 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Improved Self-supervised GAN via Adversarial Training
May 14, 2019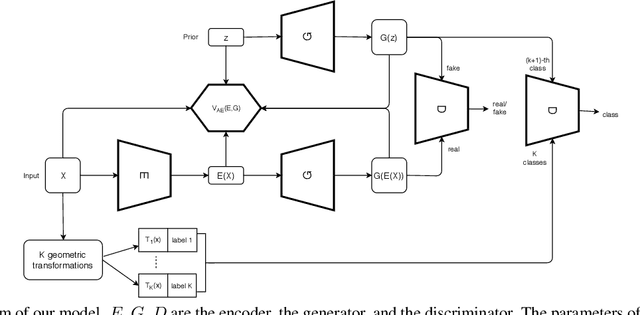

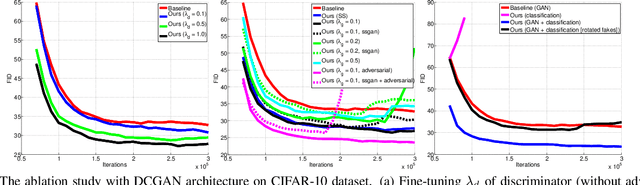
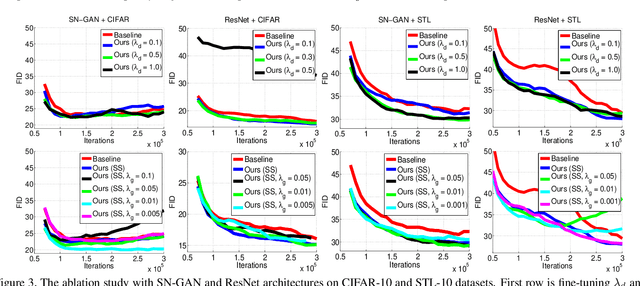
We propose to improve unconditional Generative Adversarial Networks (GAN) by training the self-supervised learning with the adversarial process. In particular, we apply self-supervised learning via the geometric transformation on input images and assign the pseudo-labels to these transformed images. (i) In addition to the GAN task, which distinguishes data (real) versus generated (fake) samples, we train the discriminator to predict the correct pseudo-labels of real transformed samples (classification task). Importantly, we find out that simultaneously training the discriminator to classify the fake class from the pseudo-classes of real samples for the classification task will improve the discriminator and subsequently lead better guides to train generator. (ii) The generator is trained by attempting to confuse the discriminator for not only the GAN task but also the classification task. For the classification task, the generator tries to confuse the discriminator recognizing the transformation of its output as one of the real transformed classes. Especially, we exploit that when the generator creates samples that result in a similar loss (via cross-entropy) as that of the real ones, the training is more stable and the generator distribution tends to match better the data distribution. When integrating our techniques into a state-of-the-art Auto-Encoder (AE) based-GAN model, they help to significantly boost the model's performance and also establish new state-of-the-art Fr\'echet Inception Distance (FID) scores in the literature of unconditional GAN for CIFAR-10 and STL-10 datasets.
Simultaneous Feature Aggregating and Hashing for Compact Binary Code Learning
Apr 24, 2019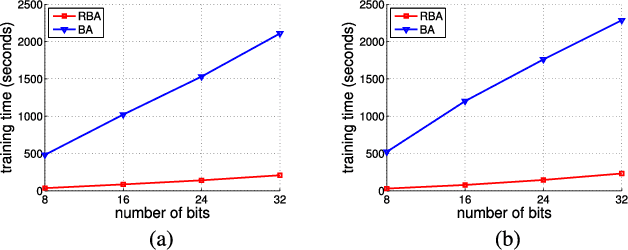
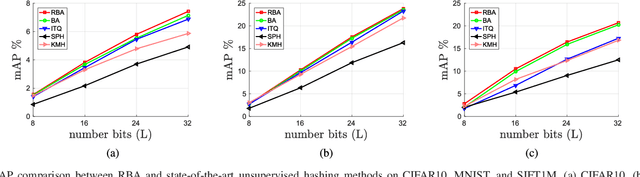
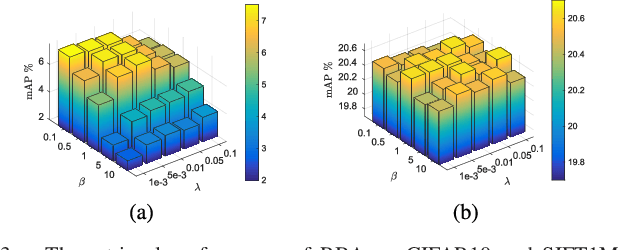
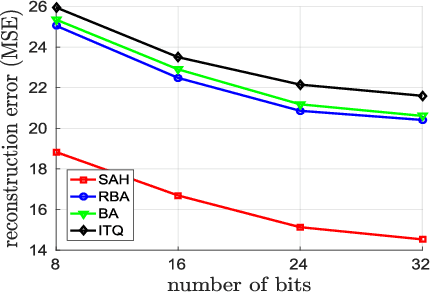
Representing images by compact hash codes is an attractive approach for large-scale content-based image retrieval. In most state-of-the-art hashing-based image retrieval systems, for each image, local descriptors are first aggregated as a global representation vector. This global vector is then subjected to a hashing function to generate a binary hash code. In previous works, the aggregating and the hashing processes are designed independently. Hence these frameworks may generate suboptimal hash codes. In this paper, we first propose a novel unsupervised hashing framework in which feature aggregating and hashing are designed simultaneously and optimized jointly. Specifically, our joint optimization generates aggregated representations that can be better reconstructed by some binary codes. This leads to more discriminative binary hash codes and improved retrieval accuracy. In addition, the proposed method is flexible. It can be extended for supervised hashing. When the data label is available, the framework can be adapted to learn binary codes which minimize the reconstruction loss w.r.t. label vectors. Furthermore, we also propose a fast version of the state-of-the-art hashing method Binary Autoencoder to be used in our proposed frameworks. Extensive experiments on benchmark datasets under various settings show that the proposed methods outperform state-of-the-art unsupervised and supervised hashing methods.
SDRSAC: Semidefinite-Based Randomized Approach for Robust Point Cloud Registration without Correspondences
Apr 14, 2019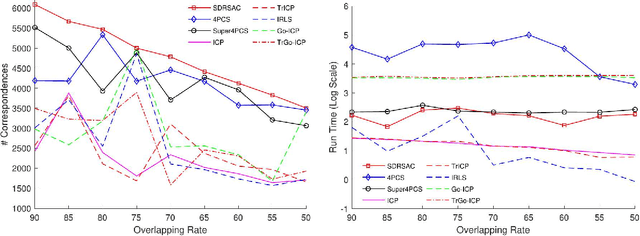
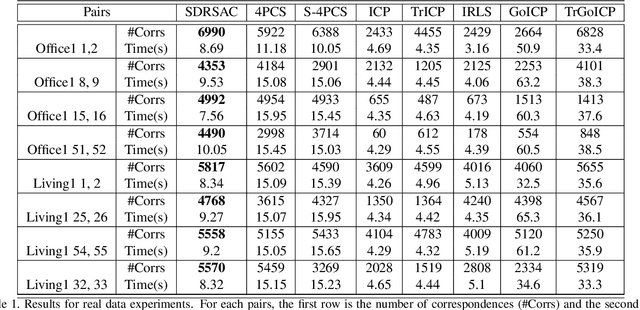
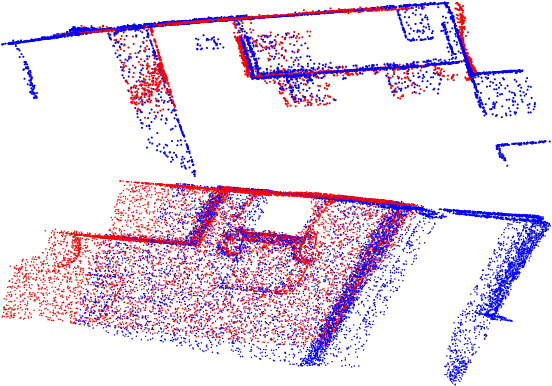
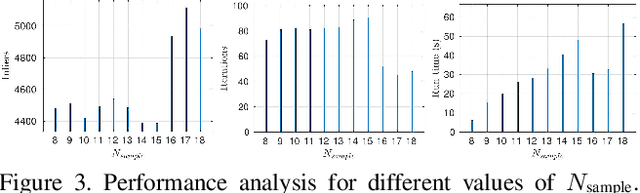
This paper presents a novel randomized algorithm for robust point cloud registration without correspondences. Most existing registration approaches require a set of putative correspondences obtained by extracting invariant descriptors. However, such descriptors could become unreliable in noisy and contaminated settings. In these settings, methods that directly handle input point sets are preferable. Without correspondences, however, conventional randomized techniques require a very large number of samples in order to reach satisfactory solutions. In this paper, we propose a novel approach to address this problem. In particular, our work enables the use of randomized methods for point cloud registration without the need of putative correspondences. By considering point cloud alignment as a special instance of graph matching and employing an efficient semi-definite relaxation, we propose a novel sampling mechanism, in which the size of the sampled subsets can be larger-than-minimal. Our tight relaxation scheme enables fast rejection of the outliers in the sampled sets, resulting in high-quality hypotheses. We conduct extensive experiments to demonstrate that our approach outperforms other state-of-the-art methods. Importantly, our proposed method serves as a generic framework which can be extended to problems with known correspondences.
Detecting Target-Area Link-Flooding DDoS Attacks using Traffic Analysis and Supervised Learning
Mar 01, 2019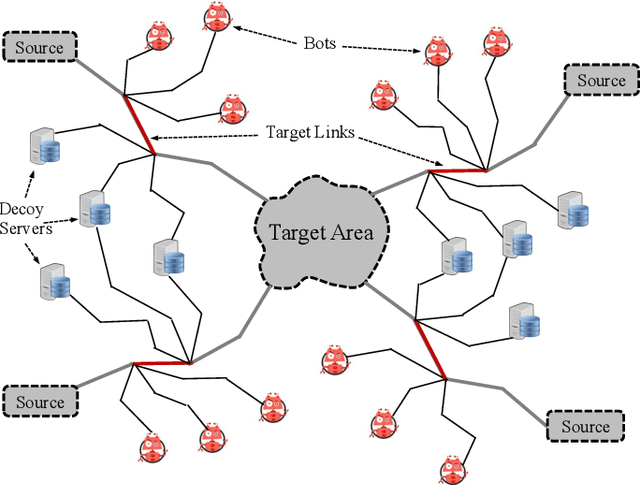
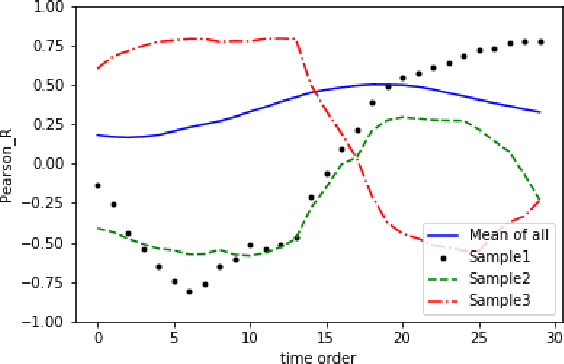
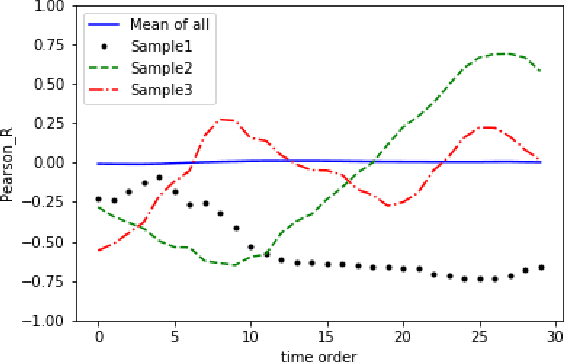
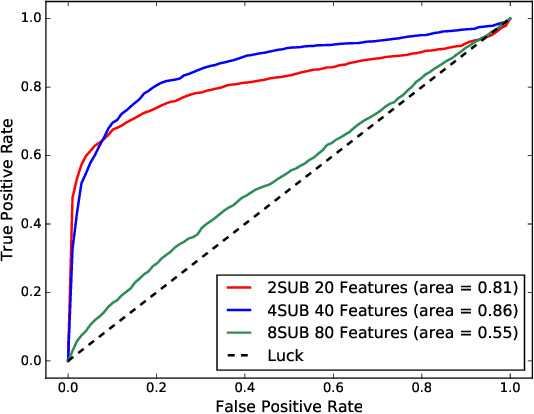
A novel class of extreme link-flooding DDoS (Distributed Denial of Service) attacks is designed to cut off entire geographical areas such as cities and even countries from the Internet by simultaneously targeting a selected set of network links. The Crossfire attack is a target-area link-flooding attack, which is orchestrated in three complex phases. The attack uses a massively distributed large-scale botnet to generate low-rate benign traffic aiming to congest selected network links, so-called target links. The adoption of benign traffic, while simultaneously targeting multiple network links, makes detecting the Crossfire attack a serious challenge. In this paper, we present analytical and emulated results showing hitherto unidentified vulnerabilities in the execution of the attack, such as a correlation between coordination of the botnet traffic and the quality of the attack, and a correlation between the attack distribution and detectability of the attack. Additionally, we identified a warm-up period due to the bot synchronization. For attack detection, we report results of using two supervised machine learning approaches: Support Vector Machine (SVM) and Random Forest (RF) for classification of network traffic to normal and abnormal traffic, i.e, attack traffic. These machine learning models have been trained in various scenarios using the link volume as the main feature set.
* arXiv admin note: text overlap with arXiv:1801.00235
Improving GAN with neighbors embedding and gradient matching
Nov 04, 2018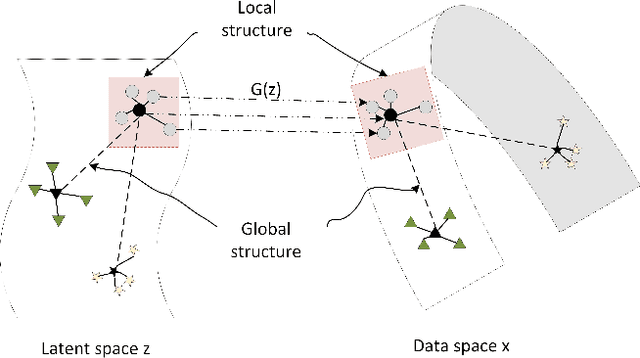
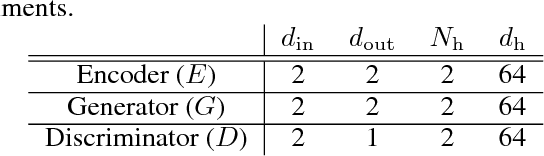
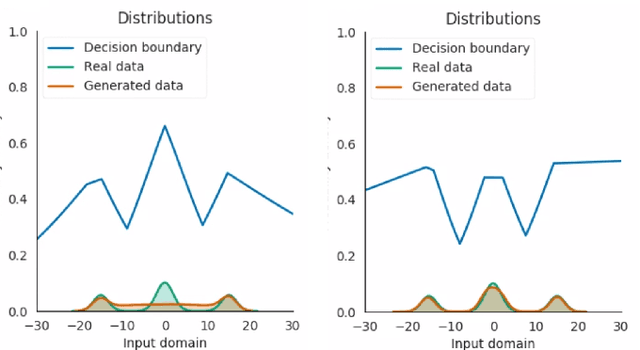

We propose two new techniques for training Generative Adversarial Networks (GANs). Our objectives are to alleviate mode collapse in GAN and improve the quality of the generated samples. First, we propose neighbor embedding, a manifold learning-based regularization to explicitly retain local structures of latent samples in the generated samples. This prevents generator from producing nearly identical data samples from different latent samples, and reduces mode collapse. We propose an inverse t-SNE regularizer to achieve this. Second, we propose a new technique, gradient matching, to align the distributions of the generated samples and the real samples. As it is challenging to work with high-dimensional sample distributions, we propose to align these distributions through the scalar discriminator scores. We constrain the difference between the discriminator scores of the real samples and generated ones. We further constrain the difference between the gradients of these discriminator scores. We derive these constraints from Taylor approximations of the discriminator function. We perform experiments to demonstrate that our proposed techniques are computationally simple and easy to be incorporated in existing systems. When Gradient matching and Neighbour embedding are applied together, our GN-GAN achieves outstanding results on 1D/2D synthetic, CIFAR-10 and STL-10 datasets, e.g. FID score of $30.80$ for the STL-10 dataset. Our code is available at: https://github.com/tntrung/gan
Supervised Hashing with End-to-End Binary Deep Neural Network
Oct 27, 2018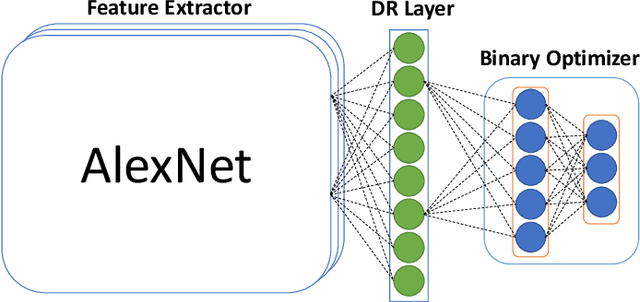
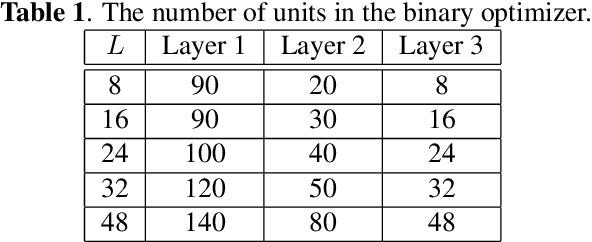
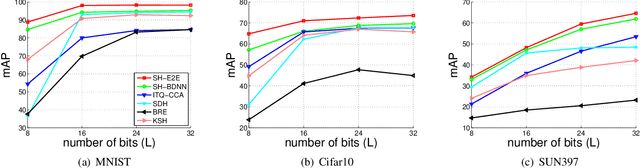
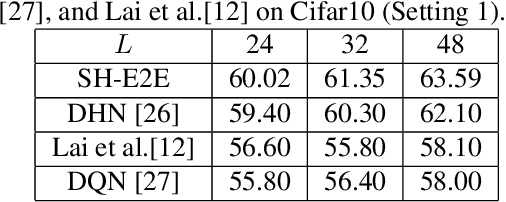
Image hashing is a popular technique applied to large scale content-based visual retrieval due to its compact and efficient binary codes. Our work proposes a new end-to-end deep network architecture for supervised hashing which directly learns binary codes from input images and maintains good properties over binary codes such as similarity preservation, independence, and balancing. Furthermore, we also propose a new learning scheme that can cope with the binary constrained loss function. The proposed algorithm not only is scalable for learning over large-scale datasets but also outperforms state-of-the-art supervised hashing methods, which are illustrated throughout extensive experiments from various image retrieval benchmarks.
DOPING: Generative Data Augmentation for Unsupervised Anomaly Detection with GAN
Aug 24, 2018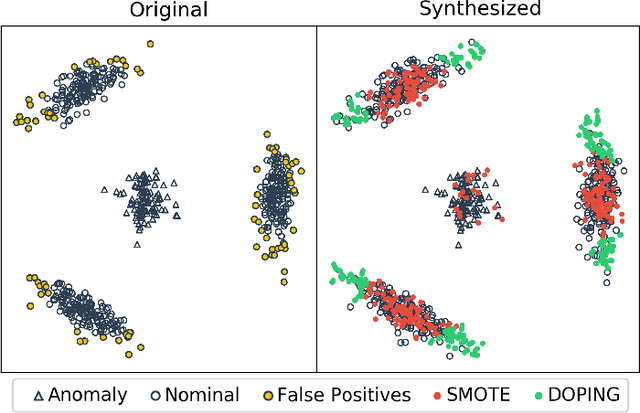

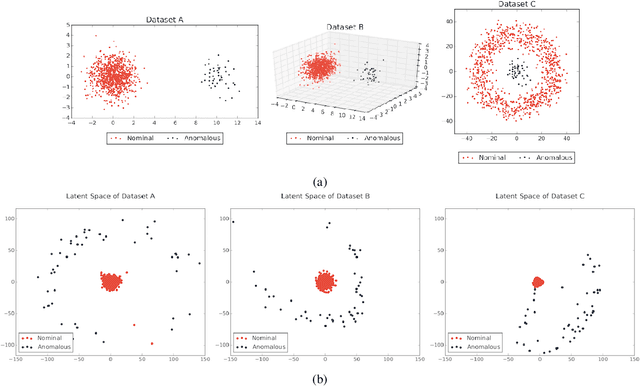
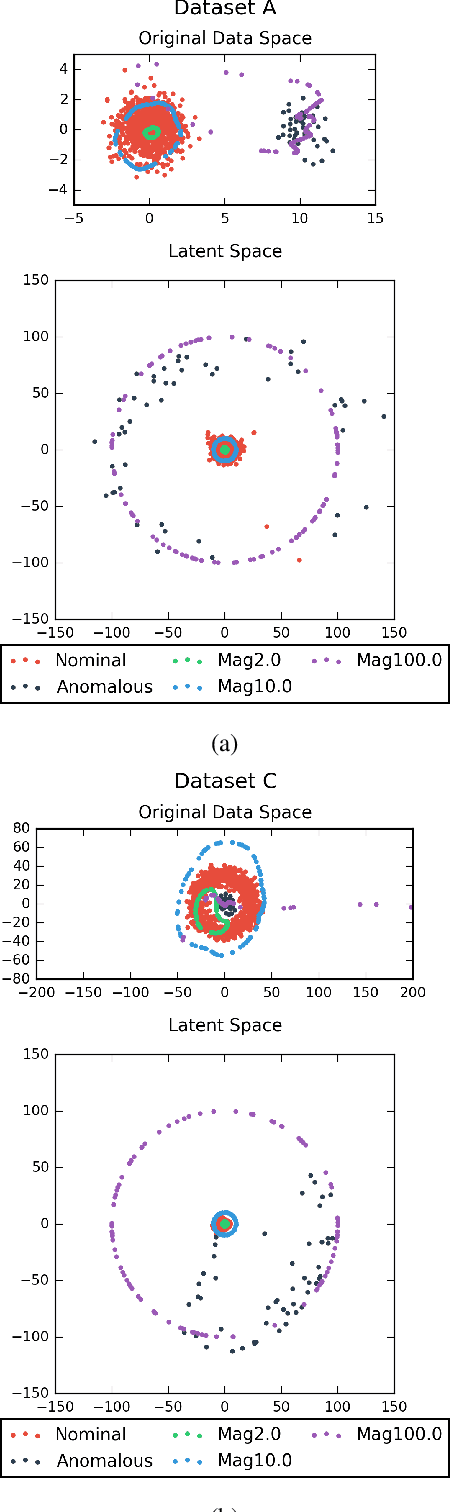
Recently, the introduction of the generative adversarial network (GAN) and its variants has enabled the generation of realistic synthetic samples, which has been used for enlarging training sets. Previous work primarily focused on data augmentation for semi-supervised and supervised tasks. In this paper, we instead focus on unsupervised anomaly detection and propose a novel generative data augmentation framework optimized for this task. In particular, we propose to oversample infrequent normal samples - normal samples that occur with small probability, e.g., rare normal events. We show that these samples are responsible for false positives in anomaly detection. However, oversampling of infrequent normal samples is challenging for real-world high-dimensional data with multimodal distributions. To address this challenge, we propose to use a GAN variant known as the adversarial autoencoder (AAE) to transform the high-dimensional multimodal data distributions into low-dimensional unimodal latent distributions with well-defined tail probability. Then, we systematically oversample at the `edge' of the latent distributions to increase the density of infrequent normal samples. We show that our oversampling pipeline is a unified one: it is generally applicable to datasets with different complex data distributions. To the best of our knowledge, our method is the first data augmentation technique focused on improving performance in unsupervised anomaly detection. We validate our method by demonstrating consistent improvements across several real-world datasets.
Deep Adaptive Temporal Pooling for Activity Recognition
Aug 22, 2018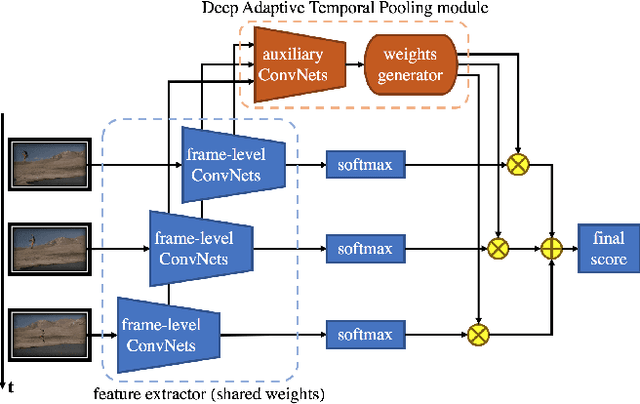

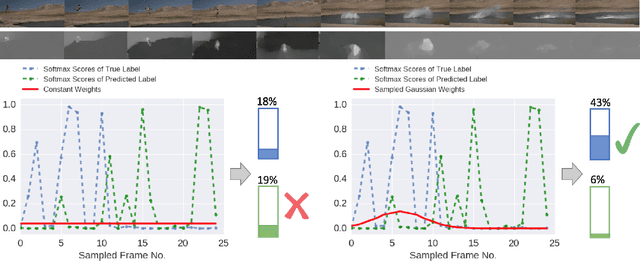

Deep neural networks have recently achieved competitive accuracy for human activity recognition. However, there is room for improvement, especially in modeling long-term temporal importance and determining the activity relevance of different temporal segments in a video. To address this problem, we propose a learnable and differentiable module: Deep Adaptive Temporal Pooling (DATP). DATP applies a self-attention mechanism to adaptively pool the classification scores of different video segments. Specifically, using frame-level features, DATP regresses importance of different temporal segments and generates weights for them. Remarkably, DATP is trained using only the video-level label. There is no need of additional supervision except video-level activity class label. We conduct extensive experiments to investigate various input features and different weight models. Experimental results show that DATP can learn to assign large weights to key video segments. More importantly, DATP can improve training of frame-level feature extractor. This is because relevant temporal segments are assigned large weights during back-propagation. Overall, we achieve state-of-the-art performance on UCF101, HMDB51 and Kinetics datasets.
Defense Against Adversarial Attacks with Saak Transform
Aug 06, 2018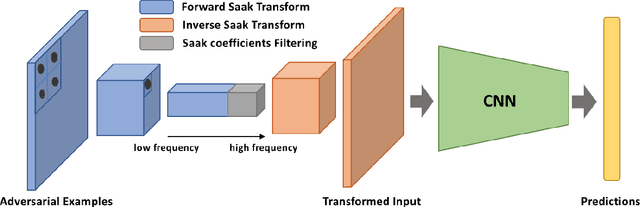
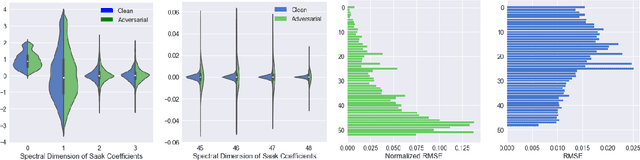

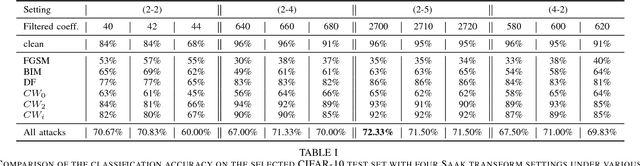
Deep neural networks (DNNs) are known to be vulnerable to adversarial perturbations, which imposes a serious threat to DNN-based decision systems. In this paper, we propose to apply the lossy Saak transform to adversarially perturbed images as a preprocessing tool to defend against adversarial attacks. Saak transform is a recently-proposed state-of-the-art for computing the spatial-spectral representations of input images. Empirically, we observe that outputs of the Saak transform are very discriminative in differentiating adversarial examples from clean ones. Therefore, we propose a Saak transform based preprocessing method with three steps: 1) transforming an input image to a joint spatial-spectral representation via the forward Saak transform, 2) apply filtering to its high-frequency components, and, 3) reconstructing the image via the inverse Saak transform. The processed image is found to be robust against adversarial perturbations. We conduct extensive experiments to investigate various settings of the Saak transform and filtering functions. Without harming the decision performance on clean images, our method outperforms state-of-the-art adversarial defense methods by a substantial margin on both the CIFAR-10 and ImageNet datasets. Importantly, our results suggest that adversarial perturbations can be effectively and efficiently defended using state-of-the-art frequency analysis.
Binary Constrained Deep Hashing Network for Image Retrieval without Manual Annotation
Aug 02, 2018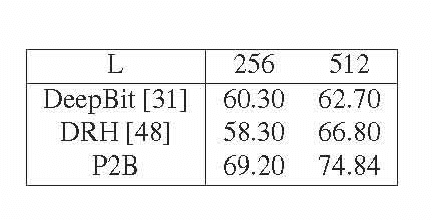
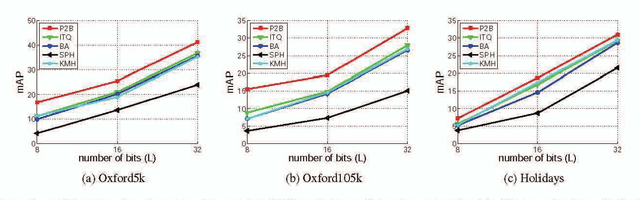
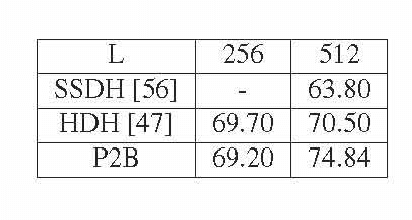
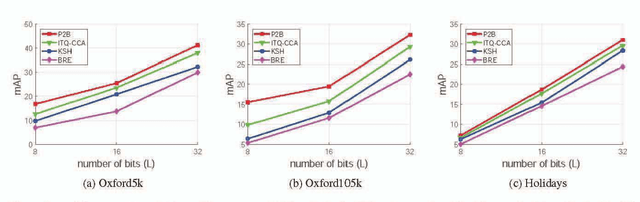
Learning compact binary codes for image retrieval problem using deep neural networks has attracted increasing attention recently. However, training deep hashing networks is challenging due to the binary constraints on the hash codes, the similarity preserving property, and the requirement for a vast amount of labelled images. To the best of our knowledge, none of the existing methods has tackled all of these challenges completely in a unified framework. In this work, we propose a novel end-to-end deep hashing approach, which is trained to produce binary codes directly from image pixels without the need of manual annotation. In particular, we propose a novel pairwise binary constrained loss function, which simultaneously encodes the distances between pairs of hash codes, and the binary quantization error. In order to train the network with the proposed loss function, we also propose an efficient parameter learning algorithm. In addition, to provide similar/dissimilar training images to train the network, we exploit 3D models reconstructed from unlabelled images for automatic generation of enormous similar/dissimilar pairs. Extensive experiments on three image retrieval benchmark datasets demonstrate the superior performance of the proposed method over the state-of-the-art hashing methods on the image retrieval problem.