 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Next-Generation Reasoning-Focused Large Language Models in Ophthalmology: A Head-to-Head Evaluation on 5,888 Items
Apr 15, 2025



Recent advances in reasoning-focused large language models (LLMs) mark a shift from general LLMs toward models designed for complex decision-making, a crucial aspect in medicine. However, their performance in specialized domains like ophthalmology remains underexplored. This study comprehensively evaluated and compared the accuracy and reasoning capabilities of four newly developed reasoning-focused LLMs, namely DeepSeek-R1, OpenAI o1, o3-mini, and Gemini 2.0 Flash-Thinking. Each model was assessed using 5,888 multiple-choice ophthalmology exam questions from the MedMCQA dataset in zero-shot setting. Quantitative evaluation included accuracy, Macro-F1, and five text-generation metrics (ROUGE-L, METEOR, BERTScore, BARTScore, and AlignScore), computed against ground-truth reasonings. Average inference time was recorded for a subset of 100 randomly selected questions. Additionally, two board-certified ophthalmologists qualitatively assessed clarity, completeness, and reasoning structure of responses to differential diagnosis questions.O1 (0.902) and DeepSeek-R1 (0.888) achieved the highest accuracy, with o1 also leading in Macro-F1 (0.900). The performance of models across the text-generation metrics varied: O3-mini excelled in ROUGE-L (0.151), o1 in METEOR (0.232), DeepSeek-R1 and o3-mini tied for BERTScore (0.673), DeepSeek-R1 (-4.105) and Gemini 2.0 Flash-Thinking (-4.127) performed best in BARTScore, while o3-mini (0.181) and o1 (0.176) led AlignScore. Inference time across the models varied, with DeepSeek-R1 being slowest (40.4 seconds) and Gemini 2.0 Flash-Thinking fastest (6.7 seconds). Qualitative evaluation revealed that DeepSeek-R1 and Gemini 2.0 Flash-Thinking tended to provide detailed and comprehensive intermediate reasoning, whereas o1 and o3-mini displayed concise and summarized justifications.
Extraction of Text from Optic Nerve Optical Coherence Tomography Reports
Aug 21, 2023



Purpose: The purpose of this study was to develop and evaluate rule-based algorithms to enhance the extraction of text data, including retinal nerve fiber layer (RNFL) values and other ganglion cell count (GCC) data, from Zeiss Cirrus optical coherence tomography (OCT) scan reports. Methods: DICOM files that contained encapsulated PDF reports with RNFL or Ganglion Cell in their document titles were identified from a clinical imaging repository at a single academic ophthalmic center. PDF reports were then converted into image files and processed using the PaddleOCR Python package for optical character recognition. Rule-based algorithms were designed and iteratively optimized for improved performance in extracting RNFL and GCC data. Evaluation of the algorithms was conducted through manual review of a set of RNFL and GCC reports. Results: The developed algorithms demonstrated high precision in extracting data from both RNFL and GCC scans. Precision was slightly better for the right eye in RNFL extraction (OD: 0.9803 vs. OS: 0.9046), and for the left eye in GCC extraction (OD: 0.9567 vs. OS: 0.9677). Some values presented more challenges in extraction, particularly clock hours 5 and 6 for RNFL thickness, and signal strength for GCC. Conclusions: A customized optical character recognition algorithm can identify numeric results from optical coherence scan reports with high precision. Automated processing of PDF reports can greatly reduce the time to extract OCT results on a large scale.
SoK: A Study of the Security on Voice Processing Systems
Dec 24, 2021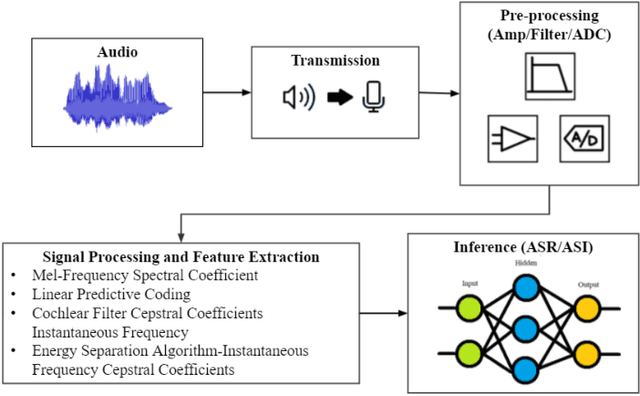
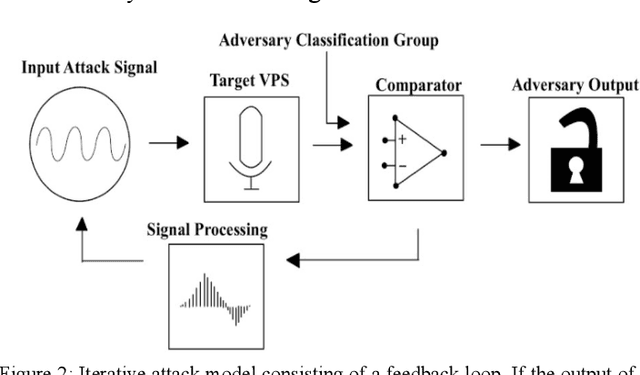
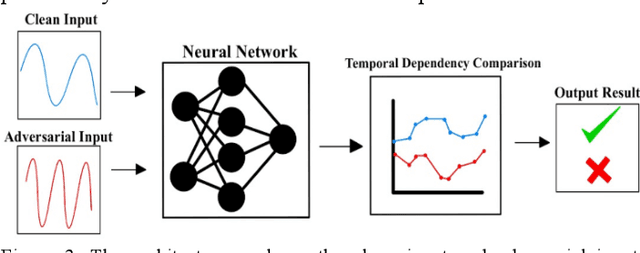
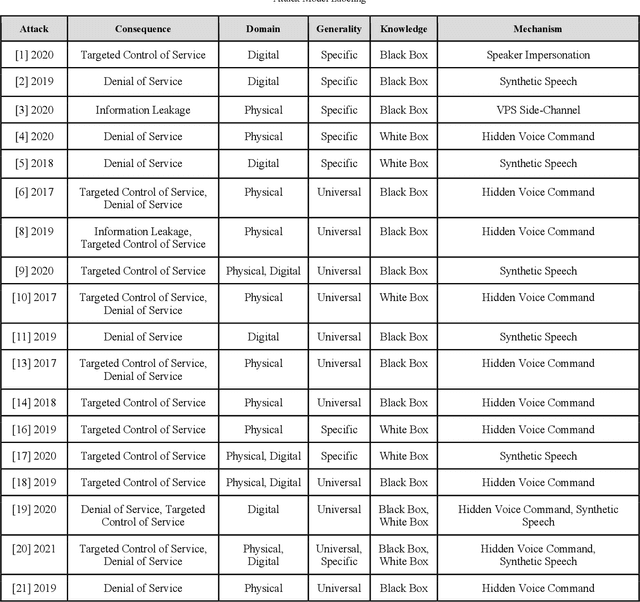
As the use of Voice Processing Systems (VPS) continues to become more prevalent in our daily lives through the increased reliance on applications such as commercial voice recognition devices as well as major text-to-speech software, the attacks on these systems are increasingly complex, varied, and constantly evolving. With the use cases for VPS rapidly growing into new spaces and purposes, the potential consequences regarding privacy are increasingly more dangerous. In addition, the growing number and increased practicality of over-the-air attacks have made system failures much more probable. In this paper, we will identify and classify an arrangement of unique attacks on voice processing systems. Over the years research has been moving from specialized, untargeted attacks that result in the malfunction of systems and the denial of services to more general, targeted attacks that can force an outcome controlled by an adversary. The current and most frequently used machine learning systems and deep neural networks, which are at the core of modern voice processing systems, were built with a focus on performance and scalability rather than security. Therefore, it is critical for us to reassess the developing voice processing landscape and to identify the state of current attacks and defenses so that we may suggest future developments and theoretical improvements.