 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifficult Lessons on Social Prediction from Wisconsin Public Schools
Apr 13, 2023



Early warning systems (EWS) are prediction algorithms that have recently taken a central role in efforts to improve graduation rates in public schools across the US. These systems assist in targeting interventions at individual students by predicting which students are at risk of dropping out. Despite significant investments and adoption, there remain significant gaps in our understanding of the efficacy of EWS. In this work, we draw on nearly a decade's worth of data from a system used throughout Wisconsin to provide the first large-scale evaluation of the long-term impact of EWS on graduation outcomes. We present evidence that risk assessments made by the prediction system are highly accurate, including for students from marginalized backgrounds. Despite the system's accuracy and widespread use, we find no evidence that it has led to improved graduation rates. We surface a robust statistical pattern that can explain why these seemingly contradictory insights hold. Namely, environmental features, measured at the level of schools, contain significant signal about dropout risk. Within each school, however, academic outcomes are essentially independent of individual student performance. This empirical observation indicates that assigning all students within the same school the same probability of graduation is a nearly optimal prediction. Our work provides an empirical backbone for the robust, qualitative understanding among education researchers and policy-makers that dropout is structurally determined. The primary barrier to improving outcomes lies not in identifying students at risk of dropping out within specific schools, but rather in overcoming structural differences across different school districts. Our findings indicate that we should carefully evaluate the decision to fund early warning systems without also devoting resources to interventions tackling structural barriers.
Causal Inference out of Control: Estimating the Steerability of Consumption
Feb 10, 2023



Regulators and academics are increasingly interested in the causal effect that algorithmic actions of a digital platform have on consumption. We introduce a general causal inference problem we call the steerability of consumption that abstracts many settings of interest. Focusing on observational designs and exploiting the structure of the problem, we exhibit a set of assumptions for causal identifiability that significantly weaken the often unrealistic overlap assumptions of standard designs. The key novelty of our approach is to explicitly model the dynamics of consumption over time, viewing the platform as a controller acting on a dynamical system. From this dynamical systems perspective, we are able to show that exogenous variation in consumption and appropriately responsive algorithmic control actions are sufficient for identifying steerability of consumption. Our results illustrate the fruitful interplay of control theory and causal inference, which we illustrate with examples from econometrics, macroeconomics, and machine learning.
Algorithmic Collective Action in Machine Learning
Feb 08, 2023



We initiate a principled study of algorithmic collective action on digital platforms that deploy machine learning algorithms. We propose a simple theoretical model of a collective interacting with a firm's learning algorithm. The collective pools the data of participating individuals and executes an algorithmic strategy by instructing participants how to modify their own data to achieve a collective goal. We investigate the consequences of this model in three fundamental learning-theoretic settings: the case of a nonparametric optimal learning algorithm, a parametric risk minimizer, and gradient-based optimization. In each setting, we come up with coordinated algorithmic strategies and characterize natural success criteria as a function of the collective's size. Complementing our theory, we conduct systematic experiments on a skill classification task involving tens of thousands of resumes from a gig platform for freelancers. Through more than two thousand model training runs of a BERT-like language model, we see a striking correspondence emerge between our empirical observations and the predictions made by our theory. Taken together, our theory and experiments broadly support the conclusion that algorithmic collectives of exceedingly small fractional size can exert significant control over a platform's learning algorithm.
A Theory of Dynamic Benchmarks
Oct 06, 2022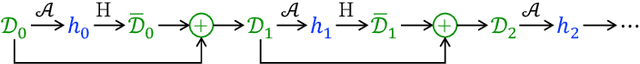
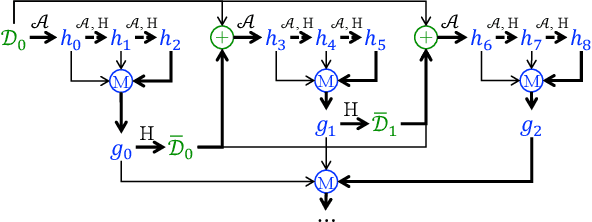
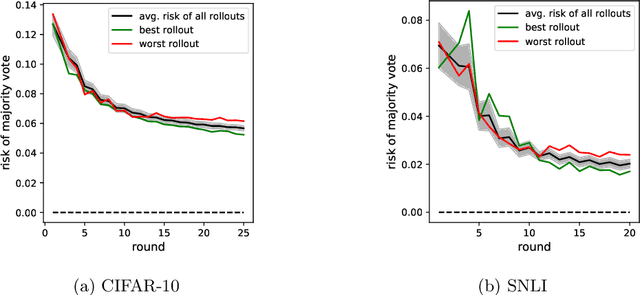
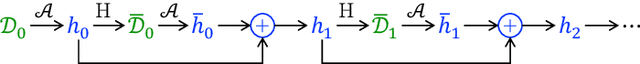
Dynamic benchmarks interweave model fitting and data collection in an attempt to mitigate the limitations of static benchmarks. In contrast to an extensive theoretical and empirical study of the static setting, the dynamic counterpart lags behind due to limited empirical studies and no apparent theoretical foundation to date. Responding to this deficit, we initiate a theoretical study of dynamic benchmarking. We examine two realizations, one capturing current practice and the other modeling more complex settings. In the first model, where data collection and model fitting alternate sequentially, we prove that model performance improves initially but can stall after only three rounds. Label noise arising from, for instance, annotator disagreement leads to even stronger negative results. Our second model generalizes the first to the case where data collection and model fitting have a hierarchical dependency structure. We show that this design guarantees strictly more progress than the first, albeit at a significant increase in complexity. We support our theoretical analysis by simulating dynamic benchmarks on two popular datasets. These results illuminate the benefits and practical limitations of dynamic benchmarking, providing both a theoretical foundation and a causal explanation for observed bottlenecks in empirical work.
Backward baselines: Is your model predicting the past?
Jun 23, 2022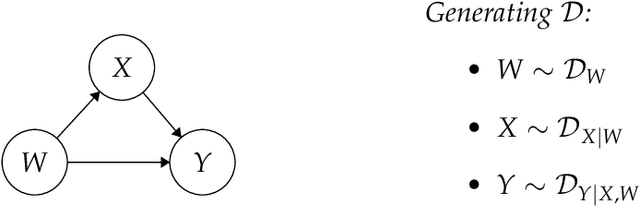
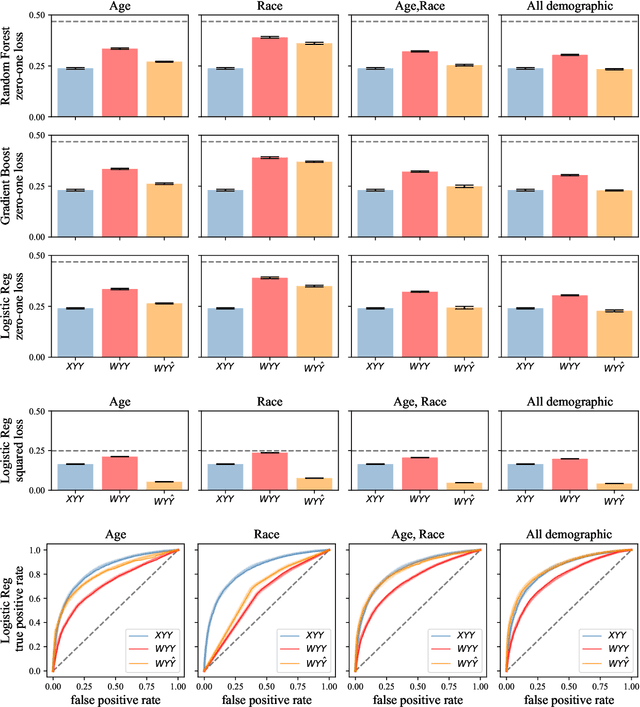
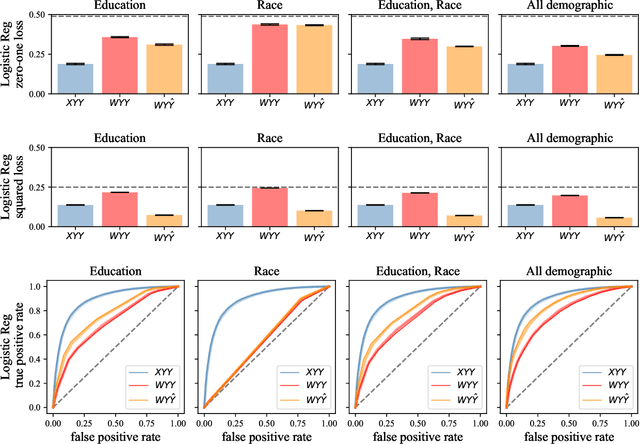
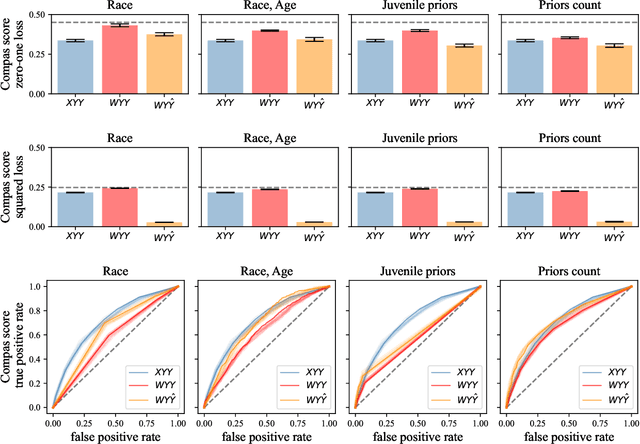
When does a machine learning model predict the future of individuals and when does it recite patterns that predate the individuals? In this work, we propose a distinction between these two pathways of prediction, supported by theoretical, empirical, and normative arguments. At the center of our proposal is a family of simple and efficient statistical tests, called backward baselines, that demonstrate if, and to which extent, a model recounts the past. Our statistical theory provides guidance for interpreting backward baselines, establishing equivalences between different baselines and familiar statistical concepts. Concretely, we derive a meaningful backward baseline for auditing a prediction system as a black box, given only background variables and the system's predictions. Empirically, we evaluate the framework on different prediction tasks derived from longitudinal panel surveys, demonstrating the ease and effectiveness of incorporating backward baselines into the practice of machine learning.
Adversarial Scrutiny of Evidentiary Statistical Software
Jun 19, 2022
The U.S. criminal legal system increasingly relies on software output to convict and incarcerate people. In a large number of cases each year, the government makes these consequential decisions based on evidence from statistical software -- such as probabilistic genotyping, environmental audio detection, and toolmark analysis tools -- that defense counsel cannot fully cross-examine or scrutinize. This undermines the commitments of the adversarial criminal legal system, which relies on the defense's ability to probe and test the prosecution's case to safeguard individual rights. Responding to this need to adversarially scrutinize output from such software, we propose robust adversarial testing as an audit framework to examine the validity of evidentiary statistical software. We define and operationalize this notion of robust adversarial testing for defense use by drawing on a large body of recent work in robust machine learning and algorithmic fairness. We demonstrate how this framework both standardizes the process for scrutinizing such tools and empowers defense lawyers to examine their validity for instances most relevant to the case at hand. We further discuss existing structural and institutional challenges within the U.S. criminal legal system that may create barriers for implementing this and other such audit frameworks and close with a discussion on policy changes that could help address these concerns.
Performative Power
Mar 31, 2022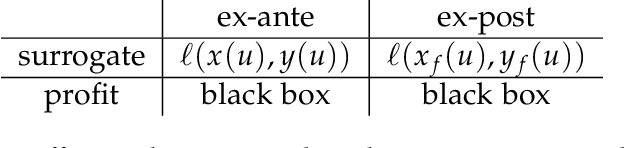
We introduce the notion of performative power, which measures the ability of a firm operating an algorithmic system, such as a digital content recommendation platform, to steer a population. We relate performative power to the economic theory of market power. Traditional economic concepts are well known to struggle with identifying anti-competitive patterns in digital platforms--a core challenge is the difficulty of defining the market, its participants, products, and prices. Performative power sidesteps the problem of market definition by focusing on a directly observable statistical measure instead. High performative power enables a platform to profit from steering participant behavior, whereas low performative power ensures that learning from historical data is close to optimal. Our first general result shows that under low performative power, a firm cannot do better than standard supervised learning on observed data. We draw an analogy with a firm being a price-taker, an economic condition that arises under perfect competition in classical market models. We then contrast this with a market where performative power is concentrated and show that the equilibrium state can differ significantly. We go on to study performative power in a concrete setting of strategic classification where participants can switch between competing firms. We show that monopolies maximize performative power and disutility for the participant, while competition and outside options decrease performative power. We end on a discussion of connections to measures of market power in economics and of the relationship with ongoing antitrust debates.
Retiring Adult: New Datasets for Fair Machine Learning
Aug 10, 2021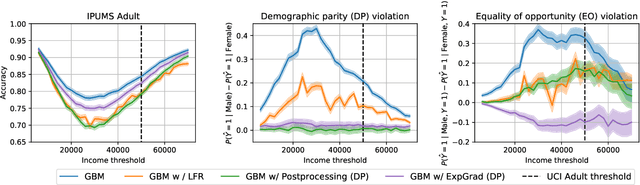
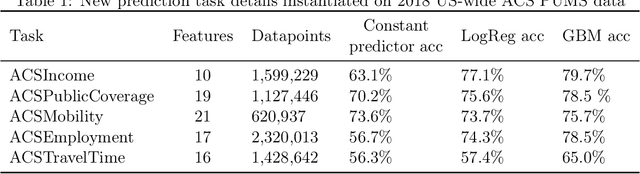
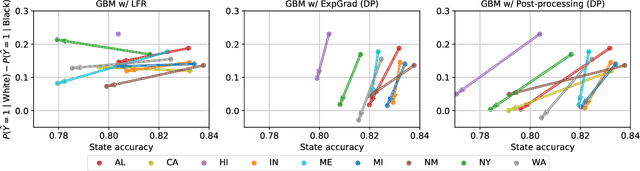

Although the fairness community has recognized the importance of data, researchers in the area primarily rely on UCI Adult when it comes to tabular data. Derived from a 1994 US Census survey, this dataset has appeared in hundreds of research papers where it served as the basis for the development and comparison of many algorithmic fairness interventions. We reconstruct a superset of the UCI Adult data from available US Census sources and reveal idiosyncrasies of the UCI Adult dataset that limit its external validity. Our primary contribution is a suite of new datasets derived from US Census surveys that extend the existing data ecosystem for research on fair machine learning. We create prediction tasks relating to income, employment, health, transportation, and housing. The data span multiple years and all states of the United States, allowing researchers to study temporal shift and geographic variation. We highlight a broad initial sweep of new empirical insights relating to trade-offs between fairness criteria, performance of algorithmic interventions, and the role of distribution shift based on our new datasets. Our findings inform ongoing debates, challenge some existing narratives, and point to future research directions. Our datasets are available at https://github.com/zykls/folktables.
Causal Inference Struggles with Agency on Online Platforms
Jul 19, 2021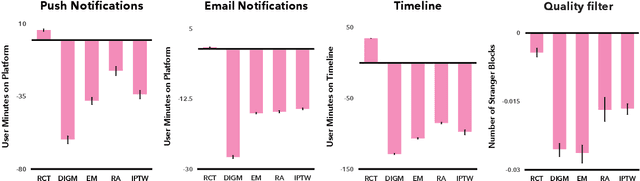

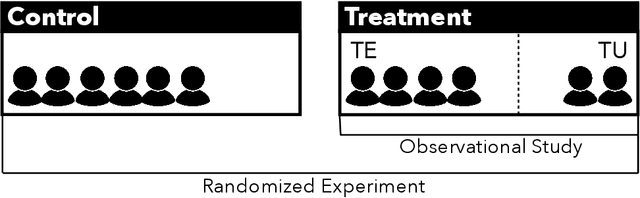
Online platforms regularly conduct randomized experiments to understand how changes to the platform causally affect various outcomes of interest. However, experimentation on online platforms has been criticized for having, among other issues, a lack of meaningful oversight and user consent. As platforms give users greater agency, it becomes possible to conduct observational studies in which users self-select into the treatment of interest as an alternative to experiments in which the platform controls whether the user receives treatment or not. In this paper, we conduct four large-scale within-study comparisons on Twitter aimed at assessing the effectiveness of observational studies derived from user self-selection on online platforms. In a within-study comparison, treatment effects from an observational study are assessed based on how effectively they replicate results from a randomized experiment with the same target population. We test the naive difference in group means estimator, exact matching, regression adjustment, and inverse probability of treatment weighting while controlling for plausible confounding variables. In all cases, all observational estimates perform poorly at recovering the ground-truth estimate from the analogous randomized experiments. In all cases except one, the observational estimates have the opposite sign of the randomized estimate. Our results suggest that observational studies derived from user self-selection are a poor alternative to randomized experimentation on online platforms. In discussing our results, we postulate "Catch-22"s that suggest that the success of causal inference in these settings may be at odds with the original motivations for providing users with greater agency.
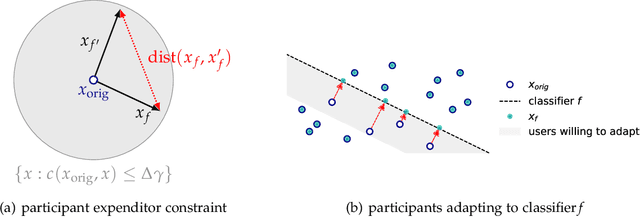
Alternative Microfoundations for Strategic Classification
Jun 24, 2021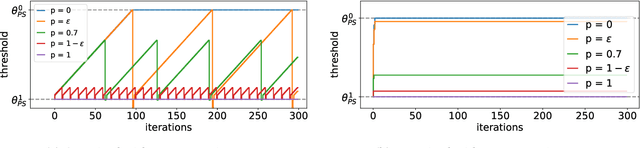
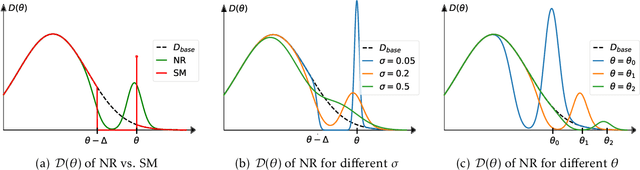
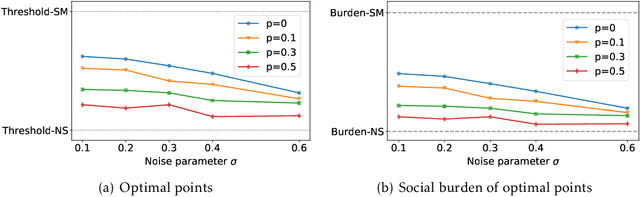
When reasoning about strategic behavior in a machine learning context it is tempting to combine standard microfoundations of rational agents with the statistical decision theory underlying classification. In this work, we argue that a direct combination of these standard ingredients leads to brittle solution concepts of limited descriptive and prescriptive value. First, we show that rational agents with perfect information produce discontinuities in the aggregate response to a decision rule that we often do not observe empirically. Second, when any positive fraction of agents is not perfectly strategic, desirable stable points -- where the classifier is optimal for the data it entails -- cease to exist. Third, optimal decision rules under standard microfoundations maximize a measure of negative externality known as social burden within a broad class of possible assumptions about agent behavior. Recognizing these limitations we explore alternatives to standard microfoundations for binary classification. We start by describing a set of desiderata that help navigate the space of possible assumptions about how agents respond to a decision rule. In particular, we analyze a natural constraint on feature manipulations, and discuss properties that are sufficient to guarantee the robust existence of stable points. Building on these insights, we then propose the noisy response model. Inspired by smoothed analysis and empirical observations, noisy response incorporates imperfection in the agent responses, which we show mitigates the limitations of standard microfoundations. Our model retains analytical tractability, leads to more robust insights about stable points, and imposes a lower social burden at optimality.