 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARTOO-DARTU: Studying AR-HRC With AR Obstruction Mitigation During a Warehouse Task
Jun 23, 2026Human-robot collaboration (HRC) often requires robot intentions and internal states to be conveyed to users for task efficiency and safety. Recently, augmented reality (AR) situated analytics provide such real-time robot feedback in HRC contexts. However, AR situated analytics can obstruct important real-world elements, posing safety and usability risks, especially when content is dynamically positioned relative to movements of mobile robots in a warehouse HRC scenario. In this paper, we introduce the Augmented Reality Technique Of Obstruction Deterrence while Aiding Robotic Teaming for Users (ARTOO-DARTU), an AR system tailored specifically for warehouse HRC that enables real-time robot situated analytics and control while preserving visibility of the real world through an obstruction detection and mitigation pipeline (ODM) that is uniquely suited for AR-HRC. To evaluate ARTOO-DARTU, we developed Pocket MonstARs, a controlled gamified abstraction of HRC warehouse inventory picking in which virtual monsters serve as proxies for pick targets, while labeled and object-marked boxes preserve the real-world identification demands of the picking task. In a 34-participant user study, we found that our designed AR situated analytics yielded a 46% increase in efficiency on the overall HRC task, but only when the ODM was active. Participants with the ODM active were also 61% faster on subtasks requiring visibility of the real world. Our findings demonstrate that, when paired with our developed ODM to prevent real-world obstructions, the situated analytics in ARTOO-DARTU can significantly enhance efficiency and user experience in AR-HRC warehouse scenarios.
fARfetch: Enabling Collocated AR-HRC in Large Visually Diverse Environments with VLM-Driven AR Content Adaptation
Jun 23, 2026Augmented Reality (AR) can improve collocated human-robot collaboration by making robot state and intent visible and enabling intuitive control, yet large, visually diverse environments like the outdoors challenge both interaction and content legibility, especially at long distances and beyond visual line of sight. We present fARfetch, an AR-HRC system that integrates (i) shared semantic environment mapping across an AR headset and robot that visualizes detected landmarks in AR to support landmark-grounded go-to commands, (ii) a context-aware world-in-miniature representation of the shared environment for fine-grained path authoring, and (iii) vision-language-model driven AR view management that jointly adapts virtual content color, size, and orientation to maintain legibility in large visually diverse environments. We implement fARfetch with a Meta Quest 3 headset and Unitree Go2 quadruped robot, and conduct a within-subjects user study (N=13) on a real-world large-scale (30.5m) outdoor inspection task. fARfetch yielded significantly faster completion times than a non-AR baseline (66%) and significantly lower workload in mental demand (-43%), temporal demand (-34%), and frustration (-66%). A custom legibility survey indicated fARfetch effectively maintained virtual content legibility in the large outdoor environment.
Benchmarking Vision-Language Models under Contradictory Virtual Content Attacks in Augmented Reality
Apr 07, 2026Augmented reality (AR) has rapidly expanded over the past decade. As AR becomes increasingly integrated into daily life, its security and reliability emerge as critical challenges. Among various threats, contradictory virtual content attacks, where malicious or inconsistent virtual elements are introduced into the user's view, pose a unique risk by misleading users, creating semantic confusion, or delivering harmful information. In this work, we systematically model such attacks and present ContrAR, a novel benchmark for evaluating the robustness of vision-language models (VLMs) against virtual content manipulation and contradiction in AR. ContrAR contains 312 real-world AR videos validated by 10 human participants. We further benchmark 11 VLMs, including both commercial and open-source models. Experimental results reveal that while current VLMs exhibit reasonable understanding of contradictory virtual content, room still remains for improvement in detecting and reasoning about adversarial content manipulations in AR environments. Moreover, balancing detection accuracy and latency remains challenging.
User Prompting Strategies and Prompt Enhancement Methods for Open-Set Object Detection in XR Environments
Jan 30, 2026Open-set object detection (OSOD) localizes objects while identifying and rejecting unknown classes at inference. While recent OSOD models perform well on benchmarks, their behavior under realistic user prompting remains underexplored. In interactive XR settings, user-generated prompts are often ambiguous, underspecified, or overly detailed. To study prompt-conditioned robustness, we evaluate two OSOD models, GroundingDINO and YOLO-E, on real-world XR images and simulate diverse user prompting behaviors using vision-language models. We consider four prompt types: standard, underdetailed, overdetailed, and pragmatically ambiguous, and examine the impact of two enhancement strategies on these prompts. Results show that both models exhibit stable performance under underdetailed and standard prompts, while they suffer degradation under ambiguous prompts. Overdetailed prompts primarily affect GroundingDINO. Prompt enhancement substantially improves robustness under ambiguity, yielding gains exceeding 55% mIoU and 41% average confidence. Based on the findings, we propose several prompting strategies and prompt enhancement methods for OSOD models in XR environments.
Can a Unimodal Language Agent Provide Preferences to Tune a Multimodal Vision-Language Model?
Jan 10, 2026To explore a more scalable path for adding multimodal capabilities to existing LLMs, this paper addresses a fundamental question: Can a unimodal LLM, relying solely on text, reason about its own informational needs and provide effective feedback to optimize a multimodal model? To answer this, we propose a method that enables a language agent to give feedback to a vision-language model (VLM) to adapt text generation to the agent's preferences. Our results from different experiments affirm this hypothesis, showing that LLM preference feedback significantly enhances VLM descriptions. Using our proposed method, we find that the VLM can generate multimodal scene descriptions to help the LLM better understand multimodal context, leading to improvements of maximum 13% in absolute accuracy compared to the baseline multimodal approach. Furthermore, a human study validated our AI-driven feedback, showing a 64.6% preference alignment rate between the LLM's choices and human judgments. Extensive experiments provide insights on how and why the method works and its limitations.
Will You Be Aware? Eye Tracking-Based Modeling of Situational Awareness in Augmented Reality
Aug 07, 2025Augmented Reality (AR) systems, while enhancing task performance through real-time guidance, pose risks of inducing cognitive tunneling-a hyperfocus on virtual content that compromises situational awareness (SA) in safety-critical scenarios. This paper investigates SA in AR-guided cardiopulmonary resuscitation (CPR), where responders must balance effective compressions with vigilance to unpredictable hazards (e.g., patient vomiting). We developed an AR app on a Magic Leap 2 that overlays real-time CPR feedback (compression depth and rate) and conducted a user study with simulated unexpected incidents (e.g., bleeding) to evaluate SA, in which SA metrics were collected via observation and questionnaires administered during freeze-probe events. Eye tracking analysis revealed that higher SA levels were associated with greater saccadic amplitude and velocity, and with reduced proportion and frequency of fixations on virtual content. To predict SA, we propose FixGraphPool, a graph neural network that structures gaze events (fixations, saccades) into spatiotemporal graphs, effectively capturing dynamic attentional patterns. Our model achieved 83.0% accuracy (F1=81.0%), outperforming feature-based machine learning and state-of-the-art time-series models by leveraging domain knowledge and spatial-temporal information encoded in ET data. These findings demonstrate the potential of eye tracking for SA modeling in AR and highlight its utility in designing AR systems that ensure user safety and situational awareness.
Detecting Visual Information Manipulation Attacks in Augmented Reality: A Multimodal Semantic Reasoning Approach
Jul 27, 2025The virtual content in augmented reality (AR) can introduce misleading or harmful information, leading to semantic misunderstandings or user errors. In this work, we focus on visual information manipulation (VIM) attacks in AR where virtual content changes the meaning of real-world scenes in subtle but impactful ways. We introduce a taxonomy that categorizes these attacks into three formats: character, phrase, and pattern manipulation, and three purposes: information replacement, information obfuscation, and extra wrong information. Based on the taxonomy, we construct a dataset, AR-VIM. It consists of 452 raw-AR video pairs spanning 202 different scenes, each simulating a real-world AR scenario. To detect such attacks, we propose a multimodal semantic reasoning framework, VIM-Sense. It combines the language and visual understanding capabilities of vision-language models (VLMs) with optical character recognition (OCR)-based textual analysis. VIM-Sense achieves an attack detection accuracy of 88.94% on AR-VIM, consistently outperforming vision-only and text-only baselines. The system reaches an average attack detection latency of 7.07 seconds in a simulated video processing framework and 7.17 seconds in a real-world evaluation conducted on a mobile Android AR application.
UAV-assisted Online Machine Learning over Multi-Tiered Networks: A Hierarchical Nested Personalized Federated Learning Approach
Jul 11, 2021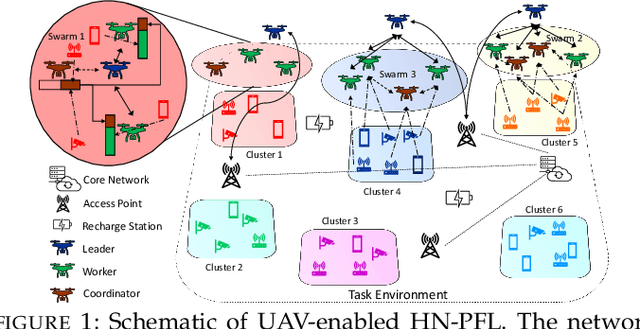
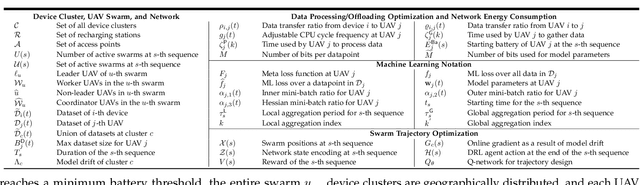
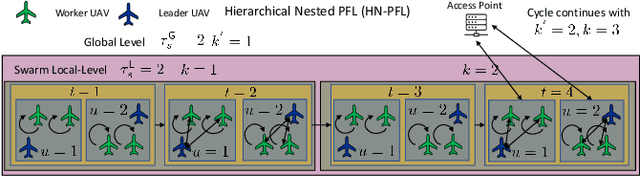
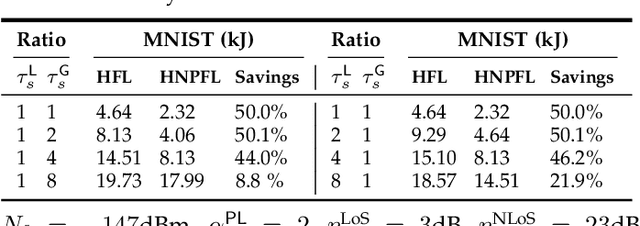
We consider distributed machine learning (ML) through unmanned aerial vehicles (UAVs) for geo-distributed device clusters. We propose five new technologies/techniques: (i) stratified UAV swarms with leader, worker, and coordinator UAVs, (ii) hierarchical nested personalized federated learning (HN-PFL): a holistic distributed ML framework for personalized model training across the worker-leader-core network hierarchy, (iii) cooperative UAV resource pooling for distributed ML using the UAVs' local computational capabilities, (iv) aerial data caching and relaying for efficient data relaying to conduct ML, and (v) concept/model drift, capturing online data variations at the devices. We split the UAV-enabled model training problem as two parts. (a) Network-aware HN-PFL, where we optimize a tradeoff between energy consumption and ML model performance by configuring data offloading among devices-UAVs and UAV-UAVs, UAVs' CPU frequencies, and mini-batch sizes subject to communication/computation network heterogeneity. We tackle this optimization problem via the method of posynomial condensation and propose a distributed algorithm with a performance guarantee. (b) Macro-trajectory and learning duration design, which we formulate as a sequential decision making problem, tackled via deep reinforcement learning. Our simulations demonstrate the superiority of our methodology with regards to the distributed ML performance, the optimization of network resources, and the swarm trajectory efficiency.