 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Choices for X-vector Based Speaker Anonymization
May 18, 2020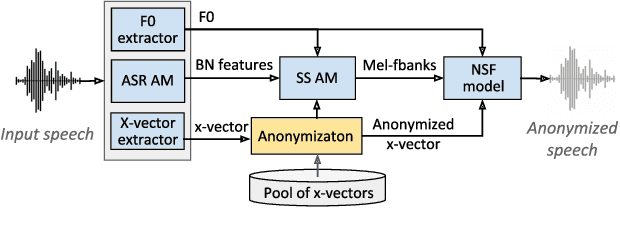
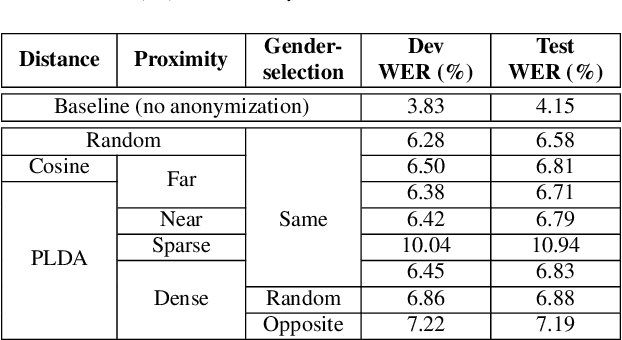
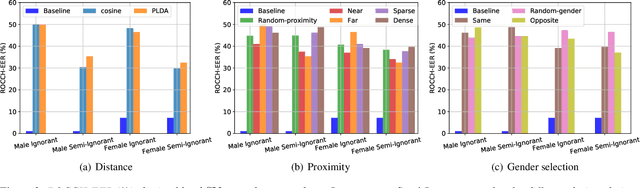
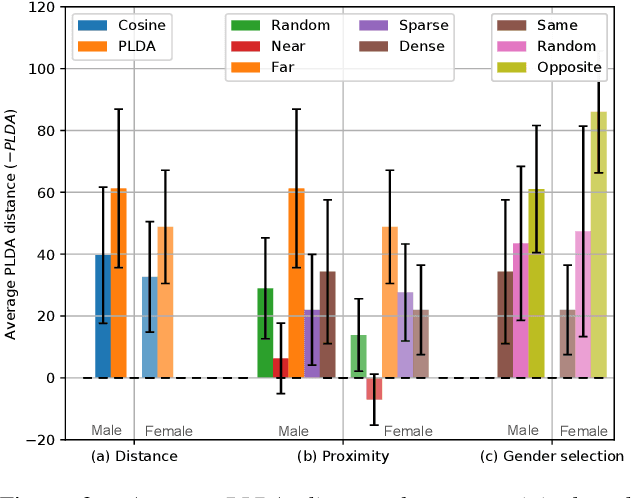
The recently proposed x-vector based anonymization scheme converts any input voice into that of a random pseudo-speaker. In this paper, we present a flexible pseudo-speaker selection technique as a baseline for the first VoicePrivacy Challenge. We explore several design choices for the distance metric between speakers, the region of x-vector space where the pseudo-speaker is picked, and gender selection. To assess the strength of anonymization achieved, we consider attackers using an x-vector based speaker verification system who may use original or anonymized speech for enrollment, depending on their knowledge of the anonymization scheme. The Equal Error Rate (EER) achieved by the attackers and the decoding Word Error Rate (WER) over anonymized data are reported as the measures of privacy and utility. Experiments are performed using datasets derived from LibriSpeech to find the optimal combination of design choices in terms of privacy and utility.
Introducing the VoicePrivacy Initiative
May 13, 2020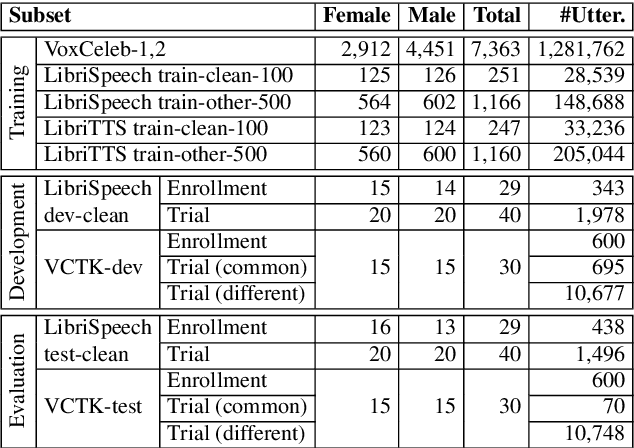
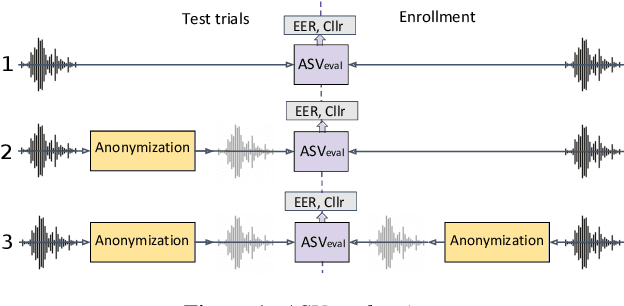
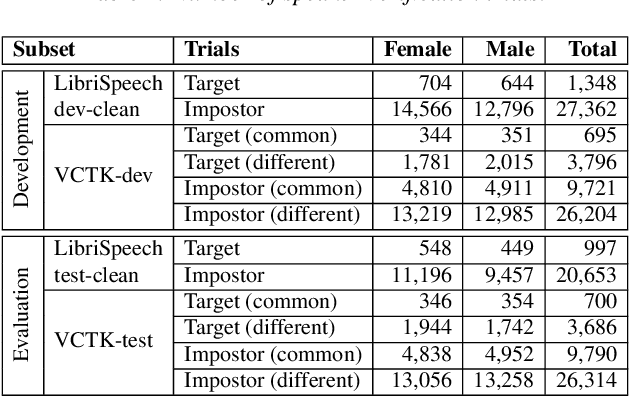
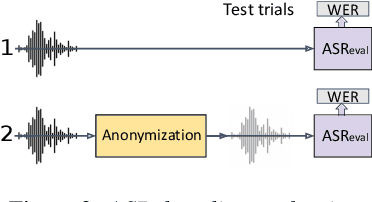
The VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this paper, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
Exploring Gaussian mixture model framework for speaker adaptation of deep neural network acoustic models
Mar 15, 2020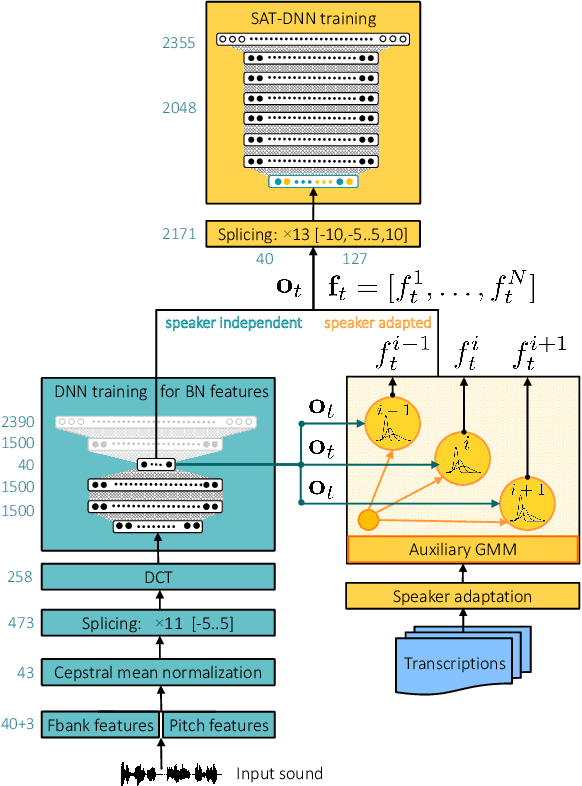
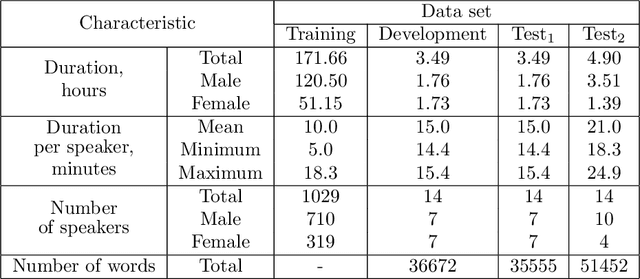
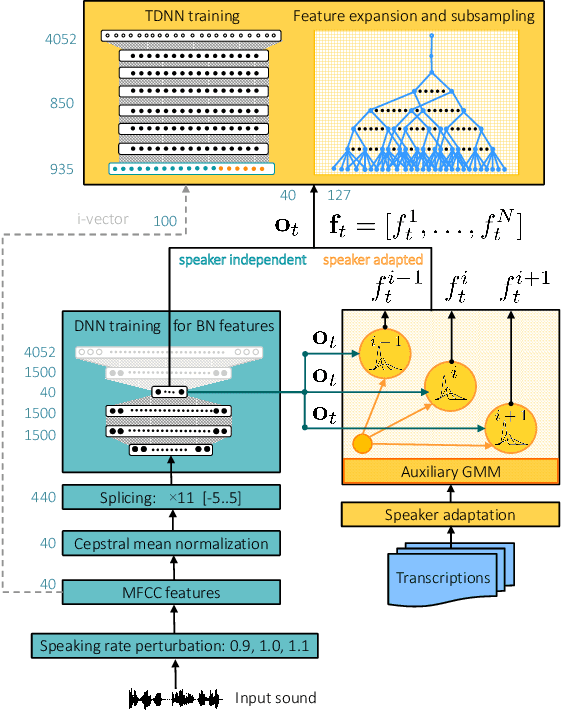
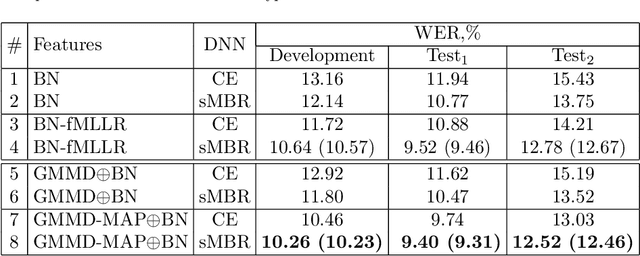
In this paper we investigate the GMM-derived (GMMD) features for adaptation of deep neural network (DNN) acoustic models. The adaptation of the DNN trained on GMMD features is done through the maximum a posteriori (MAP) adaptation of the auxiliary GMM model used for GMMD feature extraction. We explore fusion of the adapted GMMD features with conventional features, such as bottleneck and MFCC features, in two different neural network architectures: DNN and time-delay neural network (TDNN). We analyze and compare different types of adaptation techniques such as i-vectors and feature-space adaptation techniques based on maximum likelihood linear regression (fMLLR) with the proposed adaptation approach, and explore their complementarity using various types of fusion such as feature level, posterior level, lattice level and others in order to discover the best possible way of combination. Experimental results on the TED-LIUM corpus show that the proposed adaptation technique can be effectively integrated into DNN and TDNN setups at different levels and provide additional gain in recognition performance: up to 6% of relative word error rate reduction (WERR) over the strong feature-space adaptation techniques based on maximum likelihood linear regression (fMLLR) speaker adapted DNN baseline, and up to 18% of relative WERR in comparison with a speaker independent (SI) DNN baseline model, trained on conventional features. For TDNN models the proposed approach achieves up to 26% of relative WERR in comparison with a SI baseline, and up 13% in comparison with the model adapted by using i-vectors. The analysis of the adapted GMMD features from various points of view demonstrates their effectiveness at different levels.
Dialogue history integration into end-to-end signal-to-concept spoken language understanding systems
Feb 14, 2020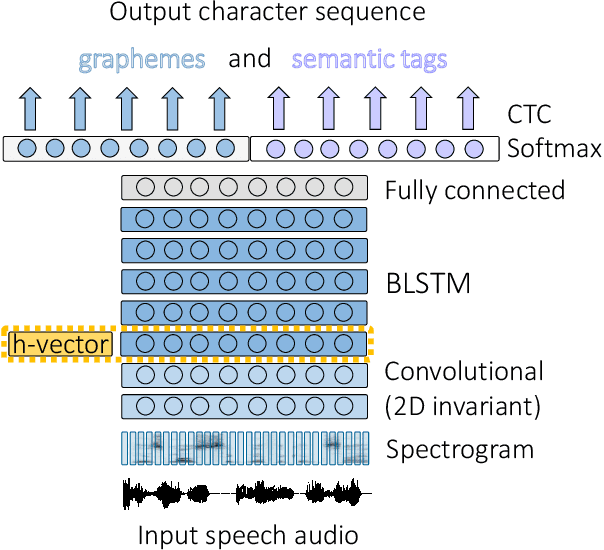
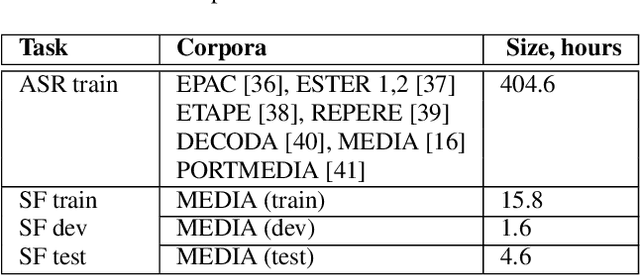
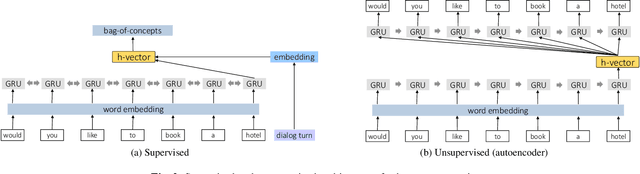

This work investigates the embeddings for representing dialog history in spoken language understanding (SLU) systems. We focus on the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. We proposed to integrate dialogue history into an end-to-end signal-to-concept SLU system. The dialog history is represented in the form of dialog history embedding vectors (so-called h-vectors) and is provided as an additional information to end-to-end SLU models in order to improve the system performance. Three following types of h-vectors are proposed and experimentally evaluated in this paper: (1) supervised-all embeddings predicting bag-of-concepts expected in the answer of the user from the last dialog system response; (2) supervised-freq embeddings focusing on predicting only a selected set of semantic concept (corresponding to the most frequent errors in our experiments); and (3) unsupervised embeddings. Experiments on the MEDIA corpus for the semantic slot filling task demonstrate that the proposed h-vectors improve the model performance.
ON-TRAC Consortium End-to-End Speech Translation Systems for the IWSLT 2019 Shared Task
Oct 30, 2019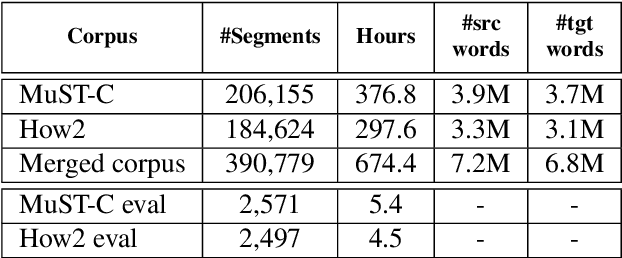
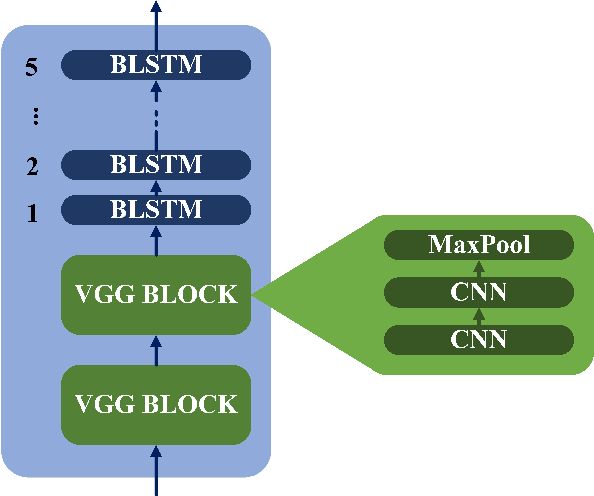
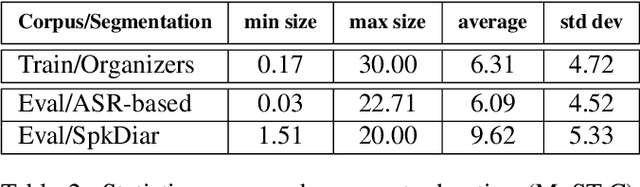
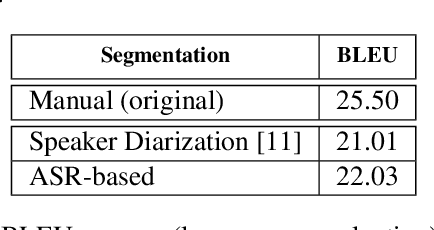
This paper describes the ON-TRAC Consortium translation systems developed for the end-to-end model task of IWSLT Evaluation 2019 for the English-to-Portuguese language pair. ON-TRAC Consortium is composed of researchers from three French academic laboratories: LIA (Avignon Universit\'e), LIG (Universit\'e Grenoble Alpes), and LIUM (Le Mans Universit\'e). A single end-to-end model built as a neural encoder-decoder architecture with attention mechanism was used for two primary submissions corresponding to the two EN-PT evaluations sets: (1) TED (MuST-C) and (2) How2. In this paper, we notably investigate impact of pooling heterogeneous corpora for training, impact of target tokenization (characters or BPEs), impact of speech input segmentation and we also compare our best end-to-end model (BLEU of 26.91 on MuST-C and 43.82 on How2 validation sets) to a pipeline (ASR+MT) approach.
Recent Advances in End-to-End Spoken Language Understanding
Sep 29, 2019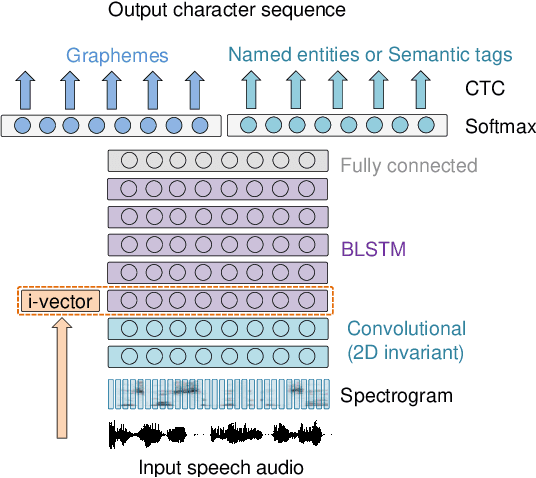
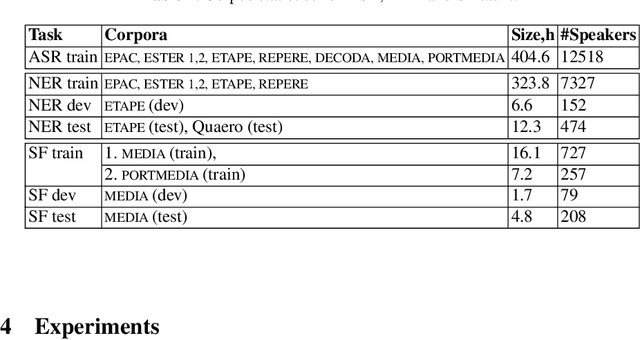
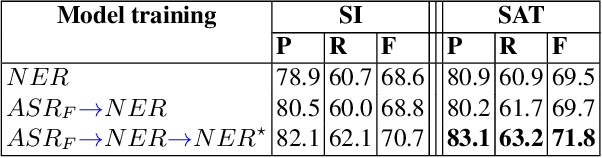
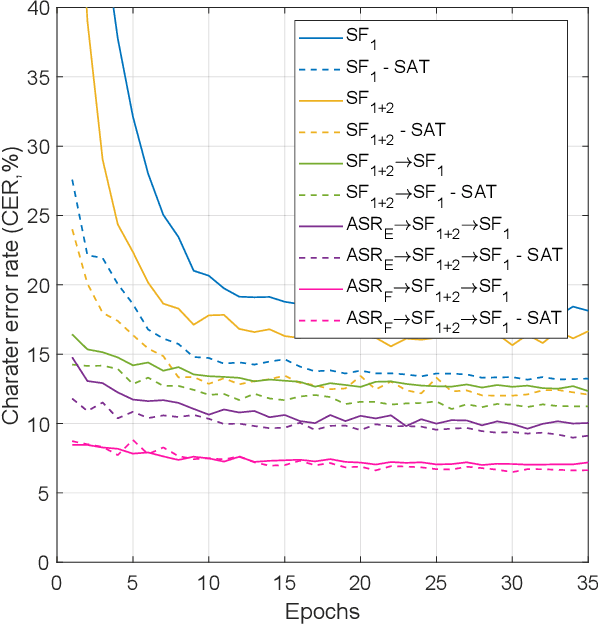
This work investigates spoken language understanding (SLU) systems in the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. Two SLU tasks are considered: named entity recognition (NER) and semantic slot filling (SF). For these tasks, in order to improve the model performance, we explore various techniques including speaker adaptation, a modification of the connectionist temporal classification (CTC) training criterion, and sequential pretraining.
Curriculum-based transfer learning for an effective end-to-end spoken language understanding and domain portability
Jun 18, 2019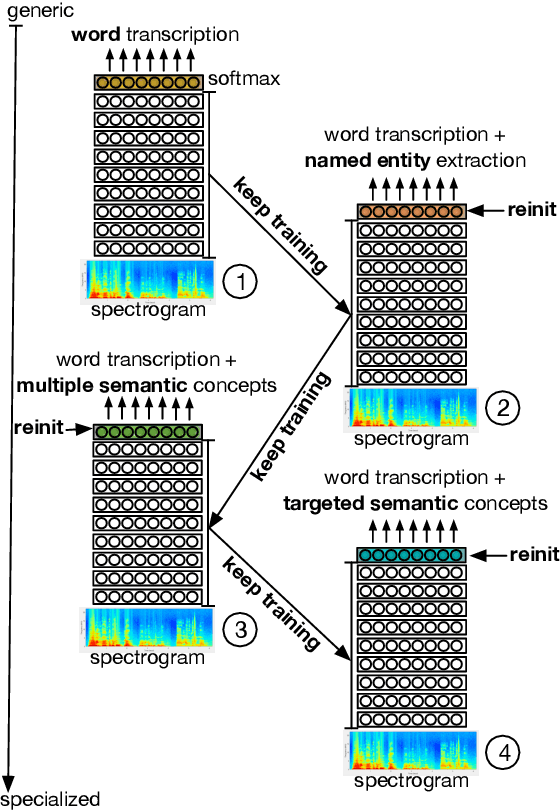

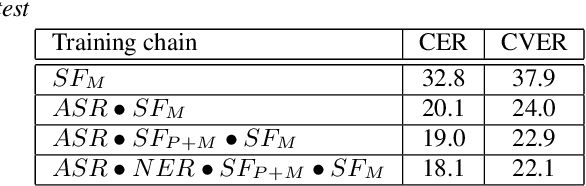

We present an end-to-end approach to extract semantic concepts directly from the speech audio signal. To overcome the lack of data available for this spoken language understanding approach, we investigate the use of a transfer learning strategy based on the principles of curriculum learning. This approach allows us to exploit out-of-domain data that can help to prepare a fully neural architecture. Experiments are carried out on the French MEDIA and PORTMEDIA corpora and show that this end-to-end SLU approach reaches the best results ever published on this task. We compare our approach to a classical pipeline approach that uses ASR, POS tagging, lemmatizer, chunker... and other NLP tools that aim to enrich ASR outputs that feed an SLU text to concepts system. Last, we explore the promising capacity of our end-to-end SLU approach to address the problem of domain portability.
TED-LIUM 3: twice as much data and corpus repartition for experiments on speaker adaptation
Jul 03, 2018
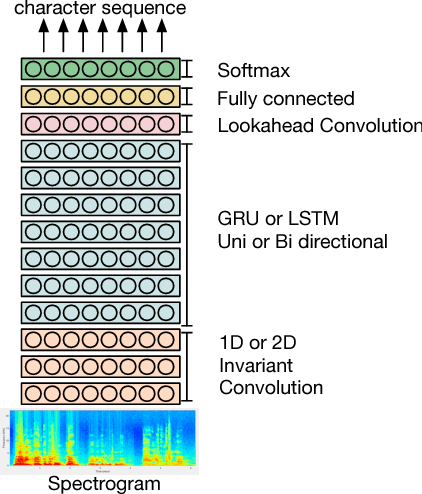
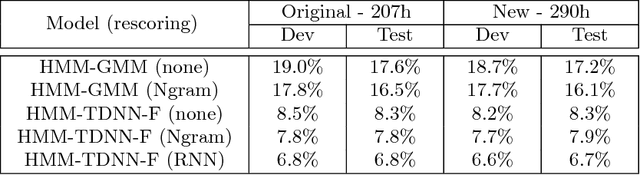
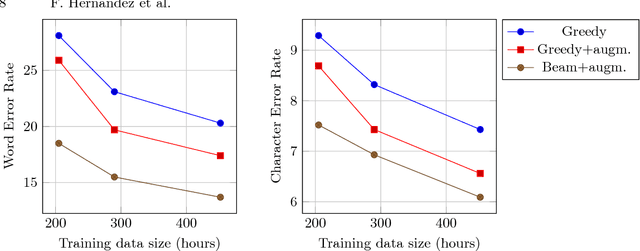
In this paper, we present TED-LIUM release 3 corpus dedicated to speech recognition in English, that multiplies by more than two the available data to train acoustic models in comparison with TED-LIUM 2. We present the recent development on Automatic Speech Recognition (ASR) systems in comparison with the two previous releases of the TED-LIUM Corpus from 2012 and 2014. We demonstrate that, passing from 207 to 452 hours of transcribed speech training data is really more useful for end-to-end ASR systems than for HMM-based state-of-the-art ones, even if the HMM-based ASR system still outperforms end-to-end ASR system when the size of audio training data is 452 hours, with respectively a Word Error Rate (WER) of 6.6% and 13.7%. Last, we propose two repartitions of the TED-LIUM release 3 corpus: the legacy one that is the same as the one existing in release 2, and a new one, calibrated and designed to make experiments on speaker adaptation. Like the two first releases, TED-LIUM 3 corpus will be freely available for the research community.
Fast and Accurate OOV Decoder on High-Level Features
Jul 19, 2017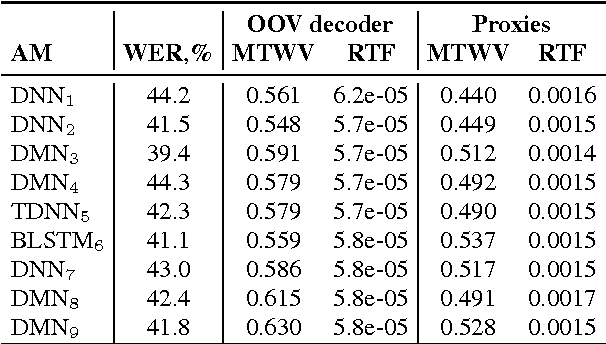
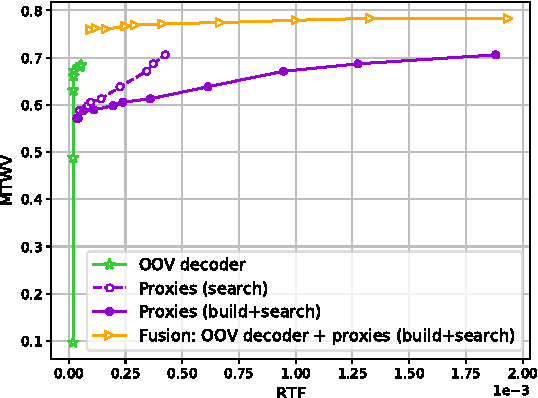
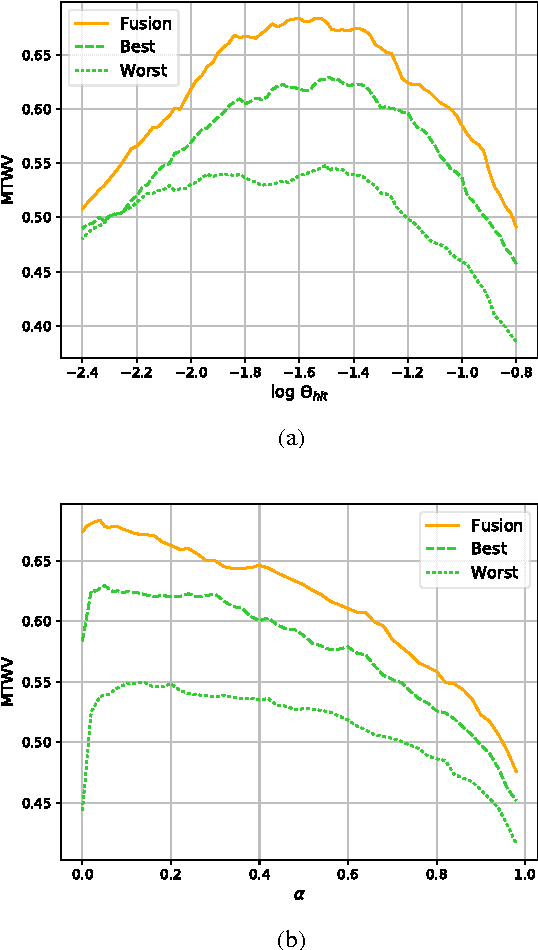

This work proposes a novel approach to out-of-vocabulary (OOV) keyword search (KWS) task. The proposed approach is based on using high-level features from an automatic speech recognition (ASR) system, so called phoneme posterior based (PPB) features, for decoding. These features are obtained by calculating time-dependent phoneme posterior probabilities from word lattices, followed by their smoothing. For the PPB features we developed a special novel very fast, simple and efficient OOV decoder. Experimental results are presented on the Georgian language from the IARPA Babel Program, which was the test language in the OpenKWS 2016 evaluation campaign. The results show that in terms of maximum term weighted value (MTWV) metric and computational speed, for single ASR systems, the proposed approach significantly outperforms the state-of-the-art approach based on using in-vocabulary proxies for OOV keywords in the indexed database. The comparison of the two OOV KWS approaches on the fusion results of the nine different ASR systems demonstrates that the proposed OOV decoder outperforms the proxy-based approach in terms of MTWV metric given the comparable processing speed. Other important advantages of the OOV decoder include extremely low memory consumption and simplicity of its implementation and parameter optimization.