 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Alignment: Finding Semantically Consistent Ground-truth for Facial Landmark Detection
Mar 26, 2019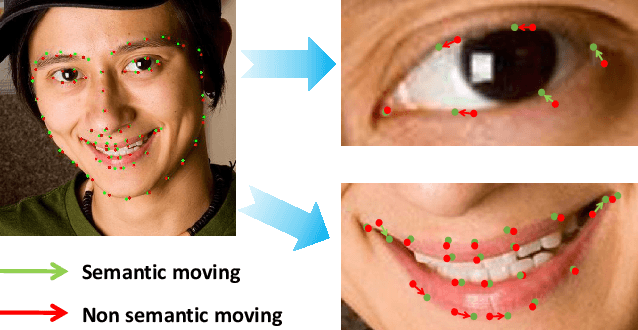
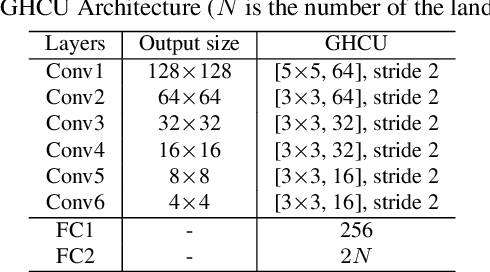
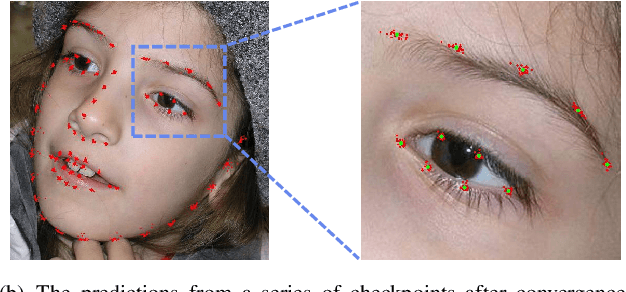
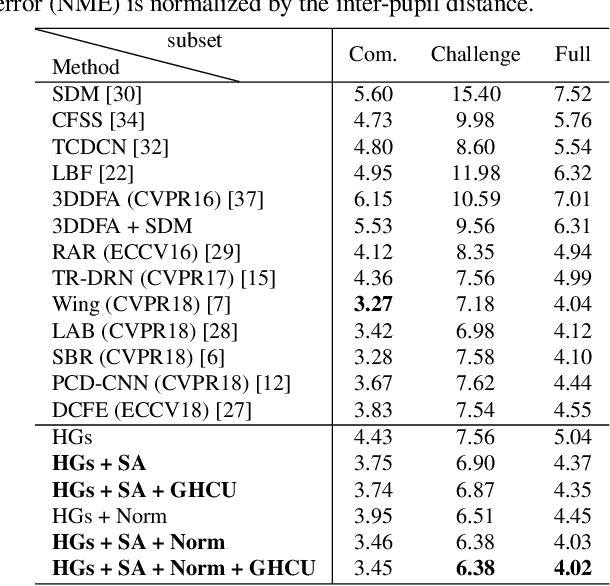
Recently, deep learning based facial landmark detection has achieved great success. Despite this, we notice that the semantic ambiguity greatly degrades the detection performance. Specifically, the semantic ambiguity means that some landmarks (e.g. those evenly distributed along the face contour) do not have clear and accurate definition, causing inconsistent annotations by annotators. Accordingly, these inconsistent annotations, which are usually provided by public databases, commonly work as the ground-truth to supervise network training, leading to the degraded accuracy. To our knowledge, little research has investigated this problem. In this paper, we propose a novel probabilistic model which introduces a latent variable, i.e. the 'real' ground-truth which is semantically consistent, to optimize. This framework couples two parts (1) training landmark detection CNN and (2) searching the 'real' ground-truth. These two parts are alternatively optimized: the searched 'real' ground-truth supervises the CNN training; and the trained CNN assists the searching of 'real' ground-truth. In addition, to recover the unconfidently predicted landmarks due to occlusion and low quality, we propose a global heatmap correction unit (GHCU) to correct outliers by considering the global face shape as a constraint. Extensive experiments on both image-based (300W and AFLW) and video-based (300-VW) databases demonstrate that our method effectively improves the landmark detection accuracy and achieves the state of the art performance.
Deep Metric Learning by Online Soft Mining and Class-Aware Attention
Nov 04, 2018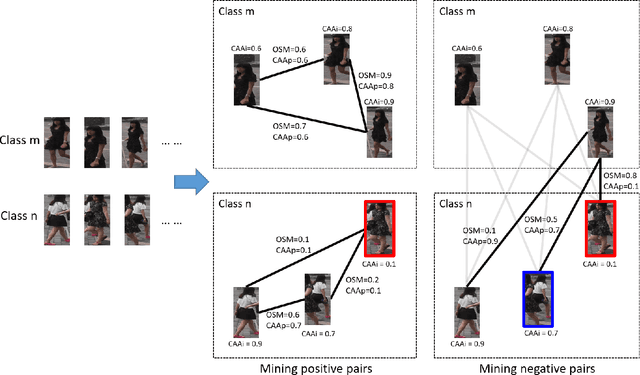
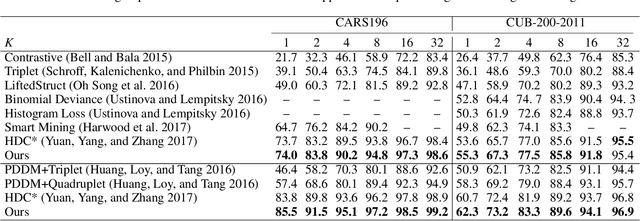


Deep metric learning aims to learn a deep embedding that can capture the semantic similarity of data points. Given the availability of massive training samples, deep metric learning is known to suffer from slow convergence due to a large fraction of trivial samples. Therefore, most existing methods generally resort to sample mining strategies for selecting nontrivial samples to accelerate convergence and improve performance. In this work, we identify two critical limitations of the sample mining methods, and provide solutions for both of them. First, previous mining methods assign one binary score to each sample, i.e., dropping or keeping it, so they only selects a subset of relevant samples in a mini-batch. Therefore, we propose a novel sample mining method, called Online Soft Mining (OSM), which assigns one continuous score to each sample to make use of all samples in the mini-batch. OSM learns extended manifolds that preserve useful intraclass variances by focusing on more similar positives. Second, the existing methods are easily influenced by outliers as they are generally included in the mined subset. To address this, we introduce Class-Aware Attention (CAA) that assigns little attention to abnormal data samples. Furthermore, by combining OSM and CAA, we propose a novel weighted contrastive loss to learn discriminative embeddings. Extensive experiments on two fine-grained visual categorisation datasets and two video-based person re-identification benchmarks show that our method significantly outperforms the state-of-the-art.