 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU-based Private Information Retrieval for On-Device Machine Learning Inference
Jan 27, 2023



On-device machine learning (ML) inference can enable the use of private user data on user devices without remote servers. However, a pure on-device solution to private ML inference is impractical for many applications that rely on embedding tables that are too large to be stored on-device. To overcome this barrier, we propose the use of private information retrieval (PIR) to efficiently and privately retrieve embeddings from servers without sharing any private information during on-device ML inference. As off-the-shelf PIR algorithms are usually too computationally intensive to directly use for latency-sensitive inference tasks, we 1) develop a novel algorithm for accelerating PIR on GPUs, and 2) co-design PIR with the downstream ML application to obtain further speedup. Our GPU acceleration strategy improves system throughput by more than $20 \times$ over an optimized CPU PIR implementation, and our co-design techniques obtain over $5 \times$ additional throughput improvement at fixed model quality. Together, on various on-device ML applications such as recommendation and language modeling, our system on a single V100 GPU can serve up to $100,000$ queries per second -- a $>100 \times$ throughput improvement over a naively implemented system -- while maintaining model accuracy, and limiting inference communication and response latency to within $300$KB and $<100$ms respectively.
DiVa: An Accelerator for Differentially Private Machine Learning
Aug 26, 2022
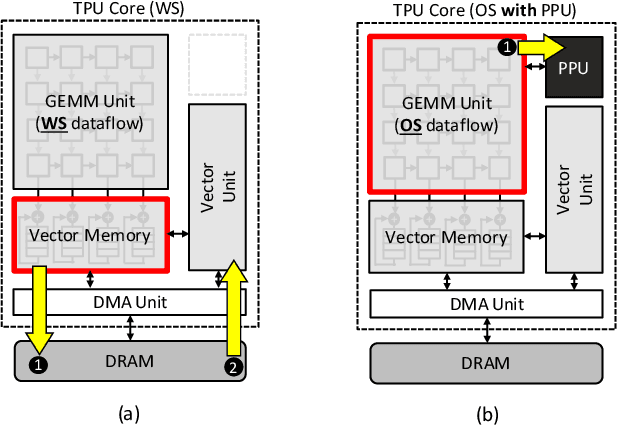
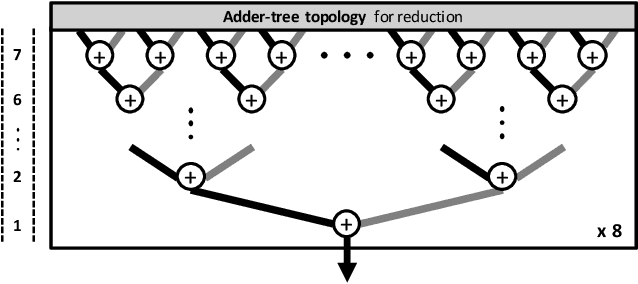
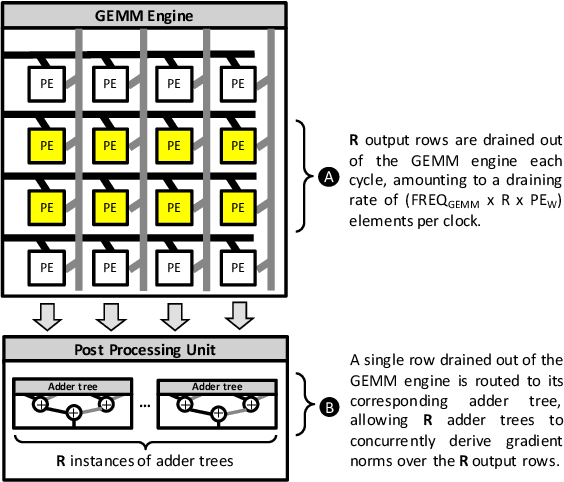
The widespread deployment of machine learning (ML) is raising serious concerns on protecting the privacy of users who contributed to the collection of training data. Differential privacy (DP) is rapidly gaining momentum in the industry as a practical standard for privacy protection. Despite DP's importance, however, little has been explored within the computer systems community regarding the implication of this emerging ML algorithm on system designs. In this work, we conduct a detailed workload characterization on a state-of-the-art differentially private ML training algorithm named DP-SGD. We uncover several unique properties of DP-SGD (e.g., its high memory capacity and computation requirements vs. non-private ML), root-causing its key bottlenecks. Based on our analysis, we propose an accelerator for differentially private ML named DiVa, which provides a significant improvement in compute utilization, leading to 2.6x higher energy-efficiency vs. conventional systolic arrays.
SmartSAGE: Training Large-scale Graph Neural Networks using In-Storage Processing Architectures
May 10, 2022
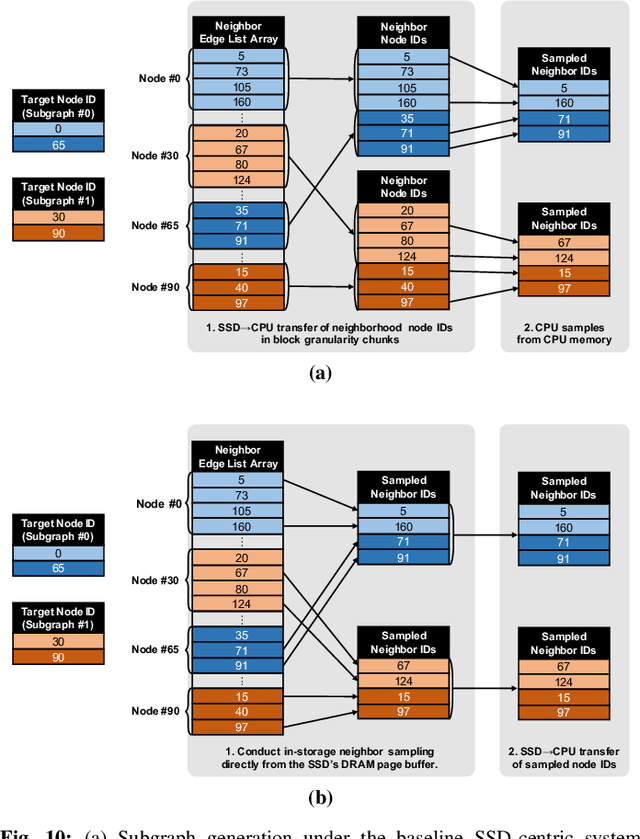
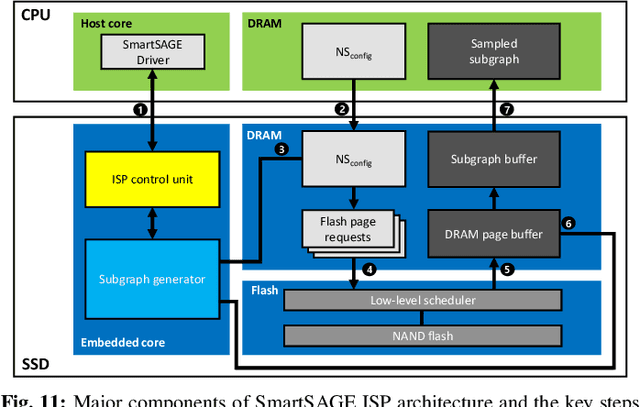
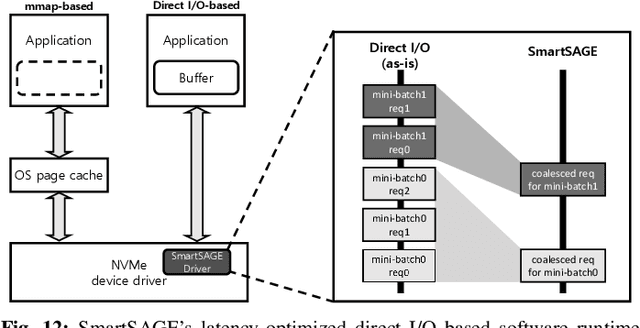
Graph neural networks (GNNs) can extract features by learning both the representation of each objects (i.e., graph nodes) and the relationship across different objects (i.e., the edges that connect nodes), achieving state-of-the-art performance in various graph-based tasks. Despite its strengths, utilizing these algorithms in a production environment faces several challenges as the number of graph nodes and edges amount to several billions to hundreds of billions scale, requiring substantial storage space for training. Unfortunately, state-of-the-art ML frameworks employ an in-memory processing model which significantly hampers the productivity of ML practitioners as it mandates the overall working set to fit within DRAM capacity. In this work, we first conduct a detailed characterization on a state-of-the-art, large-scale GNN training algorithm, GraphSAGE. Based on the characterization, we then explore the feasibility of utilizing capacity-optimized NVM SSDs for storing memory-hungry GNN data, which enables large-scale GNN training beyond the limits of main memory size. Given the large performance gap between DRAM and SSD, however, blindly utilizing SSDs as a direct substitute for DRAM leads to significant performance loss. We therefore develop SmartSAGE, our software/hardware co-design based on an in-storage processing (ISP) architecture. Our work demonstrates that an ISP based large-scale GNN training system can achieve both high capacity storage and high performance, opening up opportunities for ML practitioners to train large GNN datasets without being hampered by the physical limitations of main memory size.
Training Personalized Recommendation Systems from (GPU) Scratch: Look Forward not Backwards
May 10, 2022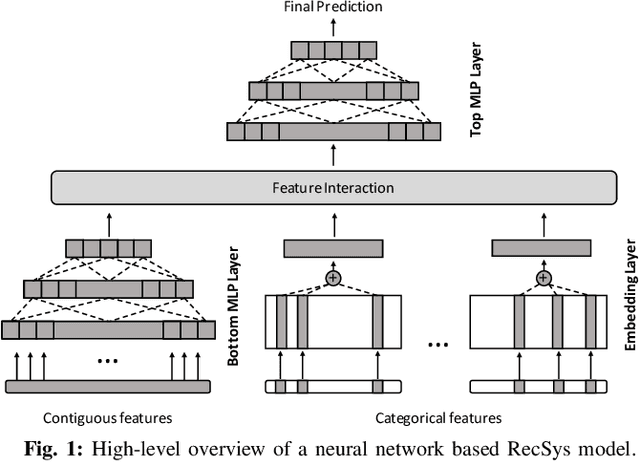
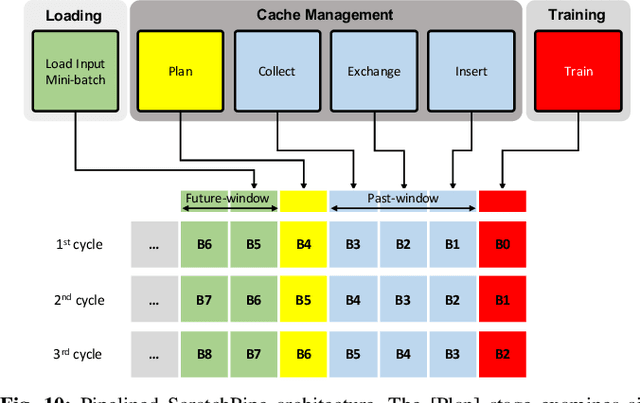
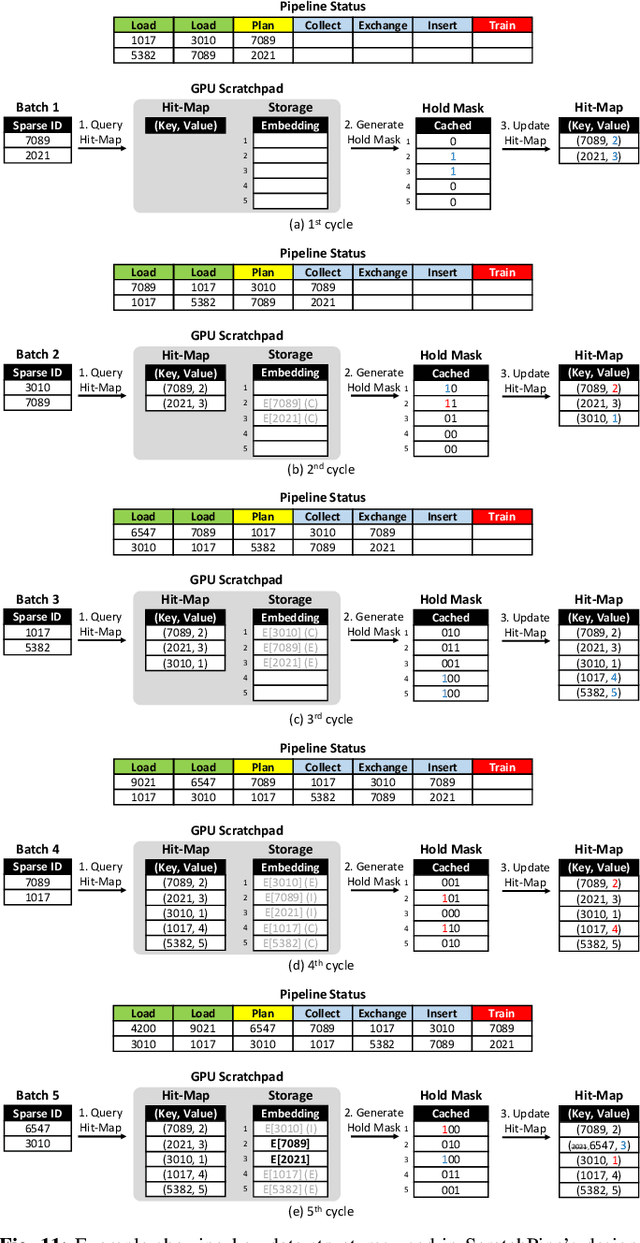
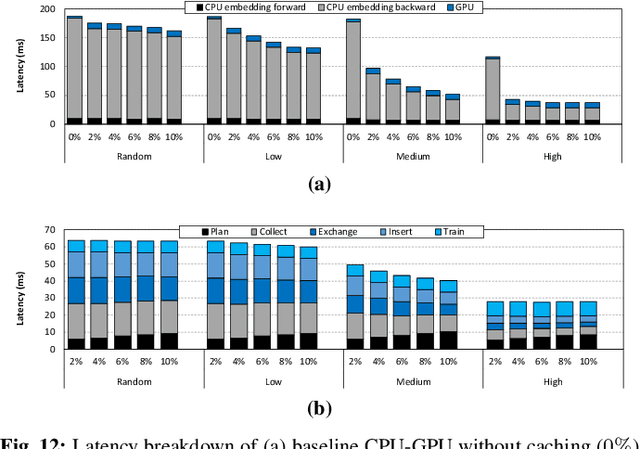
Personalized recommendation models (RecSys) are one of the most popular machine learning workload serviced by hyperscalers. A critical challenge of training RecSys is its high memory capacity requirements, reaching hundreds of GBs to TBs of model size. In RecSys, the so-called embedding layers account for the majority of memory usage so current systems employ a hybrid CPU-GPU design to have the large CPU memory store the memory hungry embedding layers. Unfortunately, training embeddings involve several memory bandwidth intensive operations which is at odds with the slow CPU memory, causing performance overheads. Prior work proposed to cache frequently accessed embeddings inside GPU memory as means to filter down the embedding layer traffic to CPU memory, but this paper observes several limitations with such cache design. In this work, we present a fundamentally different approach in designing embedding caches for RecSys. Our proposed ScratchPipe architecture utilizes unique properties of RecSys training to develop an embedding cache that not only sees the past but also the "future" cache accesses. ScratchPipe exploits such property to guarantee that the active working set of embedding layers can "always" be captured inside our proposed cache design, enabling embedding layer training to be conducted at GPU memory speed.
GROW: A Row-Stationary Sparse-Dense GEMM Accelerator for Memory-Efficient Graph Convolutional Neural Networks
Mar 02, 2022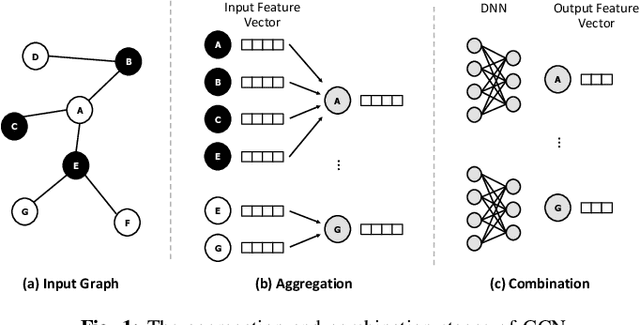
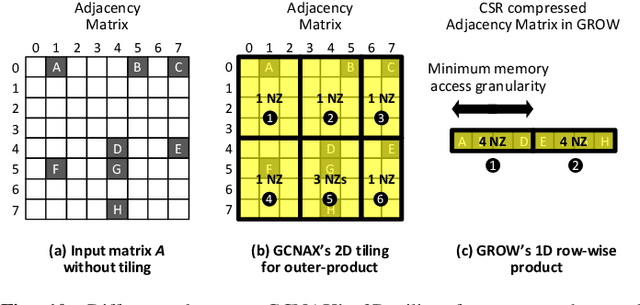
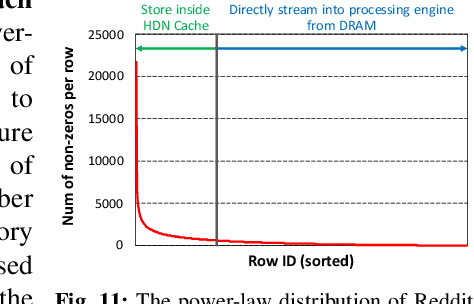
Graph convolutional neural networks (GCNs) have emerged as a key technology in various application domains where the input data is relational. A unique property of GCNs is that its two primary execution stages, aggregation and combination, exhibit drastically different dataflows. Consequently, prior GCN accelerators tackle this research space by casting the aggregation and combination stages as a series of sparse-dense matrix multiplication. However, prior work frequently suffers from inefficient data movements, leaving significant performance left on the table. We present GROW, a GCN accelerator based on Gustavson's algorithm to architect a row-wise product based sparse-dense GEMM accelerator. GROW co-designs the software/hardware that strikes a balance in locality and parallelism for GCNs, achieving significant energy-efficiency improvements vs. state-of-the-art GCN accelerators.
PARIS and ELSA: An Elastic Scheduling Algorithm for Reconfigurable Multi-GPU Inference Servers
Feb 27, 2022
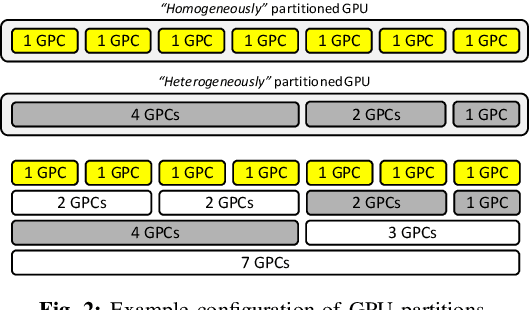
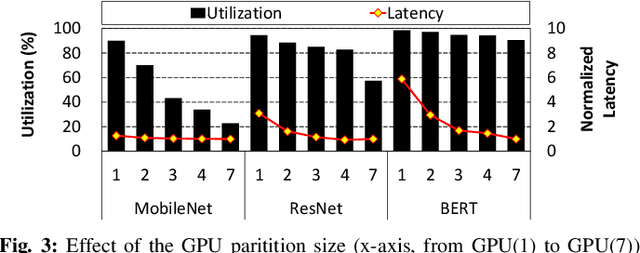
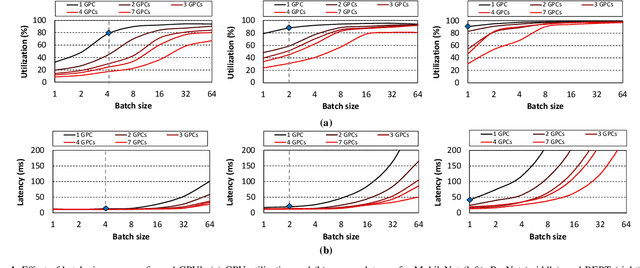
In cloud machine learning (ML) inference systems, providing low latency to end-users is of utmost importance. However, maximizing server utilization and system throughput is also crucial for ML service providers as it helps lower the total-cost-of-ownership. GPUs have oftentimes been criticized for ML inference usages as its massive compute and memory throughput is hard to be fully utilized under low-batch inference scenarios. To address such limitation, NVIDIA's recently announced Ampere GPU architecture provides features to "reconfigure" one large, monolithic GPU into multiple smaller "GPU partitions". Such feature provides cloud ML service providers the ability to utilize the reconfigurable GPU not only for large-batch training but also for small-batch inference with the potential to achieve high resource utilization. In this paper, we study this emerging GPU architecture with reconfigurability to develop a high-performance multi-GPU ML inference server. Our first proposition is a sophisticated partitioning algorithm for reconfigurable GPUs that systematically determines a heterogeneous set of multi-granular GPU partitions, best suited for the inference server's deployment. Furthermore, we co-design an elastic scheduling algorithm tailored for our heterogeneously partitioned GPU server which effectively balances low latency and high GPU utilization.
LazyBatching: An SLA-aware Batching System for Cloud Machine Learning Inference
Oct 25, 2020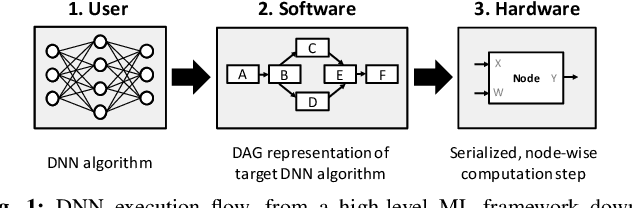
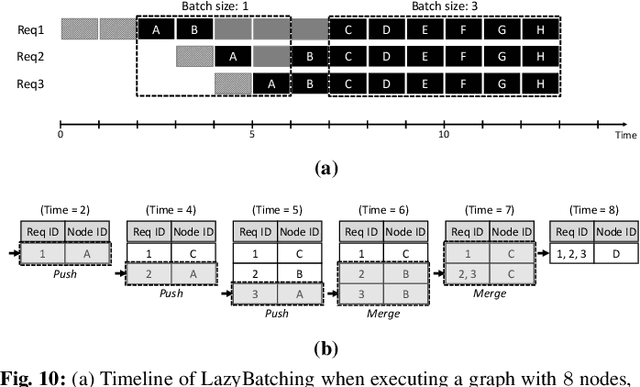
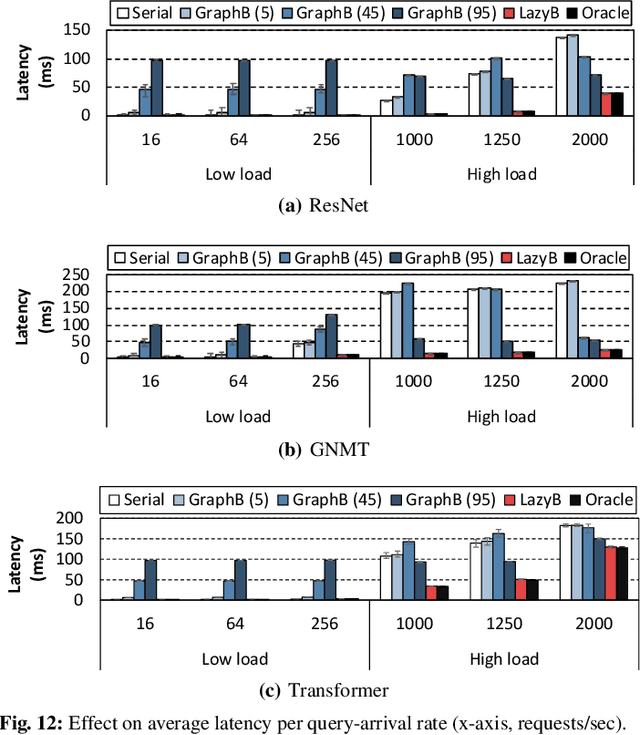
In cloud ML inference systems, batching is an essential technique to increase throughput which helps optimize total-cost-of-ownership. Prior graph batching combines the individual DNN graphs into a single one, allowing multiple inputs to be concurrently executed in parallel. We observe that the coarse-grained graph batching becomes suboptimal in effectively handling the dynamic inference request traffic, leaving significant performance left on the table. This paper proposes LazyBatching, an SLA-aware batching system that considers both scheduling and batching in the granularity of individual graph nodes, rather than the entire graph for flexible batching. We show that LazyBatching can intelligently determine the set of nodes that can be efficiently batched together, achieving an average 15x, 1.5x, and 5.5x improvement than graph batching in terms of average response time, throughput, and SLA satisfaction, respectively.
Tensor Casting: Co-Designing Algorithm-Architecture for Personalized Recommendation Training
Oct 25, 2020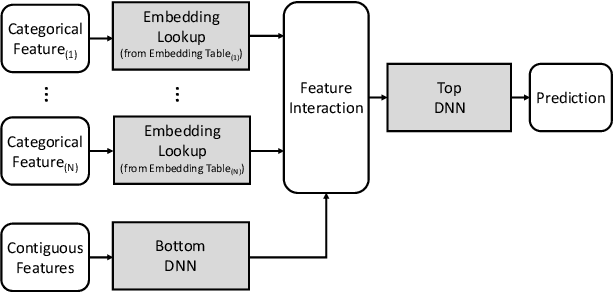
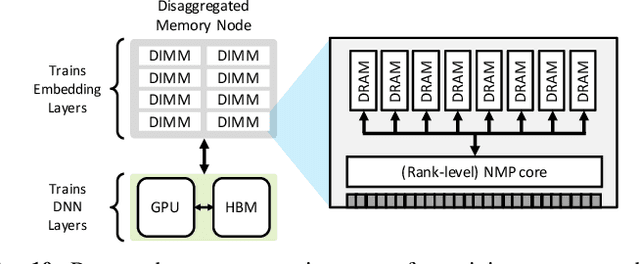
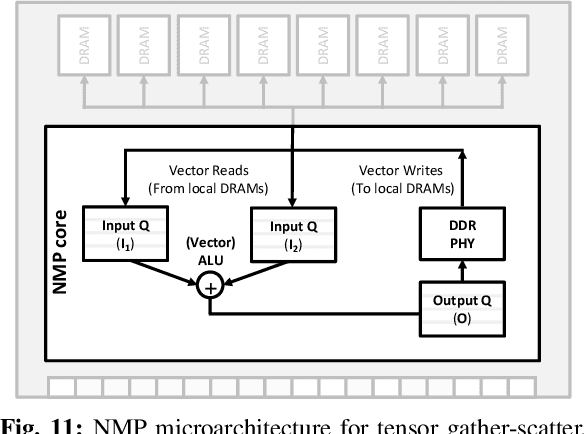
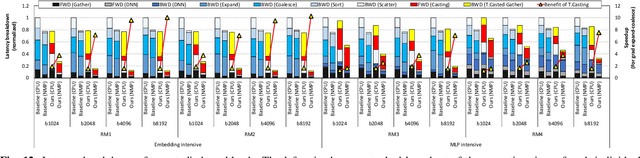
Personalized recommendations are one of the most widely deployed machine learning (ML) workload serviced from cloud datacenters. As such, architectural solutions for high-performance recommendation inference have recently been the target of several prior literatures. Unfortunately, little have been explored and understood regarding the training side of this emerging ML workload. In this paper, we first perform a detailed workload characterization study on training recommendations, root-causing sparse embedding layer training as one of the most significant performance bottlenecks. We then propose our algorithm-architecture co-design called Tensor Casting, which enables the development of a generic accelerator architecture for tensor gather-scatter that encompasses all the key primitives of training embedding layers. When prototyped on a real CPU-GPU system, Tensor Casting provides 1.9-21x improvements in training throughput compared to state-of-the-art approaches.
Centaur: A Chiplet-based, Hybrid Sparse-Dense Accelerator for Personalized Recommendations
May 12, 2020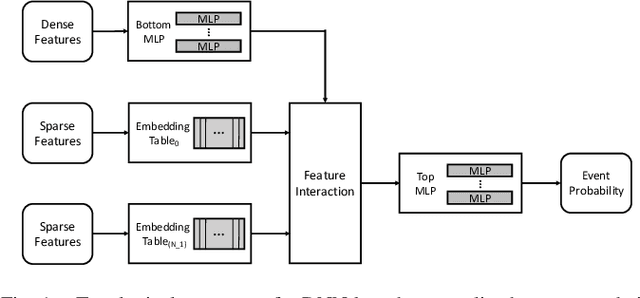
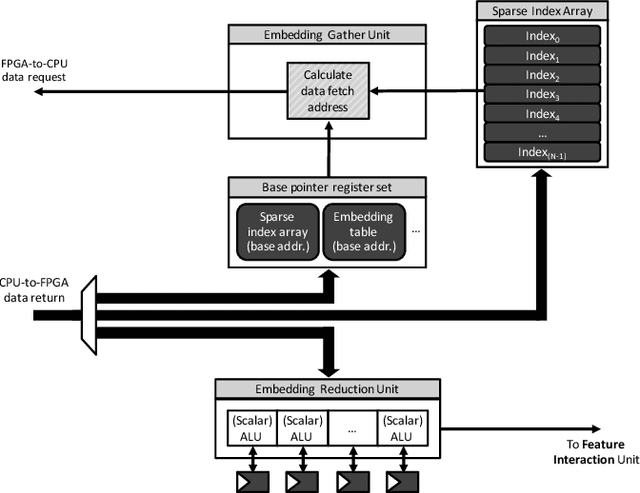
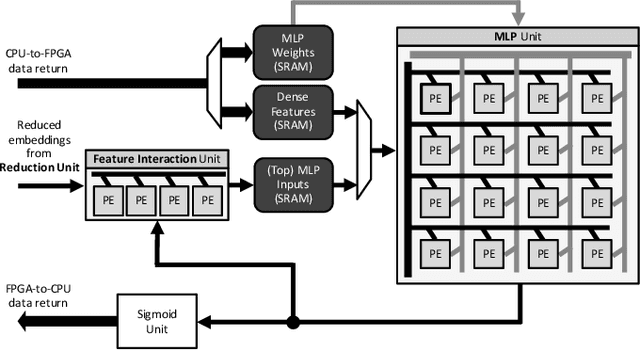
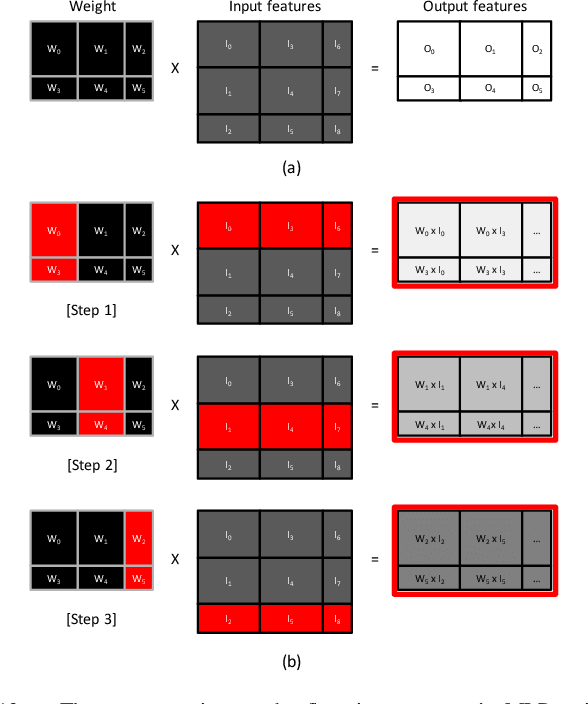
Personalized recommendations are the backbone machine learning (ML) algorithm that powers several important application domains (e.g., ads, e-commerce, etc) serviced from cloud datacenters. Sparse embedding layers are a crucial building block in designing recommendations yet little attention has been paid in properly accelerating this important ML algorithm. This paper first provides a detailed workload characterization on personalized recommendations and identifies two significant performance limiters: memory-intensive embedding layers and compute-intensive multi-layer perceptron (MLP) layers. We then present Centaur, a chiplet-based hybrid sparse-dense accelerator that addresses both the memory throughput challenges of embedding layers and the compute limitations of MLP layers. We implement and demonstrate our proposal on an Intel HARPv2, a package-integrated CPU+FPGA device, which shows a 1.7-17.2x performance speedup and 1.7-19.5x energy-efficiency improvement than conventional approaches.
NeuMMU: Architectural Support for Efficient Address Translations in Neural Processing Units
Nov 15, 2019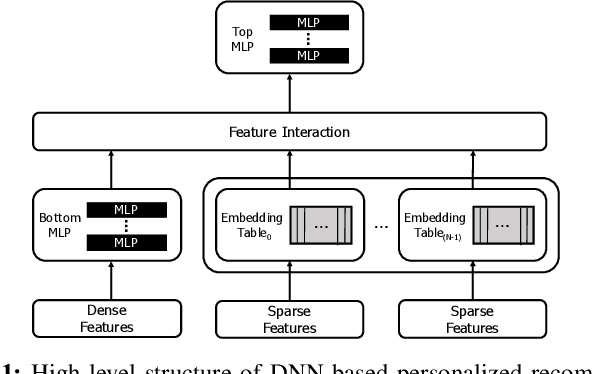
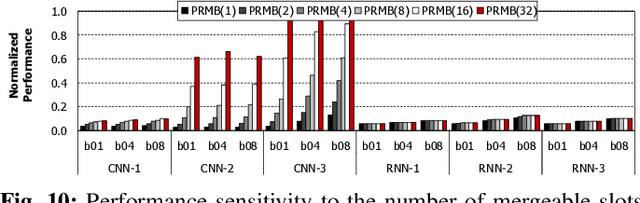
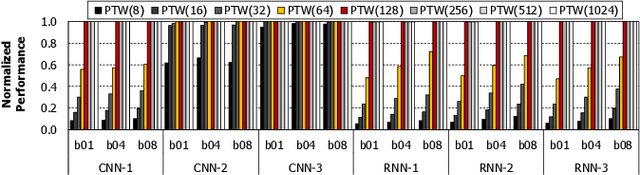
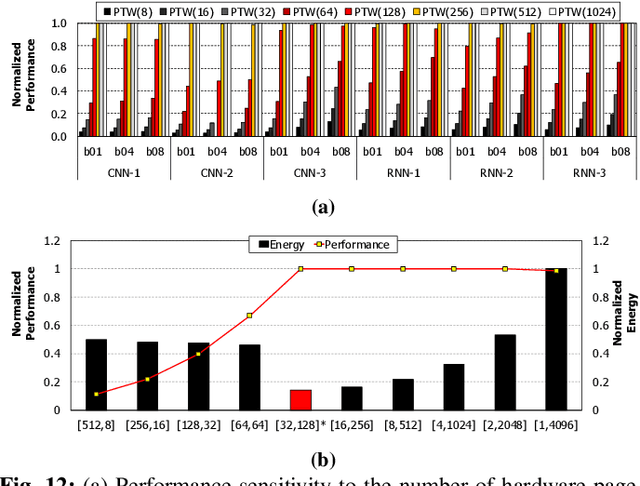
To satisfy the compute and memory demands of deep neural networks, neural processing units (NPUs) are widely being utilized for accelerating deep learning algorithms. Similar to how GPUs have evolved from a slave device into a mainstream processor architecture, it is likely that NPUs will become first class citizens in this fast-evolving heterogeneous architecture space. This paper makes a case for enabling address translation in NPUs to decouple the virtual and physical memory address space. Through a careful data-driven application characterization study, we root-cause several limitations of prior GPU-centric address translation schemes and propose a memory management unit (MMU) that is tailored for NPUs. Compared to an oracular MMU design point, our proposal incurs only an average 0.06% performance overhead.