 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Based Feature Learning under Structured Data
Sep 07, 2023Recent works have demonstrated that the sample complexity of gradient-based learning of single index models, i.e. functions that depend on a 1-dimensional projection of the input data, is governed by their information exponent. However, these results are only concerned with isotropic data, while in practice the input often contains additional structure which can implicitly guide the algorithm. In this work, we investigate the effect of a spiked covariance structure and reveal several interesting phenomena. First, we show that in the anisotropic setting, the commonly used spherical gradient dynamics may fail to recover the true direction, even when the spike is perfectly aligned with the target direction. Next, we show that appropriate weight normalization that is reminiscent of batch normalization can alleviate this issue. Further, by exploiting the alignment between the (spiked) input covariance and the target, we obtain improved sample complexity compared to the isotropic case. In particular, under the spiked model with a suitably large spike, the sample complexity of gradient-based training can be made independent of the information exponent while also outperforming lower bounds for rotationally invariant kernel methods.
Distributional Model Equivalence for Risk-Sensitive Reinforcement Learning
Jul 04, 2023


We consider the problem of learning models for risk-sensitive reinforcement learning. We theoretically demonstrate that proper value equivalence, a method of learning models which can be used to plan optimally in the risk-neutral setting, is not sufficient to plan optimally in the risk-sensitive setting. We leverage distributional reinforcement learning to introduce two new notions of model equivalence, one which is general and can be used to plan for any risk measure, but is intractable; and a practical variation which allows one to choose which risk measures they may plan optimally for. We demonstrate how our framework can be used to augment any model-free risk-sensitive algorithm, and provide both tabular and large-scale experiments to demonstrate its ability.
Towards a Complete Analysis of Langevin Monte Carlo: Beyond Poincaré Inequality
Mar 07, 2023Langevin diffusions are rapidly convergent under appropriate functional inequality assumptions. Hence, it is natural to expect that with additional smoothness conditions to handle the discretization errors, their discretizations like the Langevin Monte Carlo (LMC) converge in a similar fashion. This research program was initiated by Vemapala and Wibisono (2019), who established results under log-Sobolev inequalities. Chewi et al. (2022) extended the results to handle the case of Poincar\'e inequalities. In this paper, we go beyond Poincar\'e inequalities, and push this research program to its limit. We do so by establishing upper and lower bounds for Langevin diffusions and LMC under weak Poincar\'e inequalities that are satisfied by a large class of densities including polynomially-decaying heavy-tailed densities (i.e., Cauchy-type). Our results explicitly quantify the effect of the initializer on the performance of the LMC algorithm. In particular, we show that as the tail goes from sub-Gaussian, to sub-exponential, and finally to Cauchy-like, the dependency on the initial error goes from being logarithmic, to polynomial, and then finally to being exponential. This three-step phase transition is in particular unavoidable as demonstrated by our lower bounds, clearly defining the boundaries of LMC.
Mean-Square Analysis of Discretized Itô Diffusions for Heavy-tailed Sampling
Mar 01, 2023We analyze the complexity of sampling from a class of heavy-tailed distributions by discretizing a natural class of It\^o diffusions associated with weighted Poincar\'e inequalities. Based on a mean-square analysis, we establish the iteration complexity for obtaining a sample whose distribution is $\epsilon$ close to the target distribution in the Wasserstein-2 metric. In this paper, our results take the mean-square analysis to its limits, i.e., we invariably only require that the target density has finite variance, the minimal requirement for a mean-square analysis. To obtain explicit estimates, we compute upper bounds on certain moments associated with heavy-tailed targets under various assumptions. We also provide similar iteration complexity results for the case where only function evaluations of the unnormalized target density are available by estimating the gradients using a Gaussian smoothing technique. We provide illustrative examples based on the multivariate $t$-distribution.
Improved Discretization Analysis for Underdamped Langevin Monte Carlo
Feb 16, 2023Underdamped Langevin Monte Carlo (ULMC) is an algorithm used to sample from unnormalized densities by leveraging the momentum of a particle moving in a potential well. We provide a novel analysis of ULMC, motivated by two central questions: (1) Can we obtain improved sampling guarantees beyond strong log-concavity? (2) Can we achieve acceleration for sampling? For (1), prior results for ULMC only hold under a log-Sobolev inequality together with a restrictive Hessian smoothness condition. Here, we relax these assumptions by removing the Hessian smoothness condition and by considering distributions satisfying a Poincar\'e inequality. Our analysis achieves the state of art dimension dependence, and is also flexible enough to handle weakly smooth potentials. As a byproduct, we also obtain the first KL divergence guarantees for ULMC without Hessian smoothness under strong log-concavity, which is based on a new result on the log-Sobolev constant along the underdamped Langevin diffusion. For (2), the recent breakthrough of Cao, Lu, and Wang (2020) established the first accelerated result for sampling in continuous time via PDE methods. Our discretization analysis translates their result into an algorithmic guarantee, which indeed enjoys better condition number dependence than prior works on ULMC, although we leave open the question of full acceleration in discrete time. Both (1) and (2) necessitate R\'enyi discretization bounds, which are more challenging than the typically used Wasserstein coupling arguments. We address this using a flexible discretization analysis based on Girsanov's theorem that easily extends to more general settings.
Neural Networks Efficiently Learn Low-Dimensional Representations with SGD
Sep 29, 2022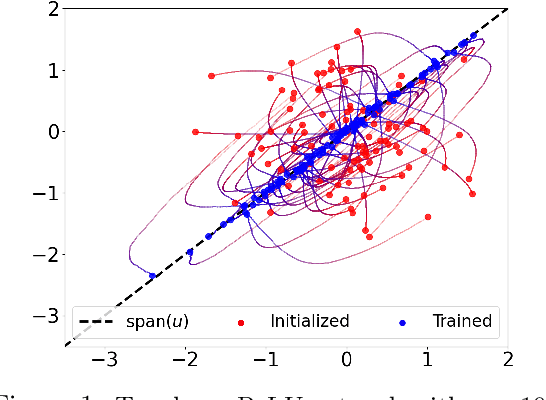
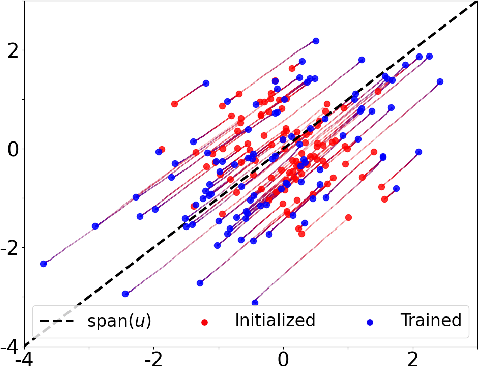
We study the problem of training a two-layer neural network (NN) of arbitrary width using stochastic gradient descent (SGD) where the input $\boldsymbol{x}\in \mathbb{R}^d$ is Gaussian and the target $y \in \mathbb{R}$ follows a multiple-index model, i.e., $y=g(\langle\boldsymbol{u_1},\boldsymbol{x}\rangle,...,\langle\boldsymbol{u_k},\boldsymbol{x}\rangle)$ with a noisy link function $g$. We prove that the first-layer weights of the NN converge to the $k$-dimensional principal subspace spanned by the vectors $\boldsymbol{u_1},...,\boldsymbol{u_k}$ of the true model, when online SGD with weight decay is used for training. This phenomenon has several important consequences when $k \ll d$. First, by employing uniform convergence on this smaller subspace, we establish a generalization error bound of $\mathcal{O}(\sqrt{{kd}/{T}})$ after $T$ iterations of SGD, which is independent of the width of the NN. We further demonstrate that, SGD-trained ReLU NNs can learn a single-index target of the form $y=f(\langle\boldsymbol{u},\boldsymbol{x}\rangle) + \epsilon$ by recovering the principal direction, with a sample complexity linear in $d$ (up to log factors), where $f$ is a monotonic function with at most polynomial growth, and $\epsilon$ is the noise. This is in contrast to the known $d^{\Omega(p)}$ sample requirement to learn any degree $p$ polynomial in the kernel regime, and it shows that NNs trained with SGD can outperform the neural tangent kernel at initialization. Finally, we also provide compressibility guarantees for NNs using the approximate low-rank structure produced by SGD.
Generalization Bounds for Stochastic Gradient Descent via Localized $\varepsilon$-Covers
Sep 19, 2022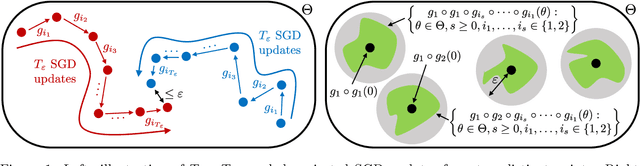
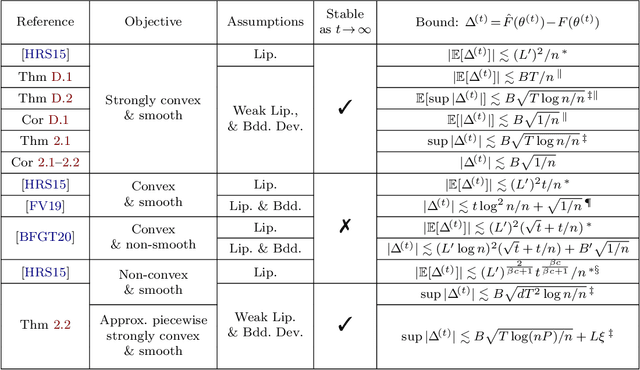
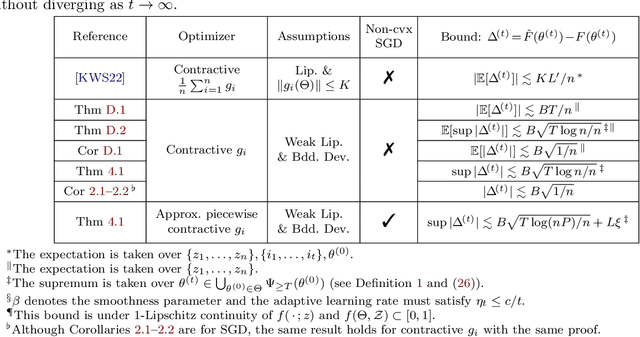
In this paper, we propose a new covering technique localized for the trajectories of SGD. This localization provides an algorithm-specific complexity measured by the covering number, which can have dimension-independent cardinality in contrast to standard uniform covering arguments that result in exponential dimension dependency. Based on this localized construction, we show that if the objective function is a finite perturbation of a piecewise strongly convex and smooth function with $P$ pieces, i.e. non-convex and non-smooth in general, the generalization error can be upper bounded by $O(\sqrt{(\log n\log(nP))/n})$, where $n$ is the number of data samples. In particular, this rate is independent of dimension and does not require early stopping and decaying step size. Finally, we employ these results in various contexts and derive generalization bounds for multi-index linear models, multi-class support vector machines, and $K$-means clustering for both hard and soft label setups, improving the known state-of-the-art rates.
$p$-DkNN: Out-of-Distribution Detection Through Statistical Testing of Deep Representations
Jul 25, 2022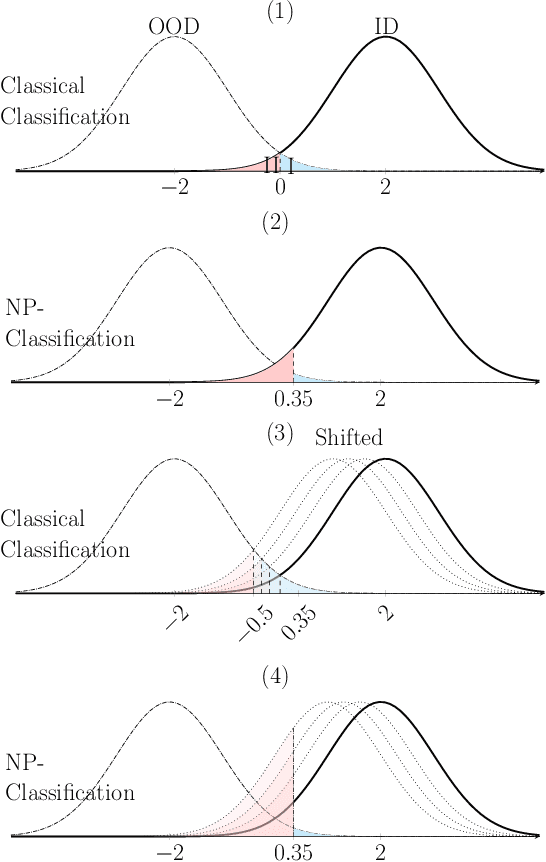
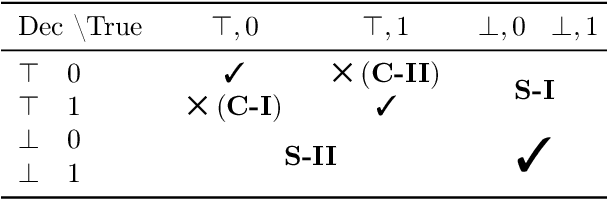
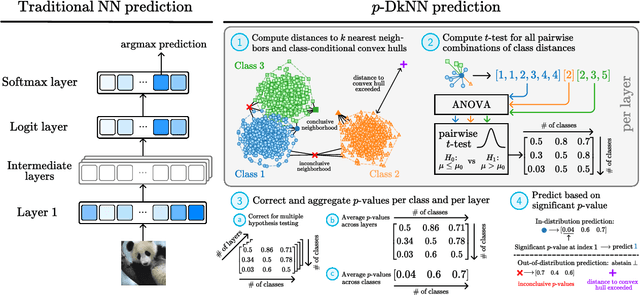
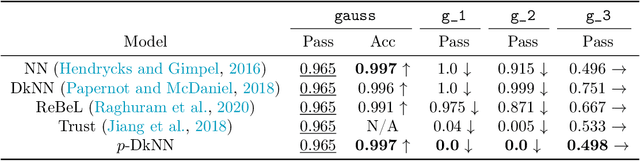
The lack of well-calibrated confidence estimates makes neural networks inadequate in safety-critical domains such as autonomous driving or healthcare. In these settings, having the ability to abstain from making a prediction on out-of-distribution (OOD) data can be as important as correctly classifying in-distribution data. We introduce $p$-DkNN, a novel inference procedure that takes a trained deep neural network and analyzes the similarity structures of its intermediate hidden representations to compute $p$-values associated with the end-to-end model prediction. The intuition is that statistical tests performed on latent representations can serve not only as a classifier, but also offer a statistically well-founded estimation of uncertainty. $p$-DkNN is scalable and leverages the composition of representations learned by hidden layers, which makes deep representation learning successful. Our theoretical analysis builds on Neyman-Pearson classification and connects it to recent advances in selective classification (reject option). We demonstrate advantageous trade-offs between abstaining from predicting on OOD inputs and maintaining high accuracy on in-distribution inputs. We find that $p$-DkNN forces adaptive attackers crafting adversarial examples, a form of worst-case OOD inputs, to introduce semantically meaningful changes to the inputs.
High-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation
May 03, 2022
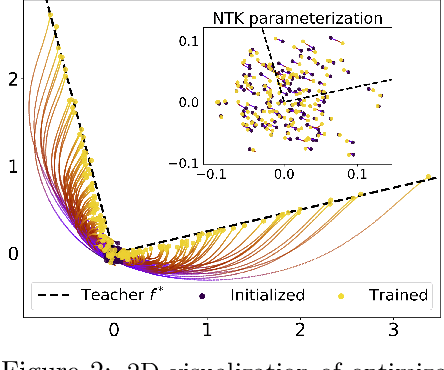
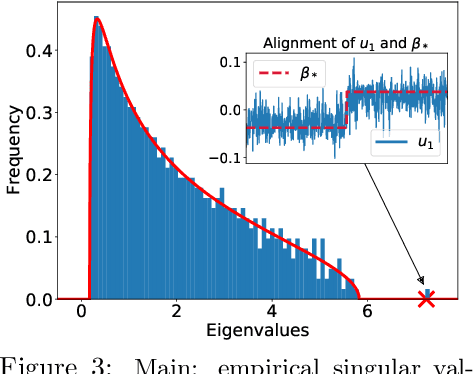
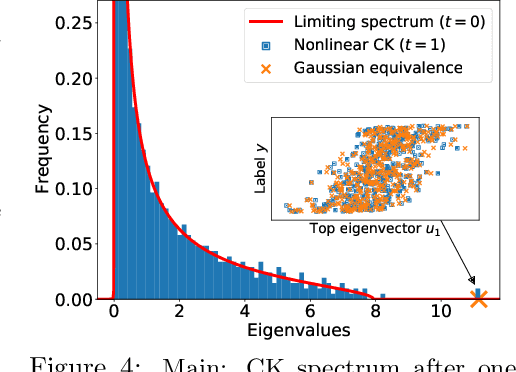
We study the first gradient descent step on the first-layer parameters $\boldsymbol{W}$ in a two-layer neural network: $f(\boldsymbol{x}) = \frac{1}{\sqrt{N}}\boldsymbol{a}^\top\sigma(\boldsymbol{W}^\top\boldsymbol{x})$, where $\boldsymbol{W}\in\mathbb{R}^{d\times N}, \boldsymbol{a}\in\mathbb{R}^{N}$ are randomly initialized, and the training objective is the empirical MSE loss: $\frac{1}{n}\sum_{i=1}^n (f(\boldsymbol{x}_i)-y_i)^2$. In the proportional asymptotic limit where $n,d,N\to\infty$ at the same rate, and an idealized student-teacher setting, we show that the first gradient update contains a rank-1 "spike", which results in an alignment between the first-layer weights and the linear component of the teacher model $f^*$. To characterize the impact of this alignment, we compute the prediction risk of ridge regression on the conjugate kernel after one gradient step on $\boldsymbol{W}$ with learning rate $\eta$, when $f^*$ is a single-index model. We consider two scalings of the first step learning rate $\eta$. For small $\eta$, we establish a Gaussian equivalence property for the trained feature map, and prove that the learned kernel improves upon the initial random features model, but cannot defeat the best linear model on the input. Whereas for sufficiently large $\eta$, we prove that for certain $f^*$, the same ridge estimator on trained features can go beyond this "linear regime" and outperform a wide range of random features and rotationally invariant kernels. Our results demonstrate that even one gradient step can lead to a considerable advantage over random features, and highlight the role of learning rate scaling in the initial phase of training.
Mirror Descent Strikes Again: Optimal Stochastic Convex Optimization under Infinite Noise Variance
Feb 23, 2022
We study stochastic convex optimization under infinite noise variance. Specifically, when the stochastic gradient is unbiased and has uniformly bounded $(1+\kappa)$-th moment, for some $\kappa \in (0,1]$, we quantify the convergence rate of the Stochastic Mirror Descent algorithm with a particular class of uniformly convex mirror maps, in terms of the number of iterations, dimensionality and related geometric parameters of the optimization problem. Interestingly this algorithm does not require any explicit gradient clipping or normalization, which have been extensively used in several recent empirical and theoretical works. We complement our convergence results with information-theoretic lower bounds showing that no other algorithm using only stochastic first-order oracles can achieve improved rates. Our results have several interesting consequences for devising online/streaming stochastic approximation algorithms for problems arising in robust statistics and machine learning.