 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbeAct: Probe-Guided Training-Free Failure Recovery in Vision-Language-Action Models
Jun 08, 2026Vision-Language-Action (VLA) models demonstrate strong perfor-1 mance on language-conditioned robotic manipulation within their training dis-2 tribution, yet their generalization capabilities remain fundamentally limited. They3 lack the robustness required to handle perturbations, frequently failing when con-4 fronted with lighting changes, altered camera viewpoints, or small initial-state5 variations. We propose PROBEACT, a training-free runtime intervention frame-6 work that detects and recovers from grasping and placement failures in pre-7 trained VLA policies without modifying their weights or requiring additional8 demonstrations. PROBEACT combines three components: (i) a lightweight multi-9 target hidden-state probe that predicts the 3D positions of task-relevant objects10 from intermediate VLA features, with Hungarian-matched identity tracking for11 multi-object scenes; (ii) an object-agnostic kinematic state machine that detects12 grasp, transport, and placement failures using only gripper-internal signals and13 end-effector kinematics; and (iii) a hierarchical Control Barrier Function (CBF)14 filter that encodes repeated-failure locations as soft safe-set constraints, mini-15 mally correcting VLA actions while preserving baseline behavior. As a plug-and-16 play, training-free intervention loop, PROBEACT is orthogonal to existing train-17 ing pipelines. Evaluated on the LIBERO-plus benchmark, our framework acts as18 a universal safety net, improving the success rate of the OpenVLA-OFT model19 from 69.6% to 74.1%, while demonstrating broad applicability to both base and20 fine-tuned VLA policies.
Your Model Already Knows: Attention-Guided Safety Filter for Vision-Language-Action Models
Jun 08, 2026Vision-Language-Action (VLA) models have demonstrated impressive end-to-end performance across a variety of robotic manipulation tasks. However, these policies offer no guarantees against collisions with task-irrelevant objects in the scene. Existing safety filters sidestep this problem by querying a vision-language model (VLM) to identify obstacles and their locations. This, however, is too slow to run in the control loop and can only be invoked at episode initialization, leaving the filter unable to track moving obstacles. We discover that a small number of attention heads within a VLA model reliably localize the object the policy intends to approach. These heads can be exploited within a training-free safety framework that obtains the active target from the attention heads at every step, treats the remainder of the scene as obstacles, and feeds these into a Control Barrier Function (CBF) filter. Together with a lightweight real-time object tracker, this allows for collision avoidance for non-static obstacles. We evaluate our framework on SafeLIBERO, which we extend with moving obstacles. On the original static benchmark, our method performs comparably to an oracle that uses privileged simulator state to identify the target, emulating a VLM-based identification step run once at episode initialization. On the dynamic variant, where the oracle's init-time target assignment becomes stale, our method substantially outperforms it by 43%, on average. Our findings suggest that the perceptual signals needed for real-time safety filtering are already present within VLA policies and can be exploited without additional training or heavy auxiliary models.
SuperPure: Efficient Purification of Localized and Distributed Adversarial Patches via Super-Resolution GAN Models
May 22, 2025As vision-based machine learning models are increasingly integrated into autonomous and cyber-physical systems, concerns about (physical) adversarial patch attacks are growing. While state-of-the-art defenses can achieve certified robustness with minimal impact on utility against highly-concentrated localized patch attacks, they fall short in two important areas: (i) State-of-the-art methods are vulnerable to low-noise distributed patches where perturbations are subtly dispersed to evade detection or masking, as shown recently by the DorPatch attack; (ii) Achieving high robustness with state-of-the-art methods is extremely time and resource-consuming, rendering them impractical for latency-sensitive applications in many cyber-physical systems. To address both robustness and latency issues, this paper proposes a new defense strategy for adversarial patch attacks called SuperPure. The key novelty is developing a pixel-wise masking scheme that is robust against both distributed and localized patches. The masking involves leveraging a GAN-based super-resolution scheme to gradually purify the image from adversarial patches. Our extensive evaluations using ImageNet and two standard classifiers, ResNet and EfficientNet, show that SuperPure advances the state-of-the-art in three major directions: (i) it improves the robustness against conventional localized patches by more than 20%, on average, while also improving top-1 clean accuracy by almost 10%; (ii) It achieves 58% robustness against distributed patch attacks (as opposed to 0% in state-of-the-art method, PatchCleanser); (iii) It decreases the defense end-to-end latency by over 98% compared to PatchCleanser. Our further analysis shows that SuperPure is robust against white-box attacks and different patch sizes. Our code is open-source.
LightPure: Realtime Adversarial Image Purification for Mobile Devices Using Diffusion Models
Aug 31, 2024



Autonomous mobile systems increasingly rely on deep neural networks for perception and decision-making. While effective, these systems are vulnerable to adversarial machine learning attacks where minor input perturbations can significantly impact outcomes. Common countermeasures involve adversarial training and/or data or network transformation. These methods, though effective, require full access to typically proprietary classifiers and are costly for large models. Recent solutions propose purification models, which add a "purification" layer before classification, eliminating the need to modify the classifier directly. Despite their effectiveness, these methods are compute-intensive, making them unsuitable for mobile systems where resources are limited and low latency is essential. This paper introduces LightPure, a new method that enhances adversarial image purification. It improves the accuracy of existing purification methods and provides notable enhancements in speed and computational efficiency, making it suitable for mobile devices with limited resources. Our approach uses a two-step diffusion and one-shot Generative Adversarial Network (GAN) framework, prioritizing latency without compromising robustness. We propose several new techniques to achieve a reasonable balance between classification accuracy and adversarial robustness while maintaining desired latency. We design and implement a proof-of-concept on a Jetson Nano board and evaluate our method using various attack scenarios and datasets. Our results show that LightPure can outperform existing methods by up to 10x in terms of latency while achieving higher accuracy and robustness for various attack scenarios. This method offers a scalable and effective solution for real-world mobile systems.
Solutions to Deepfakes: Can Camera Hardware, Cryptography, and Deep Learning Verify Real Images?
Jul 04, 2024


The exponential progress in generative AI poses serious implications for the credibility of all real images and videos. There will exist a point in the future where 1) digital content produced by generative AI will be indistinguishable from those created by cameras, 2) high-quality generative algorithms will be accessible to anyone, and 3) the ratio of all synthetic to real images will be large. It is imperative to establish methods that can separate real data from synthetic data with high confidence. We define real images as those that were produced by the camera hardware, capturing a real-world scene. Any synthetic generation of an image or alteration of a real image through generative AI or computer graphics techniques is labeled as a synthetic image. To this end, this document aims to: present known strategies in detection and cryptography that can be employed to verify which images are real, weight the strengths and weaknesses of these strategies, and suggest additional improvements to alleviate shortcomings.
SoK: A Study of the Security on Voice Processing Systems
Dec 24, 2021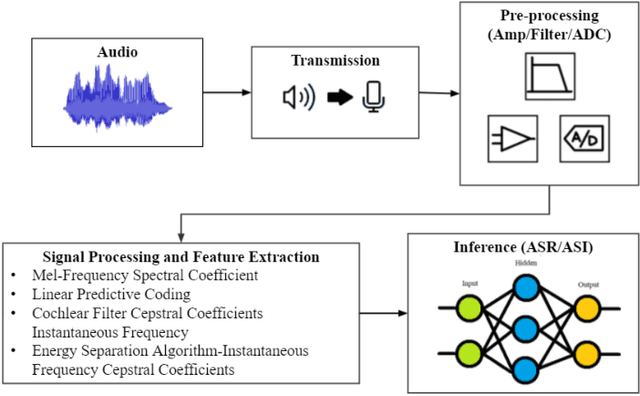
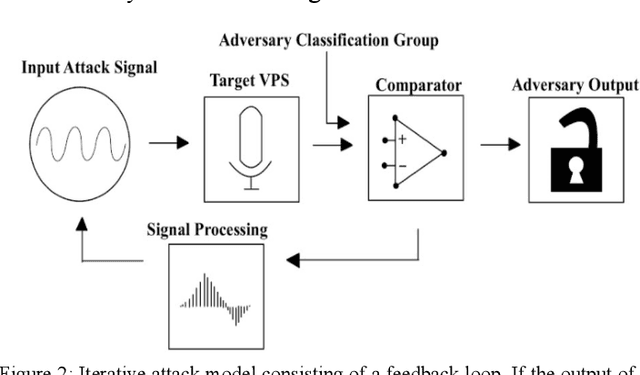
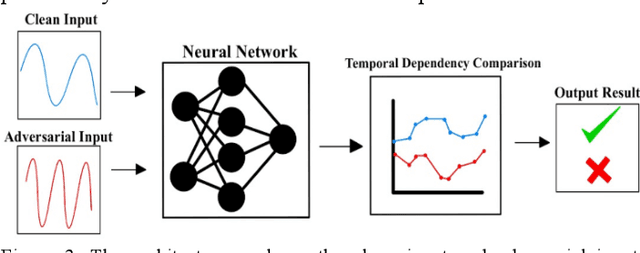
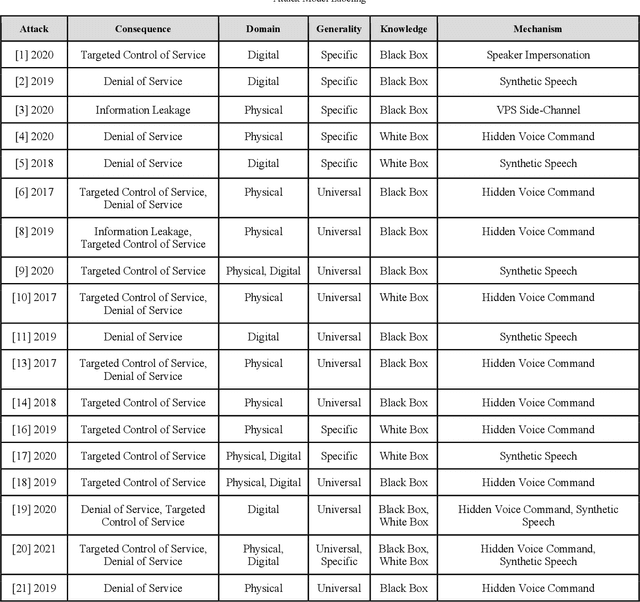
As the use of Voice Processing Systems (VPS) continues to become more prevalent in our daily lives through the increased reliance on applications such as commercial voice recognition devices as well as major text-to-speech software, the attacks on these systems are increasingly complex, varied, and constantly evolving. With the use cases for VPS rapidly growing into new spaces and purposes, the potential consequences regarding privacy are increasingly more dangerous. In addition, the growing number and increased practicality of over-the-air attacks have made system failures much more probable. In this paper, we will identify and classify an arrangement of unique attacks on voice processing systems. Over the years research has been moving from specialized, untargeted attacks that result in the malfunction of systems and the denial of services to more general, targeted attacks that can force an outcome controlled by an adversary. The current and most frequently used machine learning systems and deep neural networks, which are at the core of modern voice processing systems, were built with a focus on performance and scalability rather than security. Therefore, it is critical for us to reassess the developing voice processing landscape and to identify the state of current attacks and defenses so that we may suggest future developments and theoretical improvements.