 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOh, Jeez! or Uh-huh? A Listener-aware Backchannel Predictor on ASR Transcriptions
Apr 10, 2023This paper presents our latest investigation on modeling backchannel in conversations. Motivated by a proactive backchanneling theory, we aim at developing a system which acts as a proactive listener by inserting backchannels, such as continuers and assessment, to influence speakers. Our model takes into account not only lexical and acoustic cues, but also introduces the simple and novel idea of using listener embeddings to mimic different backchanneling behaviours. Our experimental results on the Switchboard benchmark dataset reveal that acoustic cues are more important than lexical cues in this task and their combination with listener embeddings works best on both, manual transcriptions and automatically generated transcriptions.
Conversational Tree Search: A New Hybrid Dialog Task
Mar 17, 2023Conversational interfaces provide a flexible and easy way for users to seek information that may otherwise be difficult or inconvenient to obtain. However, existing interfaces generally fall into one of two categories: FAQs, where users must have a concrete question in order to retrieve a general answer, or dialogs, where users must follow a predefined path but may receive a personalized answer. In this paper, we introduce Conversational Tree Search (CTS) as a new task that bridges the gap between FAQ-style information retrieval and task-oriented dialog, allowing domain-experts to define dialog trees which can then be converted to an efficient dialog policy that learns only to ask the questions necessary to navigate a user to their goal. We collect a dataset for the travel reimbursement domain and demonstrate a baseline as well as a novel deep Reinforcement Learning architecture for this task. Our results show that the new architecture combines the positive aspects of both the FAQ and dialog system used in the baseline and achieves higher goal completion while skipping unnecessary questions.
ArzEn-ST: A Three-way Speech Translation Corpus for Code-Switched Egyptian Arabic - English
Nov 22, 2022



We present our work on collecting ArzEn-ST, a code-switched Egyptian Arabic - English Speech Translation Corpus. This corpus is an extension of the ArzEn speech corpus, which was collected through informal interviews with bilingual speakers. In this work, we collect translations in both directions, monolingual Egyptian Arabic and monolingual English, forming a three-way speech translation corpus. We make the translation guidelines and corpus publicly available. We also report results for baseline systems for machine translation and speech translation tasks. We believe this is a valuable resource that can motivate and facilitate further research studying the code-switching phenomenon from a linguistic perspective and can be used to train and evaluate NLP systems.
Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
Oct 20, 2022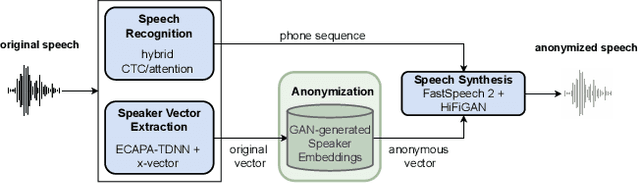
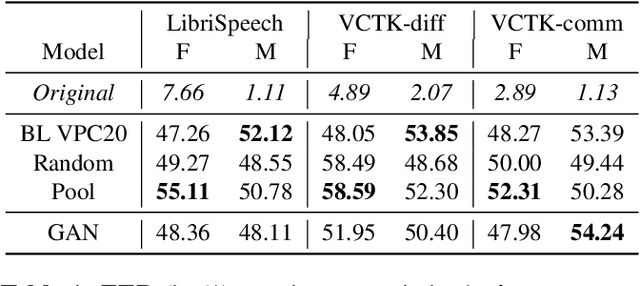
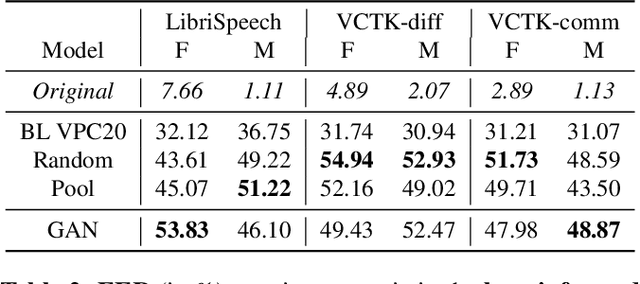
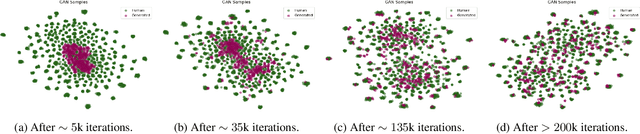
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
How (Not) To Evaluate Explanation Quality
Oct 13, 2022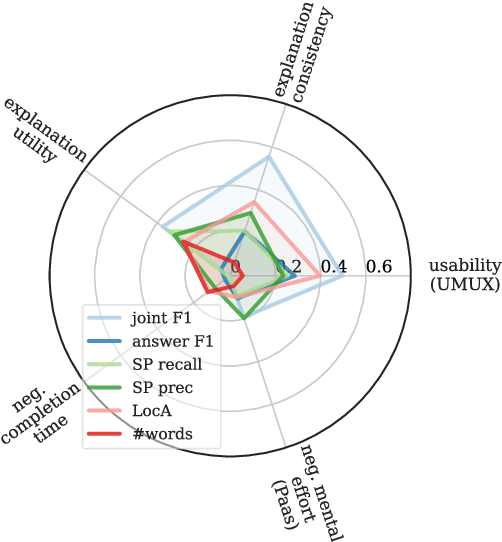

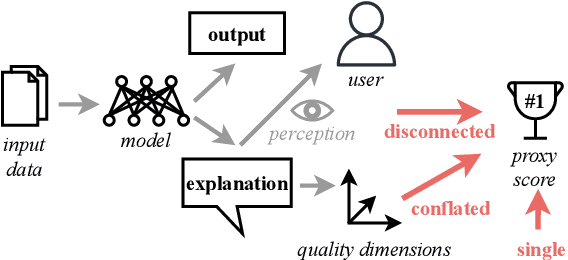

The importance of explainability is increasingly acknowledged in natural language processing. However, it is still unclear how the quality of explanations can be assessed effectively. The predominant approach is to compare proxy scores (such as BLEU or explanation F1) evaluated against gold explanations in the dataset. The assumption is that an increase of the proxy score implies a higher utility of explanations to users. In this paper, we question this assumption. In particular, we (i) formulate desired characteristics of explanation quality that apply across tasks and domains, (ii) point out how current evaluation practices violate those characteristics, and (iii) propose actionable guidelines to overcome obstacles that limit today's evaluation of explanation quality and to enable the development of explainable systems that provide tangible benefits for human users. We substantiate our theoretical claims (i.e., the lack of validity and temporal decline of currently-used proxy scores) with empirical evidence from a crowdsourcing case study in which we investigate the explanation quality of state-of-the-art explainable question answering systems.
Exploring Segmentation Approaches for Neural Machine Translation of Code-Switched Egyptian Arabic-English Text
Oct 11, 2022
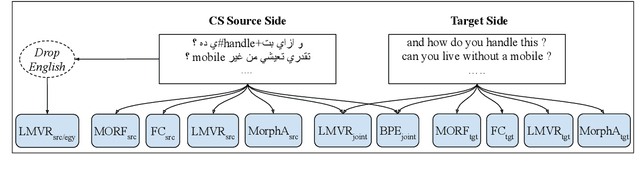
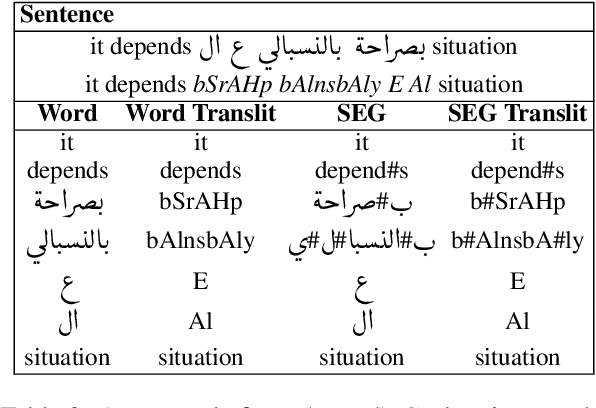
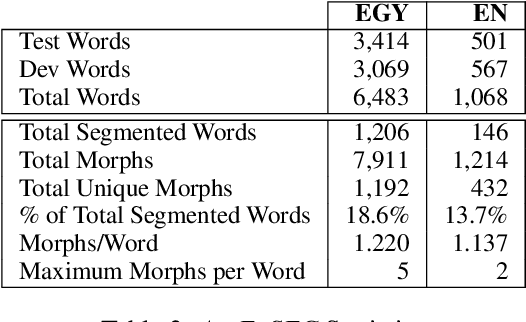
Data sparsity is one of the main challenges posed by Code-switching (CS), which is further exacerbated in the case of morphologically rich languages. For the task of Machine Translation (MT), morphological segmentation has proven successful in alleviating data sparsity in monolingual contexts; however, it has not been investigated for CS settings. In this paper, we study the effectiveness of different segmentation approaches on MT performance, covering morphology-based and frequency-based segmentation techniques. We experiment on MT from code-switched Arabic-English to English. We provide detailed analysis, examining a variety of conditions, such as data size and sentences with different degrees in CS. Empirical results show that morphology-aware segmenters perform the best in segmentation tasks but under-perform in MT. Nevertheless, we find that the choice of the segmentation setup to use for MT is highly dependent on the data size. For extreme low-resource scenarios, a combination of frequency and morphology-based segmentations is shown to perform the best. For more resourced settings, such a combination does not bring significant improvements over the use of frequency-based segmentation.
The Who in Code-Switching: A Case Study for Predicting Egyptian Arabic-English Code-Switching Levels based on Character Profiles
Jul 31, 2022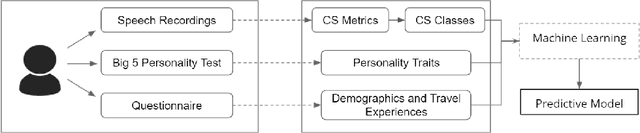

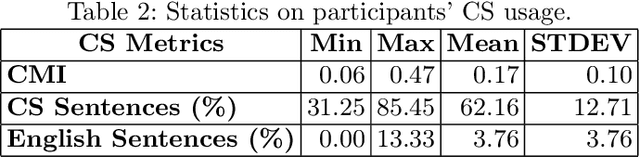
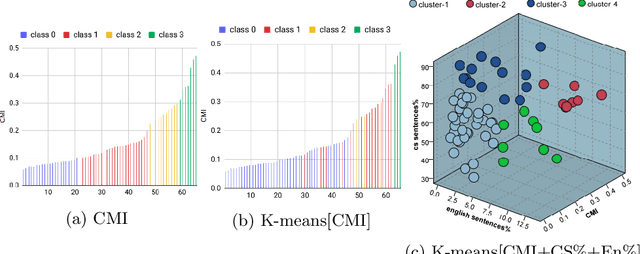
Code-switching (CS) is a common linguistic phenomenon exhibited by multilingual individuals, where they tend to alternate between languages within one single conversation. CS is a complex phenomenon that not only encompasses linguistic challenges, but also contains a great deal of complexity in terms of its dynamic behaviour across speakers. Given that the factors giving rise to CS vary from one country to the other, as well as from one person to the other, CS is found to be a speaker-dependant behaviour, where the frequency by which the foreign language is embedded differs across speakers. While several researchers have looked into predicting CS behaviour from a linguistic point of view, research is still lacking in the task of predicting user CS behaviour from sociological and psychological perspectives. We provide an empirical user study, where we investigate the correlations between users' CS levels and character traits. We conduct interviews with bilinguals and gather information on their profiles, including their demographics, personality traits, and traveling experiences. We then use machine learning (ML) to predict users' CS levels based on their profiles, where we identify the main influential factors in the modeling process. We experiment with both classification as well as regression tasks. Our results show that the CS behaviour is affected by the relation between speakers, travel experiences as well as Neuroticism and Extraversion personality traits.
PoeticTTS -- Controllable Poetry Reading for Literary Studies
Jul 11, 2022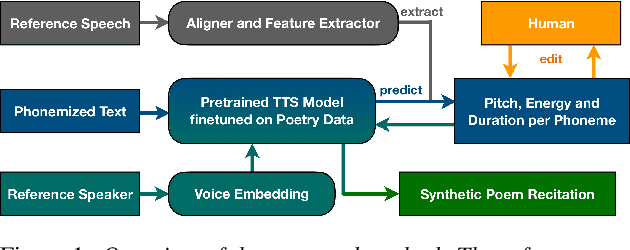

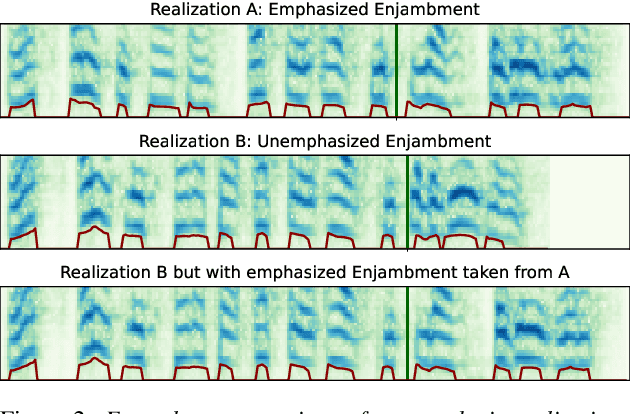
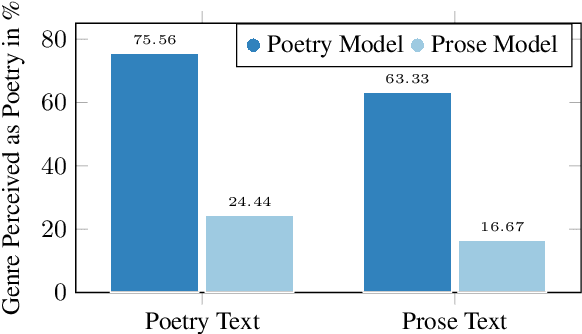
Speech synthesis for poetry is challenging due to specific intonation patterns inherent to poetic speech. In this work, we propose an approach to synthesise poems with almost human like naturalness in order to enable literary scholars to systematically examine hypotheses on the interplay between text, spoken realisation, and the listener's perception of poems. To meet these special requirements for literary studies, we resynthesise poems by cloning prosodic values from a human reference recitation, and afterwards make use of fine-grained prosody control to manipulate the synthetic speech in a human-in-the-loop setting to alter the recitation w.r.t. specific phenomena. We find that finetuning our TTS model on poetry captures poetic intonation patterns to a large extent which is beneficial for prosody cloning and manipulation and verify the success of our approach both in an objective evaluation as well as in human studies.
Speaker Anonymization with Phonetic Intermediate Representations
Jul 11, 2022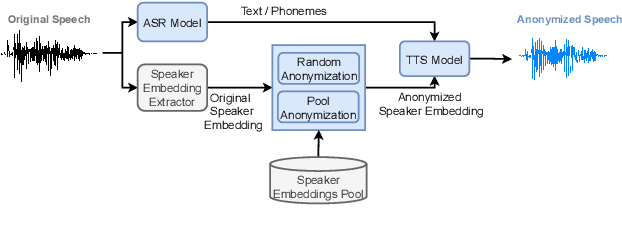
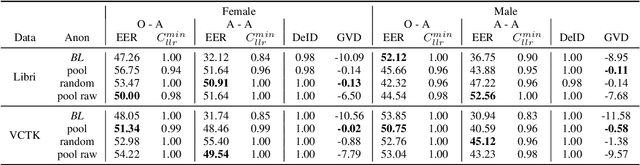
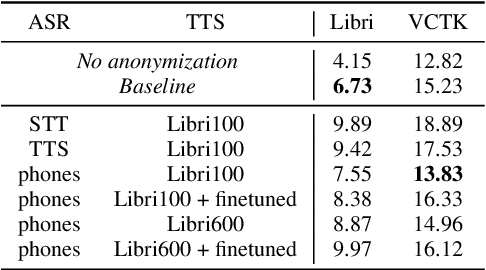

In this work, we propose a speaker anonymization pipeline that leverages high quality automatic speech recognition and synthesis systems to generate speech conditioned on phonetic transcriptions and anonymized speaker embeddings. Using phones as the intermediate representation ensures near complete elimination of speaker identity information from the input while preserving the original phonetic content as much as possible. Our experimental results on LibriSpeech and VCTK corpora reveal two key findings: 1) although automatic speech recognition produces imperfect transcriptions, our neural speech synthesis system can handle such errors, making our system feasible and robust, and 2) combining speaker embeddings from different resources is beneficial and their appropriate normalization is crucial. Overall, our final best system outperforms significantly the baselines provided in the Voice Privacy Challenge 2020 in terms of privacy robustness against a lazy-informed attacker while maintaining high intelligibility and naturalness of the anonymized speech.
Prosody Cloning in Zero-Shot Multispeaker Text-to-Speech
Jun 24, 2022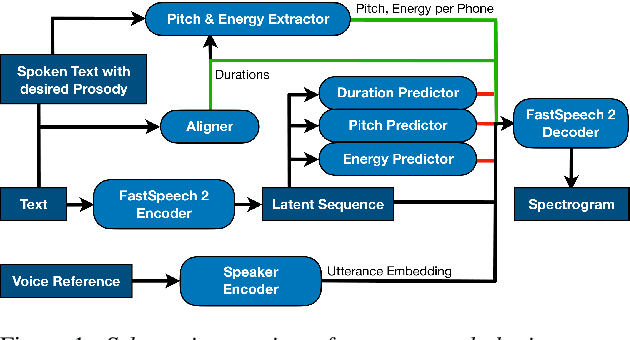
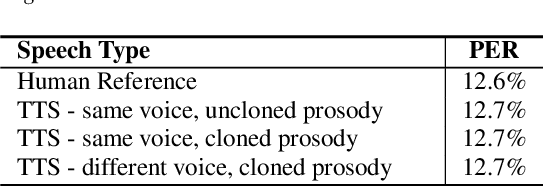

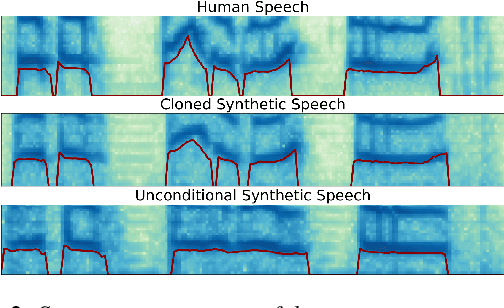
The cloning of a speaker's voice using an untranscribed reference sample is one of the great advances of modern neural text-to-speech (TTS) methods. Approaches for mimicking the prosody of a transcribed reference audio have also been proposed recently. In this work, we bring these two tasks together for the first time through utterance level normalization in conjunction with an utterance level speaker embedding. We further introduce a lightweight aligner for extracting fine-grained prosodic features, that can be finetuned on individual samples within seconds. We show that it is possible to clone the voice of a speaker as well as the prosody of a spoken reference independently without any degradation in quality and high similarity to both original voice and prosody, as our objective evaluation and human study show. All of our code and trained models are available, alongside static and interactive demos.