 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPA: Visual Informative Part Attention for Referring Image Segmentation
Feb 16, 2026Referring Image Segmentation (RIS) aims to segment a target object described by a natural language expression. Existing methods have evolved by leveraging the vision information into the language tokens. To more effectively exploit visual contexts for fine-grained segmentation, we propose a novel Visual Informative Part Attention (VIPA) framework for referring image segmentation. VIPA leverages the informative parts of visual contexts, called a visual expression, which can effectively provide the structural and semantic visual target information to the network. This design reduces high-variance cross-modal projection and enhances semantic consistency in an attention mechanism of the referring image segmentation. We also design a visual expression generator (VEG) module, which retrieves informative visual tokens via local-global linguistic context cues and refines the retrieved tokens for reducing noise information and sharing informative visual attributes. This module allows the visual expression to consider comprehensive contexts and capture semantic visual contexts of informative regions. In this way, our framework enables the network's attention to robustly align with the fine-grained regions of interest. Extensive experiments and visual analysis demonstrate the effectiveness of our approach. Our VIPA outperforms the existing state-of-the-art methods on four public RIS benchmarks.
NeuMMU: Architectural Support for Efficient Address Translations in Neural Processing Units
Nov 15, 2019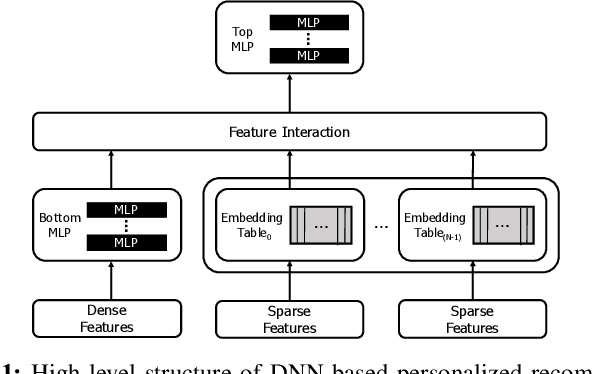
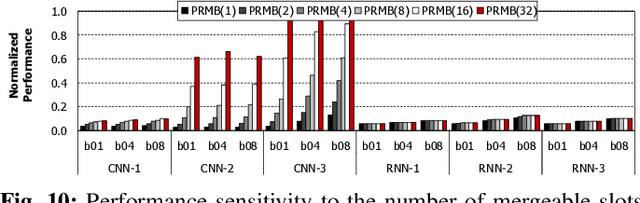
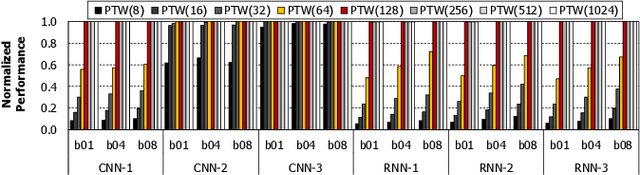
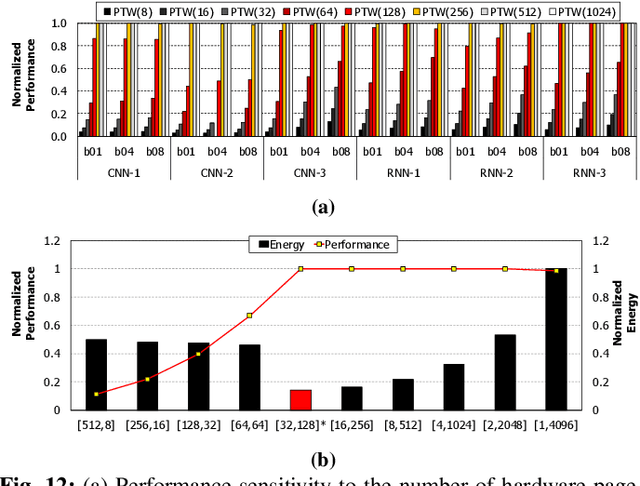
To satisfy the compute and memory demands of deep neural networks, neural processing units (NPUs) are widely being utilized for accelerating deep learning algorithms. Similar to how GPUs have evolved from a slave device into a mainstream processor architecture, it is likely that NPUs will become first class citizens in this fast-evolving heterogeneous architecture space. This paper makes a case for enabling address translation in NPUs to decouple the virtual and physical memory address space. Through a careful data-driven application characterization study, we root-cause several limitations of prior GPU-centric address translation schemes and propose a memory management unit (MMU) that is tailored for NPUs. Compared to an oracular MMU design point, our proposal incurs only an average 0.06% performance overhead.