 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePARIS and ELSA: An Elastic Scheduling Algorithm for Reconfigurable Multi-GPU Inference Servers
Feb 27, 2022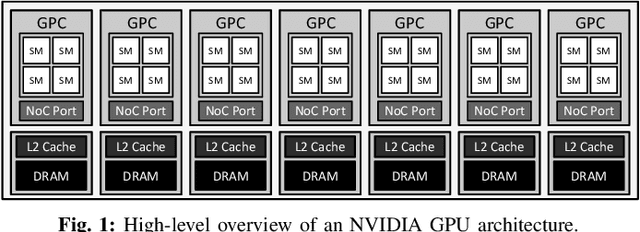
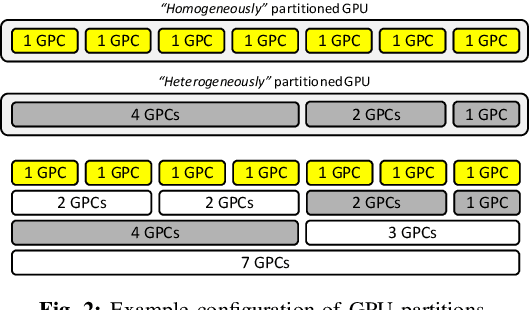
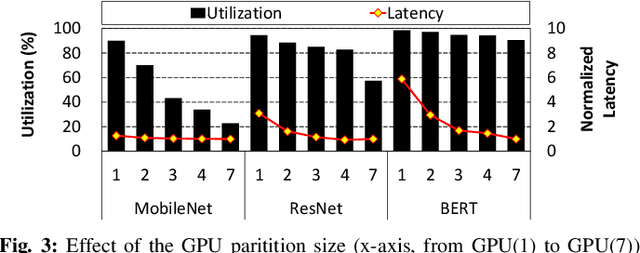
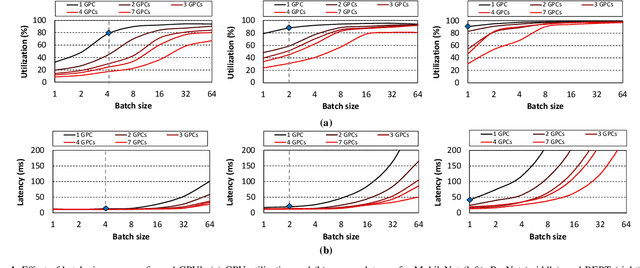
In cloud machine learning (ML) inference systems, providing low latency to end-users is of utmost importance. However, maximizing server utilization and system throughput is also crucial for ML service providers as it helps lower the total-cost-of-ownership. GPUs have oftentimes been criticized for ML inference usages as its massive compute and memory throughput is hard to be fully utilized under low-batch inference scenarios. To address such limitation, NVIDIA's recently announced Ampere GPU architecture provides features to "reconfigure" one large, monolithic GPU into multiple smaller "GPU partitions". Such feature provides cloud ML service providers the ability to utilize the reconfigurable GPU not only for large-batch training but also for small-batch inference with the potential to achieve high resource utilization. In this paper, we study this emerging GPU architecture with reconfigurability to develop a high-performance multi-GPU ML inference server. Our first proposition is a sophisticated partitioning algorithm for reconfigurable GPUs that systematically determines a heterogeneous set of multi-granular GPU partitions, best suited for the inference server's deployment. Furthermore, we co-design an elastic scheduling algorithm tailored for our heterogeneously partitioned GPU server which effectively balances low latency and high GPU utilization.
LazyBatching: An SLA-aware Batching System for Cloud Machine Learning Inference
Oct 25, 2020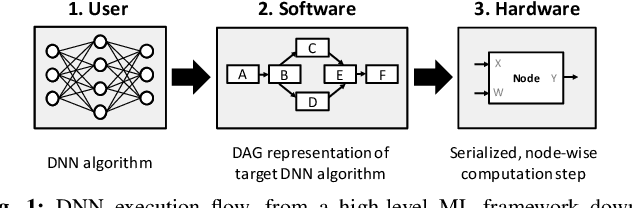
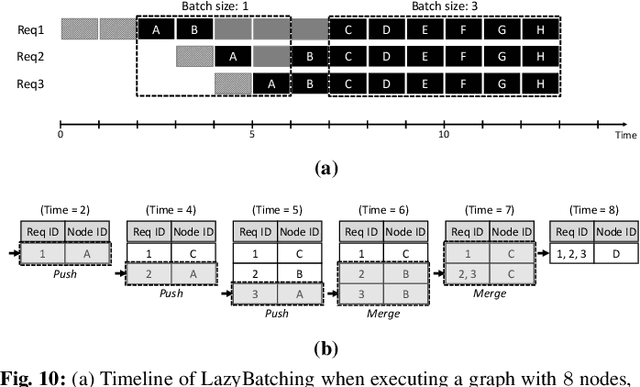
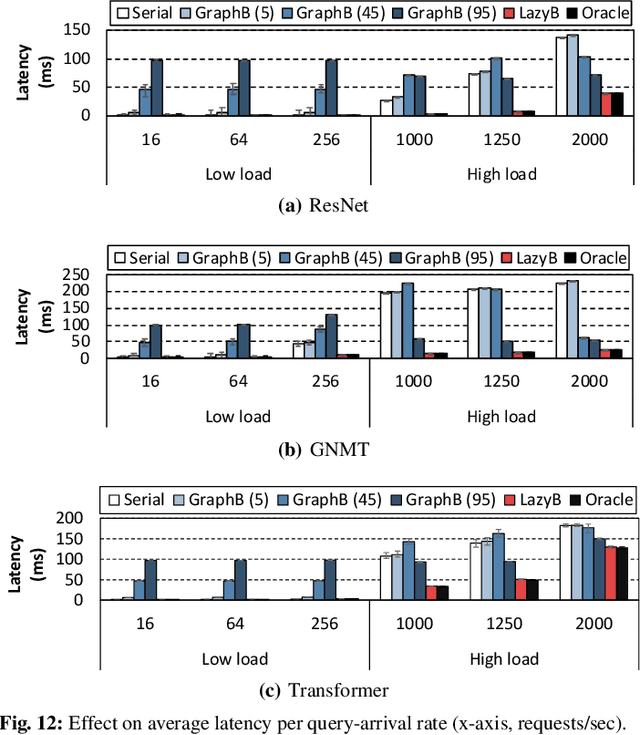
In cloud ML inference systems, batching is an essential technique to increase throughput which helps optimize total-cost-of-ownership. Prior graph batching combines the individual DNN graphs into a single one, allowing multiple inputs to be concurrently executed in parallel. We observe that the coarse-grained graph batching becomes suboptimal in effectively handling the dynamic inference request traffic, leaving significant performance left on the table. This paper proposes LazyBatching, an SLA-aware batching system that considers both scheduling and batching in the granularity of individual graph nodes, rather than the entire graph for flexible batching. We show that LazyBatching can intelligently determine the set of nodes that can be efficiently batched together, achieving an average 15x, 1.5x, and 5.5x improvement than graph batching in terms of average response time, throughput, and SLA satisfaction, respectively.