 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEventNeRF: Neural Radiance Fields from a Single Colour Event Camera
Jun 23, 2022
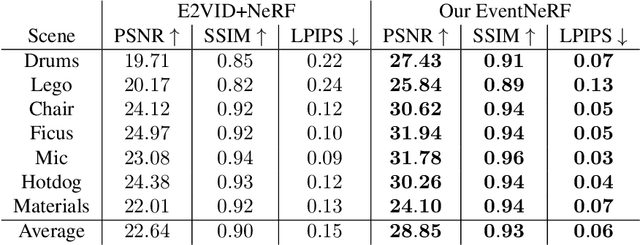

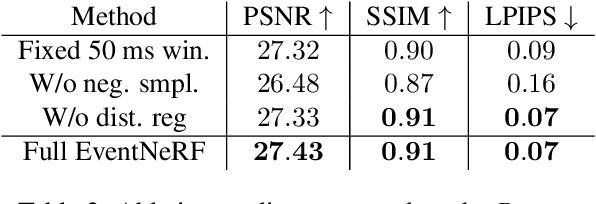
Learning coordinate-based volumetric 3D scene representations such as neural radiance fields (NeRF) has been so far studied assuming RGB or RGB-D images as inputs. At the same time, it is known from the neuroscience literature that human visual system (HVS) is tailored to process asynchronous brightness changes rather than synchronous RGB images, in order to build and continuously update mental 3D representations of the surroundings for navigation and survival. Visual sensors that were inspired by HVS principles are event cameras. Thus, events are sparse and asynchronous per-pixel brightness (or colour channel) change signals. In contrast to existing works on neural 3D scene representation learning, this paper approaches the problem from a new perspective. We demonstrate that it is possible to learn NeRF suitable for novel-view synthesis in the RGB space from asynchronous event streams. Our models achieve high visual accuracy of the rendered novel views of challenging scenes in the RGB space, even though they are trained with substantially fewer data (i.e., event streams from a single event camera moving around the object) and more efficiently (due to the inherent sparsity of event streams) than the existing NeRF models trained with RGB images. We will release our datasets and the source code, see https://4dqv.mpi-inf.mpg.de/EventNeRF/.
φ-SfT: Shape-from-Template with a Physics-Based Deformation Model
Mar 22, 2022
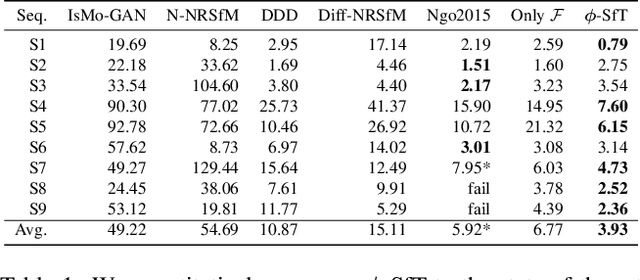
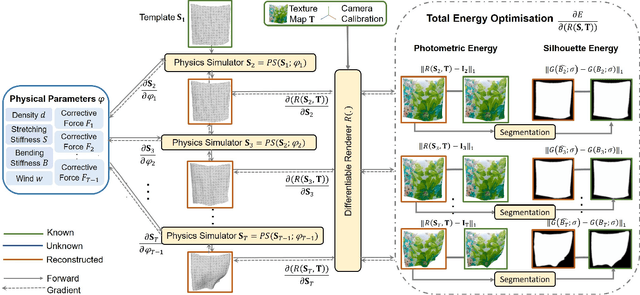
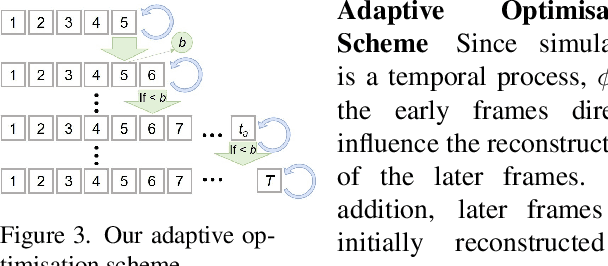
Shape-from-Template (SfT) methods estimate 3D surface deformations from a single monocular RGB camera while assuming a 3D state known in advance (a template). This is an important yet challenging problem due to the under-constrained nature of the monocular setting. Existing SfT techniques predominantly use geometric and simplified deformation models, which often limits their reconstruction abilities. In contrast to previous works, this paper proposes a new SfT approach explaining 2D observations through physical simulations accounting for forces and material properties. Our differentiable physics simulator regularises the surface evolution and optimises the material elastic properties such as bending coefficients, stretching stiffness and density. We use a differentiable renderer to minimise the dense reprojection error between the estimated 3D states and the input images and recover the deformation parameters using an adaptive gradient-based optimisation. For the evaluation, we record with an RGB-D camera challenging real surfaces exposed to physical forces with various material properties and textures. Our approach significantly reduces the 3D reconstruction error compared to multiple competing methods. For the source code and data, see https://4dqv.mpi-inf.mpg.de/phi-SfT/.
Neural Radiance Fields for Outdoor Scene Relighting
Dec 09, 2021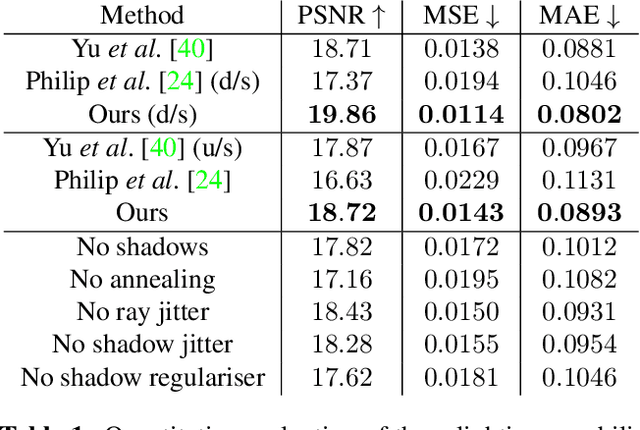
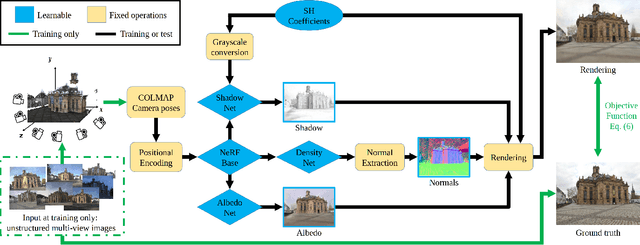
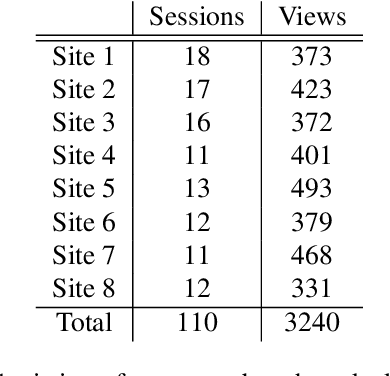

Photorealistic editing of outdoor scenes from photographs requires a profound understanding of the image formation process and an accurate estimation of the scene geometry, reflectance and illumination. A delicate manipulation of the lighting can then be performed while keeping the scene albedo and geometry unaltered. We present NeRF-OSR, i.e., the first approach for outdoor scene relighting based on neural radiance fields. In contrast to the prior art, our technique allows simultaneous editing of both scene illumination and camera viewpoint using only a collection of outdoor photos shot in uncontrolled settings. Moreover, it enables direct control over the scene illumination, as defined through a spherical harmonics model. It also includes a dedicated network for shadow reproduction, which is crucial for high-quality outdoor scene relighting. To evaluate the proposed method, we collect a new benchmark dataset of several outdoor sites, where each site is photographed from multiple viewpoints and at different timings. For each timing, a 360 degrees environment map is captured together with a colour-calibration chequerboard to allow accurate numerical evaluations on real data against ground truth. Comparisons against state of the art show that NeRF-OSR enables controllable lighting and viewpoint editing at higher quality and with realistic self-shadowing reproduction. Our method and the dataset will be made publicly available at https://4dqv.mpi-inf.mpg.de/NeRF-OSR/.
StyleVideoGAN: A Temporal Generative Model using a Pretrained StyleGAN
Jul 15, 2021

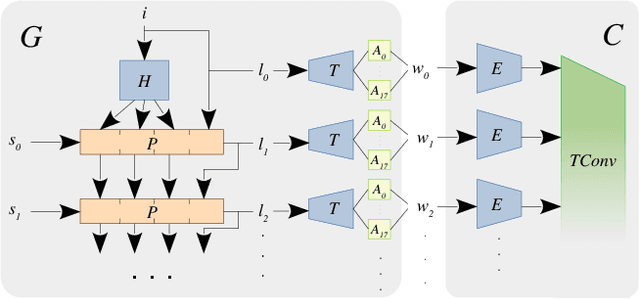
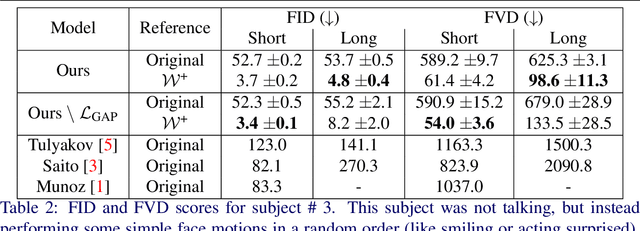
Generative adversarial models (GANs) continue to produce advances in terms of the visual quality of still images, as well as the learning of temporal correlations. However, few works manage to combine these two interesting capabilities for the synthesis of video content: Most methods require an extensive training dataset in order to learn temporal correlations, while being rather limited in the resolution and visual quality of their output frames. In this paper, we present a novel approach to the video synthesis problem that helps to greatly improve visual quality and drastically reduce the amount of training data and resources necessary for generating video content. Our formulation separates the spatial domain, in which individual frames are synthesized, from the temporal domain, in which motion is generated. For the spatial domain we make use of a pre-trained StyleGAN network, the latent space of which allows control over the appearance of the objects it was trained for. The expressive power of this model allows us to embed our training videos in the StyleGAN latent space. Our temporal architecture is then trained not on sequences of RGB frames, but on sequences of StyleGAN latent codes. The advantageous properties of the StyleGAN space simplify the discovery of temporal correlations. We demonstrate that it suffices to train our temporal architecture on only 10 minutes of footage of 1 subject for about 6 hours. After training, our model can not only generate new portrait videos for the training subject, but also for any random subject which can be embedded in the StyleGAN space.
Egocentric Videoconferencing
Jul 07, 2021

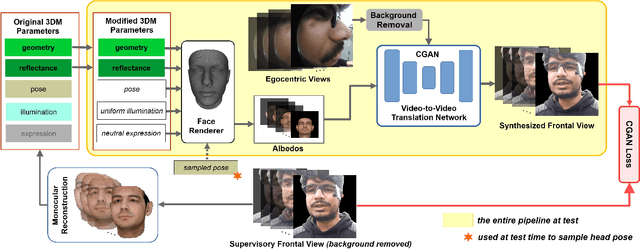

We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
* Mohamed Elgharib and Mohit Mendiratta contributed equally to this work. http://gvv.mpi-inf.mpg.de/projects/EgoChat/
Self-supervised Outdoor Scene Relighting
Jul 07, 2021
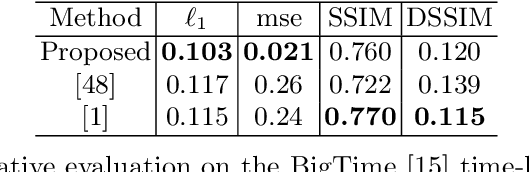
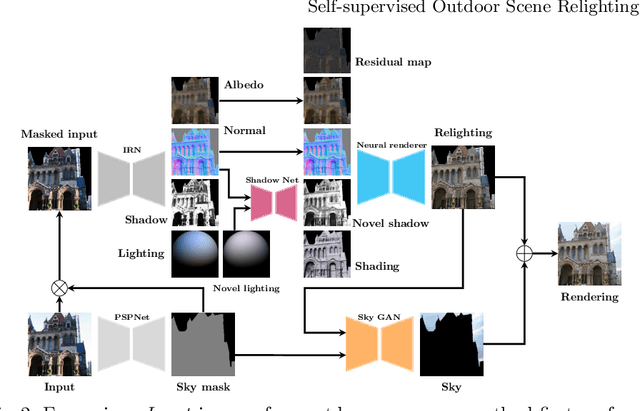
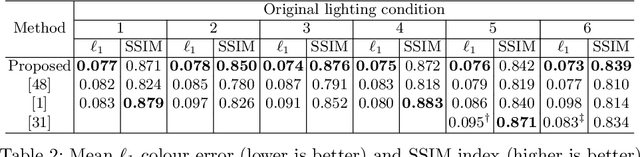
Outdoor scene relighting is a challenging problem that requires good understanding of the scene geometry, illumination and albedo. Current techniques are completely supervised, requiring high quality synthetic renderings to train a solution. Such renderings are synthesized using priors learned from limited data. In contrast, we propose a self-supervised approach for relighting. Our approach is trained only on corpora of images collected from the internet without any user-supervision. This virtually endless source of training data allows training a general relighting solution. Our approach first decomposes an image into its albedo, geometry and illumination. A novel relighting is then produced by modifying the illumination parameters. Our solution capture shadow using a dedicated shadow prediction map, and does not rely on accurate geometry estimation. We evaluate our technique subjectively and objectively using a new dataset with ground-truth relighting. Results show the ability of our technique to produce photo-realistic and physically plausible results, that generalizes to unseen scenes.
Differentiable Event Stream Simulator for Non-Rigid 3D Tracking
Apr 30, 2021
This paper introduces the first differentiable simulator of event streams, i.e., streams of asynchronous brightness change signals recorded by event cameras. Our differentiable simulator enables non-rigid 3D tracking of deformable objects (such as human hands, isometric surfaces and general watertight meshes) from event streams by leveraging an analysis-by-synthesis principle. So far, event-based tracking and reconstruction of non-rigid objects in 3D, like hands and body, has been either tackled using explicit event trajectories or large-scale datasets. In contrast, our method does not require any such processing or data, and can be readily applied to incoming event streams. We show the effectiveness of our approach for various types of non-rigid objects and compare to existing methods for non-rigid 3D tracking. In our experiments, the proposed energy-based formulations outperform competing RGB-based methods in terms of 3D errors. The source code and the new data are publicly available.
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021
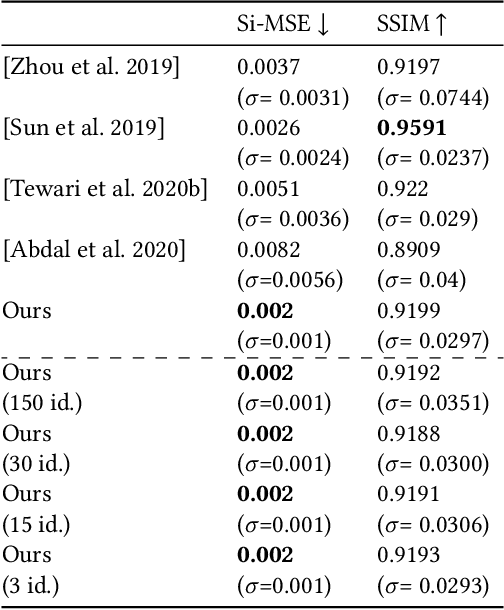
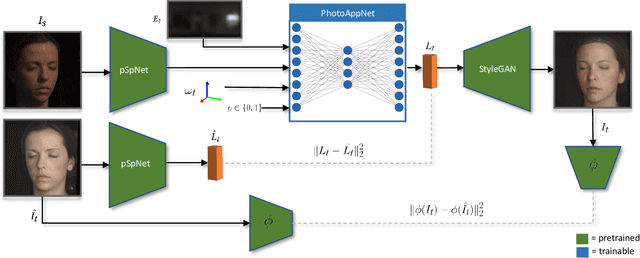
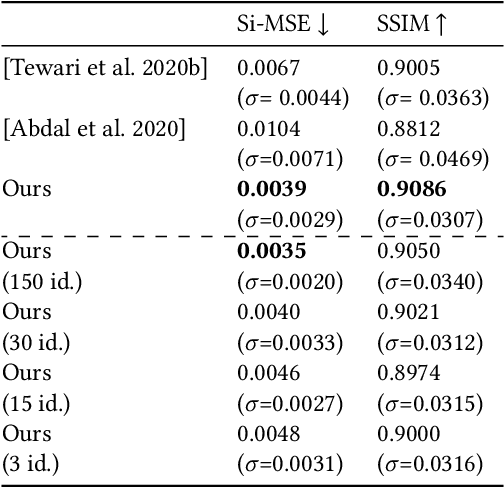
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
Learning Speech-driven 3D Conversational Gestures from Video
Feb 13, 2021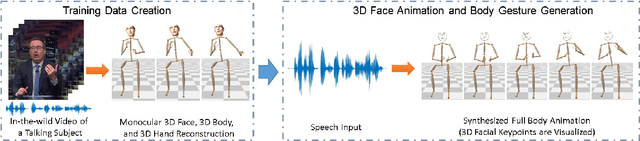
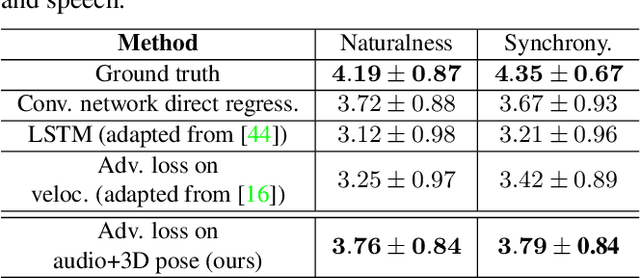
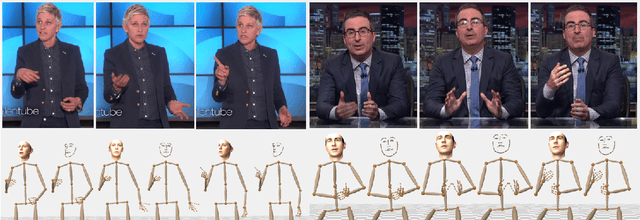
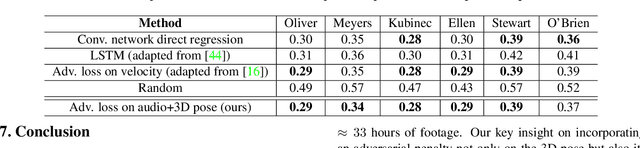
We propose the first approach to automatically and jointly synthesize both the synchronous 3D conversational body and hand gestures, as well as 3D face and head animations, of a virtual character from speech input. Our algorithm uses a CNN architecture that leverages the inherent correlation between facial expression and hand gestures. Synthesis of conversational body gestures is a multi-modal problem since many similar gestures can plausibly accompany the same input speech. To synthesize plausible body gestures in this setting, we train a Generative Adversarial Network (GAN) based model that measures the plausibility of the generated sequences of 3D body motion when paired with the input audio features. We also contribute a new way to create a large corpus of more than 33 hours of annotated body, hand, and face data from in-the-wild videos of talking people. To this end, we apply state-of-the-art monocular approaches for 3D body and hand pose estimation as well as dense 3D face performance capture to the video corpus. In this way, we can train on orders of magnitude more data than previous algorithms that resort to complex in-studio motion capture solutions, and thereby train more expressive synthesis algorithms. Our experiments and user study show the state-of-the-art quality of our speech-synthesized full 3D character animations.
High-Fidelity Neural Human Motion Transfer from Monocular Video
Dec 20, 2020
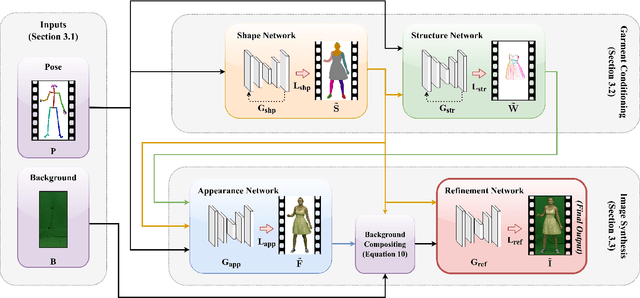


Video-based human motion transfer creates video animations of humans following a source motion. Current methods show remarkable results for tightly-clad subjects. However, the lack of temporally consistent handling of plausible clothing dynamics, including fine and high-frequency details, significantly limits the attainable visual quality. We address these limitations for the first time in the literature and present a new framework which performs high-fidelity and temporally-consistent human motion transfer with natural pose-dependent non-rigid deformations, for several types of loose garments. In contrast to the previous techniques, we perform image generation in three subsequent stages, synthesizing human shape, structure, and appearance. Given a monocular RGB video of an actor, we train a stack of recurrent deep neural networks that generate these intermediate representations from 2D poses and their temporal derivatives. Splitting the difficult motion transfer problem into subtasks that are aware of the temporal motion context helps us to synthesize results with plausible dynamics and pose-dependent detail. It also allows artistic control of results by manipulation of individual framework stages. In the experimental results, we significantly outperform the state-of-the-art in terms of video realism. Our code and data will be made publicly available.