 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Equivariant Learning for Oriented Keypoint Detection
Apr 19, 2022
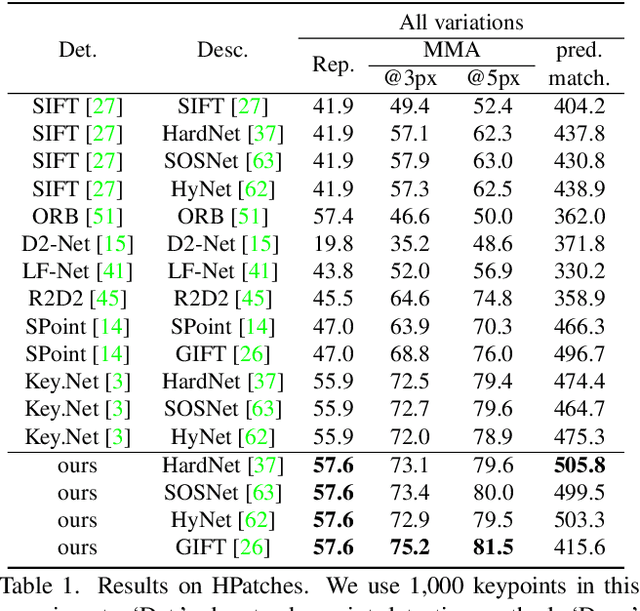
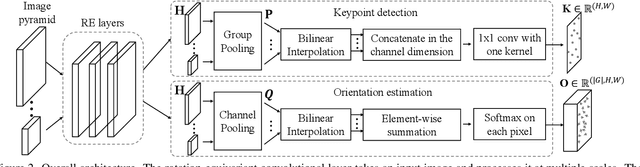
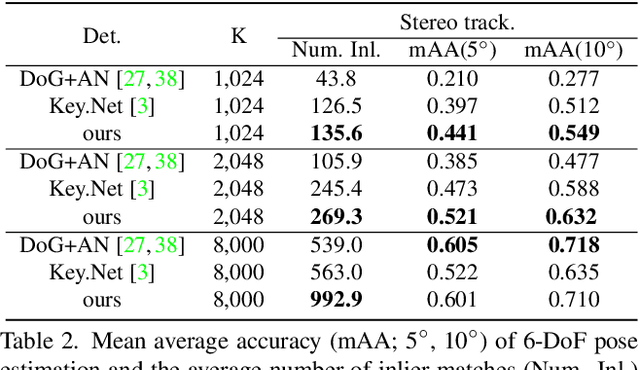
Detecting robust keypoints from an image is an integral part of many computer vision problems, and the characteristic orientation and scale of keypoints play an important role for keypoint description and matching. Existing learning-based methods for keypoint detection rely on standard translation-equivariant CNNs but often fail to detect reliable keypoints against geometric variations. To learn to detect robust oriented keypoints, we introduce a self-supervised learning framework using rotation-equivariant CNNs. We propose a dense orientation alignment loss by an image pair generated by synthetic transformations for training a histogram-based orientation map. Our method outperforms the previous methods on an image matching benchmark and a camera pose estimation benchmark.
Detector-Free Weakly Supervised Group Activity Recognition
Apr 05, 2022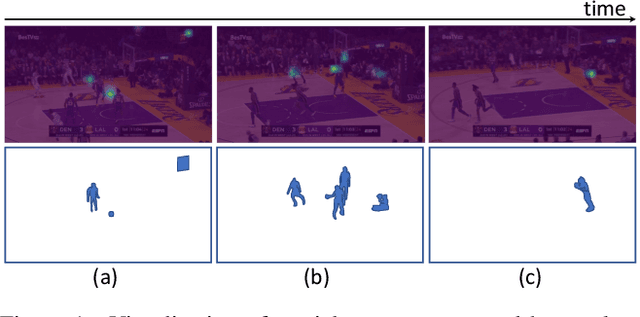
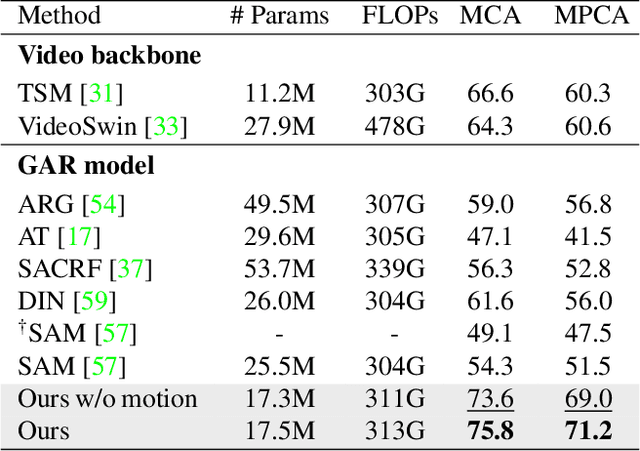
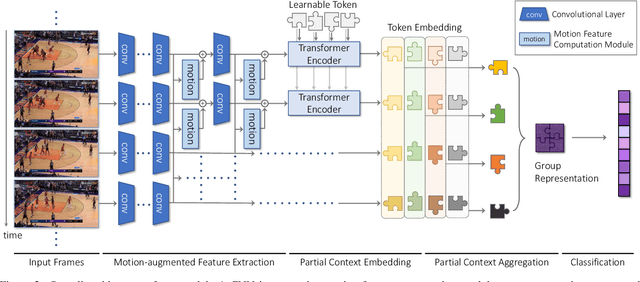
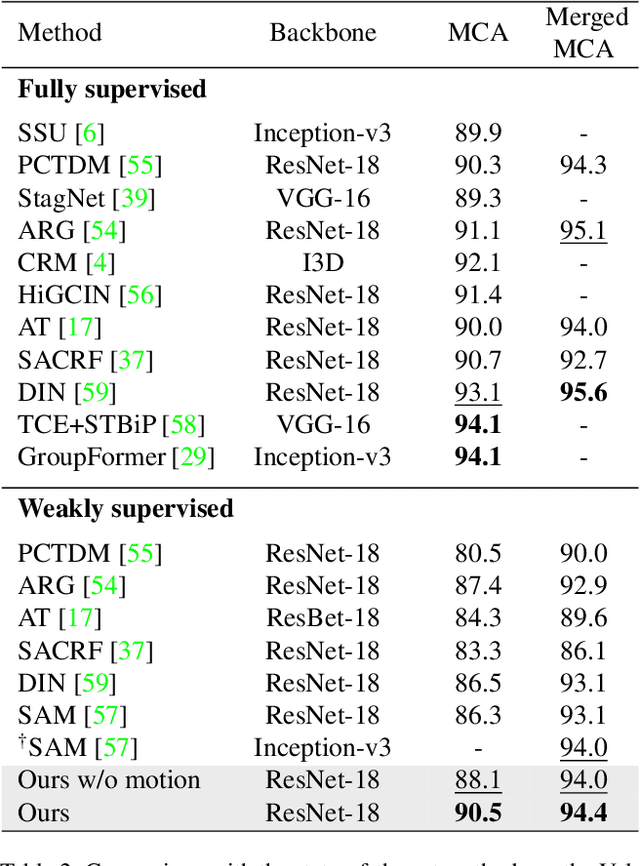
Group activity recognition is the task of understanding the activity conducted by a group of people as a whole in a multi-person video. Existing models for this task are often impractical in that they demand ground-truth bounding box labels of actors even in testing or rely on off-the-shelf object detectors. Motivated by this, we propose a novel model for group activity recognition that depends neither on bounding box labels nor on object detector. Our model based on Transformer localizes and encodes partial contexts of a group activity by leveraging the attention mechanism, and represents a video clip as a set of partial context embeddings. The embedding vectors are then aggregated to form a single group representation that reflects the entire context of an activity while capturing temporal evolution of each partial context. Our method achieves outstanding performance on two benchmarks, Volleyball and NBA datasets, surpassing not only the state of the art trained with the same level of supervision, but also some of existing models relying on stronger supervision.
Reflection and Rotation Symmetry Detection via Equivariant Learning
Mar 31, 2022
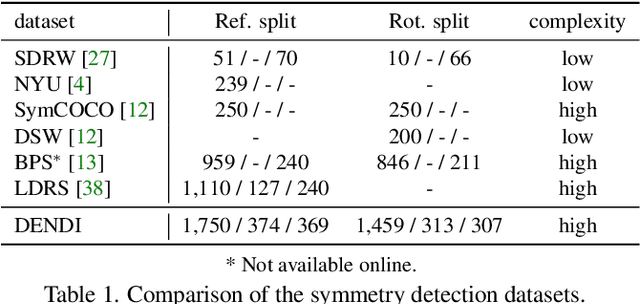
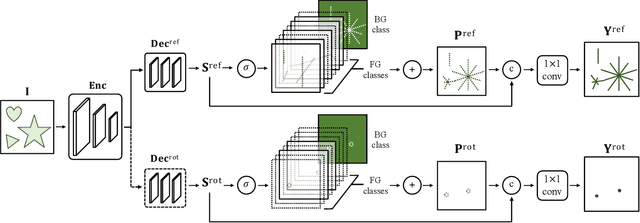
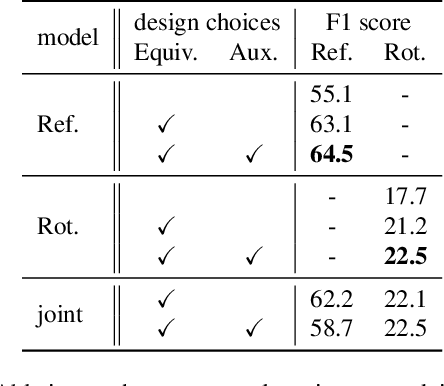
The inherent challenge of detecting symmetries stems from arbitrary orientations of symmetry patterns; a reflection symmetry mirrors itself against an axis with a specific orientation while a rotation symmetry matches its rotated copy with a specific orientation. Discovering such symmetry patterns from an image thus benefits from an equivariant feature representation, which varies consistently with reflection and rotation of the image. In this work, we introduce a group-equivariant convolutional network for symmetry detection, dubbed EquiSym, which leverages equivariant feature maps with respect to a dihedral group of reflection and rotation. The proposed network is built end-to-end with dihedrally-equivariant layers and trained to output a spatial map for reflection axes or rotation centers. We also present a new dataset, DENse and DIverse symmetry (DENDI), which mitigates limitations of existing benchmarks for reflection and rotation symmetry detection. Experiments show that our method achieves the state of the arts in symmetry detection on LDRS and DENDI datasets.
Integrative Few-Shot Learning for Classification and Segmentation
Mar 29, 2022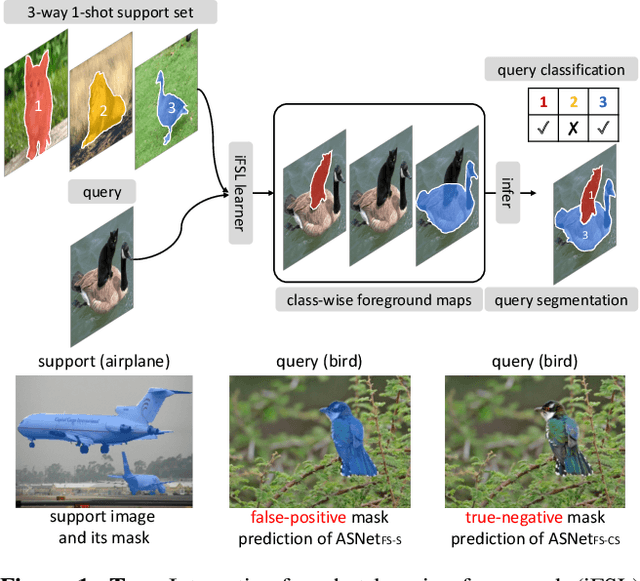
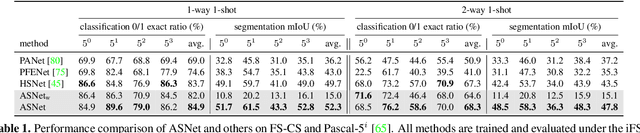
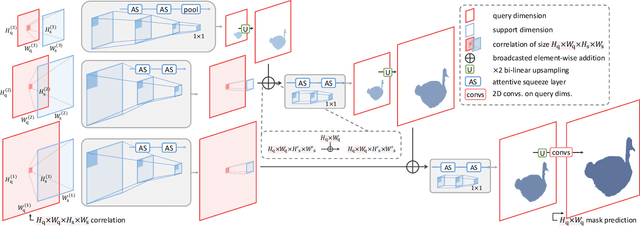
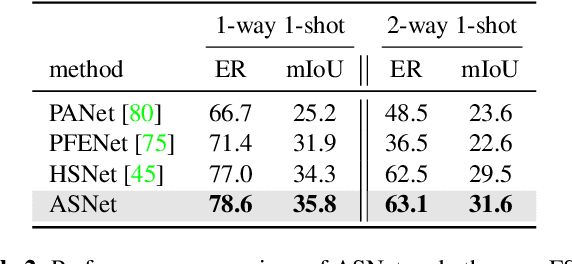
We introduce the integrative task of few-shot classification and segmentation (FS-CS) that aims to both classify and segment target objects in a query image when the target classes are given with a few examples. This task combines two conventional few-shot learning problems, few-shot classification and segmentation. FS-CS generalizes them to more realistic episodes with arbitrary image pairs, where each target class may or may not be present in the query. To address the task, we propose the integrative few-shot learning (iFSL) framework for FS-CS, which trains a learner to construct class-wise foreground maps for multi-label classification and pixel-wise segmentation. We also develop an effective iFSL model, attentive squeeze network (ASNet), that leverages deep semantic correlation and global self-attention to produce reliable foreground maps. In experiments, the proposed method shows promising performance on the FS-CS task and also achieves the state of the art on standard few-shot segmentation benchmarks.
Autoregressive Image Generation using Residual Quantization
Mar 09, 2022
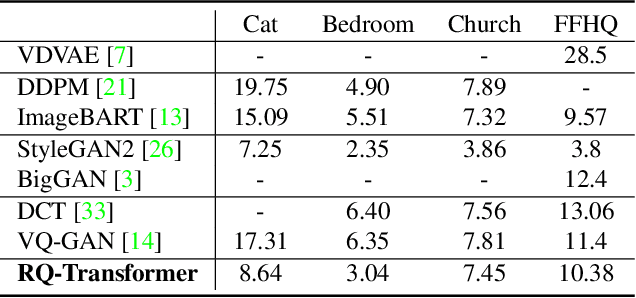
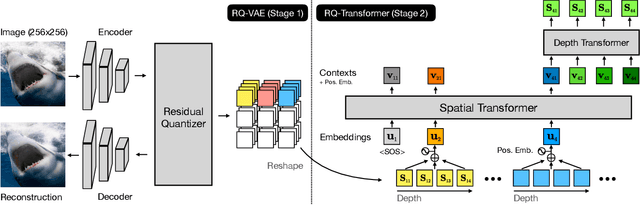

For autoregressive (AR) modeling of high-resolution images, vector quantization (VQ) represents an image as a sequence of discrete codes. A short sequence length is important for an AR model to reduce its computational costs to consider long-range interactions of codes. However, we postulate that previous VQ cannot shorten the code sequence and generate high-fidelity images together in terms of the rate-distortion trade-off. In this study, we propose the two-stage framework, which consists of Residual-Quantized VAE (RQ-VAE) and RQ-Transformer, to effectively generate high-resolution images. Given a fixed codebook size, RQ-VAE can precisely approximate a feature map of an image and represent the image as a stacked map of discrete codes. Then, RQ-Transformer learns to predict the quantized feature vector at the next position by predicting the next stack of codes. Thanks to the precise approximation of RQ-VAE, we can represent a 256$\times$256 image as 8$\times$8 resolution of the feature map, and RQ-Transformer can efficiently reduce the computational costs. Consequently, our framework outperforms the existing AR models on various benchmarks of unconditional and conditional image generation. Our approach also has a significantly faster sampling speed than previous AR models to generate high-quality images.
Selective Network Linearization for Efficient Private Inference
Feb 04, 2022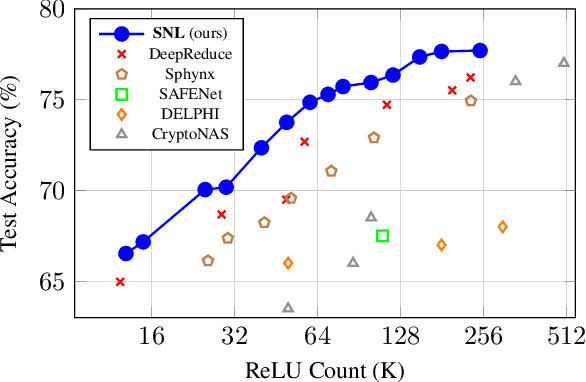
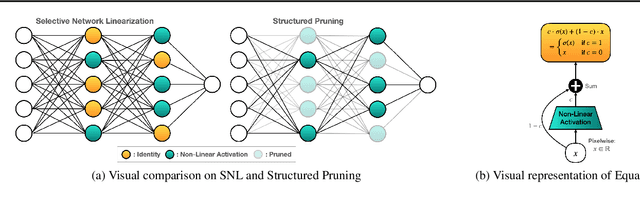
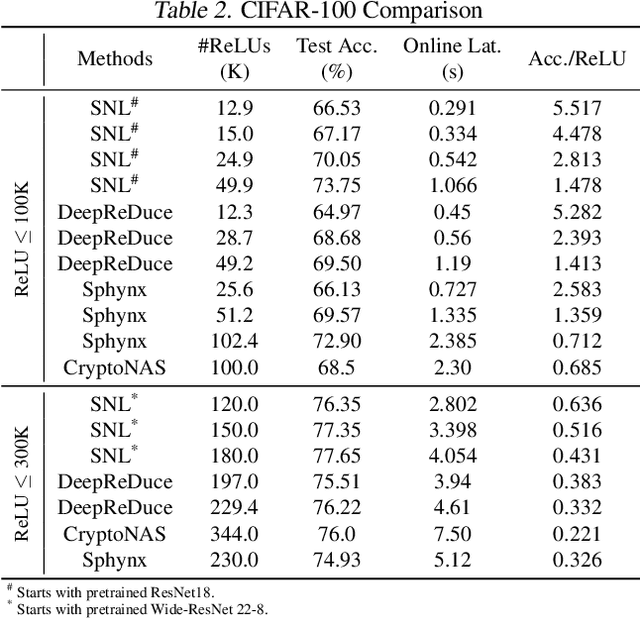
Private inference (PI) enables inference directly on cryptographically secure data. While promising to address many privacy issues, it has seen limited use due to extreme runtimes. Unlike plaintext inference, where latency is dominated by FLOPs, in PI non-linear functions (namely ReLU) are the bottleneck. Thus, practical PI demands novel ReLU-aware optimizations. To reduce PI latency we propose a gradient-based algorithm that selectively linearizes ReLUs while maintaining prediction accuracy. We evaluate our algorithm on several standard PI benchmarks. The results demonstrate up to $4.25\%$ more accuracy (iso-ReLU count at 50K) or $2.2\times$ less latency (iso-accuracy at 70\%) than the current state of the art and advance the Pareto frontier across the latency-accuracy space. To complement empirical results, we present a "no free lunch" theorem that sheds light on how and when network linearization is possible while maintaining prediction accuracy.
Contrastive Regularization for Semi-Supervised Learning
Jan 17, 2022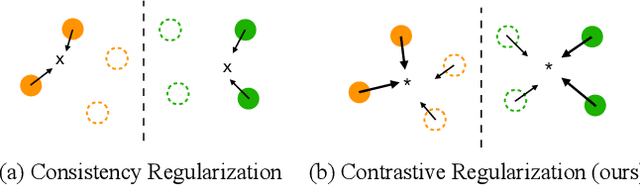
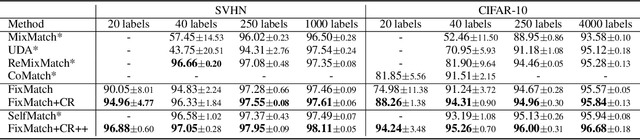
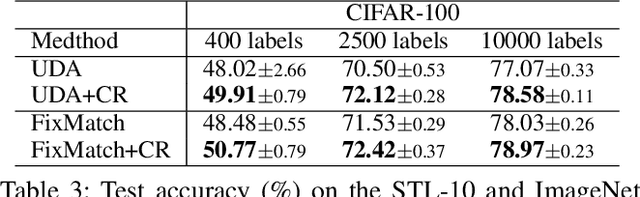
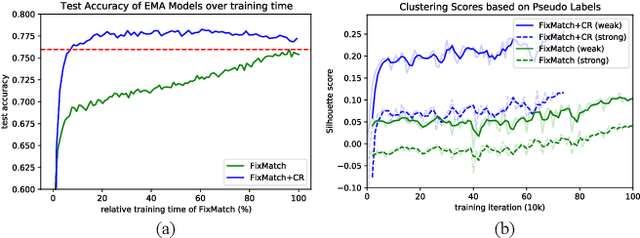
Consistency regularization on label predictions becomes a fundamental technique in semi-supervised learning, but it still requires a large number of training iterations for high performance. In this study, we analyze that the consistency regularization restricts the propagation of labeling information due to the exclusion of samples with unconfident pseudo-labels in the model updates. Then, we propose contrastive regularization to improve both efficiency and accuracy of the consistency regularization by well-clustered features of unlabeled data. In specific, after strongly augmented samples are assigned to clusters by their pseudo-labels, our contrastive regularization updates the model so that the features with confident pseudo-labels aggregate the features in the same cluster, while pushing away features in different clusters. As a result, the information of confident pseudo-labels can be effectively propagated into more unlabeled samples during training by the well-clustered features. On benchmarks of semi-supervised learning tasks, our contrastive regularization improves the previous consistency-based methods and achieves state-of-the-art results, especially with fewer training iterations. Our method also shows robust performance on open-set semi-supervised learning where unlabeled data includes out-of-distribution samples.
Fast Point Transformer
Dec 09, 2021
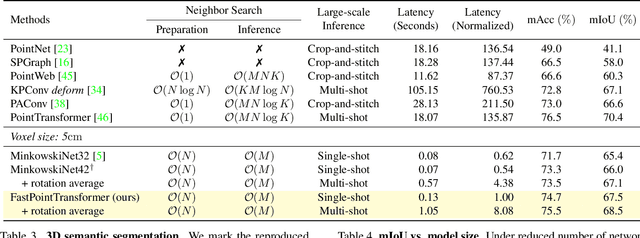
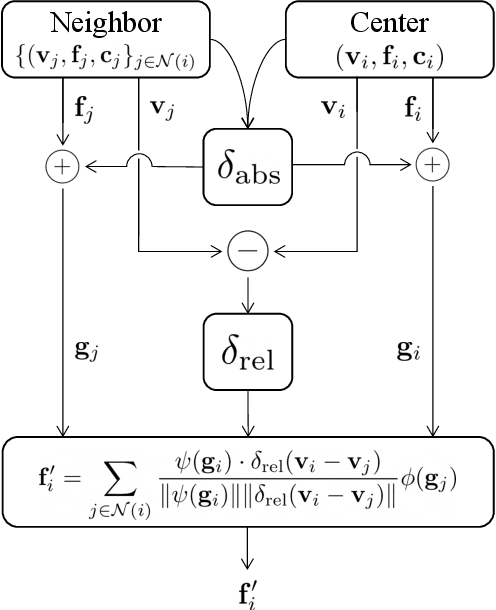
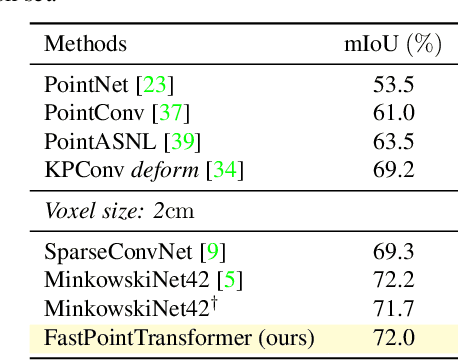
The recent success of neural networks enables a better interpretation of 3D point clouds, but processing a large-scale 3D scene remains a challenging problem. Most current approaches divide a large-scale scene into small regions and combine the local predictions together. However, this scheme inevitably involves additional stages for pre- and post-processing and may also degrade the final output due to predictions in a local perspective. This paper introduces Fast Point Transformer that consists of a new lightweight self-attention layer. Our approach encodes continuous 3D coordinates, and the voxel hashing-based architecture boosts computational efficiency. The proposed method is demonstrated with 3D semantic segmentation and 3D detection. The accuracy of our approach is competitive to the best voxel-based method, and our network achieves 136 times faster inference time than the state-of-the-art, Point Transformer, with a reasonable accuracy trade-off.
Semi-supervised Domain Adaptation via Sample-to-Sample Self-Distillation
Nov 29, 2021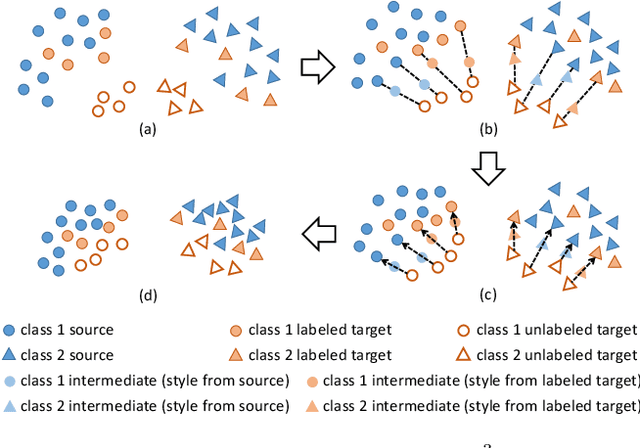
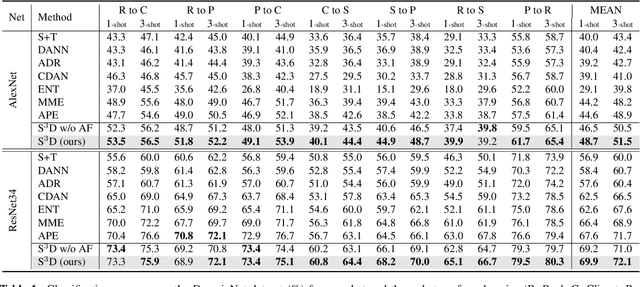
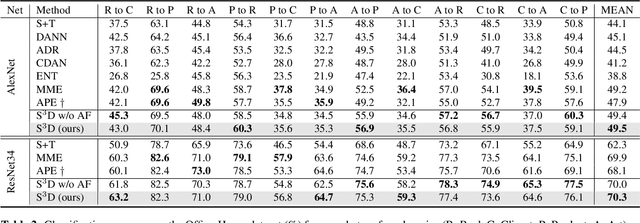
Semi-supervised domain adaptation (SSDA) is to adapt a learner to a new domain with only a small set of labeled samples when a large labeled dataset is given on a source domain. In this paper, we propose a pair-based SSDA method that adapts a model to the target domain using self-distillation with sample pairs. Each sample pair is composed of a teacher sample from a labeled dataset (i.e., source or labeled target) and its student sample from an unlabeled dataset (i.e., unlabeled target). Our method generates an assistant feature by transferring an intermediate style between the teacher and the student, and then train the model by minimizing the output discrepancy between the student and the assistant. During training, the assistants gradually bridge the discrepancy between the two domains, thus allowing the student to easily learn from the teacher. Experimental evaluation on standard benchmarks shows that our method effectively minimizes both the inter-domain and intra-domain discrepancies, thus achieving significant improvements over recent methods.
Relational Self-Attention: What's Missing in Attention for Video Understanding
Nov 02, 2021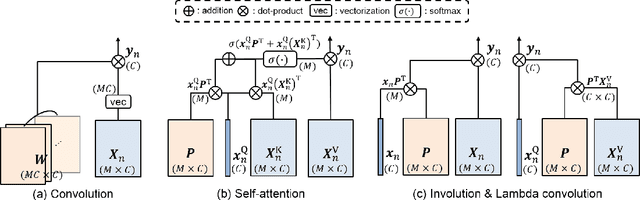

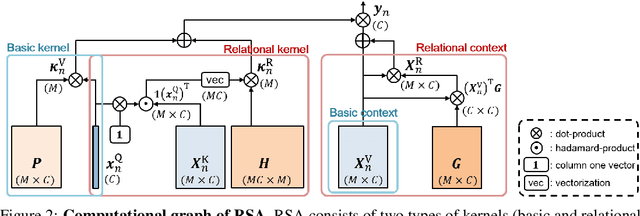
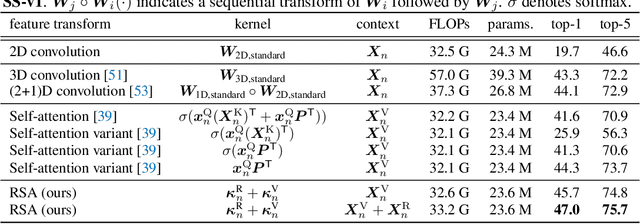
Convolution has been arguably the most important feature transform for modern neural networks, leading to the advance of deep learning. Recent emergence of Transformer networks, which replace convolution layers with self-attention blocks, has revealed the limitation of stationary convolution kernels and opened the door to the era of dynamic feature transforms. The existing dynamic transforms, including self-attention, however, are all limited for video understanding where correspondence relations in space and time, i.e., motion information, are crucial for effective representation. In this work, we introduce a relational feature transform, dubbed the relational self-attention (RSA), that leverages rich structures of spatio-temporal relations in videos by dynamically generating relational kernels and aggregating relational contexts. Our experiments and ablation studies show that the RSA network substantially outperforms convolution and self-attention counterparts, achieving the state of the art on the standard motion-centric benchmarks for video action recognition, such as Something-Something-V1 & V2, Diving48, and FineGym.