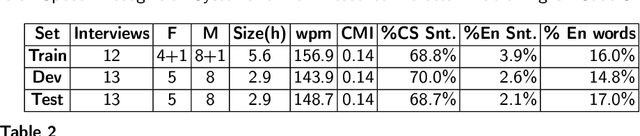
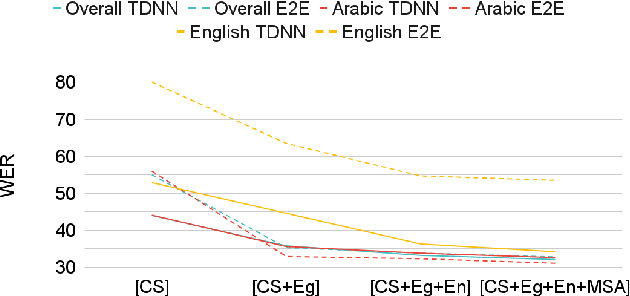
Code-switching (CS), defined as the mixing of languages in conversations, has become a worldwide phenomenon. The prevalence of CS has been recently met with a growing demand and interest to build CS ASR systems. In this paper, we present our work on code-switched Egyptian Arabic-English automatic speech recognition (ASR). We first contribute in filling the huge gap in resources by collecting, analyzing and publishing our spontaneous CS Egyptian Arabic-English speech corpus. We build our ASR systems using DNN-based hybrid and Transformer-based end-to-end models. In this paper, we present a thorough comparison between both approaches under the setting of a low-resource, orthographically unstandardized, and morphologically rich language pair. We show that while both systems give comparable overall recognition results, each system provides complementary sets of strength points. We show that recognition can be improved by combining the outputs of both systems. We propose several effective system combination approaches, where hypotheses of both systems are merged on sentence- and word-levels. Our approaches result in overall WER relative improvement of 4.7%, over a baseline performance of 32.1% WER. In the case of intra-sentential CS sentences, we achieve WER relative improvement of 4.8%. Our best performing system achieves 30.6% WER on ArzEn test set.
Thought Flow Nets: From Single Predictions to Trains of Model Thought
Jul 26, 2021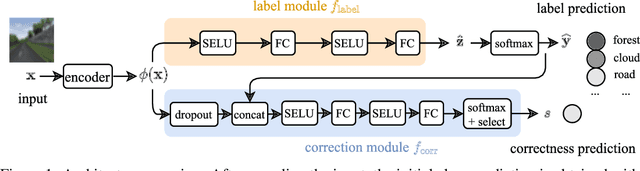
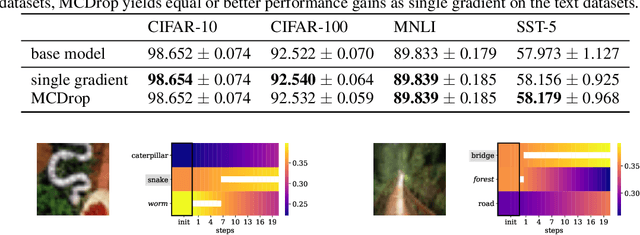

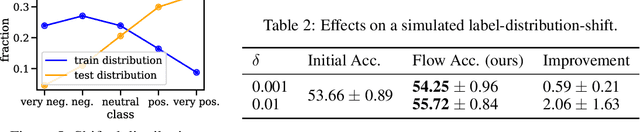
When humans solve complex problems, they rarely come up with a decision right-away. Instead, they start with an intuitive decision, reflect upon it, spot mistakes, resolve contradictions and jump between different hypotheses. Thus, they create a sequence of ideas and follow a train of thought that ultimately reaches a conclusive decision. Contrary to this, today's neural classification models are mostly trained to map an input to one single and fixed output. In this paper, we investigate how we can give models the opportunity of a second, third and $k$-th thought. We take inspiration from Hegel's dialectics and propose a method that turns an existing classifier's class prediction (such as the image class forest) into a sequence of predictions (such as forest $\rightarrow$ tree $\rightarrow$ mushroom). Concretely, we propose a correction module that is trained to estimate the model's correctness as well as an iterative prediction update based on the prediction's gradient. Our approach results in a dynamic system over class probability distributions $\unicode{x2014}$ the thought flow. We evaluate our method on diverse datasets and tasks from computer vision and natural language processing. We observe surprisingly complex but intuitive behavior and demonstrate that our method (i) can correct misclassifications, (ii) strengthens model performance, (iii) is robust to high levels of adversarial attacks, (iv) can increase accuracy up to 4% in a label-distribution-shift setting and (iv) provides a tool for model interpretability that uncovers model knowledge which otherwise remains invisible in a single distribution prediction.
IMS' Systems for the IWSLT 2021 Low-Resource Speech Translation Task
Jun 30, 2021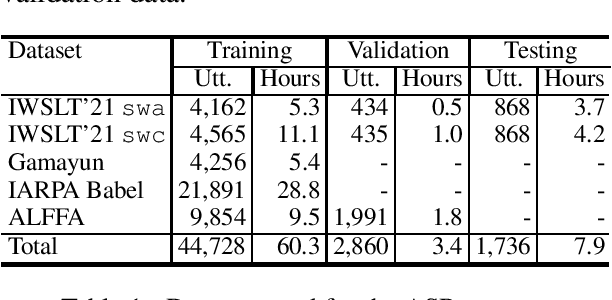
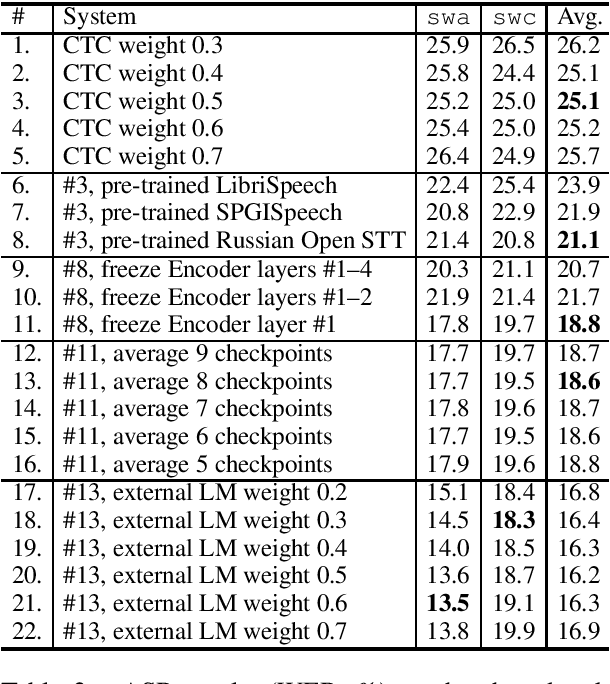
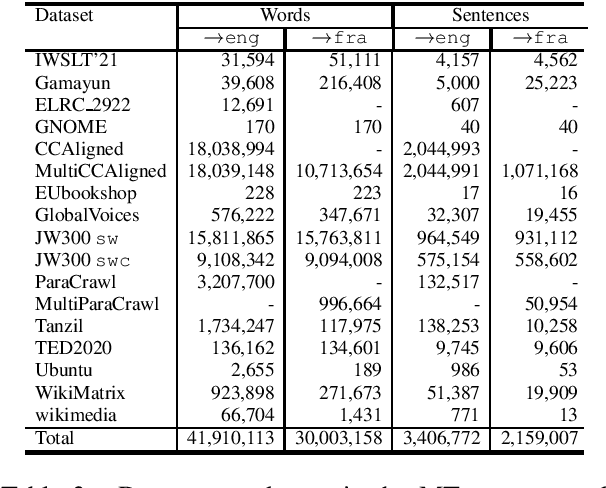
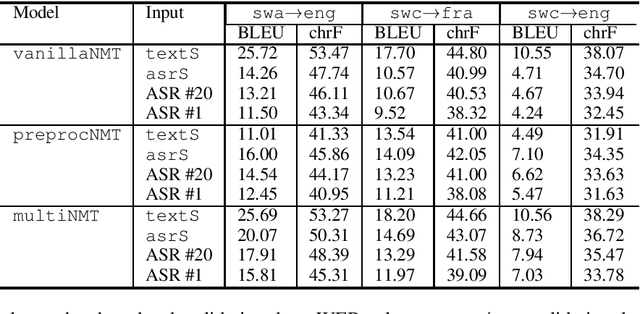
This paper describes the submission to the IWSLT 2021 Low-Resource Speech Translation Shared Task by IMS team. We utilize state-of-the-art models combined with several data augmentation, multi-task and transfer learning approaches for the automatic speech recognition (ASR) and machine translation (MT) steps of our cascaded system. Moreover, we also explore the feasibility of a full end-to-end speech translation (ST) model in the case of very constrained amount of ground truth labeled data. Our best system achieves the best performance among all submitted systems for Congolese Swahili to English and French with BLEU scores 7.7 and 13.7 respectively, and the second best result for Coastal Swahili to English with BLEU score 14.9.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021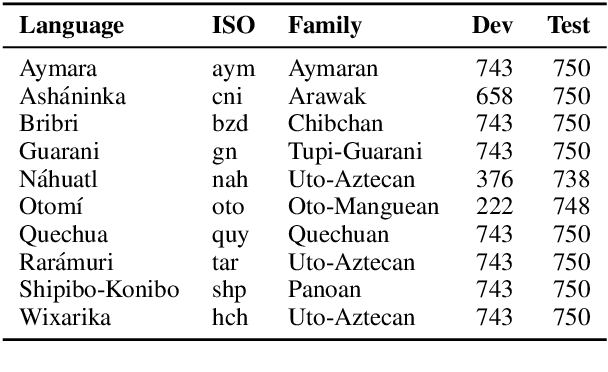
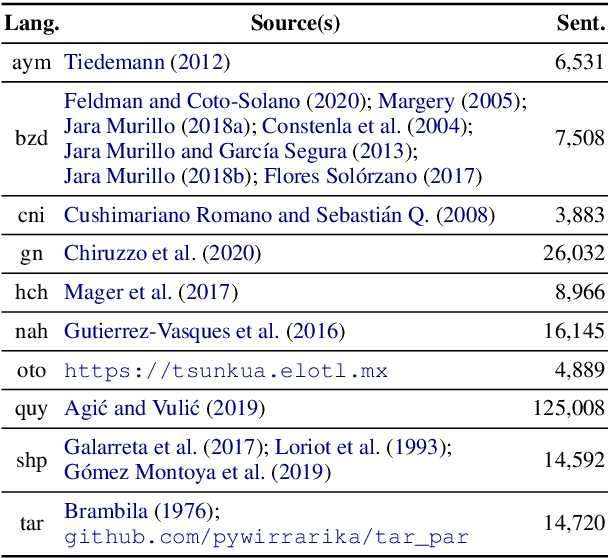
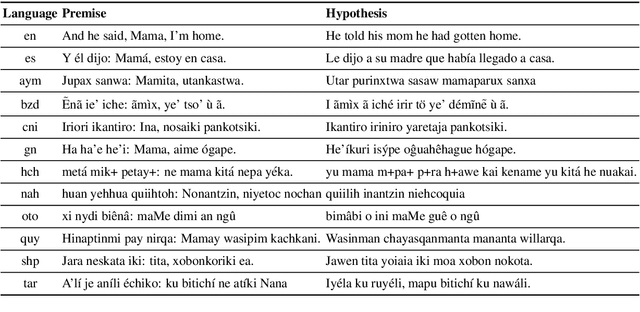

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.
Few-shot Learning for Slot Tagging with Attentive Relational Network
Mar 03, 2021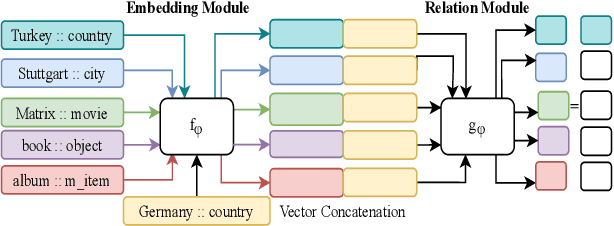

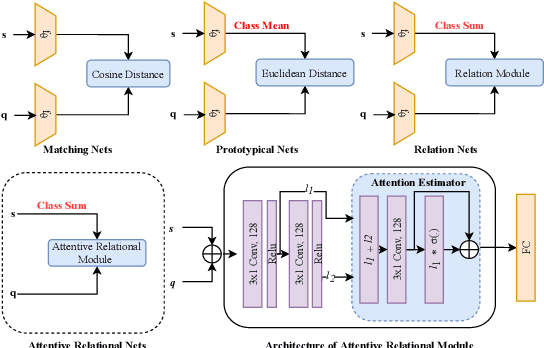
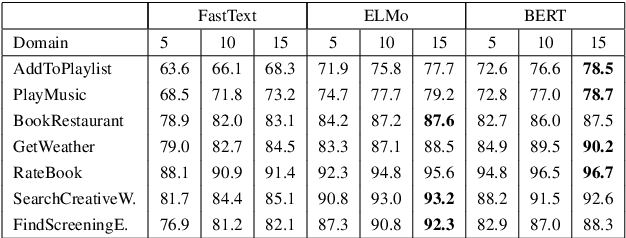
Metric-based learning is a well-known family of methods for few-shot learning, especially in computer vision. Recently, they have been used in many natural language processing applications but not for slot tagging. In this paper, we explore metric-based learning methods in the slot tagging task and propose a novel metric-based learning architecture - Attentive Relational Network. Our proposed method extends relation networks, making them more suitable for natural language processing applications in general, by leveraging pretrained contextual embeddings such as ELMO and BERT and by using attention mechanism. The results on SNIPS data show that our proposed method outperforms other state-of-the-art metric-based learning methods.
Investigations on Audiovisual Emotion Recognition in Noisy Conditions
Mar 02, 2021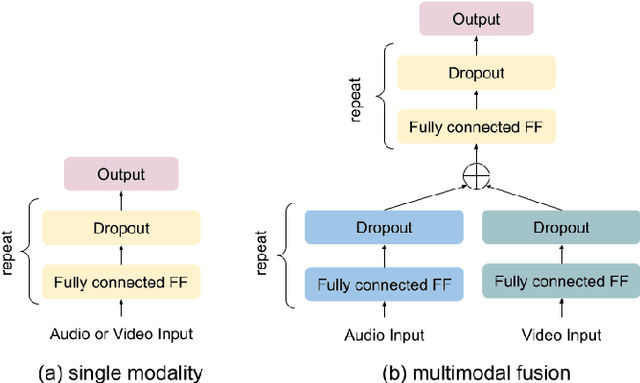

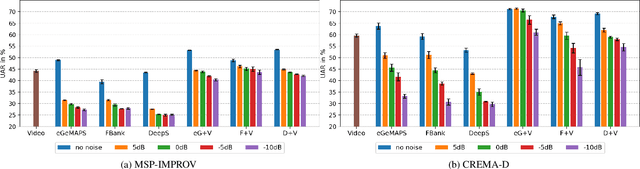
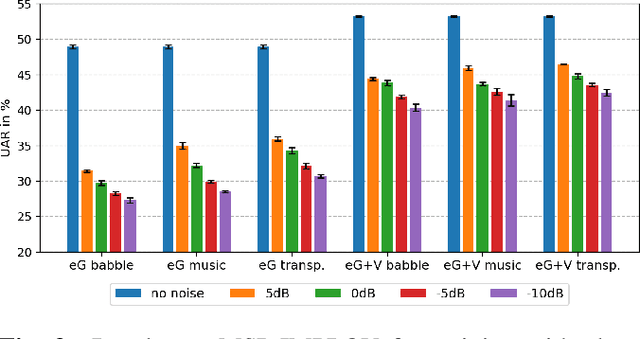
In this paper we explore audiovisual emotion recognition under noisy acoustic conditions with a focus on speech features. We attempt to answer the following research questions: (i) How does speech emotion recognition perform on noisy data? and (ii) To what extend does a multimodal approach improve the accuracy and compensate for potential performance degradation at different noise levels? We present an analytical investigation on two emotion datasets with superimposed noise at different signal-to-noise ratios, comparing three types of acoustic features. Visual features are incorporated with a hybrid fusion approach: The first neural network layers are separate modality-specific ones, followed by at least one shared layer before the final prediction. The results show a significant performance decrease when a model trained on clean audio is applied to noisy data and that the addition of visual features alleviates this effect.
Meta-Learning for improving rare word recognition in end-to-end ASR
Feb 25, 2021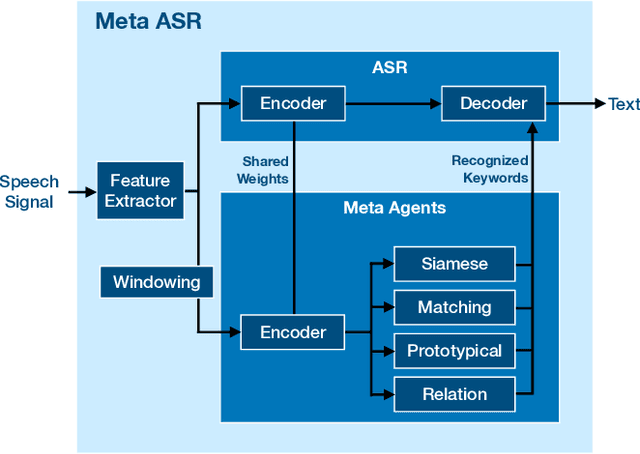
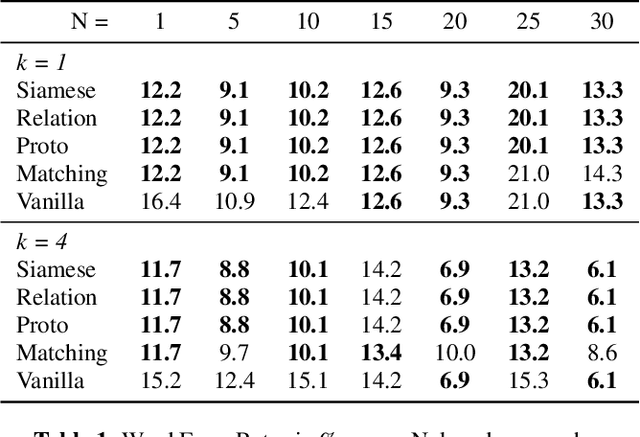
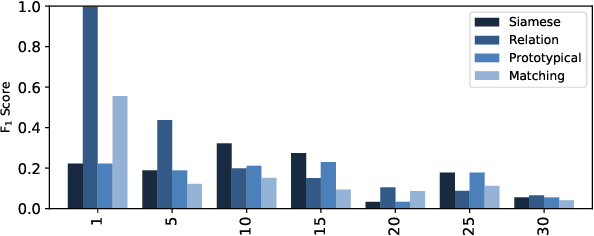
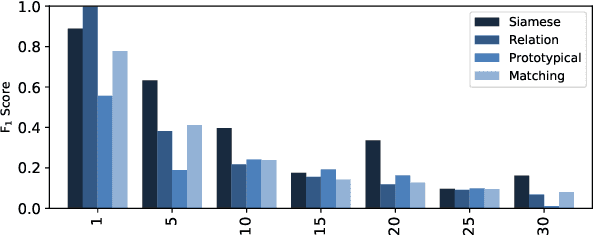
We propose a new method of generating meaningful embeddings for speech, changes to four commonly used meta learning approaches to enable them to perform keyword spotting in continuous signals and an approach of combining their outcomes into an end-to-end automatic speech recognition system to improve rare word recognition. We verify the functionality of each of our three contributions in two experiments exploring their performance for different amounts of classes (N-way) and examples per class (k-shot) in a few-shot setting. We find that the speech embeddings work well and the changes to the meta learning approaches also clearly enable them to perform continuous signal spotting. Despite the interface between keyword spotting and speech recognition being very simple, we are able to consistently improve word error rate by up to 5%.