 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREBA: A Hardware/Software Co-Design for Multi-Instance GPU based AI Inference Servers
Nov 28, 2024NVIDIA's Multi-Instance GPU (MIG) is a feature that enables system designers to reconfigure one large GPU into multiple smaller GPU slices. This work characterizes this emerging GPU and evaluates its effectiveness in designing high-performance AI inference servers. Our study reveals that the data preprocessing stage of AI inference causes significant performance bottlenecks to MIG. To this end, we present PREBA, which is a hardware/software co-design targeting MIG inference servers. Our first proposition is an FPGA-based data preprocessing accelerator that unlocks the full potential of MIG with domain-specific acceleration of data preprocessing. The MIG inference server unleashed from preprocessing overheads is then augmented with our dynamic batching system that enables high-performance inference. PREBA is implemented end-to-end in real systems, providing a 3.7x improvement in throughput, 3.4x reduction in tail latency, 3.5x improvement in energy-efficiency, and 3.0x improvement in cost-efficiency.
ElasticRec: A Microservice-based Model Serving Architecture Enabling Elastic Resource Scaling for Recommendation Models
Jun 11, 2024With the increasing popularity of recommendation systems (RecSys), the demand for compute resources in datacenters has surged. However, the model-wise resource allocation employed in current RecSys model serving architectures falls short in effectively utilizing resources, leading to sub-optimal total cost of ownership. We propose ElasticRec, a model serving architecture for RecSys providing resource elasticity and high memory efficiency. ElasticRec is based on a microservice-based software architecture for fine-grained resource allocation, tailored to the heterogeneous resource demands of RecSys. Additionally, ElasticRec achieves high memory efficiency via our utility-based resource allocation. Overall, ElasticRec achieves an average 3.3x reduction in memory allocation size and 8.1x increase in memory utility, resulting in an average 1.6x reduction in deployment cost compared to state-of-the-art RecSys inference serving system.
Hera: A Heterogeneity-Aware Multi-Tenant Inference Server for Personalized Recommendations
Feb 23, 2023



While providing low latency is a fundamental requirement in deploying recommendation services, achieving high resource utility is also crucial in cost-effectively maintaining the datacenter. Co-locating multiple workers of a model is an effective way to maximize query-level parallelism and server throughput, but the interference caused by concurrent workers at shared resources can prevent server queries from meeting its SLA. Hera utilizes the heterogeneous memory requirement of multi-tenant recommendation models to intelligently determine a productive set of co-located models and its resource allocation, providing fast response time while achieving high throughput. We show that Hera achieves an average 37.3% improvement in effective machine utilization, enabling 26% reduction in required servers, significantly improving upon the baseline recommedation inference server.
PARIS and ELSA: An Elastic Scheduling Algorithm for Reconfigurable Multi-GPU Inference Servers
Feb 27, 2022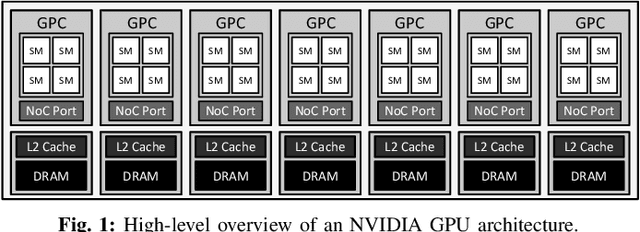
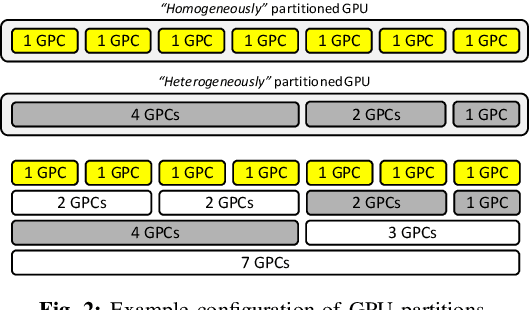
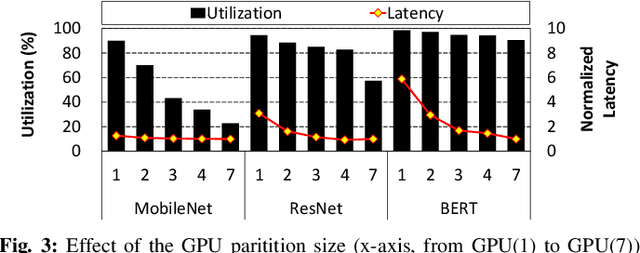
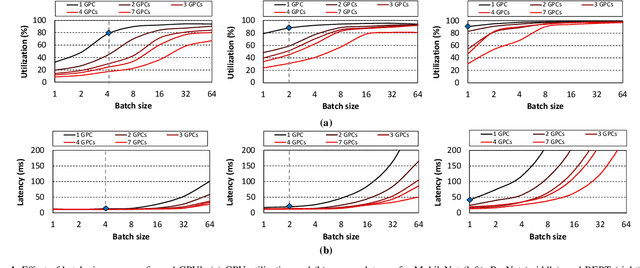
In cloud machine learning (ML) inference systems, providing low latency to end-users is of utmost importance. However, maximizing server utilization and system throughput is also crucial for ML service providers as it helps lower the total-cost-of-ownership. GPUs have oftentimes been criticized for ML inference usages as its massive compute and memory throughput is hard to be fully utilized under low-batch inference scenarios. To address such limitation, NVIDIA's recently announced Ampere GPU architecture provides features to "reconfigure" one large, monolithic GPU into multiple smaller "GPU partitions". Such feature provides cloud ML service providers the ability to utilize the reconfigurable GPU not only for large-batch training but also for small-batch inference with the potential to achieve high resource utilization. In this paper, we study this emerging GPU architecture with reconfigurability to develop a high-performance multi-GPU ML inference server. Our first proposition is a sophisticated partitioning algorithm for reconfigurable GPUs that systematically determines a heterogeneous set of multi-granular GPU partitions, best suited for the inference server's deployment. Furthermore, we co-design an elastic scheduling algorithm tailored for our heterogeneously partitioned GPU server which effectively balances low latency and high GPU utilization.
LazyBatching: An SLA-aware Batching System for Cloud Machine Learning Inference
Oct 25, 2020
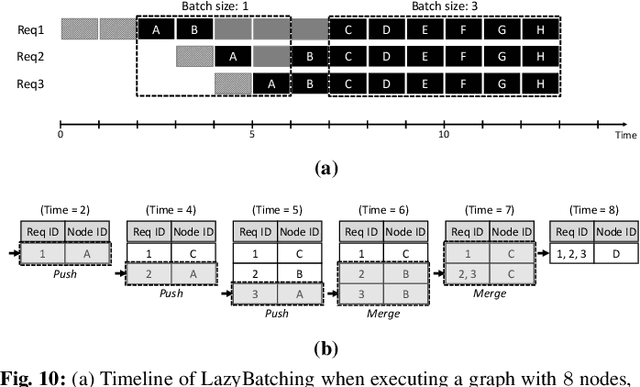
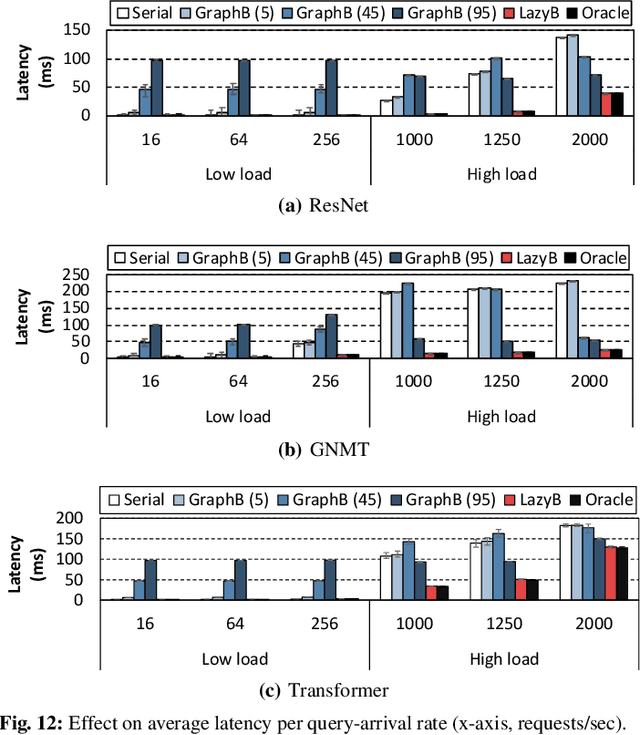
In cloud ML inference systems, batching is an essential technique to increase throughput which helps optimize total-cost-of-ownership. Prior graph batching combines the individual DNN graphs into a single one, allowing multiple inputs to be concurrently executed in parallel. We observe that the coarse-grained graph batching becomes suboptimal in effectively handling the dynamic inference request traffic, leaving significant performance left on the table. This paper proposes LazyBatching, an SLA-aware batching system that considers both scheduling and batching in the granularity of individual graph nodes, rather than the entire graph for flexible batching. We show that LazyBatching can intelligently determine the set of nodes that can be efficiently batched together, achieving an average 15x, 1.5x, and 5.5x improvement than graph batching in terms of average response time, throughput, and SLA satisfaction, respectively.
NeuMMU: Architectural Support for Efficient Address Translations in Neural Processing Units
Nov 15, 2019
To satisfy the compute and memory demands of deep neural networks, neural processing units (NPUs) are widely being utilized for accelerating deep learning algorithms. Similar to how GPUs have evolved from a slave device into a mainstream processor architecture, it is likely that NPUs will become first class citizens in this fast-evolving heterogeneous architecture space. This paper makes a case for enabling address translation in NPUs to decouple the virtual and physical memory address space. Through a careful data-driven application characterization study, we root-cause several limitations of prior GPU-centric address translation schemes and propose a memory management unit (MMU) that is tailored for NPUs. Compared to an oracular MMU design point, our proposal incurs only an average 0.06% performance overhead.
PREMA: A Predictive Multi-task Scheduling Algorithm For Preemptible Neural Processing Units
Sep 06, 2019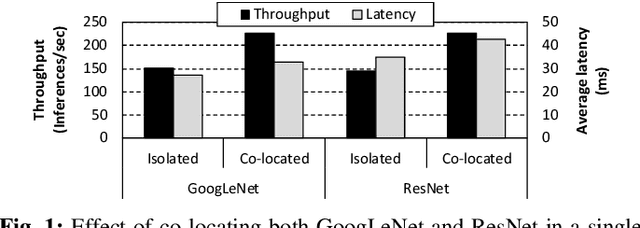
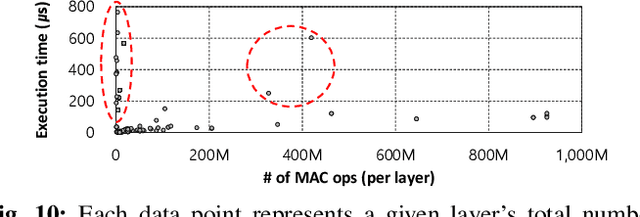
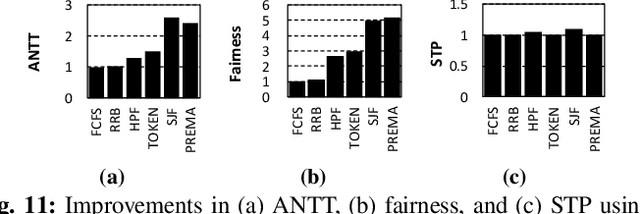
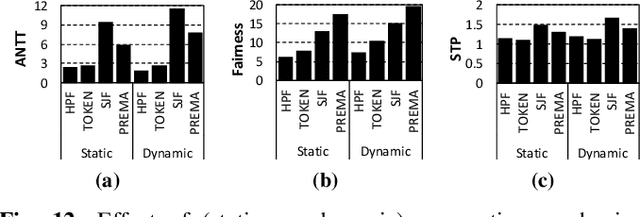
To amortize cost, cloud vendors providing DNN acceleration as a service to end-users employ consolidation and virtualization to share the underlying resources among multiple DNN service requests. This paper makes a case for a "preemptible" neural processing unit (NPU) and a "predictive" multi-task scheduler to meet the latency demands of high-priority inference while maintaining high throughput. We evaluate both the mechanisms that enable NPUs to be preemptible and the policies that utilize them to meet scheduling objectives. We show that preemptive NPU multi-tasking can achieve an average 7.8x, 1.4x, and 4.8x improvement in latency, throughput, and SLA satisfaction, respectively.