 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARSS22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events
Jun 04, 2022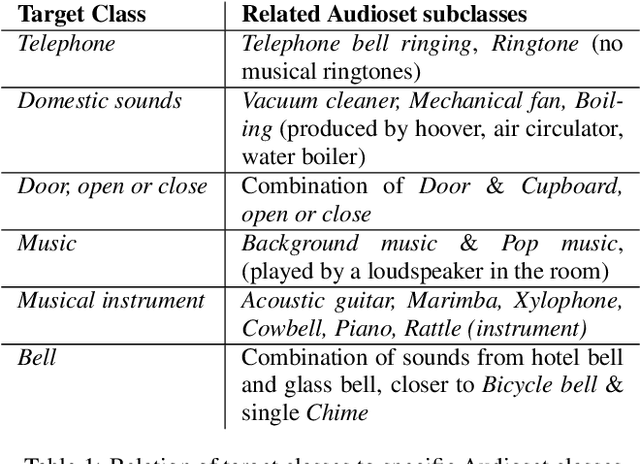
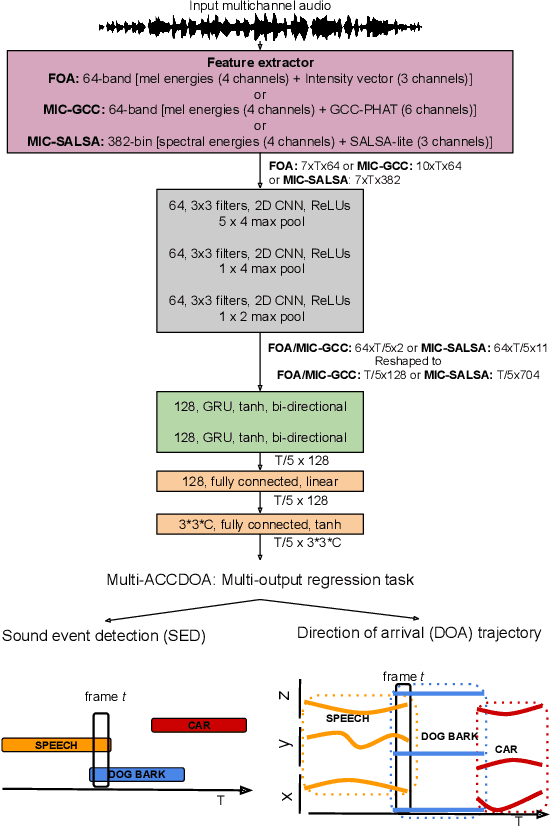
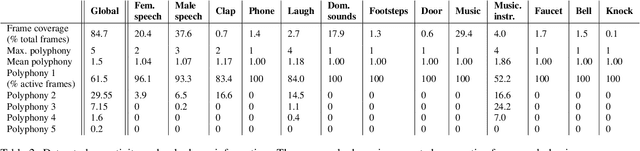

This report presents the Sony-TAu Realistic Spatial Soundscapes 2022 (STARS22) dataset for sound event localization and detection, comprised of spatial recordings of real scenes collected in various interiors of two different sites. The dataset is captured with a high resolution spherical microphone array and delivered in two 4-channel formats, first-order Ambisonics and tetrahedral microphone array. Sound events in the dataset belonging to 13 target sound classes are annotated both temporally and spatially through a combination of human annotation and optical tracking. The dataset serves as the development and evaluation dataset for the Task 3 of the DCASE2022 Challenge on Sound Event Localization and Detection and introduces significant new challenges for the task compared to the previous iterations, which were based on synthetic spatialized sound scene recordings. Dataset specifications are detailed including recording and annotation process, target classes and their presence, and details on the development and evaluation splits. Additionally, the report presents the baseline system that accompanies the dataset in the challenge with emphasis on the differences with the baseline of the previous iterations; namely, introduction of the multi-ACCDOA representation to handle multiple simultaneous occurences of events of the same class, and support for additional improved input features for the microphone array format. Results of the baseline indicate that with a suitable training strategy a reasonable detection and localization performance can be achieved on real sound scene recordings. The dataset is available in https://zenodo.org/record/6387880.
Multi-ACCDOA: Localizing and Detecting Overlapping Sounds from the Same Class with Auxiliary Duplicating Permutation Invariant Training
Oct 14, 2021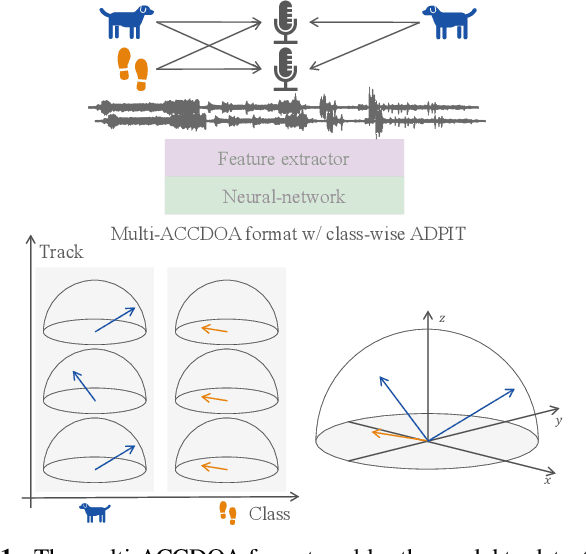

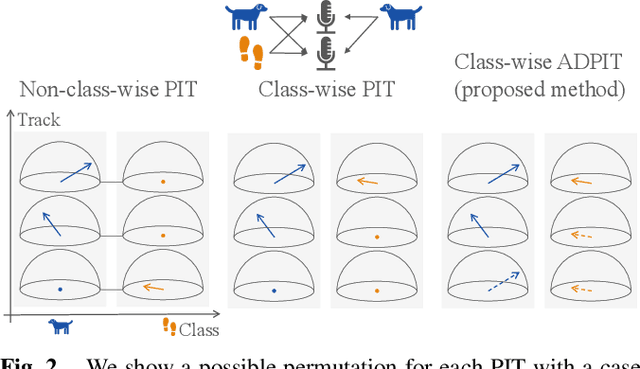

Sound event localization and detection (SELD) involves identifying the direction-of-arrival (DOA) and the event class. The SELD methods with a class-wise output format make the model predict activities of all sound event classes and corresponding locations. The class-wise methods can output activity-coupled Cartesian DOA (ACCDOA) vectors, which enable us to solve a SELD task with a single target using a single network. However, there is still a challenge in detecting the same event class from multiple locations. To overcome this problem while maintaining the advantages of the class-wise format, we extended ACCDOA to a multi one and proposed auxiliary duplicating permutation invariant training (ADPIT). The multi- ACCDOA format (a class- and track-wise output format) enables the model to solve the cases with overlaps from the same class. The class-wise ADPIT scheme enables each track of the multi-ACCDOA format to learn with the same target as the single-ACCDOA format. In evaluations with the DCASE 2021 Task 3 dataset, the model trained with the multi-ACCDOA format and with the class-wise ADPIT detects overlapping events from the same class while maintaining its performance in the other cases. Also, the proposed method performed comparably to state-of-the-art SELD methods with fewer parameters.
Spatial Data Augmentation with Simulated Room Impulse Responses for Sound Event Localization and Detection
Oct 13, 2021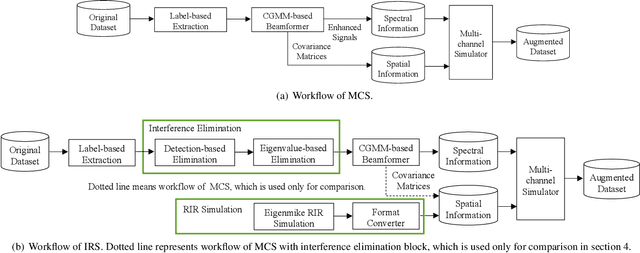
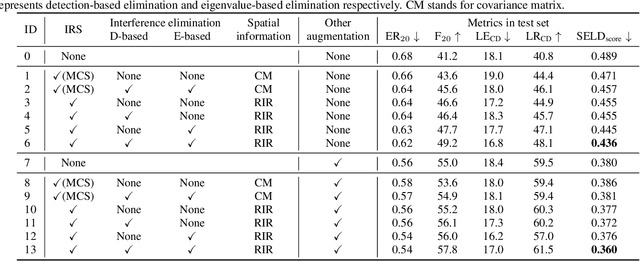
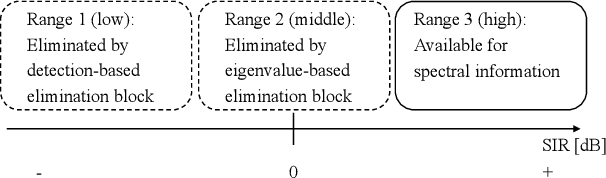
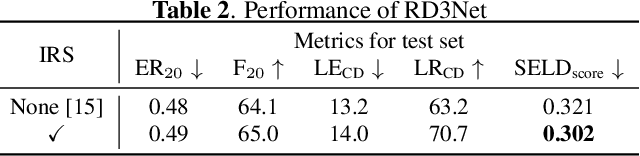
Recording and annotating real sound events for a sound event localization and detection (SELD) task is time consuming, and data augmentation techniques are often favored when the amount of data is limited. However, how to augment the spatial information in a dataset, including unlabeled directional interference events, remains an open research question. Furthermore, directional interference events make it difficult to accurately extract spatial characteristics from target sound events. To address this problem, we propose an impulse response simulation framework (IRS) that augments spatial characteristics using simulated room impulse responses (RIR). RIRs corresponding to a microphone array assumed to be placed in various rooms are accurately simulated, and the source signals of the target sound events are extracted from a mixture. The simulated RIRs are then convolved with the extracted source signals to obtain an augmented multi-channel training dataset. Evaluation results obtained using the TAU-NIGENS Spatial Sound Events 2021 dataset show that the IRS contributes to improving the overall SELD performance. Additionally, we conducted an ablation study to discuss the contribution and need for each component within the IRS.
Amicable examples for informed source separation
Oct 11, 2021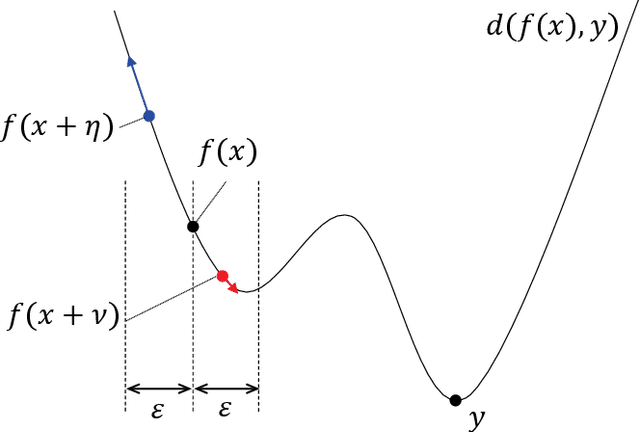
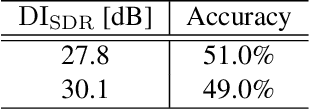
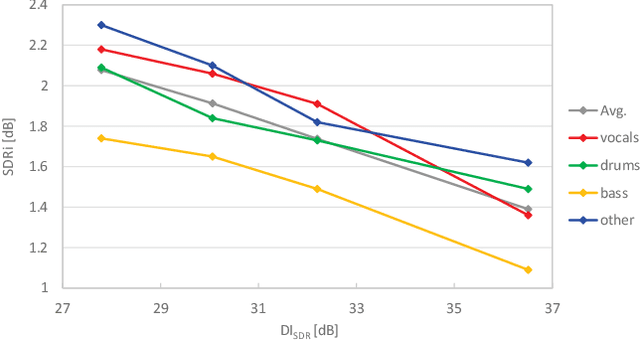
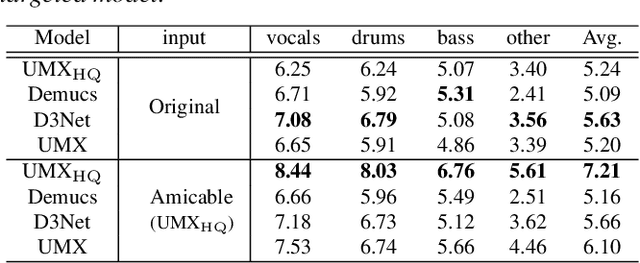
This paper deals with the problem of informed source separation (ISS), where the sources are accessible during the so-called \textit{encoding} stage. Previous works computed side-information during the encoding stage and source separation models were designed to utilize the side-information to improve the separation performance. In contrast, in this work, we improve the performance of a pretrained separation model that does not use any side-information. To this end, we propose to adopt an adversarial attack for the opposite purpose, i.e., rather than computing the perturbation to degrade the separation, we compute an imperceptible perturbation called amicable noise to improve the separation. Experimental results show that the proposed approach selectively improves the performance of the targeted separation model by 2.23 dB on average and is robust to signal compression. Moreover, we propose multi-model multi-purpose learning that control the effect of the perturbation on different models individually.
Source Mixing and Separation Robust Audio Steganography
Oct 11, 2021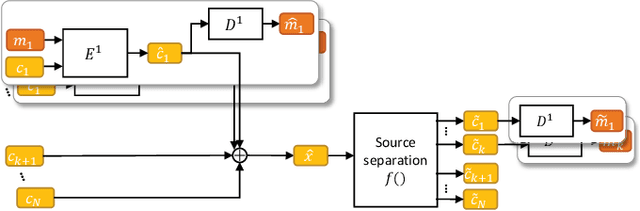

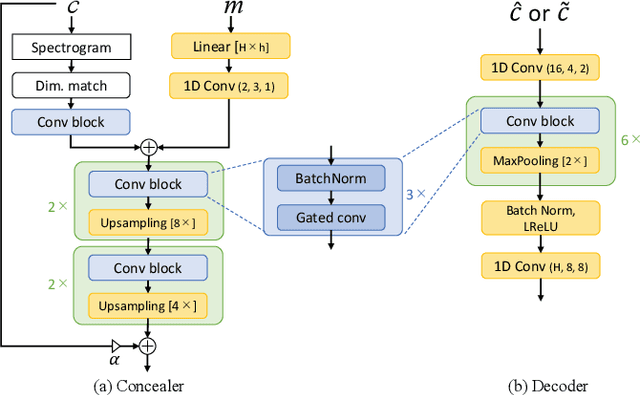
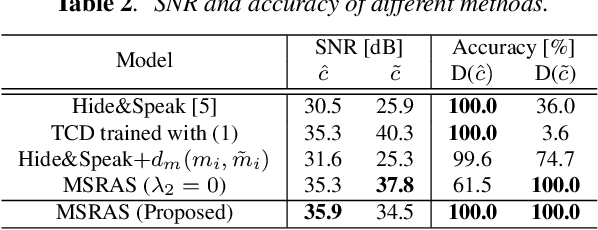
Audio steganography aims at concealing secret information in carrier audio with imperceptible modification on the carrier. Although previous works addressed the robustness of concealed message recovery against distortions introduced during transmission, they do not address the robustness against aggressive editing such as mixing of other audio sources and source separation. In this work, we propose for the first time a steganography method that can embed information into individual sound sources in a mixture such as instrumental tracks in music. To this end, we propose a time-domain model and curriculum learning essential to learn to decode the concealed message from the separated sources. Experimental results show that the proposed method successfully conceals the information in an imperceptible perturbation and that the information can be correctly recovered even after mixing of other sources and separation by a source separation algorithm. Furthermore, we show that the proposed method can be applied to multiple sources simultaneously without interfering with the decoder for other sources even after the sources are mixed and separated.
Ensemble of ACCDOA- and EINV2-based Systems with D3Nets and Impulse Response Simulation for Sound Event Localization and Detection
Jun 21, 2021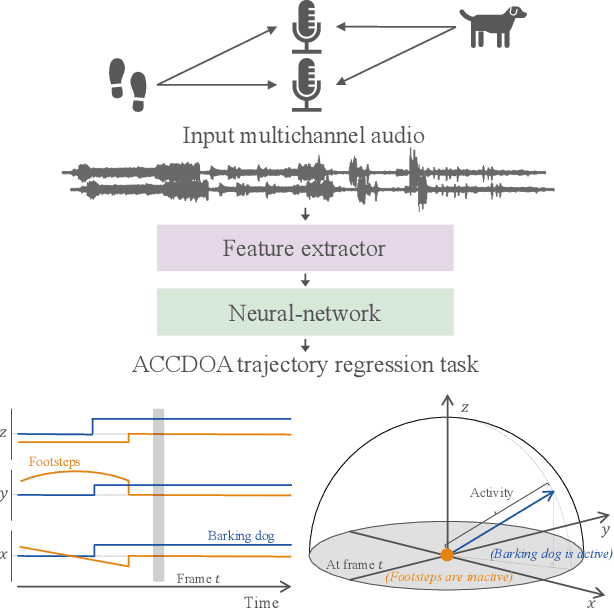
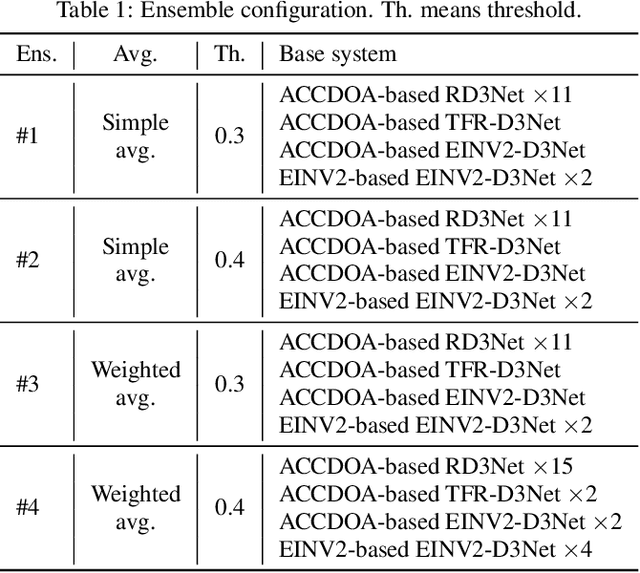
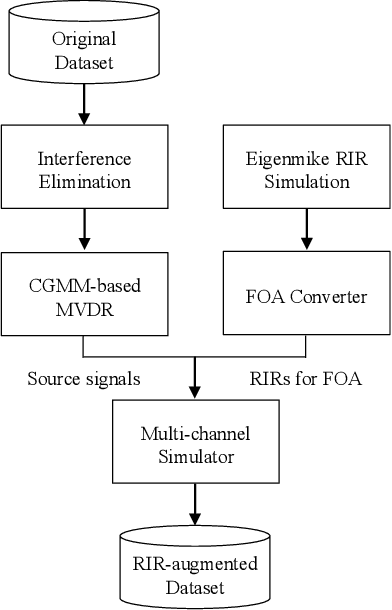
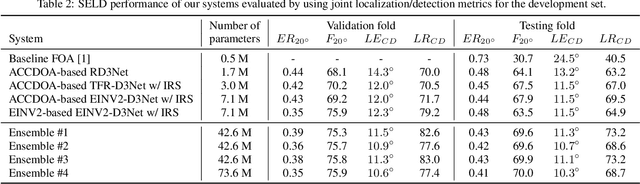
This report describes our systems submitted to the DCASE2021 challenge task 3: sound event localization and detection (SELD) with directional interference. Our previous system based on activity-coupled Cartesian direction of arrival (ACCDOA) representation enables us to solve a SELD task with a single target. This ACCDOA-based system with efficient network architecture called RD3Net and data augmentation techniques outperformed state-of-the-art SELD systems in terms of localization and location-dependent detection. Using the ACCDOA-based system as a base, we perform model ensembles by averaging outputs of several systems trained with different conditions such as input features, training folds, and model architectures. We also use the event independent network v2 (EINV2)-based system to increase the diversity of the model ensembles. To generalize the models, we further propose impulse response simulation (IRS), which generates simulated multi-channel signals by convolving simulated room impulse responses (RIRs) with source signals extracted from the original dataset. Our systems significantly improved over the baseline system on the development dataset.
End-to-end lyrics Recognition with Voice to Singing Style Transfer
Feb 17, 2021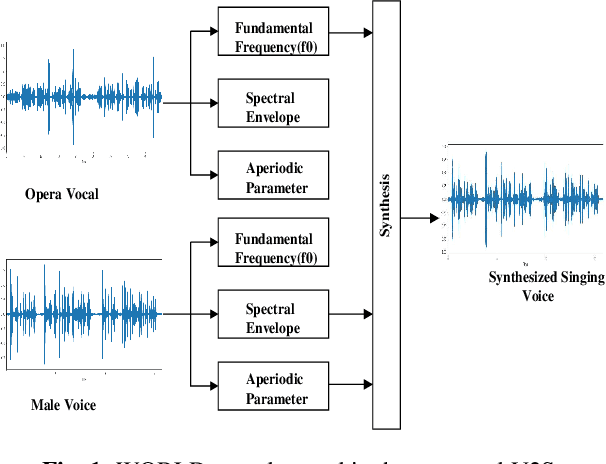

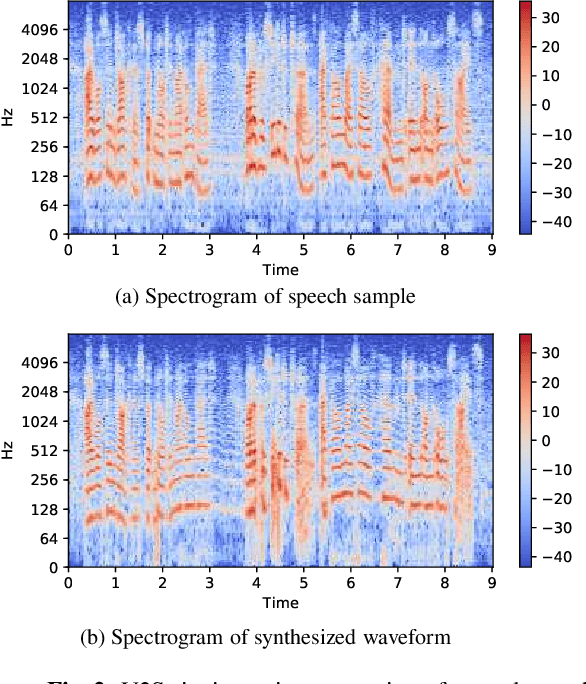
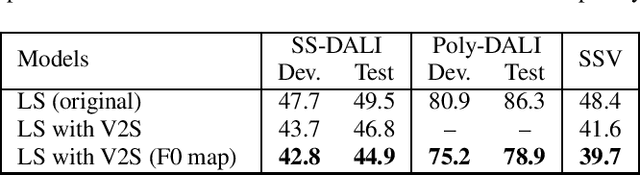
Automatic transcription of monophonic/polyphonic music is a challenging task due to the lack of availability of large amounts of transcribed data. In this paper, we propose a data augmentation method that converts natural speech to singing voice based on vocoder based speech synthesizer. This approach, called voice to singing (V2S), performs the voice style conversion by modulating the F0 contour of the natural speech with that of a singing voice. The V2S model based style transfer can generate good quality singing voice thereby enabling the conversion of large corpora of natural speech to singing voice that is useful in building an E2E lyrics transcription system. In our experiments on monophonic singing voice data, the V2S style transfer provides a significant gain (relative improvements of 21%) for the E2E lyrics transcription system. We also discuss additional components like transfer learning and lyrics based language modeling to improve the performance of the lyrics transcription system.
Hierarchical disentangled representation learning for singing voice conversion
Jan 18, 2021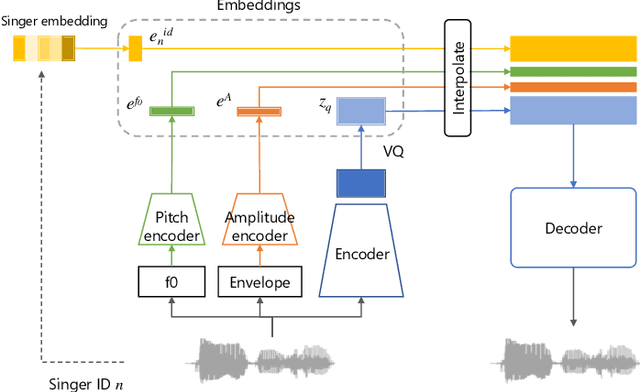
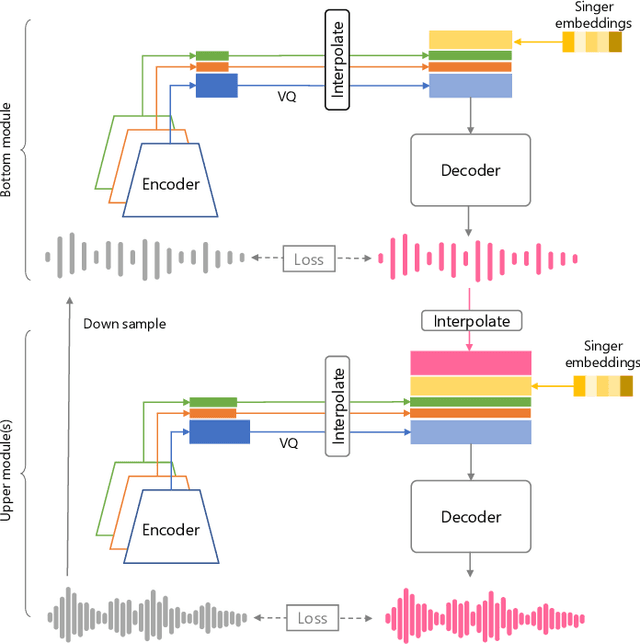
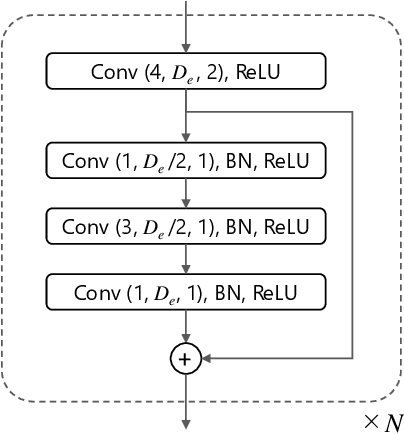
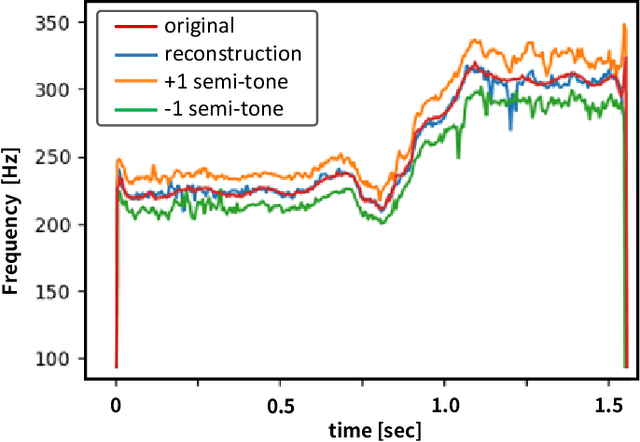
Conventional singing voice conversion (SVC) methods often suffer from operating in high-resolution audio owing to a high dimensionality of data. In this paper, we propose a hierarchical representation learning that enables the learning of disentangled representations with multiple resolutions independently. With the learned disentangled representations, the proposed method progressively performs SVC from low to high resolutions. Experimental results show that the proposed method outperforms baselines that operate with a single resolution in terms of mean opinion score (MOS), similarity score, and pitch accuracy.
Densely connected multidilated convolutional networks for dense prediction tasks
Nov 21, 2020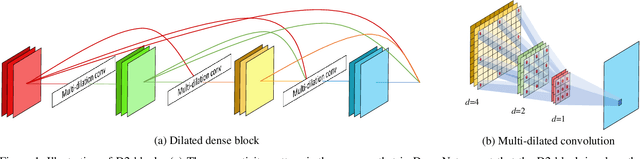
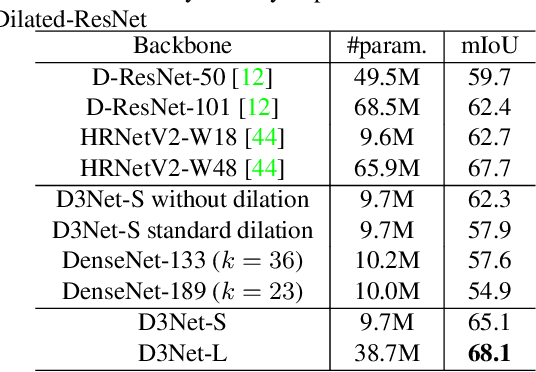

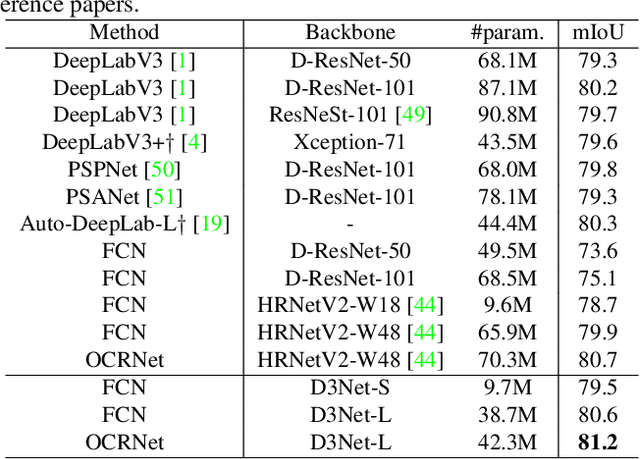
Tasks that involve high-resolution dense prediction require a modeling of both local and global patterns in a large input field. Although the local and global structures often depend on each other and their simultaneous modeling is important, many convolutional neural network (CNN)-based approaches interchange representations in different resolutions only a few times. In this paper, we claim the importance of a dense simultaneous modeling of multiresolution representation and propose a novel CNN architecture called densely connected multidilated DenseNet (D3Net). D3Net involves a novel multidilated convolution that has different dilation factors in a single layer to model different resolutions simultaneously. By combining the multidilated convolution with the DenseNet architecture, D3Net incorporates multiresolution learning with an exponentially growing receptive field in almost all layers, while avoiding the aliasing problem that occurs when we naively incorporate the dilated convolution in DenseNet. Experiments on the image semantic segmentation task using Cityscapes and the audio source separation task using MUSDB18 show that the proposed method has superior performance over state-of-the-art methods.
D3Net: Densely connected multidilated DenseNet for music source separation
Oct 15, 2020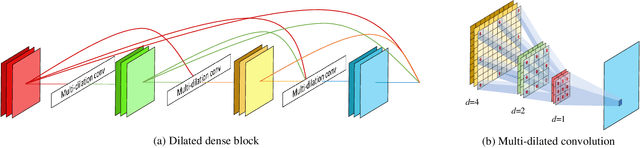
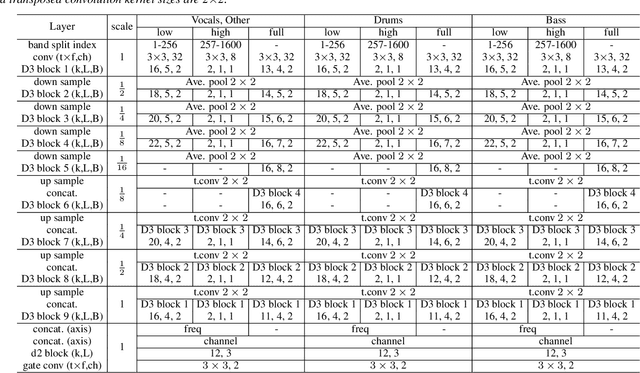
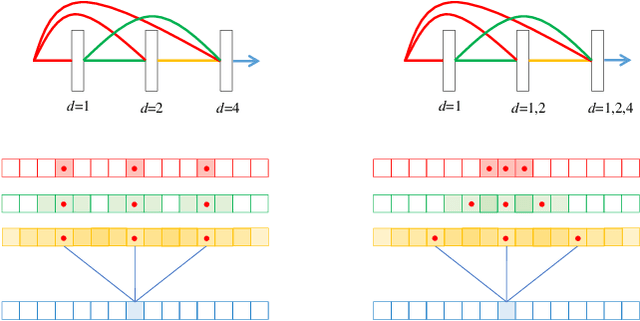
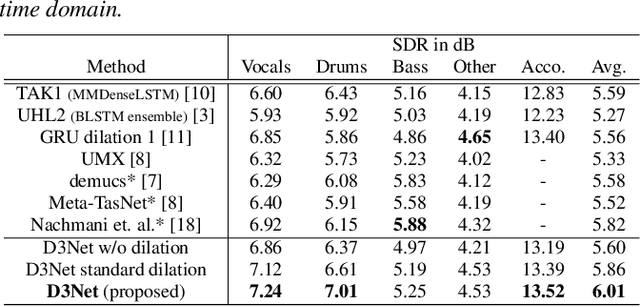
Music source separation involves a large input field to model a long-term dependence of an audio signal. Previous convolutional neural network (CNN) -based approaches address the large input field modeling using sequentially down- and up-sampling feature maps or dilated convolution. In this paper, we claim the importance of a rapid growth of a receptive field and a simultaneous modeling of multi-resolution data in a single convolution layer, and propose a novel CNN architecture called densely connected dilated DenseNet (D3Net). D3Net involves a novel multi-dilated convolution that has different dilation factors in a single layer to model different resolutions simultaneously. By combining the multi-dilated convolution with DenseNet architecture, D3Net avoids the aliasing problem that exists when we naively incorporate the dilated convolution in DenseNet. Experimental results on MUSDB18 dataset show that D3Net achieves state-of-the-art performance with an average signal to distortion ratio (SDR) of 6.01 dB.