 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Efficient Neural Estimation of Structural Equation Model: An Adversarial Approach
Jul 02, 2020
Structural equation models (SEMs) are widely used in sciences, ranging from economics to psychology, to uncover causal relationships underlying a complex system under consideration and estimate structural parameters of interest. We study estimation in a class of generalized SEMs where the object of interest is defined as the solution to a linear operator equation. We formulate the linear operator equation as a min-max game, where both players are parameterized by neural networks (NNs), and learn the parameters of these neural networks using the stochastic gradient descent. We consider both 2-layer and multi-layer NNs with ReLU activation functions and prove global convergence in an overparametrized regime, where the number of neurons is diverging. The results are established using techniques from online learning and local linearization of NNs, and improve in several aspects the current state-of-the-art. For the first time we provide a tractable estimation procedure for SEMs based on NNs with provable convergence and without the need for sample splitting.
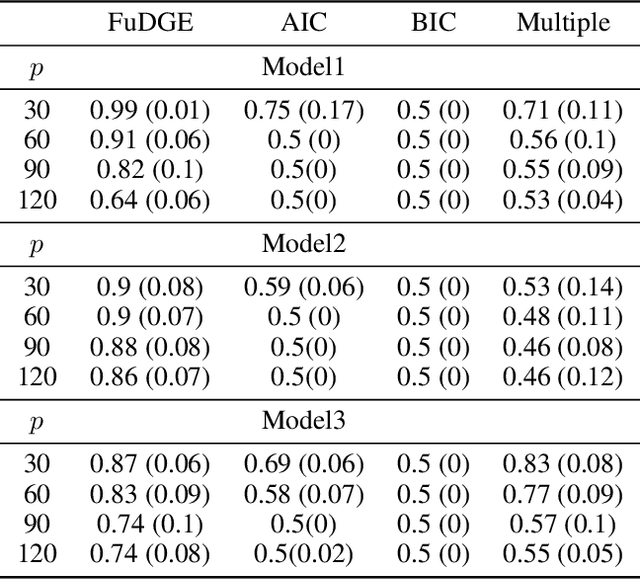
FuDGE: Functional Differential Graph Estimation with fully and discretely observed curves
Mar 11, 2020
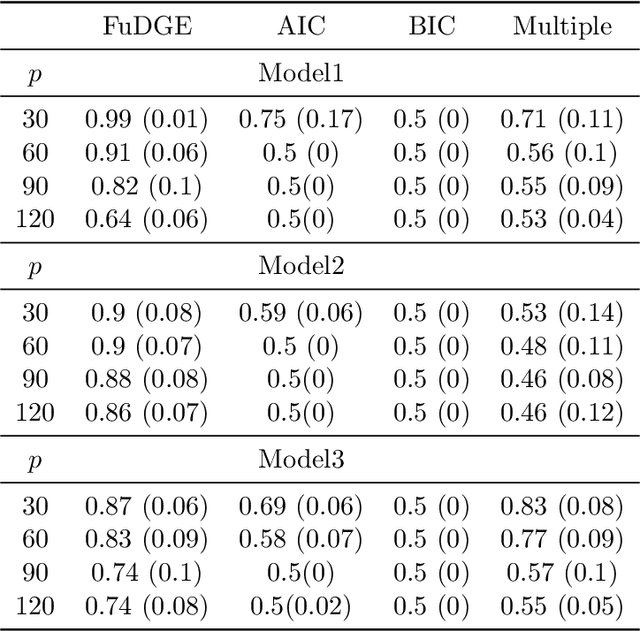
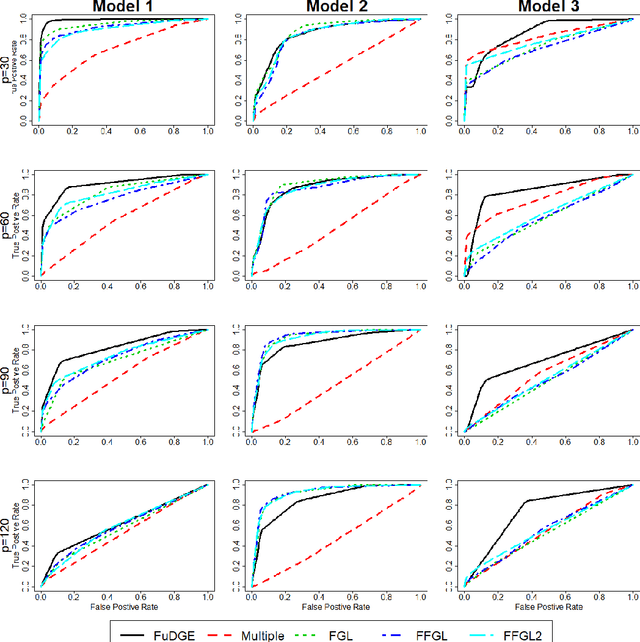
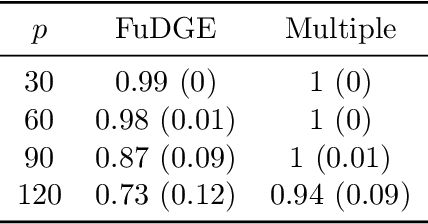
We consider the problem of estimating the difference between two functional undirected graphical models with shared structures. In many applications, data are naturally regarded as high-dimensional random function vectors rather than multivariate scalars. For example, electroencephalography (EEG) data are more appropriately treated as functions of time. In these problems, not only can the number of functions measured per sample be large, but each function is itself an infinite dimensional object, making estimation of model parameters challenging. In practice, curves are usually discretely observed, which makes graph structure recovery even more challenging. We formally characterize when two functional graphical models are comparable and propose a method that directly estimates the functional differential graph, which we term FuDGE. FuDGE avoids separate estimation of each graph, which allows for estimation in problems where individual graphs are dense, but their difference is sparse. We show that FuDGE consistently estimates the functional differential graph in a high-dimensional setting for both discretely observed and fully observed function paths. We illustrate finite sample properties of our method through simulation studies. In order to demonstrate the benefits of our method, we propose Joint Functional Graphical Lasso as a competitor, which is a generalization of the Joint Graphical Lasso. Finally, we apply our method to EEG data to uncover differences in functional brain connectivity between alcoholics and control subjects.
Semiparametric Nonlinear Bipartite Graph Representation Learning with Provable Guarantees
Mar 02, 2020

Graph representation learning is a ubiquitous task in machine learning where the goal is to embed each vertex into a low-dimensional vector space. We consider the bipartite graph and formalize its representation learning problem as a statistical estimation problem of parameters in a semiparametric exponential family distribution. The bipartite graph is assumed to be generated by a semiparametric exponential family distribution, whose parametric component is given by the proximity of outputs of two one-layer neural networks, while nonparametric (nuisance) component is the base measure. Neural networks take high-dimensional features as inputs and output embedding vectors. In this setting, the representation learning problem is equivalent to recovering the weight matrices. The main challenges of estimation arise from the nonlinearity of activation functions and the nonparametric nuisance component of the distribution. To overcome these challenges, we propose a pseudo-likelihood objective based on the rank-order decomposition technique and focus on its local geometry. We show that the proposed objective is strongly convex in a neighborhood around the ground truth, so that a gradient descent-based method achieves linear convergence rate. Moreover, we prove that the sample complexity of the problem is linear in dimensions (up to logarithmic factors), which is consistent with parametric Gaussian models. However, our estimator is robust to any model misspecification within the exponential family, which is validated in extensive experiments.
Posterior Ratio Estimation for Latent Variables
Feb 15, 2020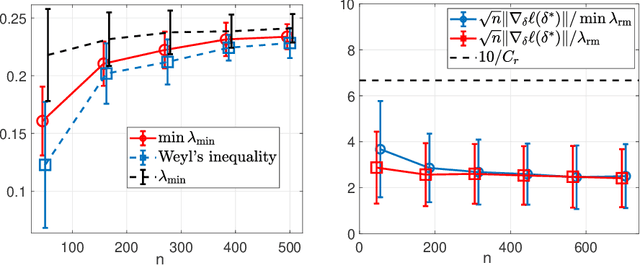
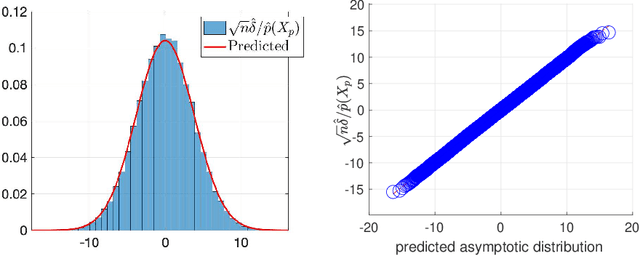
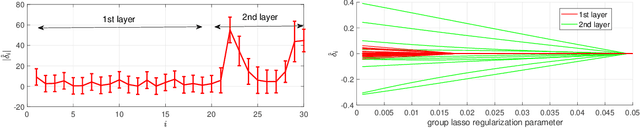
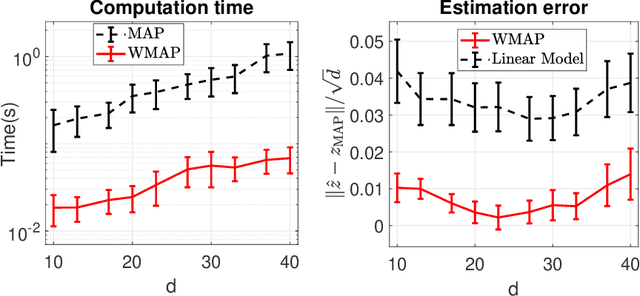
Density Ratio Estimation has attracted attention from machine learning community due to its ability of comparing the underlying distributions of two datasets. However, in some applications, we want to compare distributions of \emph{latent} random variables that can be only inferred from observations. In this paper, we study the problem of estimating the ratio between two posterior probability density functions of a latent variable. Particularly, we assume the posterior ratio function can be well-approximated by a parametric model, which is then estimated using observed datasets and synthetic prior samples. We prove consistency of our estimator and the asymptotic normality of the estimated parameters as the number of prior samples tending to infinity. Finally, we validate our theories using numerical experiments and demonstrate the usefulness of the proposed method through some real-world applications.
Natural Actor-Critic Converges Globally for Hierarchical Linear Quadratic Regulator
Dec 14, 2019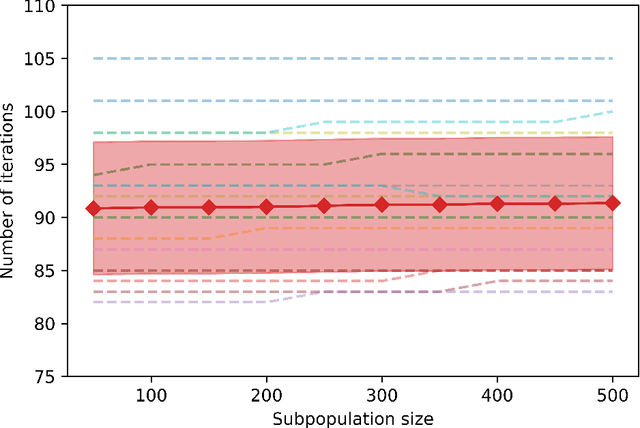

Multi-agent reinforcement learning has been successfully applied to a number of challenging problems. Despite these empirical successes, theoretical understanding of different algorithms is lacking, primarily due to the curse of dimensionality caused by the exponential growth of the state-action space with the number of agents. We study a fundamental problem of multi-agent linear quadratic regulator in a setting where the agents are partially exchangeable. In this setting, we develop a hierarchical actor-critic algorithm, whose computational complexity is independent of the total number of agents, and prove its global linear convergence to the optimal policy. As linear quadratic regulators are often used to approximate general dynamic systems, this paper provided an important step towards better understanding of general hierarchical mean-field multi-agent reinforcement learning.
Direct Estimation of Differential Functional Graphical Models
Nov 16, 2019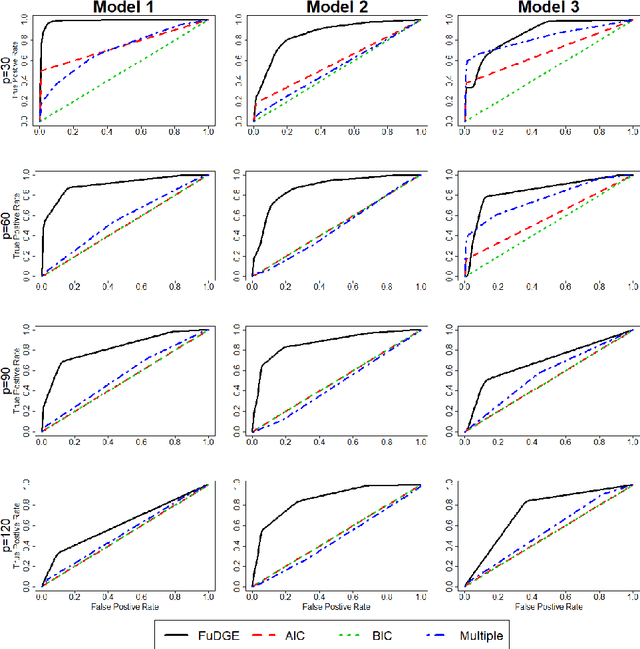
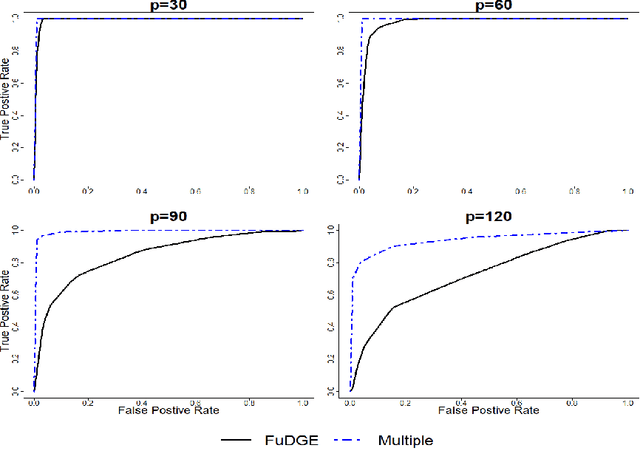
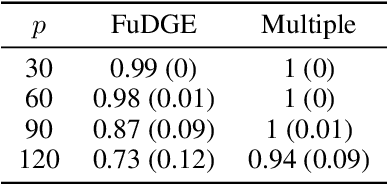
We consider the problem of estimating the difference between two functional undirected graphical models with shared structures. In many applications, data are naturally regarded as high-dimensional random function vectors rather than multivariate scalars. For example, electroencephalography (EEG) data are more appropriately treated as functions of time. In these problems, not only can the number of functions measured per sample be large, but each function is itself an infinite dimensional object, making estimation of model parameters challenging. We develop a method that directly estimates the difference of graphs, avoiding separate estimation of each graph, and show it is consistent in certain high-dimensional settings. We illustrate finite sample properties of our method through simulation studies. Finally, we apply our method to EEG data to uncover differences in functional brain connectivity between alcoholics and control subjects.
Convergent Policy Optimization for Safe Reinforcement Learning
Oct 26, 2019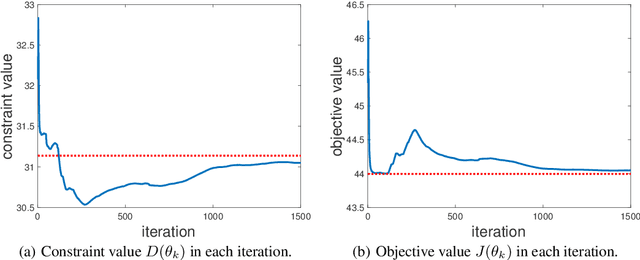

We study the safe reinforcement learning problem with nonlinear function approximation, where policy optimization is formulated as a constrained optimization problem with both the objective and the constraint being nonconvex functions. For such a problem, we construct a sequence of surrogate convex constrained optimization problems by replacing the nonconvex functions locally with convex quadratic functions obtained from policy gradient estimators. We prove that the solutions to these surrogate problems converge to a stationary point of the original nonconvex problem. Furthermore, to extend our theoretical results, we apply our algorithm to examples of optimal control and multi-agent reinforcement learning with safety constraints.
Tensor Canonical Correlation Analysis
Jul 03, 2019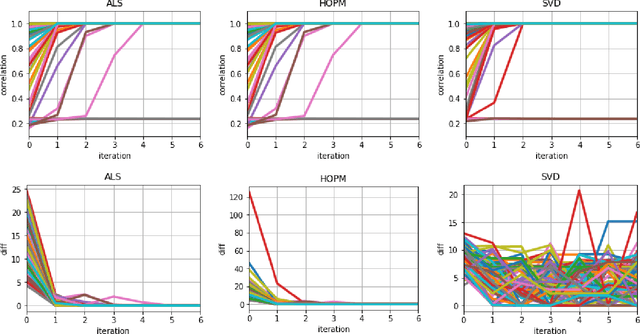

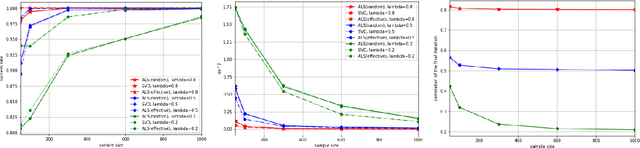
In many applications, such as classification of images or videos, it is of interest to develop a framework for tensor data instead of ad-hoc way of transforming data to vectors due to the computational and under-sampling issues. In this paper, we study canonical correlation analysis by extending the framework of two dimensional analysis (Lee and Choi, 2007) to tensor-valued data. Instead of adopting the iterative algorithm provided in Lee and Choi (2007), we propose an efficient algorithm, called the higher-order power method, which is commonly used in tensor decomposition and more efficient for large-scale setting. Moreover, we carefully examine theoretical properties of our algorithm and establish a local convergence property via the theory of Lojasiewicz's inequalities. Our results fill a missing, but crucial, part in the literature on tensor data. For practical applications, we further develop (a) an inexact updating scheme which allows us to use the state-of-the-art stochastic gradient descent algorithm, (b) an effective initialization scheme which alleviates the problem of local optimum in non-convex optimization, and (c) an extension for extracting several canonical components. Empirical analyses on challenging data including gene expression, air pollution indexes in Taiwan, and electricity demand in Australia, show the effectiveness and efficiency of the proposed methodology.
Partially Linear Additive Gaussian Graphical Models
Jun 08, 2019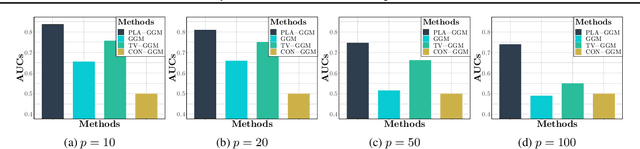
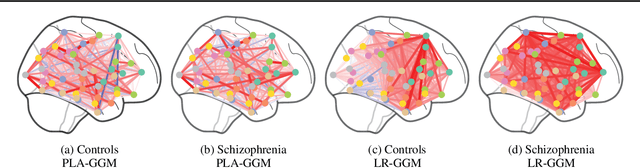
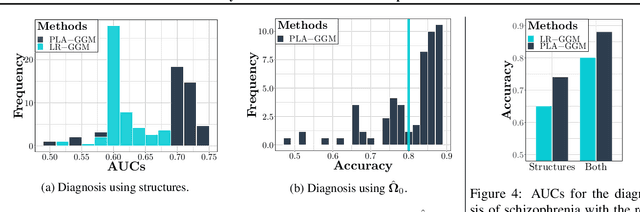
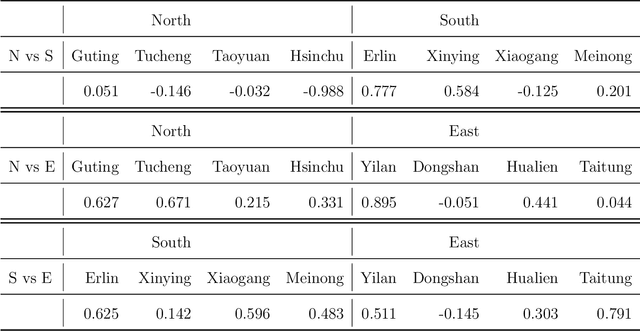
We propose a partially linear additive Gaussian graphical model (PLA-GGM) for the estimation of associations between random variables distorted by observed confounders. Model parameters are estimated using an $L_1$-regularized maximal pseudo-profile likelihood estimator (MaPPLE) for which we prove $\sqrt{n}$-sparsistency. Importantly, our approach avoids parametric constraints on the effects of confounders on the estimated graphical model structure. Empirically, the PLA-GGM is applied to both synthetic and real-world datasets, demonstrating superior performance compared to competing methods.
High-dimensional Index Volatility Models via Stein's Identity
Nov 27, 2018
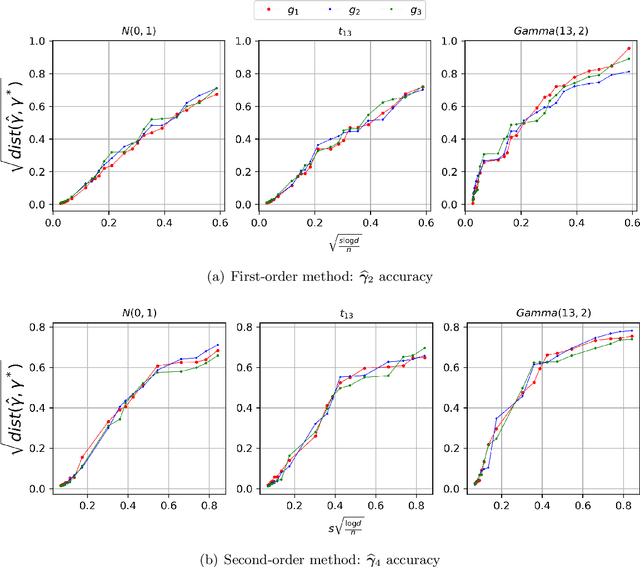
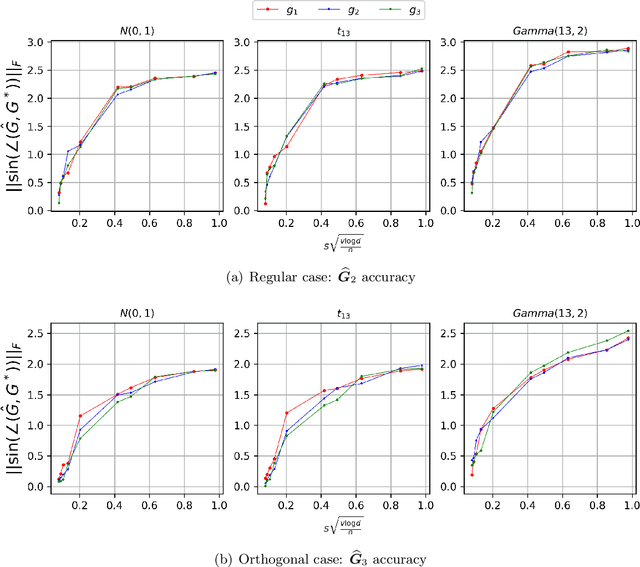
In this paper, we consider estimating the parametric components of index volatility models, whose variance function has semiparametric form with two common index structures: single index and multiple index. Our approach applies the first- and second-order Stein's identities on the empirical mean squared error (MSE) to extract the direction of true signals. We study both low-dimensional setting and high-dimensional setting under finite moment condition, which is weaker than existing literature and makes our estimators applicable even for some heavy-tailed data. From our theoretical analysis, we prove that the statistical rate of convergence has two components: parametric rate and nonparametric rate. For the parametric rate, we achieve $\sqrt{n}$-consistency for low-dimensional setting and optimal/sub-optimal rate for high-dimensional setting. For the nonparametric rate, we show it's asymptotically bounded by $n^{-4/5}$ under both settings when the mean function has bounded second derivative, so it only contributes high-order terms. Simulation results also back our theoretical conclusions.