 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-X: Full Pipeline Acceleration of On-device AI Agents
May 11, 2026LLM-based agents deliver state-of-the-art performance across tasks but incur high end-to-end latency on edge devices. We introduce Agent-X, a software-only, accuracy-preserving framework that accelerates both the prefill and decode stages of on-device agent workloads. Agent-X's two key components rewrite prompts to leverage prefix caching tailored to agent-specific input-token patterns and enable LLM-free speculative decoding for fast token generation with minimal overhead. On representative agentic workloads, Agent-X achieves a 1.61x end-to-end speedup in real systems with no accuracy loss and can be seamlessly integrated into existing on-device AI agents. To the best of our knowledge, ours is the first to systematically characterize and eliminate latency bottlenecks in on-device agents.
SpecMoE: A Fast and Efficient Mixture-of-Experts Inference via Self-Assisted Speculative Decoding
Apr 11, 2026The Mixture-of-Experts (MoE) architecture has emerged as a promising approach to mitigate the rising computational costs of large language models (LLMs) by selectively activating parameters. However, its high memory requirements and sub-optimal parameter efficiency pose significant challenges for efficient deployment. Although CPU-offloaded MoE inference systems have been proposed in the literature, they offer limited efficiency, particularly for large batch sizes. In this work, we propose SpecMoE, a memory-efficient MoE inference system based on our self-assisted speculative decoding algorithm. SpecMoE demonstrates the effectiveness of applying speculative decoding to MoE inference without requiring additional model training or fine-tuning. Our system improves inference throughput by up to $4.30\times$, while significantly reducing bandwidth requirements of both memory and interconnect on memory-constrained systems.
The Cost of Dynamic Reasoning: Demystifying AI Agents and Test-Time Scaling from an AI Infrastructure Perspective
Jun 04, 2025



Large-language-model (LLM)-based AI agents have recently showcased impressive versatility by employing dynamic reasoning, an adaptive, multi-step process that coordinates with external tools. This shift from static, single-turn inference to agentic, multi-turn workflows broadens task generalization and behavioral flexibility, but it also introduces serious concerns about system-level cost, efficiency, and sustainability. This paper presents the first comprehensive system-level analysis of AI agents, quantifying their resource usage, latency behavior, energy consumption, and datacenter-wide power consumption demands across diverse agent designs and test-time scaling strategies. We further characterize how AI agent design choices, such as few-shot prompting, reflection depth, and parallel reasoning, impact accuracy-cost tradeoffs. Our findings reveal that while agents improve accuracy with increased compute, they suffer from rapidly diminishing returns, widening latency variance, and unsustainable infrastructure costs. Through detailed evaluation of representative agents, we highlight the profound computational demands introduced by AI agent workflows, uncovering a looming sustainability crisis. These results call for a paradigm shift in agent design toward compute-efficient reasoning, balancing performance with deployability under real-world constraints.
SmartSAGE: Training Large-scale Graph Neural Networks using In-Storage Processing Architectures
May 10, 2022
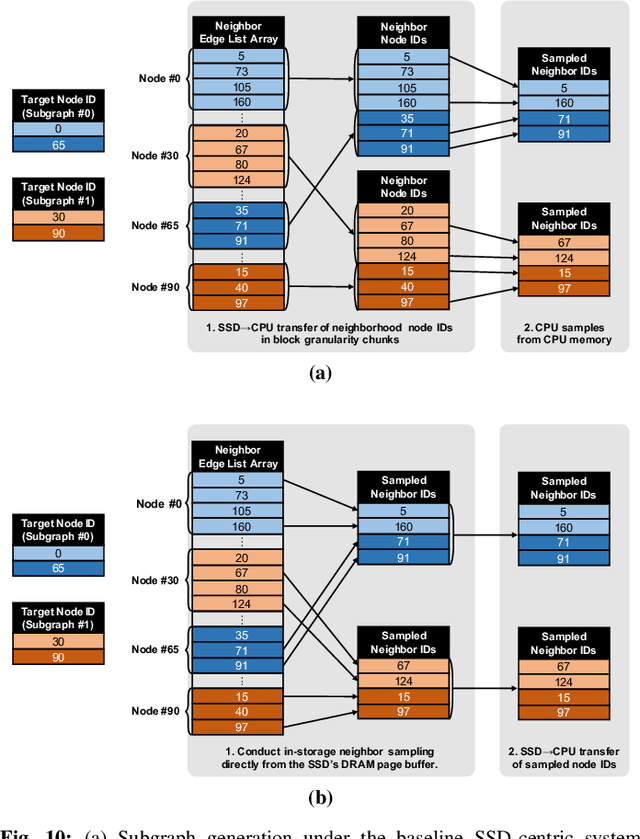
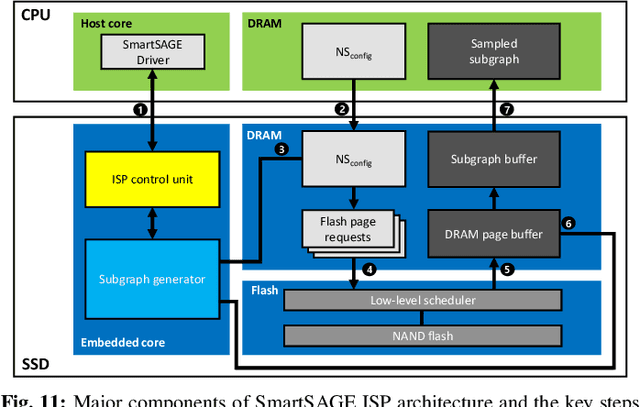
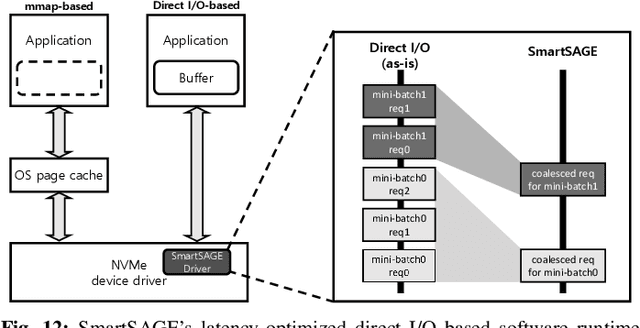
Graph neural networks (GNNs) can extract features by learning both the representation of each objects (i.e., graph nodes) and the relationship across different objects (i.e., the edges that connect nodes), achieving state-of-the-art performance in various graph-based tasks. Despite its strengths, utilizing these algorithms in a production environment faces several challenges as the number of graph nodes and edges amount to several billions to hundreds of billions scale, requiring substantial storage space for training. Unfortunately, state-of-the-art ML frameworks employ an in-memory processing model which significantly hampers the productivity of ML practitioners as it mandates the overall working set to fit within DRAM capacity. In this work, we first conduct a detailed characterization on a state-of-the-art, large-scale GNN training algorithm, GraphSAGE. Based on the characterization, we then explore the feasibility of utilizing capacity-optimized NVM SSDs for storing memory-hungry GNN data, which enables large-scale GNN training beyond the limits of main memory size. Given the large performance gap between DRAM and SSD, however, blindly utilizing SSDs as a direct substitute for DRAM leads to significant performance loss. We therefore develop SmartSAGE, our software/hardware co-design based on an in-storage processing (ISP) architecture. Our work demonstrates that an ISP based large-scale GNN training system can achieve both high capacity storage and high performance, opening up opportunities for ML practitioners to train large GNN datasets without being hampered by the physical limitations of main memory size.