 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Baselines for Multilingual Reply Suggestion
Jun 03, 2021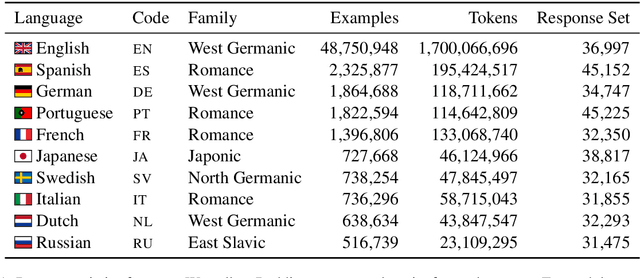
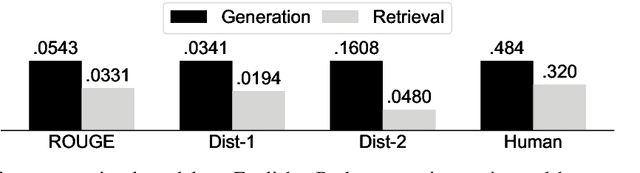

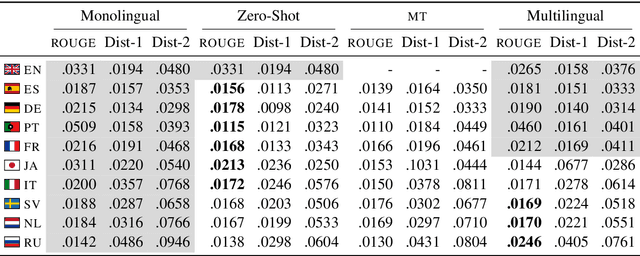
Reply suggestion models help users process emails and chats faster. Previous work only studies English reply suggestion. Instead, we present MRS, a multilingual reply suggestion dataset with ten languages. MRS can be used to compare two families of models: 1) retrieval models that select the reply from a fixed set and 2) generation models that produce the reply from scratch. Therefore, MRS complements existing cross-lingual generalization benchmarks that focus on classification and sequence labeling tasks. We build a generation model and a retrieval model as baselines for MRS. The two models have different strengths in the monolingual setting, and they require different strategies to generalize across languages. MRS is publicly available at https://github.com/zhangmozhi/mrs.
Optimization of Graph Neural Networks: Implicit Acceleration by Skip Connections and More Depth
May 26, 2021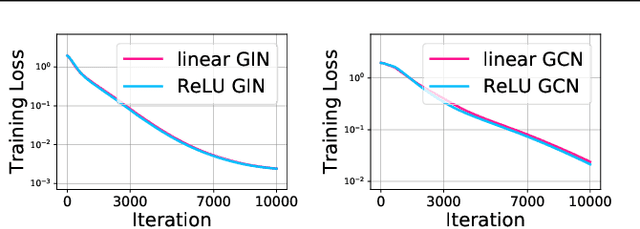
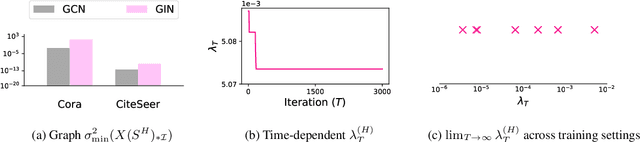
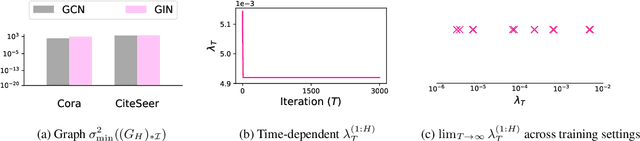
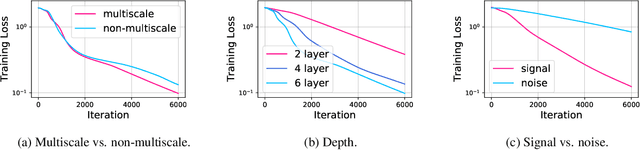
Graph Neural Networks (GNNs) have been studied through the lens of expressive power and generalization. However, their optimization properties are less well understood. We take the first step towards analyzing GNN training by studying the gradient dynamics of GNNs. First, we analyze linearized GNNs and prove that despite the non-convexity of training, convergence to a global minimum at a linear rate is guaranteed under mild assumptions that we validate on real-world graphs. Second, we study what may affect the GNNs' training speed. Our results show that the training of GNNs is implicitly accelerated by skip connections, more depth, and/or a good label distribution. Empirical results confirm that our theoretical results for linearized GNNs align with the training behavior of nonlinear GNNs. Our results provide the first theoretical support for the success of GNNs with skip connections in terms of optimization, and suggest that deep GNNs with skip connections would be promising in practice.
Noisy Labels Can Induce Good Representations
Dec 23, 2020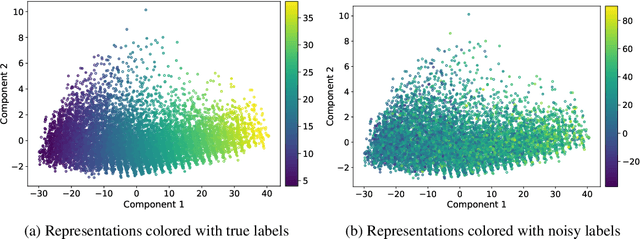

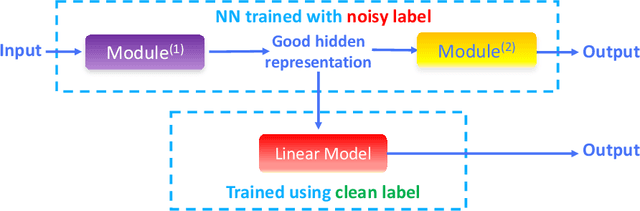
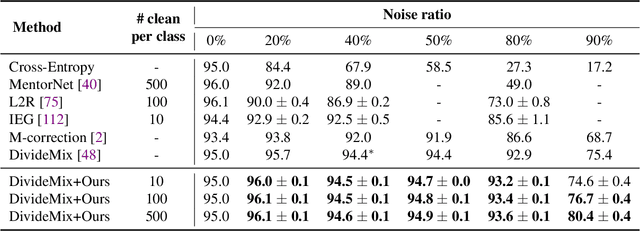
The current success of deep learning depends on large-scale labeled datasets. In practice, high-quality annotations are expensive to collect, but noisy annotations are more affordable. Previous works report mixed empirical results when training with noisy labels: neural networks can easily memorize random labels, but they can also generalize from noisy labels. To explain this puzzle, we study how architecture affects learning with noisy labels. We observe that if an architecture "suits" the task, training with noisy labels can induce useful hidden representations, even when the model generalizes poorly; i.e., the last few layers of the model are more negatively affected by noisy labels. This finding leads to a simple method to improve models trained on noisy labels: replacing the final dense layers with a linear model, whose weights are learned from a small set of clean data. We empirically validate our findings across three architectures (Convolutional Neural Networks, Graph Neural Networks, and Multi-Layer Perceptrons) and two domains (graph algorithmic tasks and image classification). Furthermore, we achieve state-of-the-art results on image classification benchmarks by combining our method with existing approaches on noisy label training.
How Neural Networks Extrapolate: From Feedforward to Graph Neural Networks
Oct 01, 2020


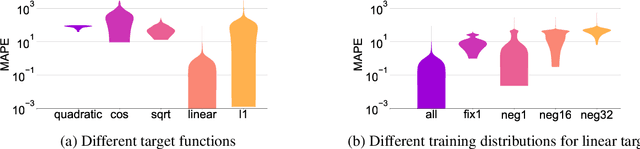
We study how neural networks trained by gradient descent extrapolate, i.e., what they learn outside the support of the training distribution. Previous works report mixed empirical results when extrapolating with neural networks: while multilayer perceptrons (MLPs) do not extrapolate well in certain simple tasks, Graph Neural Network (GNN), a structured network with MLP modules, has shown some success in more complex tasks. Working towards a theoretical explanation, we identify conditions under which MLPs and GNNs extrapolate well. First, we quantify the observation that ReLU MLPs quickly converge to linear functions along any direction from the origin, which implies that ReLU MLPs do not extrapolate most non-linear functions. But, they can provably learn a linear target function when the training distribution is sufficiently "diverse". Second, in connection to analyzing successes and limitations of GNNs, these results suggest a hypothesis for which we provide theoretical and empirical evidence: the success of GNNs in extrapolating algorithmic tasks to new data (e.g., larger graphs or edge weights) relies on encoding task-specific non-linearities in the architecture or features.
Why Overfitting Isn't Always Bad: Retrofitting Cross-Lingual Word Embeddings to Dictionaries
May 01, 2020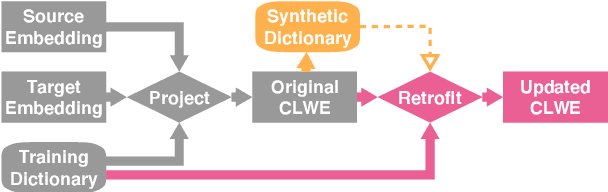
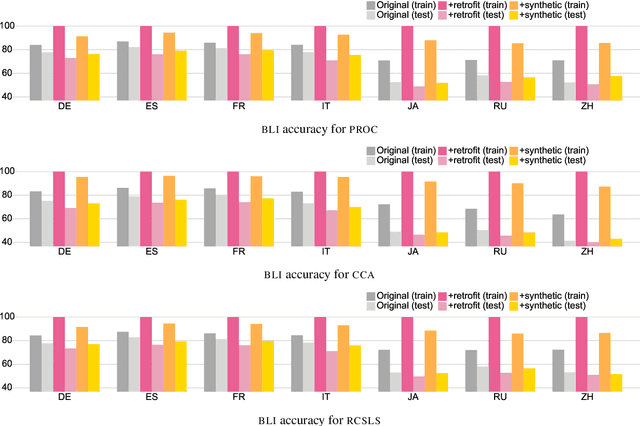
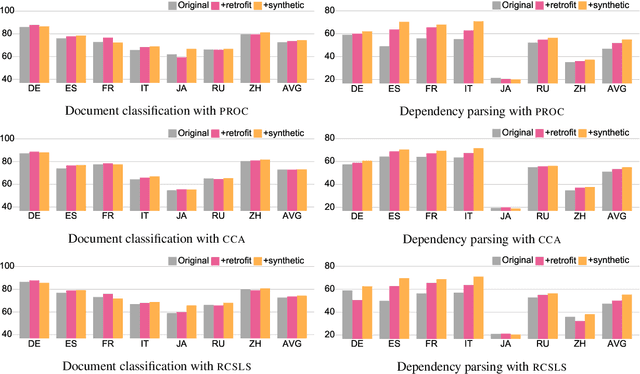
Cross-lingual word embeddings (CLWE) are often evaluated on bilingual lexicon induction (BLI). Recent CLWE methods use linear projections, which underfit the training dictionary, to generalize on BLI. However, underfitting can hinder generalization to other downstream tasks that rely on words from the training dictionary. We address this limitation by retrofitting CLWE to the training dictionary, which pulls training translation pairs closer in the embedding space and overfits the training dictionary. This simple post-processing step often improves accuracy on two downstream tasks, despite lowering BLI test accuracy. We also retrofit to both the training dictionary and a synthetic dictionary induced from CLWE, which sometimes generalizes even better on downstream tasks. Our results confirm the importance of fully exploiting training dictionary in downstream tasks and explains why BLI is a flawed CLWE evaluation.
Interactive Refinement of Cross-Lingual Word Embeddings
Nov 08, 2019



Cross-lingual word embeddings transfer knowledge between languages: models trained for a high-resource language can be used in a low-resource language. These embeddings are usually trained on general-purpose corpora but used for a domain-specific task. We introduce CLIME, an interactive system that allows a user to quickly adapt cross-lingual word embeddings for a given classification problem. First, words in the vocabulary are ranked by their salience to the downstream task. Then, salient keywords are displayed on an interface. Users mark the similarity between each keyword and its nearest neighbors in the embedding space. Finally, CLIME updates the embeddings using the annotations. We experiment clime on a cross-lingual text classification benchmark for four low-resource languages: Ilocano, Sinhalese, Tigrinya, and Uyghur. Embeddings refined by CLIME capture more nuanced word semantics and have higher test accuracy than the original embeddings. CLIME also improves test accuracy faster than an active learning baseline, and a simple combination of CLIME with active learning has the highest test accuracy.
Are Girls Neko or Shōjo? Cross-Lingual Alignment of Non-Isomorphic Embeddings with Iterative Normalization
Jun 05, 2019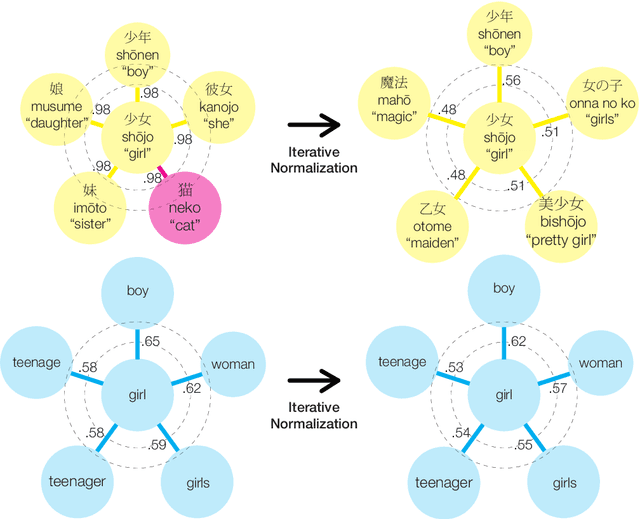
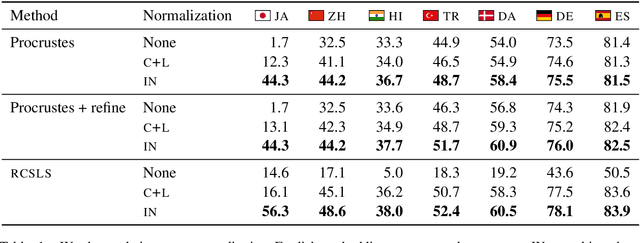
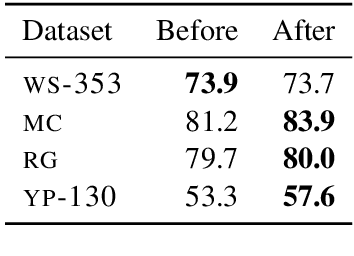
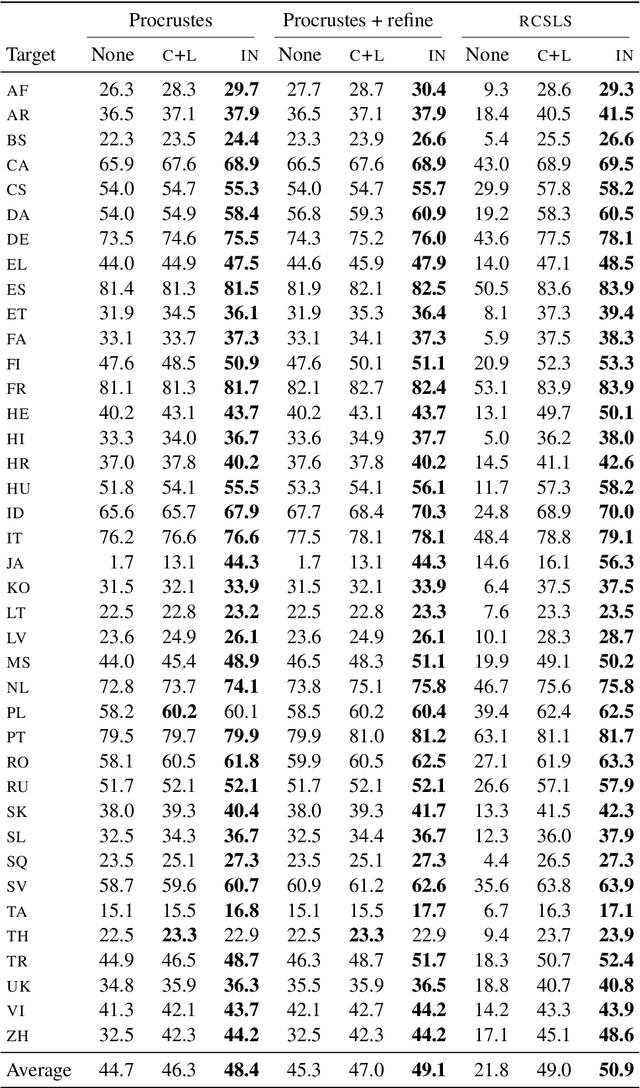
Cross-lingual word embeddings (CLWE) underlie many multilingual natural language processing systems, often through orthogonal transformations of pre-trained monolingual embeddings. However, orthogonal mapping only works on language pairs whose embeddings are naturally isomorphic. For non-isomorphic pairs, our method (Iterative Normalization) transforms monolingual embeddings to make orthogonal alignment easier by simultaneously enforcing that (1) individual word vectors are unit length, and (2) each language's average vector is zero. Iterative Normalization consistently improves word translation accuracy of three CLWE methods, with the largest improvement observed on English-Japanese (from 2% to 44% test accuracy).
What Can Neural Networks Reason About?
May 31, 2019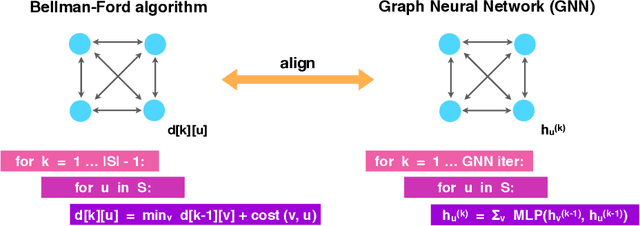
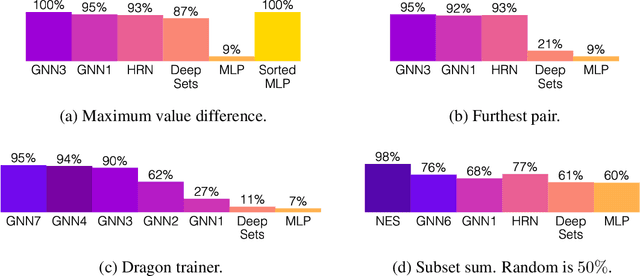
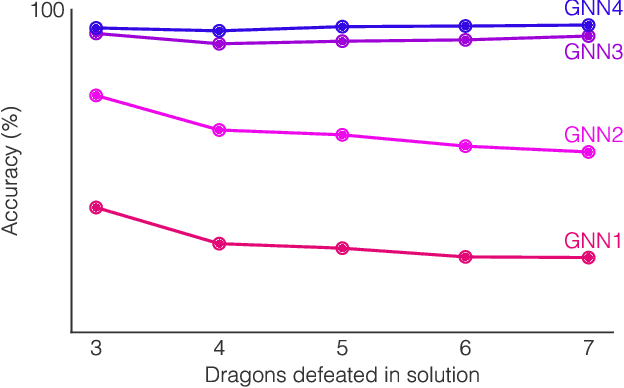
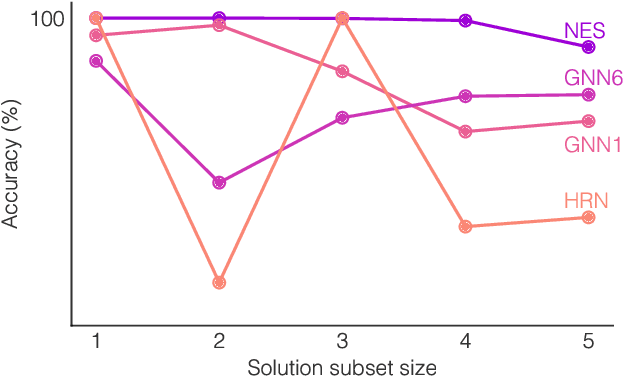
Neural networks have successfully been applied to solving reasoning tasks, ranging from learning simple concepts like "close to", to intricate questions whose reasoning procedures resemble algorithms. Empirically, not all network structures work equally well for reasoning. For example, Graph Neural Networks have achieved impressive empirical results, while less structured neural networks may fail to learn to reason. Theoretically, there is currently limited understanding of the interplay between reasoning tasks and network learning. In this paper, we develop a framework to characterize which tasks a neural network can learn well, by studying how well its structure aligns with the algorithmic structure of the relevant reasoning procedure. This suggests that Graph Neural Networks can learn dynamic programming, a powerful algorithmic strategy that solves a broad class of reasoning problems, such as relational question answering, sorting, intuitive physics, and shortest paths. Our perspective also implies strategies to design neural architectures for complex reasoning. On several abstract reasoning tasks, we see empirically that our theory aligns well with practice.
Exploiting Cross-Lingual Subword Similarities in Low-Resource Document Classification
Dec 22, 2018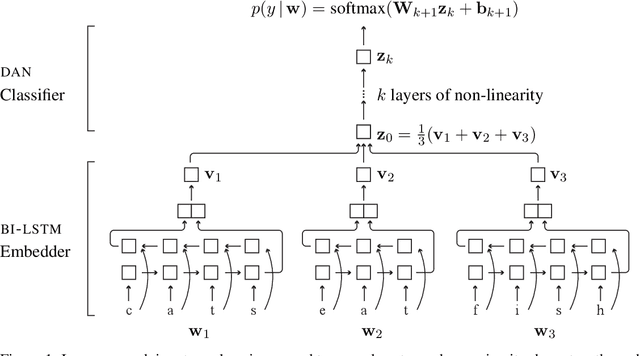
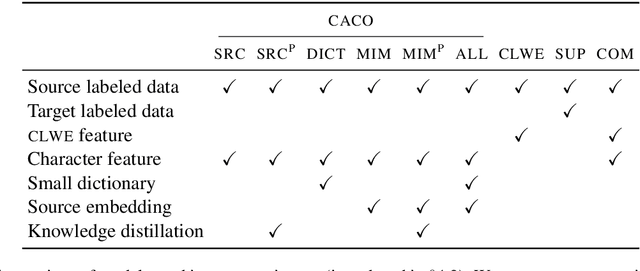
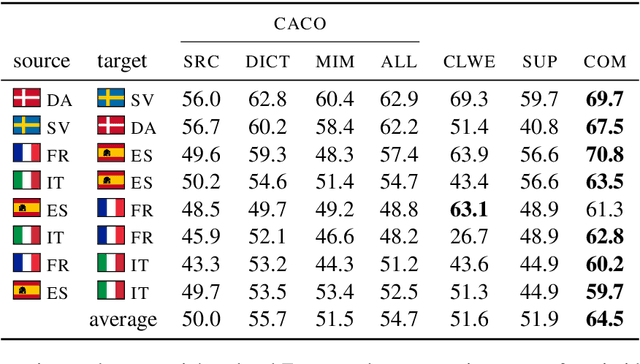
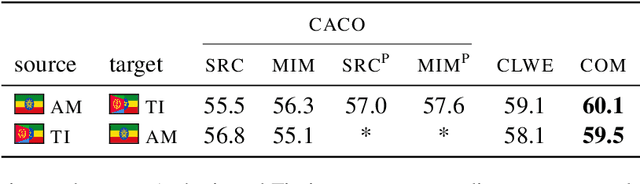
Text classification must sometimes be applied in situations with no training data in a target language. However, training data may be available in a related language. We introduce a cross-lingual document classification framework (CACO) between related language pairs. To best use limited training data, our transfer learning scheme exploits cross-lingual subword similarity by jointly training a character-based embedder and a word-based classifier. The embedder derives vector representations for input words from their written forms, and the classifier makes predictions based on the word vectors. We use a joint character representation for both the source language and the target language, which allows the embedder to generalize knowledge about source language words to target language words with similar forms. We propose a multi-task objective that can further improve the model if additional cross-lingual or monolingual resources are available. CACO models trained under low-resource settings rival cross-lingual word embedding models trained under high-resource settings on related language pairs.