 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Successive Learning for Dynamic Distributed Model Training over Heterogeneous Wireless Networks
Feb 12, 2022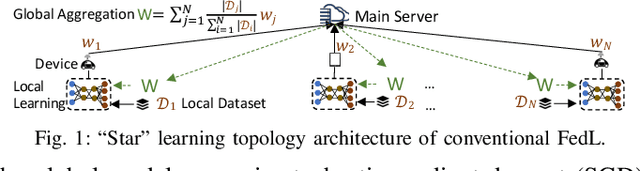
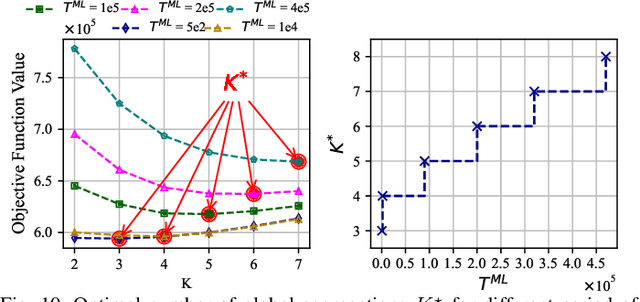
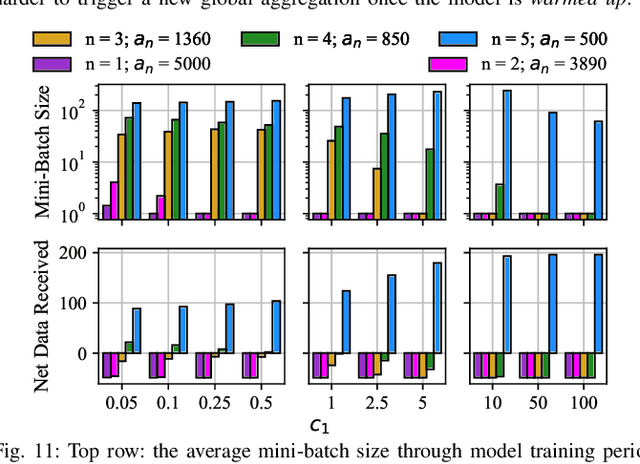
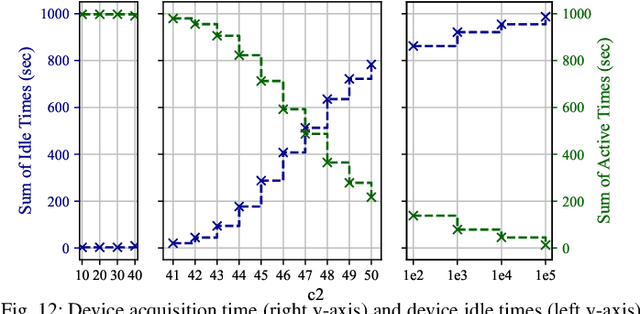
Federated learning (FedL) has emerged as a popular technique for distributing model training over a set of wireless devices, via iterative local updates (at devices) and global aggregations (at the server). In this paper, we develop parallel successive learning (PSL), which expands the FedL architecture along three dimensions: (i) Network, allowing decentralized cooperation among the devices via device-to-device (D2D) communications. (ii) Heterogeneity, interpreted at three levels: (ii-a) Learning: PSL considers heterogeneous number of stochastic gradient descent iterations with different mini-batch sizes at the devices; (ii-b) Data: PSL presumes a dynamic environment with data arrival and departure, where the distributions of local datasets evolve over time, captured via a new metric for model/concept drift. (ii-c) Device: PSL considers devices with different computation and communication capabilities. (iii) Proximity, where devices have different distances to each other and the access point. PSL considers the realistic scenario where global aggregations are conducted with idle times in-between them for resource efficiency improvements, and incorporates data dispersion and model dispersion with local model condensation into FedL. Our analysis sheds light on the notion of cold vs. warmed up models, and model inertia in distributed machine learning. We then propose network-aware dynamic model tracking to optimize the model learning vs. resource efficiency tradeoff, which we show is an NP-hard signomial programming problem. We finally solve this problem through proposing a general optimization solver. Our numerical results reveal new findings on the interdependencies between the idle times in-between the global aggregations, model/concept drift, and D2D cooperation configuration.
Adversarial Neural Networks for Error Correcting Codes
Dec 21, 2021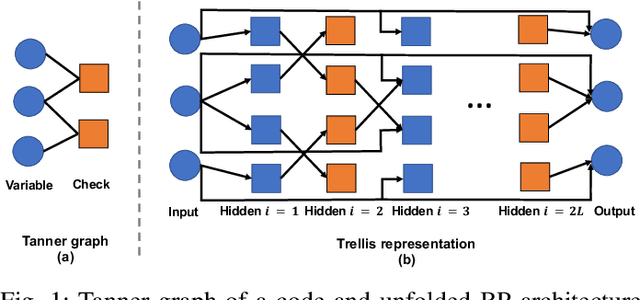
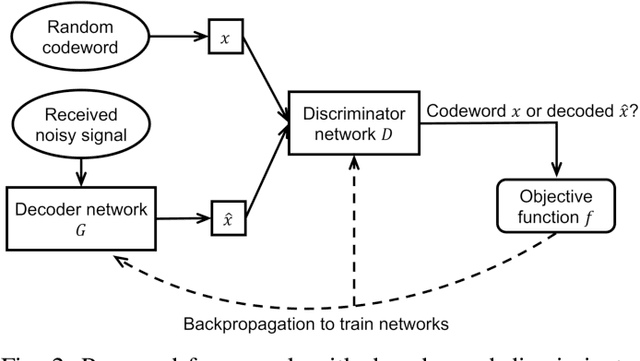
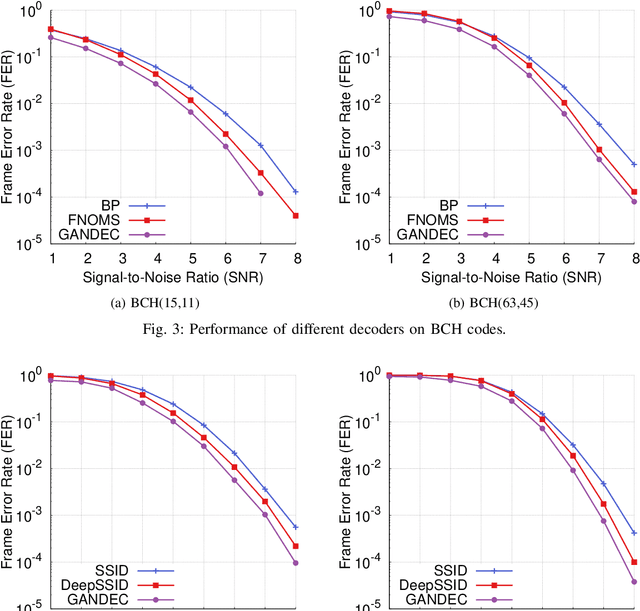
Error correcting codes are a fundamental component in modern day communication systems, demanding extremely high throughput, ultra-reliability and low latency. Recent approaches using machine learning (ML) models as the decoders offer both improved performance and great adaptability to unknown environments, where traditional decoders struggle. We introduce a general framework to further boost the performance and applicability of ML models. We propose to combine ML decoders with a competing discriminator network that tries to distinguish between codewords and noisy words, and, hence, guides the decoding models to recover transmitted codewords. Our framework is game-theoretic, motivated by generative adversarial networks (GANs), with the decoder and discriminator competing in a zero-sum game. The decoder learns to simultaneously decode and generate codewords while the discriminator learns to tell the differences between decoded outputs and codewords. Thus, the decoder is able to decode noisy received signals into codewords, increasing the probability of successful decoding. We show a strong connection of our framework with the optimal maximum likelihood decoder by proving that this decoder defines a Nash equilibrium point of our game. Hence, training to equilibrium has a good possibility of achieving the optimal maximum likelihood performance. Moreover, our framework does not require training labels, which are typically unavailable during communications, and, thus, seemingly can be trained online and adapt to channel dynamics. To demonstrate the performance of our framework, we combine it with the very recent neural decoders and show improved performance compared to the original models and traditional decoding algorithms on various codes.
On-the-fly Resource-Aware Model Aggregation for Federated Learning in Heterogeneous Edge
Dec 21, 2021

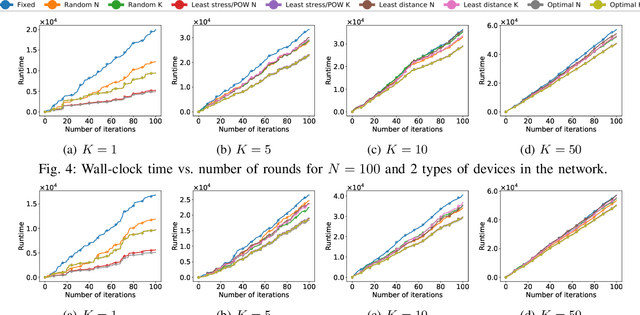
Edge computing has revolutionized the world of mobile and wireless networks world thanks to its flexible, secure, and performing characteristics. Lately, we have witnessed the increasing use of it to make more performing the deployment of machine learning (ML) techniques such as federated learning (FL). FL was debuted to improve communication efficiency compared to conventional distributed machine learning (ML). The original FL assumes a central aggregation server to aggregate locally optimized parameters and might bring reliability and latency issues. In this paper, we conduct an in-depth study of strategies to replace this central server by a flying master that is dynamically selected based on the current participants and/or available resources at every FL round of optimization. Specifically, we compare different metrics to select this flying master and assess consensus algorithms to perform the selection. Our results demonstrate a significant reduction of runtime using our flying master FL framework compared to the original FL from measurements results conducted in our EdgeAI testbed and over real 5G networks using an operational edge testbed.
UAV-assisted Online Machine Learning over Multi-Tiered Networks: A Hierarchical Nested Personalized Federated Learning Approach
Jul 11, 2021
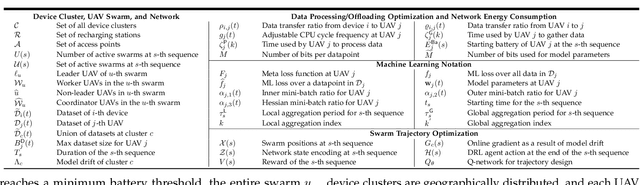
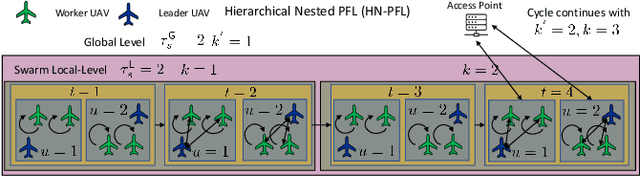
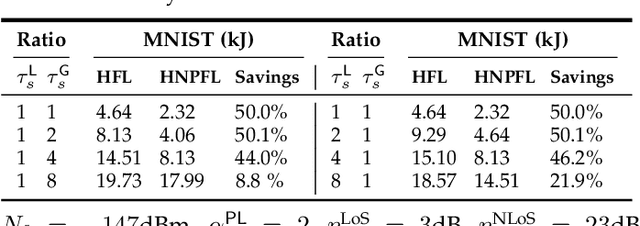
We consider distributed machine learning (ML) through unmanned aerial vehicles (UAVs) for geo-distributed device clusters. We propose five new technologies/techniques: (i) stratified UAV swarms with leader, worker, and coordinator UAVs, (ii) hierarchical nested personalized federated learning (HN-PFL): a holistic distributed ML framework for personalized model training across the worker-leader-core network hierarchy, (iii) cooperative UAV resource pooling for distributed ML using the UAVs' local computational capabilities, (iv) aerial data caching and relaying for efficient data relaying to conduct ML, and (v) concept/model drift, capturing online data variations at the devices. We split the UAV-enabled model training problem as two parts. (a) Network-aware HN-PFL, where we optimize a tradeoff between energy consumption and ML model performance by configuring data offloading among devices-UAVs and UAV-UAVs, UAVs' CPU frequencies, and mini-batch sizes subject to communication/computation network heterogeneity. We tackle this optimization problem via the method of posynomial condensation and propose a distributed algorithm with a performance guarantee. (b) Macro-trajectory and learning duration design, which we formulate as a sequential decision making problem, tackled via deep reinforcement learning. Our simulations demonstrate the superiority of our methodology with regards to the distributed ML performance, the optimization of network resources, and the swarm trajectory efficiency.
Improving Adversarial Robustness Using Proxy Distributions
Apr 19, 2021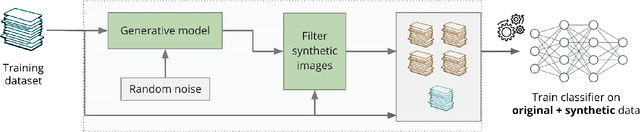

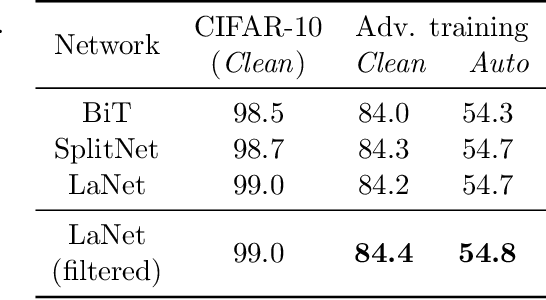
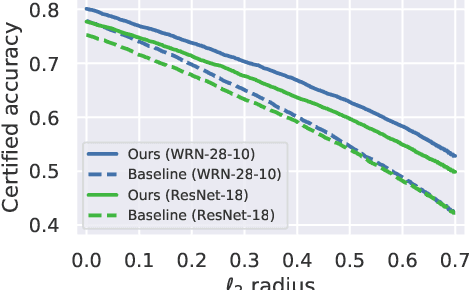
We focus on the use of proxy distributions, i.e., approximations of the underlying distribution of the training dataset, in both understanding and improving the adversarial robustness in image classification. While additional training data helps in adversarial training, curating a very large number of real-world images is challenging. In contrast, proxy distributions enable us to sample a potentially unlimited number of images and improve adversarial robustness using these samples. We first ask the question: when does adversarial robustness benefit from incorporating additional samples from the proxy distribution in the training stage? We prove that the difference between the robustness of a classifier on the proxy and original training dataset distribution is upper bounded by the conditional Wasserstein distance between them. Our result confirms the intuition that samples from a proxy distribution that closely approximates training dataset distribution should be able to boost adversarial robustness. Motivated by this finding, we leverage samples from state-of-the-art generative models, which can closely approximate training data distribution, to improve robustness. In particular, we improve robust accuracy by up to 6.1% and 5.7% in $l_{\infty}$ and $l_2$ threat model, and certified robust accuracy by 6.7% over baselines not using proxy distributions on the CIFAR-10 dataset. Since we can sample an unlimited number of images from a proxy distribution, it also allows us to investigate the effect of an increasing number of training samples on adversarial robustness. Here we provide the first large scale empirical investigation of accuracy vs robustness trade-off and sample complexity of adversarial training by training deep neural networks on 2K to 10M images.
SSD: A Unified Framework for Self-Supervised Outlier Detection
Mar 22, 2021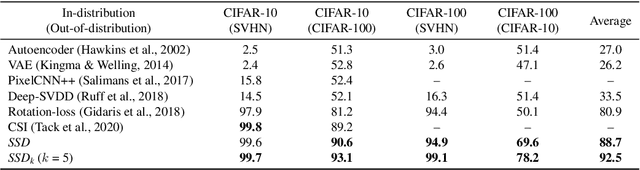
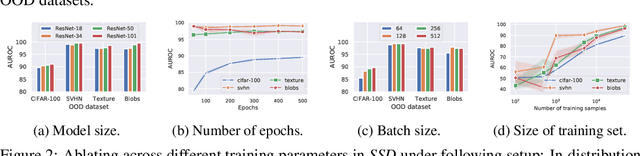
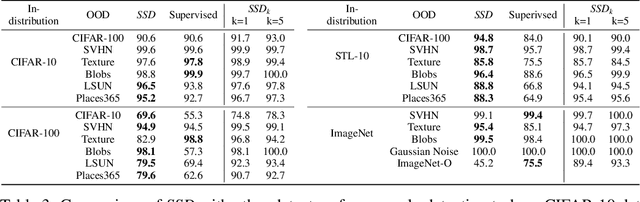
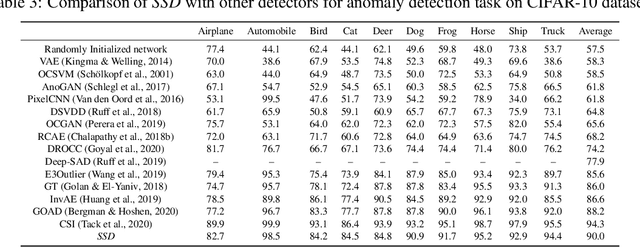
We ask the following question: what training information is required to design an effective outlier/out-of-distribution (OOD) detector, i.e., detecting samples that lie far away from the training distribution? Since unlabeled data is easily accessible for many applications, the most compelling approach is to develop detectors based on only unlabeled in-distribution data. However, we observe that most existing detectors based on unlabeled data perform poorly, often equivalent to a random prediction. In contrast, existing state-of-the-art OOD detectors achieve impressive performance but require access to fine-grained data labels for supervised training. We propose SSD, an outlier detector based on only unlabeled in-distribution data. We use self-supervised representation learning followed by a Mahalanobis distance based detection in the feature space. We demonstrate that SSD outperforms most existing detectors based on unlabeled data by a large margin. Additionally, SSD even achieves performance on par, and sometimes even better, with supervised training based detectors. Finally, we expand our detection framework with two key extensions. First, we formulate few-shot OOD detection, in which the detector has access to only one to five samples from each class of the targeted OOD dataset. Second, we extend our framework to incorporate training data labels, if available. We find that our novel detection framework based on SSD displays enhanced performance with these extensions, and achieves state-of-the-art performance. Our code is publicly available at https://github.com/inspire-group/SSD.
Device Sampling for Heterogeneous Federated Learning: Theory, Algorithms, and Implementation
Jan 04, 2021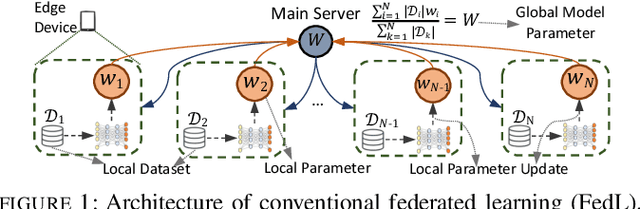
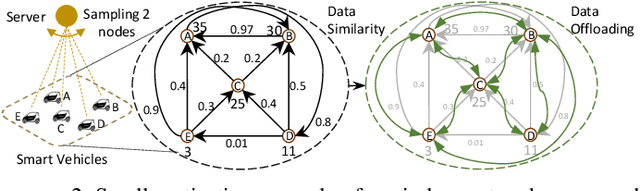
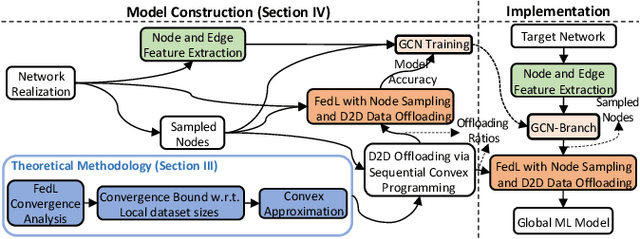
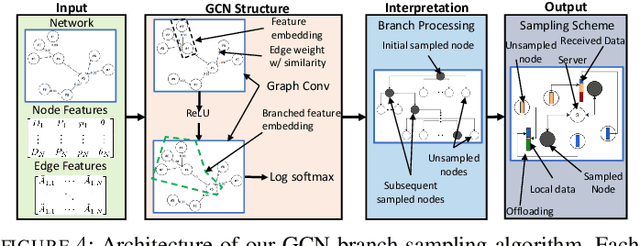
The conventional federated learning (FedL) architecture distributes machine learning (ML) across worker devices by having them train local models that are periodically aggregated by a server. FedL ignores two important characteristics of contemporary wireless networks, however: (i) the network may contain heterogeneous communication/computation resources, while (ii) there may be significant overlaps in devices' local data distributions. In this work, we develop a novel optimization methodology that jointly accounts for these factors via intelligent device sampling complemented by device-to-device (D2D) offloading. Our optimization aims to select the best combination of sampled nodes and data offloading configuration to maximize FedL training accuracy subject to realistic constraints on the network topology and device capabilities. Theoretical analysis of the D2D offloading subproblem leads to new FedL convergence bounds and an efficient sequential convex optimizer. Using this result, we develop a sampling methodology based on graph convolutional networks (GCNs) which learns the relationship between network attributes, sampled nodes, and resulting offloading that maximizes FedL accuracy. Through evaluation on real-world datasets and network measurements from our IoT testbed, we find that our methodology while sampling less than 5% of all devices outperforms conventional FedL substantially both in terms of trained model accuracy and required resource utilization.
RobustBench: a standardized adversarial robustness benchmark
Oct 19, 2020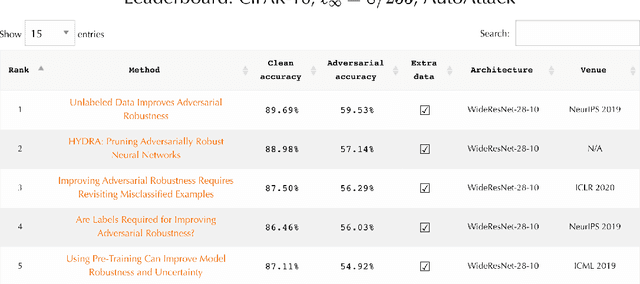
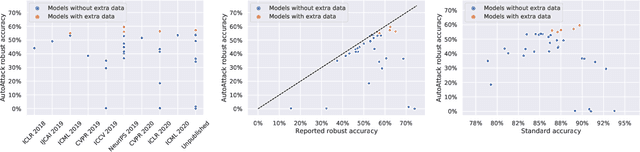
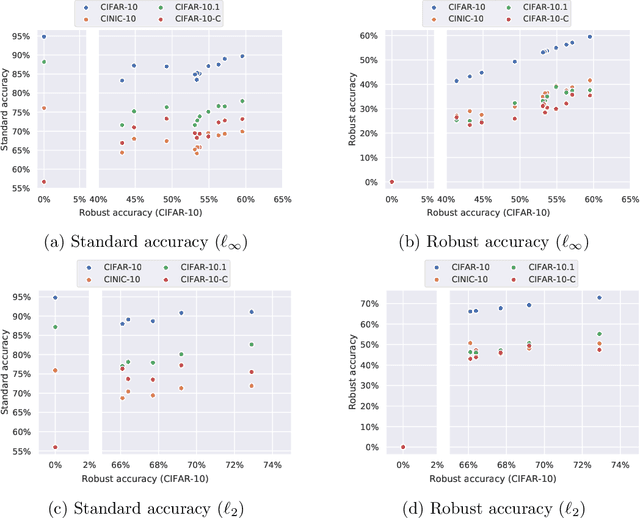
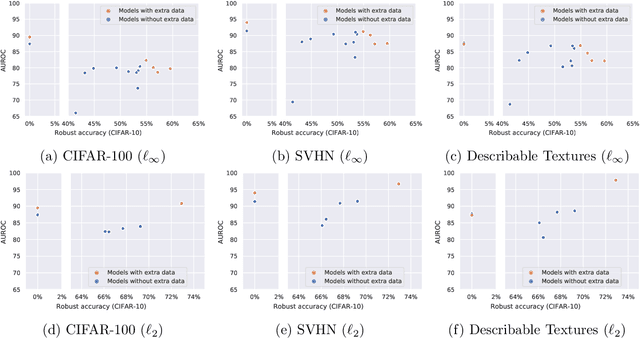
Evaluation of adversarial robustness is often error-prone leading to overestimation of the true robustness of models. While adaptive attacks designed for a particular defense are a way out of this, there are only approximate guidelines on how to perform them. Moreover, adaptive evaluations are highly customized for particular models, which makes it difficult to compare different defenses. Our goal is to establish a standardized benchmark of adversarial robustness, which as accurately as possible reflects the robustness of the considered models within a reasonable computational budget. This requires to impose some restrictions on the admitted models to rule out defenses that only make gradient-based attacks ineffective without improving actual robustness. We evaluate robustness of models for our benchmark with AutoAttack, an ensemble of white- and black-box attacks which was recently shown in a large-scale study to improve almost all robustness evaluations compared to the original publications. Our leaderboard, hosted at http://robustbench.github.io/, aims at reflecting the current state of the art on a set of well-defined tasks in $\ell_\infty$- and $\ell_2$-threat models with possible extensions in the future. Additionally, we open-source the library http://github.com/RobustBench/robustbench that provides unified access to state-of-the-art robust models to facilitate their downstream applications. Finally, based on the collected models, we analyze general trends in $\ell_p$-robustness and its impact on other tasks such as robustness to various distribution shifts and out-of-distribution detection.
Fast-Convergent Federated Learning
Jul 26, 2020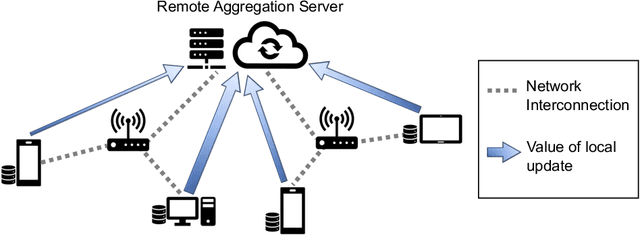
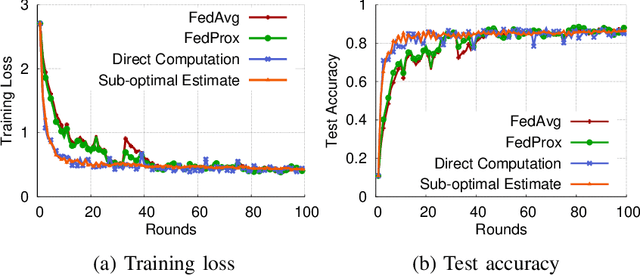
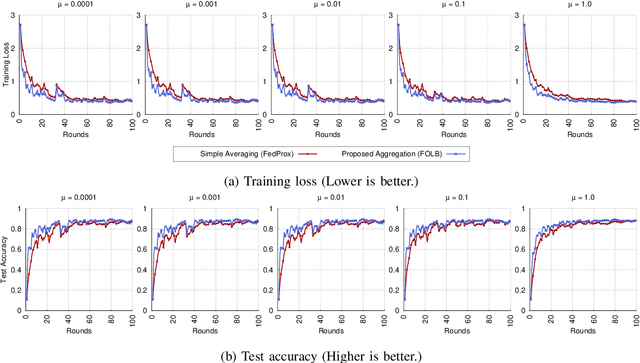
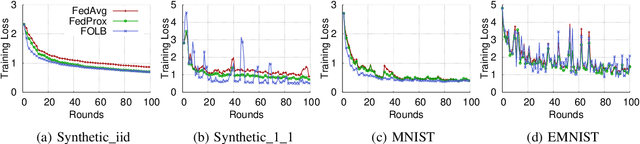
Federated learning has emerged recently as a promising solution for distributing machine learning tasks through modern networks of mobile devices. Recent studies have obtained lower bounds on the expected decrease in model loss that is achieved through each round of federated learning. However, convergence generally requires a large number of communication rounds, which induces delay in model training and is costly in terms of network resources. In this paper, we propose a fast-convergent federated learning algorithm, called FOLB, which obtains significant improvements in convergence speed through intelligent sampling of devices in each round of model training. We first theoretically characterize a lower bound on improvement that can be obtained in each round if devices are selected according to the expected improvement their local models will provide to the current global model. Then, we show that FOLB obtains this bound through uniform sampling by weighting device updates according to their gradient information. FOLB is able to handle both communication and computation heterogeneity of devices by adapting the aggregations according to estimates of device's capabilities of contributing to the updates. We evaluate FOLB in comparison with existing federated learning algorithms and experimentally show its improvement in training loss and test accuracy across various machine learning tasks and datasets.
Time for a Background Check! Uncovering the impact of Background Features on Deep Neural Networks
Jun 24, 2020
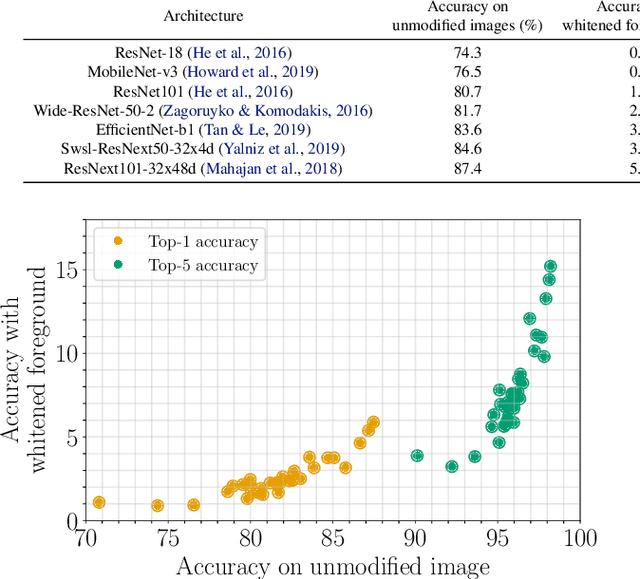

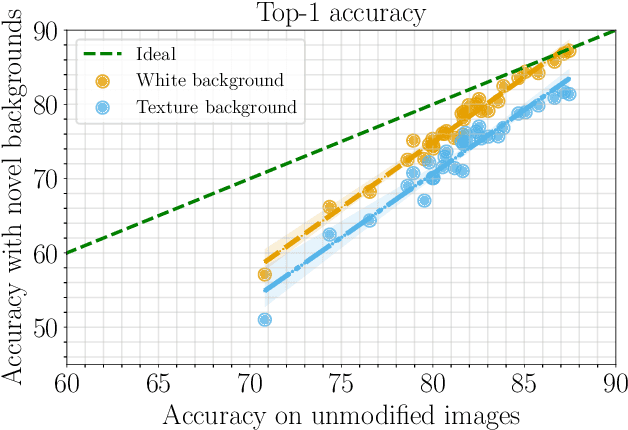
With increasing expressive power, deep neural networks have significantly improved the state-of-the-art on image classification datasets, such as ImageNet. In this paper, we investigate to what extent the increasing performance of deep neural networks is impacted by background features? In particular, we focus on background invariance, i.e., accuracy unaffected by switching background features and background influence, i.e., predictive power of background features itself when foreground is masked. We perform experiments with 32 different neural networks ranging from small-size networks to large-scale networks trained with up to one Billion images. Our investigations reveal that increasing expressive power of DNNs leads to higher influence of background features, while simultaneously, increases their ability to make the correct prediction when background features are removed or replaced with a randomly selected texture-based background.