 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Correspondence to Actions: Human-Like Multi-Image Spatial Reasoning in Multi-modal Large Language Models
Feb 09, 2026While multimodal large language models (MLLMs) have made substantial progress in single-image spatial reasoning, multi-image spatial reasoning, which requires integration of information from multiple viewpoints, remains challenging. Cognitive studies suggest that humans address such tasks through two mechanisms: cross-view correspondence, which identifies regions across different views that correspond to the same physical locations, and stepwise viewpoint transformation, which composes relative viewpoint changes sequentially. However, existing studies incorporate these mechanisms only partially and often implicitly, without explicit supervision for both. We propose Human-Aware Training for Cross-view correspondence and viewpoint cHange (HATCH), a training framework with two complementary objectives: (1) Patch-Level Spatial Alignment, which encourages patch representations to align across views for spatially corresponding regions, and (2) Action-then-Answer Reasoning, which requires the model to generate explicit viewpoint transition actions before predicting the final answer. Experiments on three benchmarks demonstrate that HATCH consistently outperforms baselines of comparable size by a clear margin and achieves competitive results against much larger models, while preserving single-image reasoning capabilities.
DISCODE: Distribution-Aware Score Decoder for Robust Automatic Evaluation of Image Captioning
Dec 16, 2025Large vision-language models (LVLMs) have shown impressive performance across a broad range of multimodal tasks. However, robust image caption evaluation using LVLMs remains challenging, particularly under domain-shift scenarios. To address this issue, we introduce the Distribution-Aware Score Decoder (DISCODE), a novel finetuning-free method that generates robust evaluation scores better aligned with human judgments across diverse domains. The core idea behind DISCODE lies in its test-time adaptive evaluation approach, which introduces the Adaptive Test-Time (ATT) loss, leveraging a Gaussian prior distribution to improve robustness in evaluation score estimation. This loss is efficiently minimized at test time using an analytical solution that we derive. Furthermore, we introduce the Multi-domain Caption Evaluation (MCEval) benchmark, a new image captioning evaluation benchmark covering six distinct domains, designed to assess the robustness of evaluation metrics. In our experiments, we demonstrate that DISCODE achieves state-of-the-art performance as a reference-free evaluation metric across MCEval and four representative existing benchmarks.
STATUS Bench: A Rigorous Benchmark for Evaluating Object State Understanding in Vision-Language Models
Oct 26, 2025



Object state recognition aims to identify the specific condition of objects, such as their positional states (e.g., open or closed) and functional states (e.g., on or off). While recent Vision-Language Models (VLMs) are capable of performing a variety of multimodal tasks, it remains unclear how precisely they can identify object states. To alleviate this issue, we introduce the STAte and Transition UnderStanding Benchmark (STATUS Bench), the first benchmark for rigorously evaluating the ability of VLMs to understand subtle variations in object states in diverse situations. Specifically, STATUS Bench introduces a novel evaluation scheme that requires VLMs to perform three tasks simultaneously: object state identification (OSI), image retrieval (IR), and state change identification (SCI). These tasks are defined over our fully hand-crafted dataset involving image pairs, their corresponding object state descriptions and state change descriptions. Furthermore, we introduce a large-scale training dataset, namely STATUS Train, which consists of 13 million semi-automatically created descriptions. This dataset serves as the largest resource to facilitate further research in this area. In our experiments, we demonstrate that STATUS Bench enables rigorous consistency evaluation and reveal that current state-of-the-art VLMs still significantly struggle to capture subtle object state distinctions. Surprisingly, under the proposed rigorous evaluation scheme, most open-weight VLMs exhibited chance-level zero-shot performance. After fine-tuning on STATUS Train, Qwen2.5-VL achieved performance comparable to Gemini 2.0 Flash. These findings underscore the necessity of STATUS Bench and Train for advancing object state recognition in VLM research.
AgroBench: Vision-Language Model Benchmark in Agriculture
Jul 28, 2025



Precise automated understanding of agricultural tasks such as disease identification is essential for sustainable crop production. Recent advances in vision-language models (VLMs) are expected to further expand the range of agricultural tasks by facilitating human-model interaction through easy, text-based communication. Here, we introduce AgroBench (Agronomist AI Benchmark), a benchmark for evaluating VLM models across seven agricultural topics, covering key areas in agricultural engineering and relevant to real-world farming. Unlike recent agricultural VLM benchmarks, AgroBench is annotated by expert agronomists. Our AgroBench covers a state-of-the-art range of categories, including 203 crop categories and 682 disease categories, to thoroughly evaluate VLM capabilities. In our evaluation on AgroBench, we reveal that VLMs have room for improvement in fine-grained identification tasks. Notably, in weed identification, most open-source VLMs perform close to random. With our wide range of topics and expert-annotated categories, we analyze the types of errors made by VLMs and suggest potential pathways for future VLM development. Our dataset and code are available at https://dahlian00.github.io/AgroBenchPage/ .
AnimalClue: Recognizing Animals by their Traces
Jul 27, 2025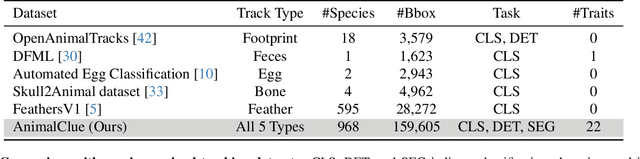

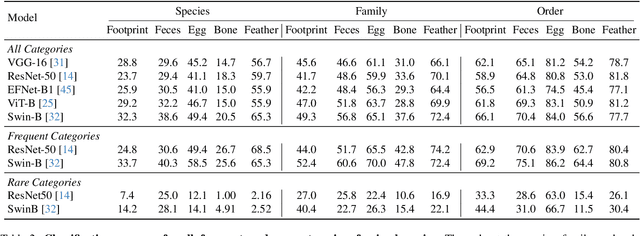
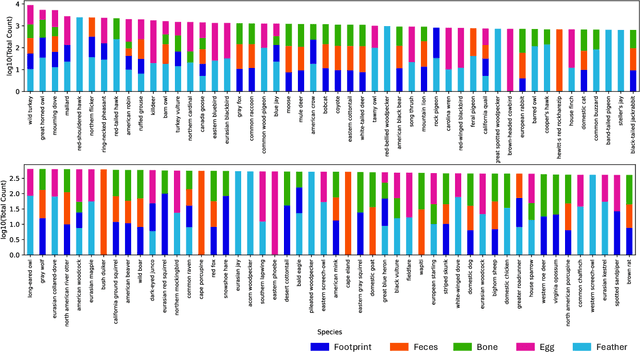
Wildlife observation plays an important role in biodiversity conservation, necessitating robust methodologies for monitoring wildlife populations and interspecies interactions. Recent advances in computer vision have significantly contributed to automating fundamental wildlife observation tasks, such as animal detection and species identification. However, accurately identifying species from indirect evidence like footprints and feces remains relatively underexplored, despite its importance in contributing to wildlife monitoring. To bridge this gap, we introduce AnimalClue, the first large-scale dataset for species identification from images of indirect evidence. Our dataset consists of 159,605 bounding boxes encompassing five categories of indirect clues: footprints, feces, eggs, bones, and feathers. It covers 968 species, 200 families, and 65 orders. Each image is annotated with species-level labels, bounding boxes or segmentation masks, and fine-grained trait information, including activity patterns and habitat preferences. Unlike existing datasets primarily focused on direct visual features (e.g., animal appearances), AnimalClue presents unique challenges for classification, detection, and instance segmentation tasks due to the need for recognizing more detailed and subtle visual features. In our experiments, we extensively evaluate representative vision models and identify key challenges in animal identification from their traces. Our dataset and code are available at https://dahlian00.github.io/AnimalCluePage/
Free Random Projection for In-Context Reinforcement Learning
Apr 09, 2025



Hierarchical inductive biases are hypothesized to promote generalizable policies in reinforcement learning, as demonstrated by explicit hyperbolic latent representations and architectures. Therefore, a more flexible approach is to have these biases emerge naturally from the algorithm. We introduce Free Random Projection, an input mapping grounded in free probability theory that constructs random orthogonal matrices where hierarchical structure arises inherently. The free random projection integrates seamlessly into existing in-context reinforcement learning frameworks by encoding hierarchical organization within the input space without requiring explicit architectural modifications. Empirical results on multi-environment benchmarks show that free random projection consistently outperforms the standard random projection, leading to improvements in generalization. Furthermore, analyses within linearly solvable Markov decision processes and investigations of the spectrum of kernel random matrices reveal the theoretical underpinnings of free random projection's enhanced performance, highlighting its capacity for effective adaptation in hierarchically structured state spaces.
On the Relationship Between Double Descent of CNNs and Shape/Texture Bias Under Learning Process
Mar 04, 2025The double descent phenomenon, which deviates from the traditional bias-variance trade-off theory, attracts considerable research attention; however, the mechanism of its occurrence is not fully understood. On the other hand, in the study of convolutional neural networks (CNNs) for image recognition, methods are proposed to quantify the bias on shape features versus texture features in images, determining which features the CNN focuses on more. In this work, we hypothesize that there is a relationship between the shape/texture bias in the learning process of CNNs and epoch-wise double descent, and we conduct verification. As a result, we discover double descent/ascent of shape/texture bias synchronized with double descent of test error under conditions where epoch-wise double descent is observed. Quantitative evaluations confirm this correlation between the test errors and the bias values from the initial decrease to the full increase in test error. Interestingly, double descent/ascent of shape/texture bias is observed in some cases even in conditions without label noise, where double descent is thought not to occur. These experimental results are considered to contribute to the understanding of the mechanisms behind the double descent phenomenon and the learning process of CNNs in image recognition.
Rectified Lagrangian for Out-of-Distribution Detection in Modern Hopfield Networks
Feb 19, 2025



Modern Hopfield networks (MHNs) have recently gained significant attention in the field of artificial intelligence because they can store and retrieve a large set of patterns with an exponentially large memory capacity. A MHN is generally a dynamical system defined with Lagrangians of memory and feature neurons, where memories associated with in-distribution (ID) samples are represented by attractors in the feature space. One major problem in existing MHNs lies in managing out-of-distribution (OOD) samples because it was originally assumed that all samples are ID samples. To address this, we propose the rectified Lagrangian (RegLag), a new Lagrangian for memory neurons that explicitly incorporates an attractor for OOD samples in the dynamical system of MHNs. RecLag creates a trivial point attractor for any interaction matrix, enabling OOD detection by identifying samples that fall into this attractor as OOD. The interaction matrix is optimized so that the probability densities can be estimated to identify ID/OOD. We demonstrate the effectiveness of RecLag-based MHNs compared to energy-based OOD detection methods, including those using state-of-the-art Hopfield energies, across nine image datasets.
Multi-Point Positional Insertion Tuning for Small Object Detection
Dec 24, 2024



Small object detection aims to localize and classify small objects within images. With recent advances in large-scale vision-language pretraining, finetuning pretrained object detection models has emerged as a promising approach. However, finetuning large models is computationally and memory expensive. To address this issue, this paper introduces multi-point positional insertion (MPI) tuning, a parameter-efficient finetuning (PEFT) method for small object detection. Specifically, MPI incorporates multiple positional embeddings into a frozen pretrained model, enabling the efficient detection of small objects by providing precise positional information to latent features. Through experiments, we demonstrated the effectiveness of the proposed method on the SODA-D dataset. MPI performed comparably to conventional PEFT methods, including CoOp and VPT, while significantly reducing the number of parameters that need to be tuned.
HarmonicEval: Multi-modal, Multi-task, Multi-criteria Automatic Evaluation Using a Vision Language Model
Dec 19, 2024



Vision-language models (VLMs) have shown impressive abilities in text and image understanding. However, existing metrics for evaluating the text generated by VLMs focus exclusively on overall quality, leading to two limitations: 1) it is challenging to identify which aspects of the text need improvement from the overall score; 2) metrics may overlook specific evaluation criteria when predicting an overall score. To address these limitations, we propose HarmonicEval, a reference-free evaluation metric that aggregates criterion-wise scores to produce the overall score in a bottom-up manner. Furthermore, we construct the Multi-task Multi-criteria Human Evaluation (MMHE) dataset, which comprises 18,000 expert human judgments across four vision-language tasks. Our experiments demonstrate that HarmonicEval achieves higher correlations with human judgments than conventional metrics while providing numerical scores for each criterion.