 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoBERTa: A Robustly Optimized BERT Pretraining Approach
Jul 26, 2019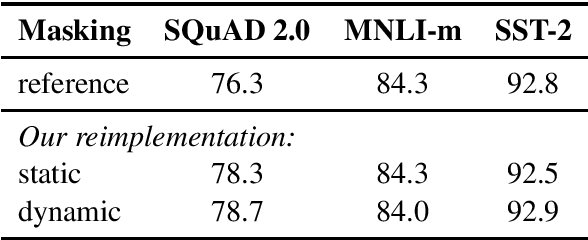
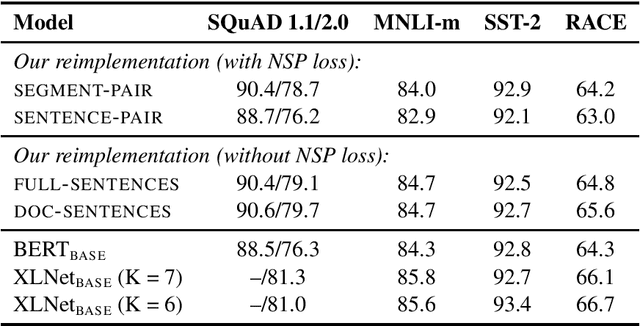
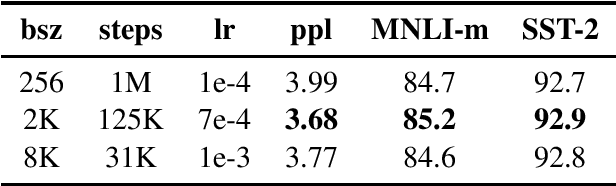
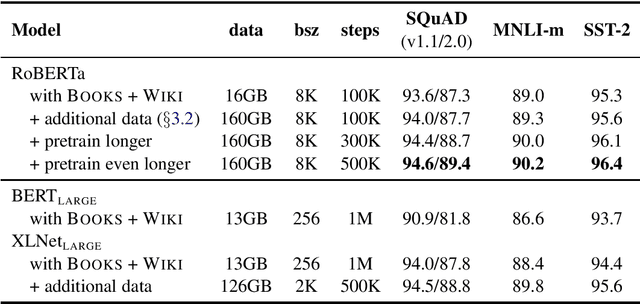
Language model pretraining has led to significant performance gains but careful comparison between different approaches is challenging. Training is computationally expensive, often done on private datasets of different sizes, and, as we will show, hyperparameter choices have significant impact on the final results. We present a replication study of BERT pretraining (Devlin et al., 2019) that carefully measures the impact of many key hyperparameters and training data size. We find that BERT was significantly undertrained, and can match or exceed the performance of every model published after it. Our best model achieves state-of-the-art results on GLUE, RACE and SQuAD. These results highlight the importance of previously overlooked design choices, and raise questions about the source of recently reported improvements. We release our models and code.
Facebook FAIR's WMT19 News Translation Task Submission
Jul 15, 2019
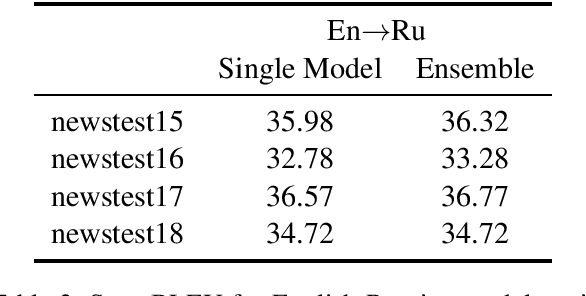
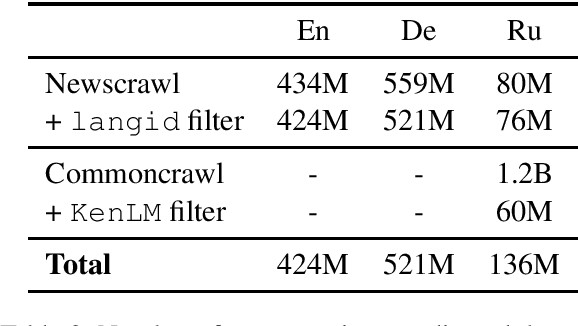
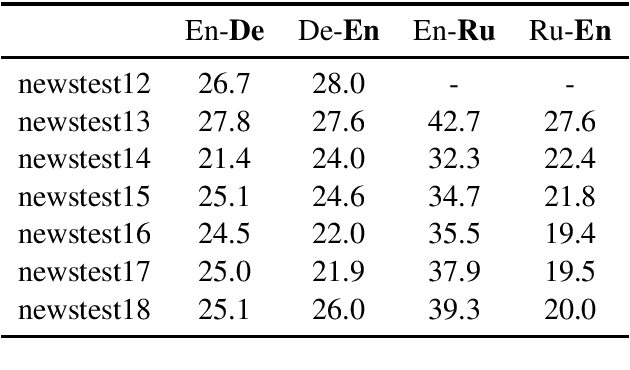
This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes, as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations. This system improves upon our WMT'18 submission by 4.5 BLEU points.
Real or Fake? Learning to Discriminate Machine from Human Generated Text
Jun 07, 2019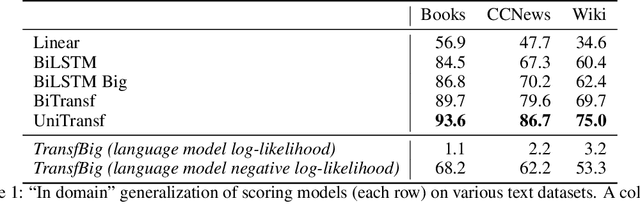
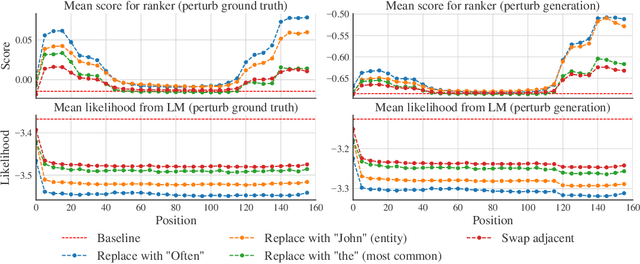
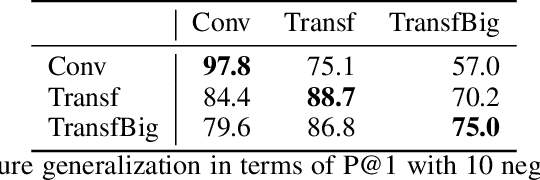
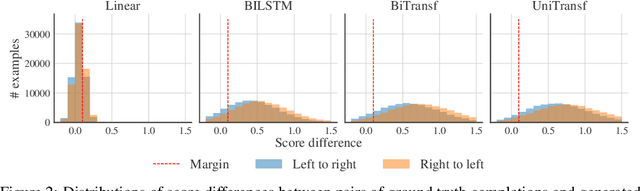
Recent advances in generative modeling of text have demonstrated remarkable improvements in terms of fluency and coherency. In this work we investigate to which extent a machine can discriminate real from machine generated text. This is important in itself for automatic detection of computer generated stories, but can also serve as a tool for further improving text generation. We show that learning a dedicated scoring function to discriminate between real and fake text achieves higher precision than employing the likelihood of a generative model. The scoring functions generalize to other generators than those used for training as long as these generators have comparable model complexity and are trained on similar datasets.
fairseq: A Fast, Extensible Toolkit for Sequence Modeling
Apr 01, 2019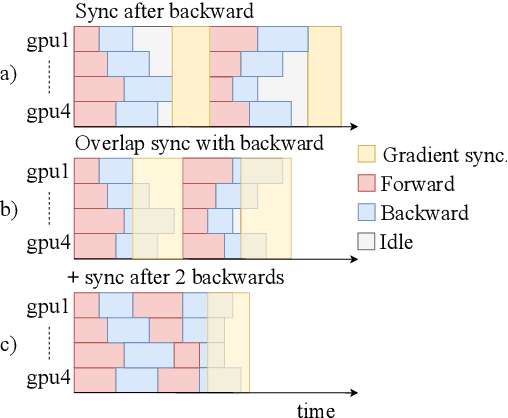

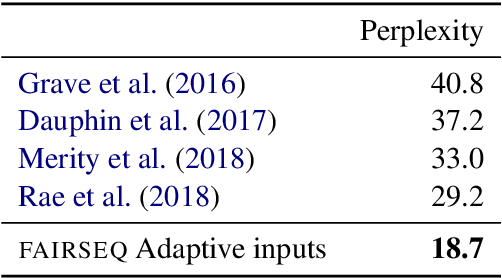
fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs. A demo video can be found at https://www.youtube.com/watch?v=OtgDdWtHvto
Mixture Models for Diverse Machine Translation: Tricks of the Trade
Feb 20, 2019
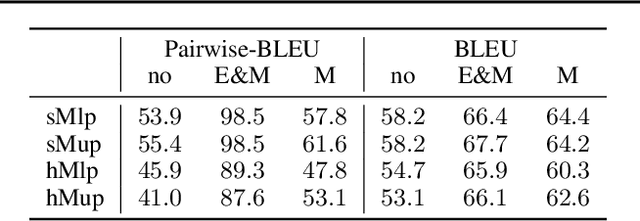
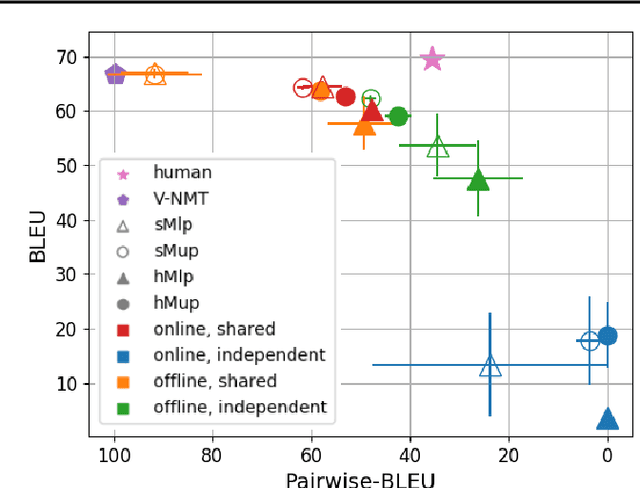
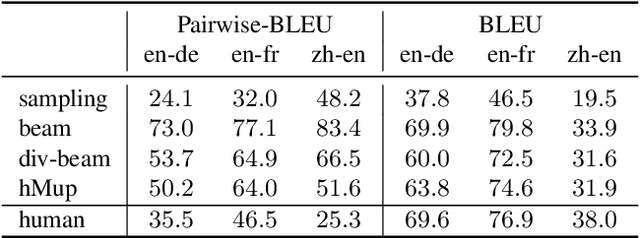
Mixture models trained via EM are among the simplest, most widely used and well understood latent variable models in the machine learning literature. Surprisingly, these models have been hardly explored in text generation applications such as machine translation. In principle, they provide a latent variable to control generation and produce a diverse set of hypotheses. In practice, however, mixture models are prone to degeneracies---often only one component gets trained or the latent variable is simply ignored. We find that disabling dropout noise in responsibility computation is critical to successful training. In addition, the design choices of parameterization, prior distribution, hard versus soft EM and online versus offline assignment can dramatically affect model performance. We develop an evaluation protocol to assess both quality and diversity of generations against multiple references, and provide an extensive empirical study of several mixture model variants. Our analysis shows that certain types of mixture models are more robust and offer the best trade-off between translation quality and diversity compared to variational models and diverse decoding approaches.
Two New Evaluation Datasets for Low-Resource Machine Translation: Nepali-English and Sinhala-English
Feb 04, 2019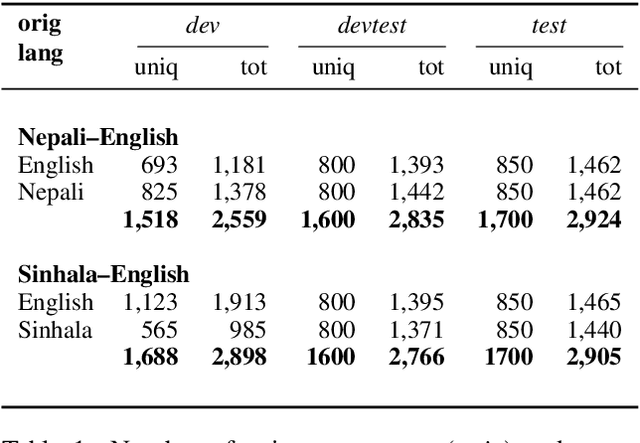
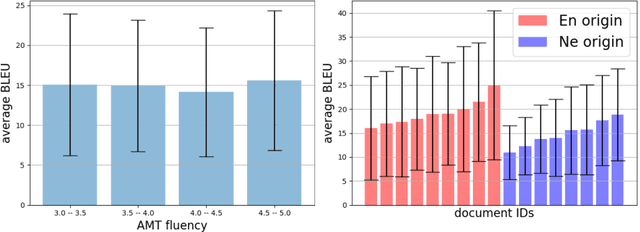
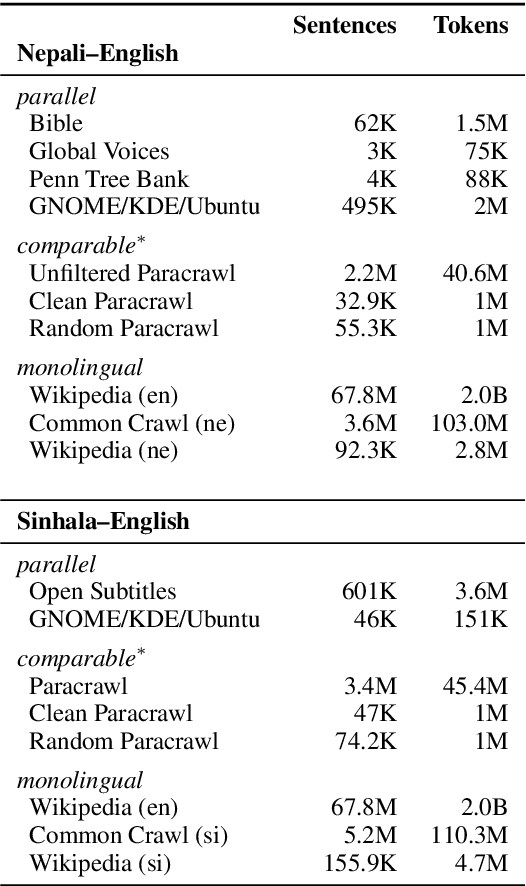
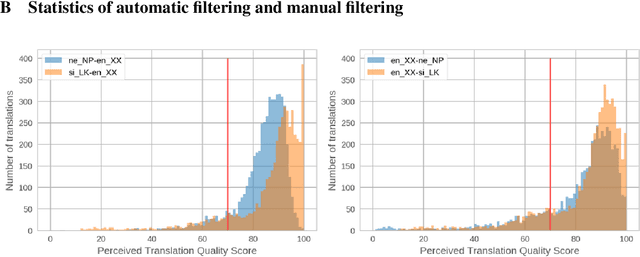
The vast majority of language pairs in the world are low-resource because they have little, if any, parallel data available. Unfortunately, machine translation (MT) systems do not currently work well in this setting. Besides the technical challenges of learning with limited supervision, there is also another challenge: it is very difficult to evaluate methods trained on low resource language pairs because there are very few freely and publicly available benchmarks. In this work, we take sentences from Wikipedia pages and introduce new evaluation datasets in two very low resource language pairs, Nepali-English and Sinhala-English. These are languages with very different morphology and syntax, for which little out-of-domain parallel data is available and for which relatively large amounts of monolingual data are freely available. We describe our process to collect and cross-check the quality of translations, and we report baseline performance using several learning settings: fully supervised, weakly supervised, semi-supervised, and fully unsupervised. Our experiments demonstrate that current state-of-the-art methods perform rather poorly on this benchmark, posing a challenge to the research community working on low resource MT. Data and code to reproduce our experiments are available at https://github.com/facebookresearch/flores.
Classical Structured Prediction Losses for Sequence to Sequence Learning
Oct 05, 2018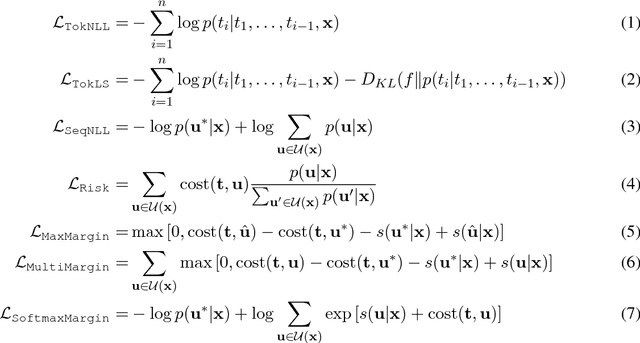
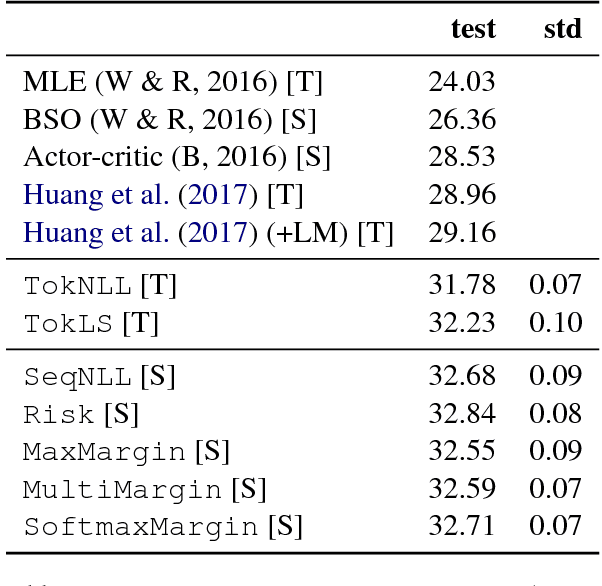
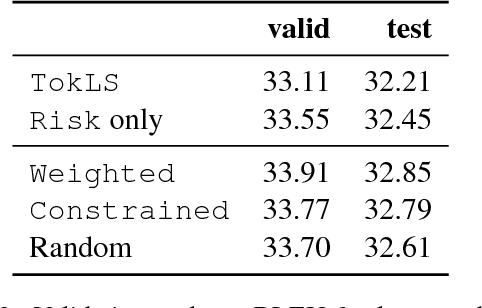
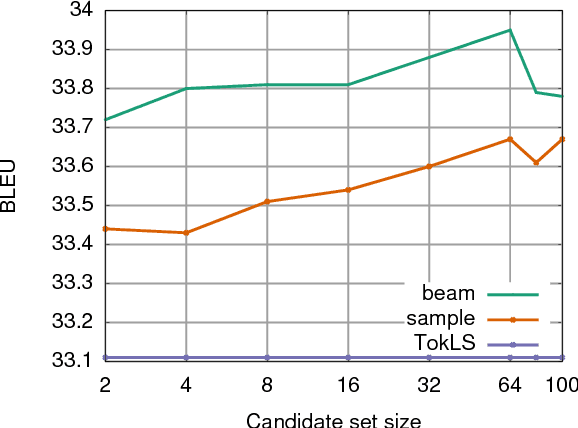
There has been much recent work on training neural attention models at the sequence-level using either reinforcement learning-style methods or by optimizing the beam. In this paper, we survey a range of classical objective functions that have been widely used to train linear models for structured prediction and apply them to neural sequence to sequence models. Our experiments show that these losses can perform surprisingly well by slightly outperforming beam search optimization in a like for like setup. We also report new state of the art results on both IWSLT'14 German-English translation as well as Gigaword abstractive summarization. On the larger WMT'14 English-French translation task, sequence-level training achieves 41.5 BLEU which is on par with the state of the art.
Understanding Back-Translation at Scale
Oct 03, 2018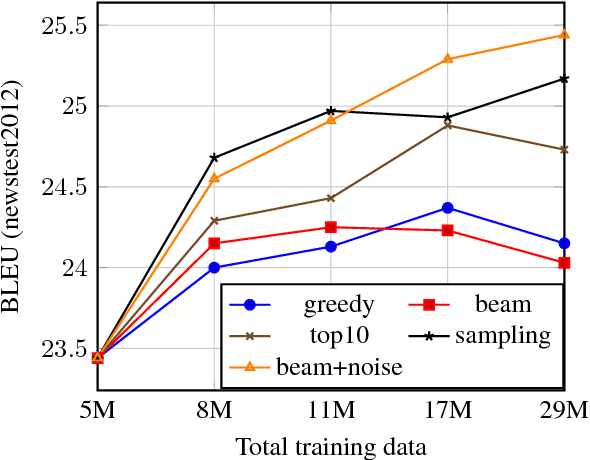
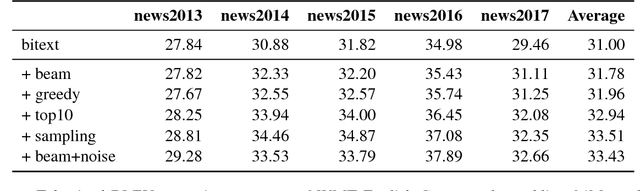
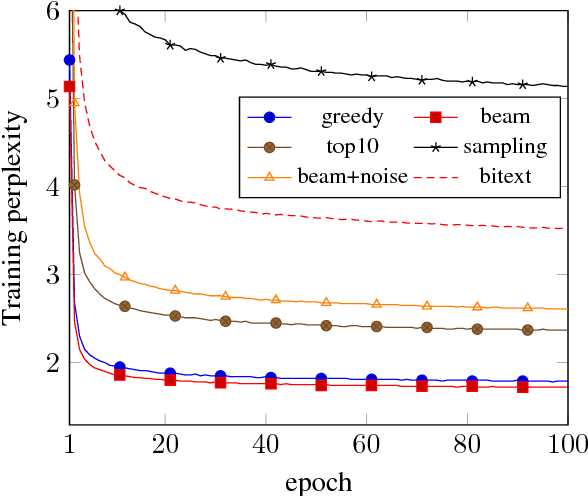
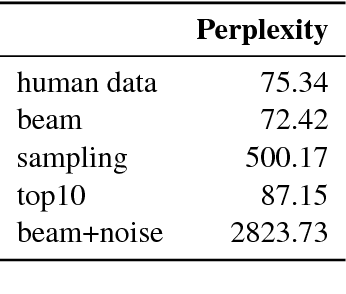
An effective method to improve neural machine translation with monolingual data is to augment the parallel training corpus with back-translations of target language sentences. This work broadens the understanding of back-translation and investigates a number of methods to generate synthetic source sentences. We find that in all but resource poor settings back-translations obtained via sampling or noised beam outputs are most effective. Our analysis shows that sampling or noisy synthetic data gives a much stronger training signal than data generated by beam or greedy search. We also compare how synthetic data compares to genuine bitext and study various domain effects. Finally, we scale to hundreds of millions of monolingual sentences and achieve a new state of the art of 35 BLEU on the WMT'14 English-German test set.
Scaling Neural Machine Translation
Sep 04, 2018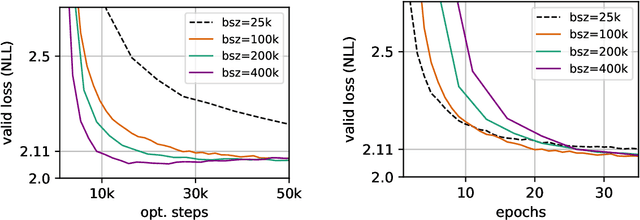
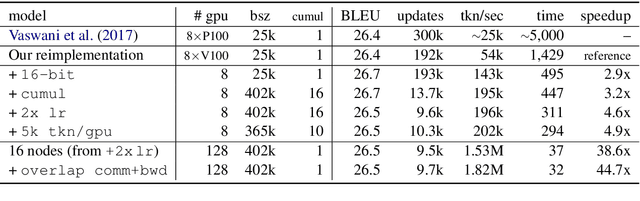
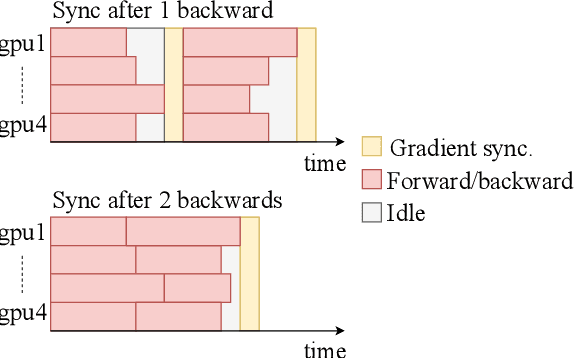
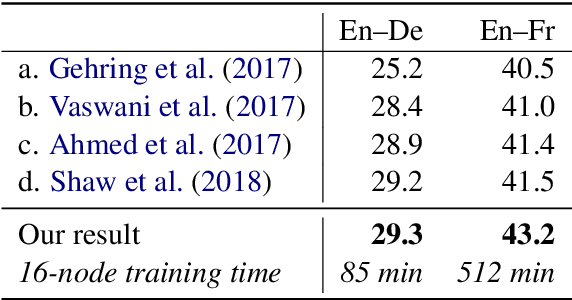
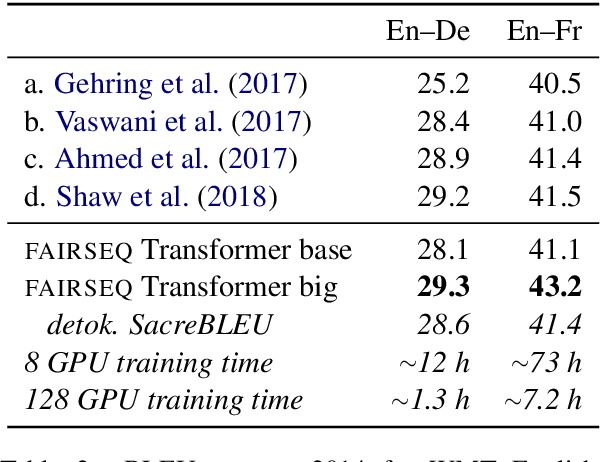
Sequence to sequence learning models still require several days to reach state of the art performance on large benchmark datasets using a single machine. This paper shows that reduced precision and large batch training can speedup training by nearly 5x on a single 8-GPU machine with careful tuning and implementation. On WMT'14 English-German translation, we match the accuracy of Vaswani et al. (2017) in under 5 hours when training on 8 GPUs and we obtain a new state of the art of 29.3 BLEU after training for 85 minutes on 128 GPUs. We further improve these results to 29.8 BLEU by training on the much larger Paracrawl dataset. On the WMT'14 English-French task, we obtain a state-of-the-art BLEU of 43.2 in 8.5 hours on 128 GPUs.
Phrase-Based & Neural Unsupervised Machine Translation
Aug 13, 2018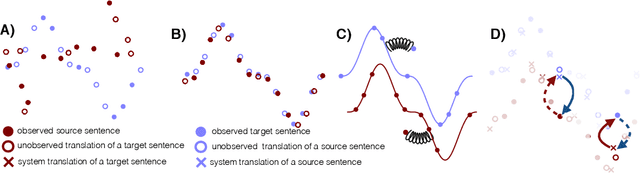
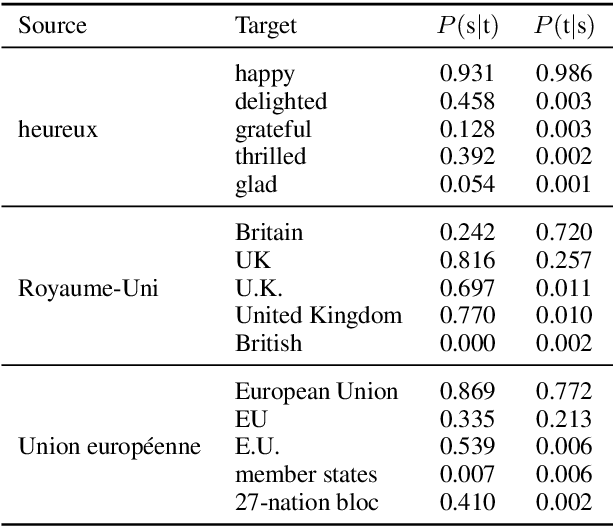
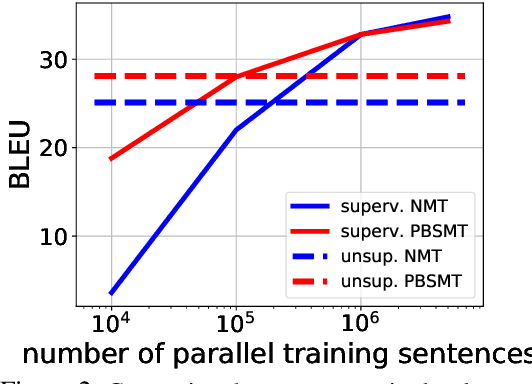
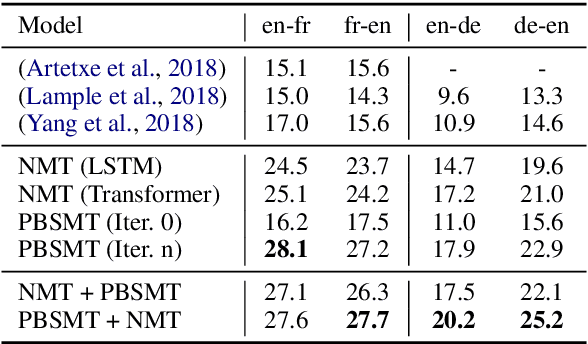
Machine translation systems achieve near human-level performance on some languages, yet their effectiveness strongly relies on the availability of large amounts of parallel sentences, which hinders their applicability to the majority of language pairs. This work investigates how to learn to translate when having access to only large monolingual corpora in each language. We propose two model variants, a neural and a phrase-based model. Both versions leverage a careful initialization of the parameters, the denoising effect of language models and automatic generation of parallel data by iterative back-translation. These models are significantly better than methods from the literature, while being simpler and having fewer hyper-parameters. On the widely used WMT'14 English-French and WMT'16 German-English benchmarks, our models respectively obtain 28.1 and 25.2 BLEU points without using a single parallel sentence, outperforming the state of the art by more than 11 BLEU points. On low-resource languages like English-Urdu and English-Romanian, our methods achieve even better results than semi-supervised and supervised approaches leveraging the paucity of available bitexts. Our code for NMT and PBSMT is publicly available.