 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKuraNet: Systems of Coupled Oscillators that Learn to Synchronize
May 06, 2021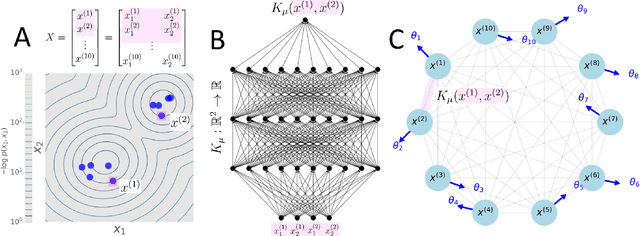
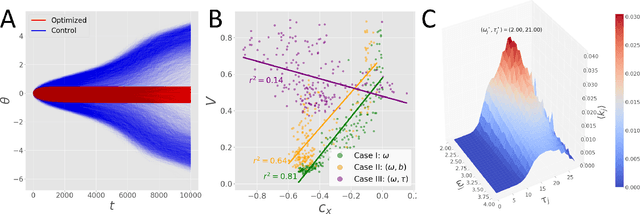
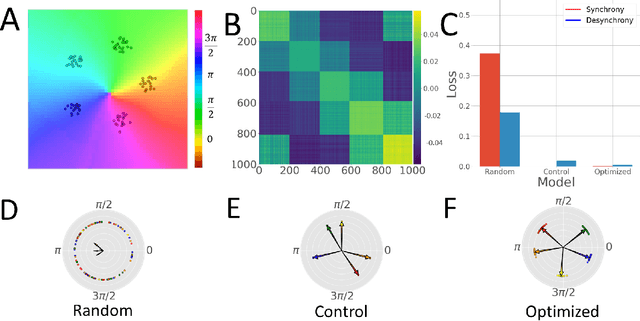

Networks of coupled oscillators are some of the most studied objects in the theory of dynamical systems. Two important areas of current interest are the study of synchrony in highly disordered systems and the modeling of systems with adaptive network structures. Here, we present a single approach to both of these problems in the form of "KuraNet", a deep-learning-based system of coupled oscillators that can learn to synchronize across a distribution of disordered network conditions. The key feature of the model is the replacement of the traditionally static couplings with a coupling function which can learn optimal interactions within heterogeneous oscillator populations. We apply our approach to the eponymous Kuramoto model and demonstrate how KuraNet can learn data-dependent coupling structures that promote either global or cluster synchrony. For example, we show how KuraNet can be used to empirically explore the conditions of global synchrony in analytically impenetrable models with disordered natural frequencies, external field strengths, and interaction delays. In a sequence of cluster synchrony experiments, we further show how KuraNet can function as a data classifier by synchronizing into coherent assemblies. In all cases, we show how KuraNet can generalize to both new data and new network scales, making it easy to work with small systems and form hypotheses about the thermodynamic limit. Our proposed learning-based approach is broadly applicable to arbitrary dynamical systems with wide-ranging relevance to modeling in physics and systems biology.
Iterative VAE as a predictive brain model for out-of-distribution generalization
Dec 01, 2020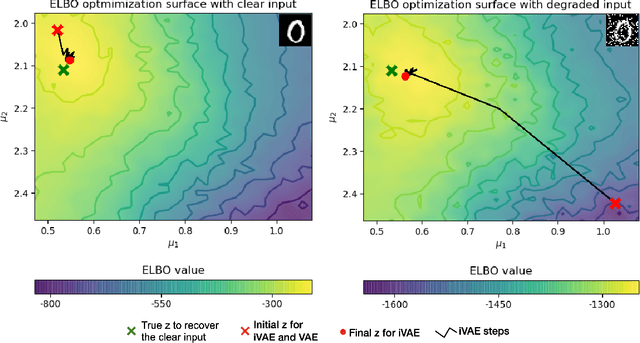
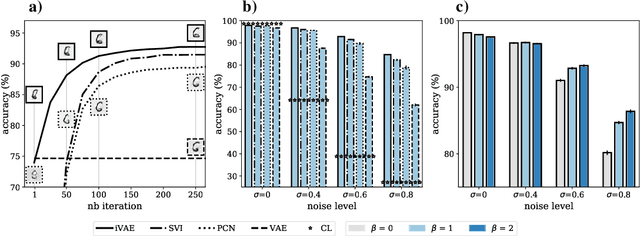
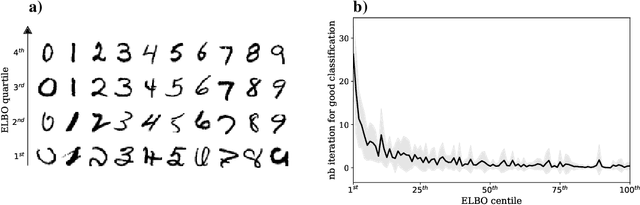
Our ability to generalize beyond training data to novel, out-of-distribution, image degradations is a hallmark of primate vision. The predictive brain, exemplified by predictive coding networks (PCNs), has become a prominent neuroscience theory of neural computation. Motivated by the recent successes of variational autoencoders (VAEs) in machine learning, we rigorously derive a correspondence between PCNs and VAEs. This motivates us to consider iterative extensions of VAEs (iVAEs) as plausible variational extensions of the PCNs. We further demonstrate that iVAEs generalize to distributional shifts significantly better than both PCNs and VAEs. In addition, we propose a novel measure of recognizability for individual samples which can be tested against human psychophysical data. Overall, we hope this work will spur interest in iVAEs as a promising new direction for modeling in neuroscience.
Goal-Directed Behavior under Variational Predictive Coding: Dynamic Organization of Visual Attention and Working Memory
Mar 12, 2019



Mental simulation is a critical cognitive function for goal-directed behavior because it is essential for assessing actions and their consequences. When a self-generated or externally specified goal is given, a sequence of actions that is most likely to attain that goal is selected among other candidates via mental simulation. Therefore, better mental simulation leads to better goal-directed action planning. However, developing a mental simulation model is challenging because it requires knowledge of self and the environment. The current paper studies how adequate goal-directed action plans of robots can be mentally generated by dynamically organizing top-down visual attention and visual working memory. For this purpose, we propose a neural network model based on variational Bayes predictive coding, where goal-directed action planning is formulated by Bayesian inference of latent intentional space. Our experimental results showed that cognitively meaningful competencies, such as autonomous top-down attention to the robot end effector (its hand) as well as dynamic organization of occlusion-free visual working memory, emerged. Furthermore, our analysis of comparative experiments indicated that introduction of visual working memory and the inference mechanism using variational Bayes predictive coding significantly improve the performance in planning adequate goal-directed actions.
Generating Goal-Directed Visuomotor Plans Based on Learning Using a Predictive Coding-type Deep Visuomotor Recurrent Neural Network Model
Jun 05, 2018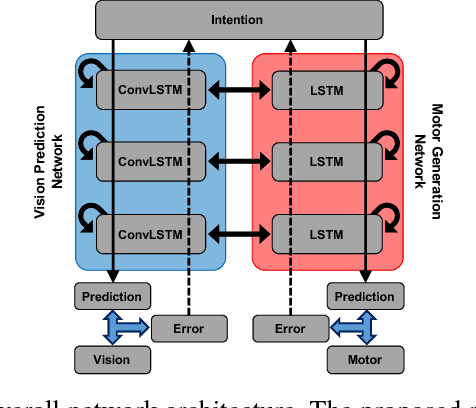


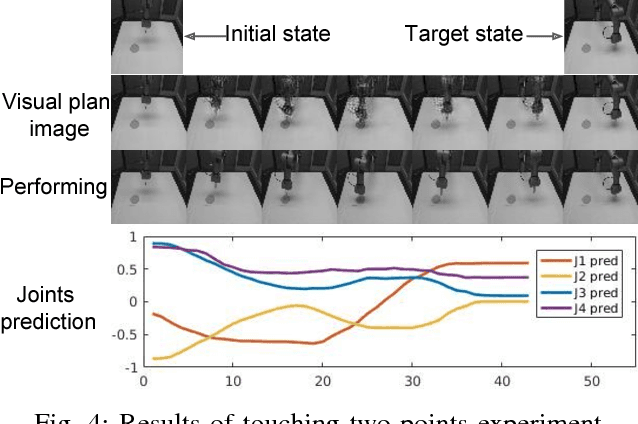
The current paper presents how a predictive coding type deep recurrent neural networks can generate vision-based goal-directed plans based on prior learning experience by examining experiment results using a real arm robot. The proposed deep recurrent neural network learns to predict visuo-proprioceptive sequences by extracting an adequate predictive model from various visuomotor experiences related to object-directed behaviors. The predictive model was developed in terms of mapping from intention state space to expected visuo-proprioceptive sequences space through iterative learning. Our arm robot experiments adopted with three different tasks with different levels of difficulty showed that the error minimization principle in the predictive coding framework applied to inference of the optimal intention states for given goal states can generate goal-directed plans even for unlearned goal states with generalization. It was, however, shown that sufficient generalization requires relatively large number of learning trajectories. The paper discusses possible countermeasure to overcome this problem.
Less-forgetful Learning for Domain Expansion in Deep Neural Networks
Nov 16, 2017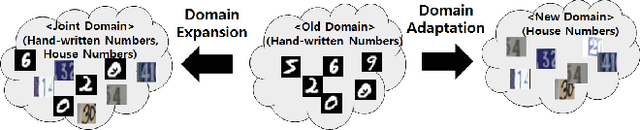

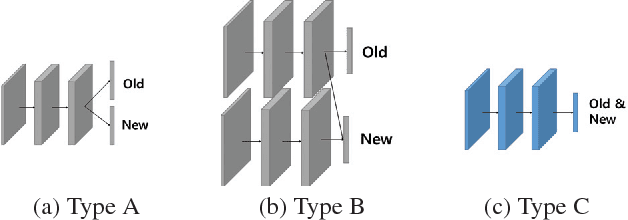
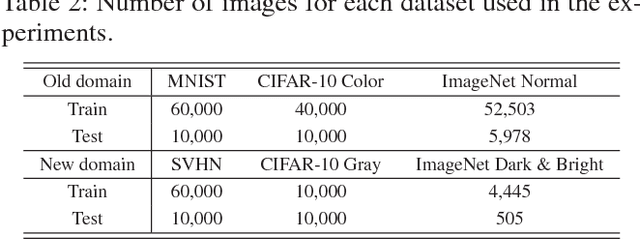
Expanding the domain that deep neural network has already learned without accessing old domain data is a challenging task because deep neural networks forget previously learned information when learning new data from a new domain. In this paper, we propose a less-forgetful learning method for the domain expansion scenario. While existing domain adaptation techniques solely focused on adapting to new domains, the proposed technique focuses on working well with both old and new domains without needing to know whether the input is from the old or new domain. First, we present two naive approaches which will be problematic, then we provide a new method using two proposed properties for less-forgetful learning. Finally, we prove the effectiveness of our method through experiments on image classification tasks. All datasets used in the paper, will be released on our website for someone's follow-up study.
Adaptive Detrending to Accelerate Convolutional Gated Recurrent Unit Training for Contextual Video Recognition
May 24, 2017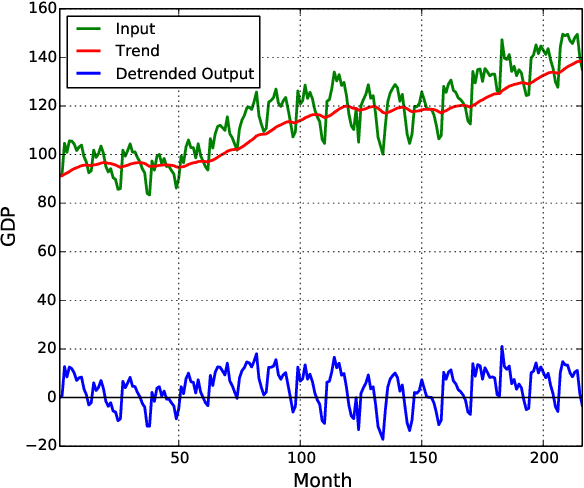
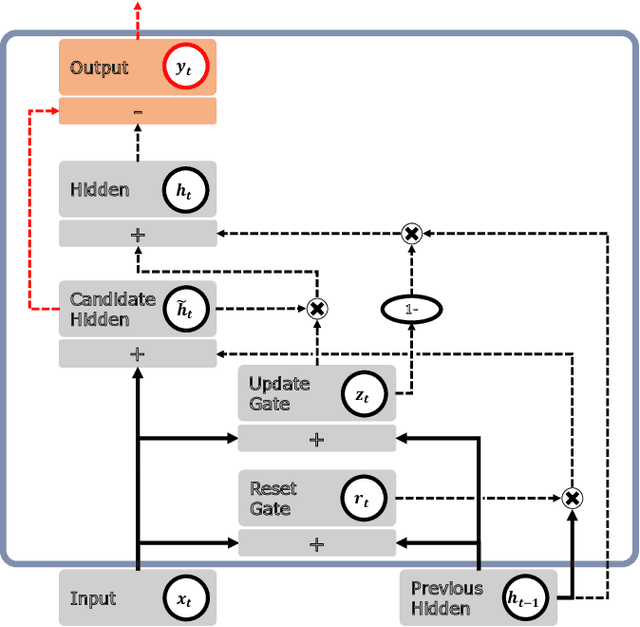
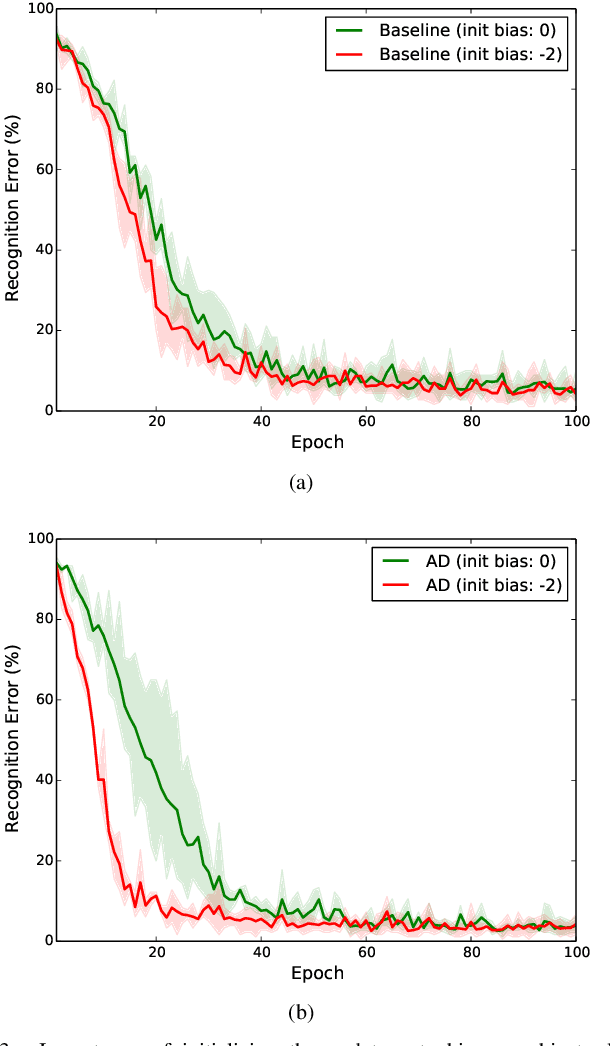
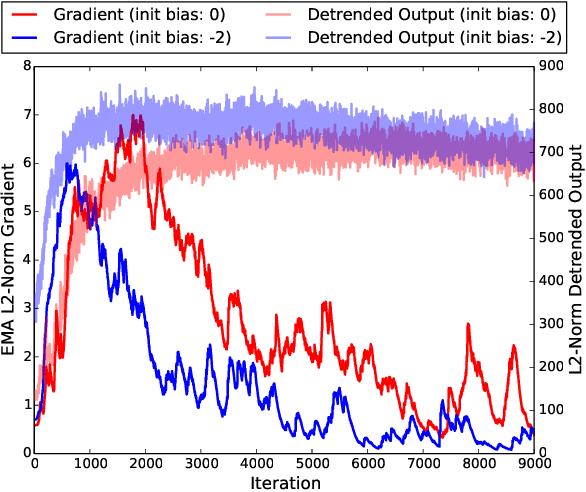
Based on the progress of image recognition, video recognition has been extensively studied recently. However, most of the existing methods are focused on short-term but not long-term video recognition, called contextual video recognition. To address contextual video recognition, we use convolutional recurrent neural networks (ConvRNNs) having a rich spatio-temporal information processing capability, but ConvRNNs requires extensive computation that slows down training. In this paper, inspired by the normalization and detrending methods, we propose adaptive detrending (AD) for temporal normalization in order to accelerate the training of ConvRNNs, especially for convolutional gated recurrent unit (ConvGRU). AD removes internal covariate shift within a sequence of each neuron in recurrent neural networks (RNNs) by subtracting a trend. In the experiments for contextual recognition on ConvGRU, the results show that (1) ConvGRU clearly outperforms the feed-forward neural networks, (2) AD consistently offers a significant training acceleration and generalization improvement, and (3) AD is further improved by collaborating with the existing normalization methods.
Recognition of Visually Perceived Compositional Human Actions by Multiple Spatio-Temporal Scales Recurrent Neural Networks
Feb 22, 2017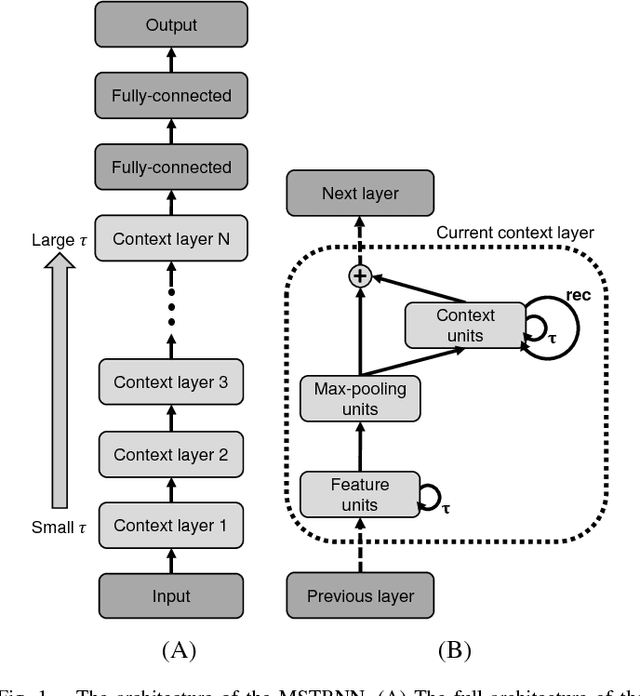
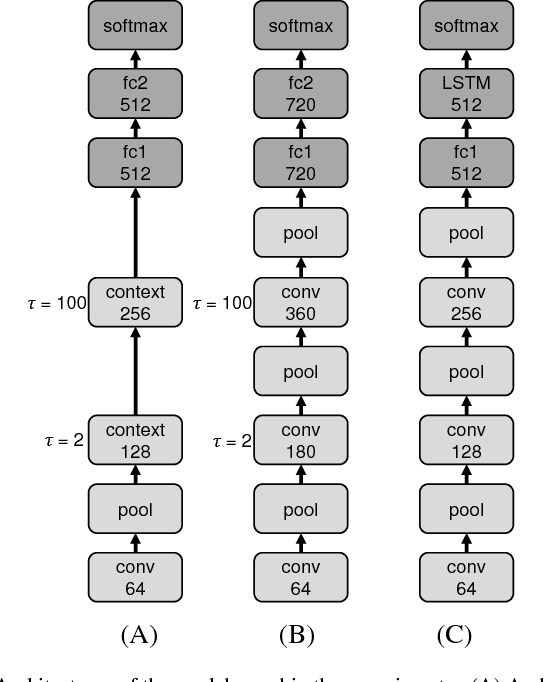

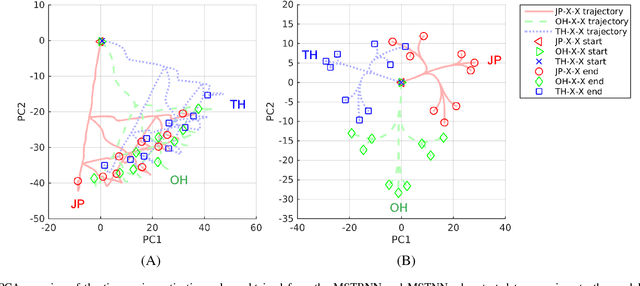
The current paper proposes a novel neural network model for recognizing visually perceived human actions. The proposed multiple spatio-temporal scales recurrent neural network (MSTRNN) model is derived by introducing multiple timescale recurrent dynamics to the conventional convolutional neural network model. One of the essential characteristics of the MSTRNN is that its architecture imposes both spatial and temporal constraints simultaneously on the neural activity which vary in multiple scales among different layers. As suggested by the principle of the upward and downward causation, it is assumed that the network can develop meaningful structures such as functional hierarchy by taking advantage of such constraints during the course of learning. To evaluate the characteristics of the model, the current study uses three types of human action video dataset consisting of different types of primitive actions and different levels of compositionality on them. The performance of the MSTRNN in testing with these dataset is compared with the ones by other representative deep learning models used in the field. The analysis of the internal representation obtained through the learning with the dataset clarifies what sorts of functional hierarchy can be developed by extracting the essential compositionality underlying the dataset.
Less-forgetting Learning in Deep Neural Networks
Jul 01, 2016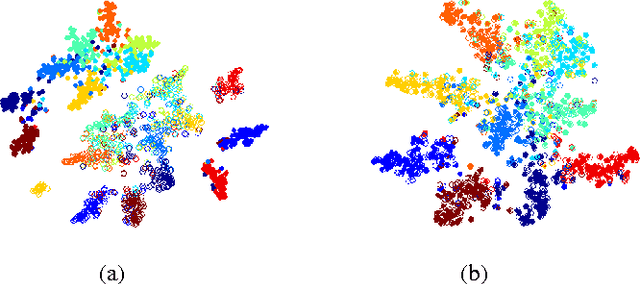
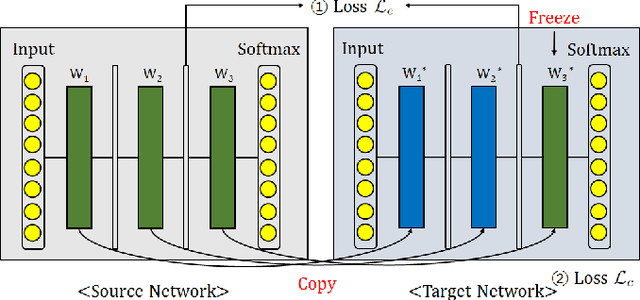
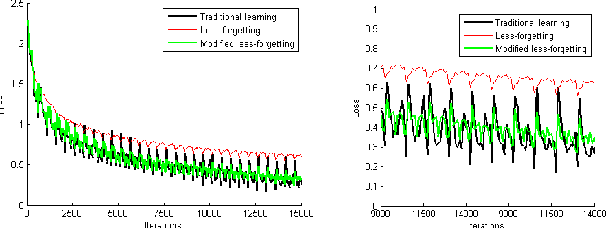
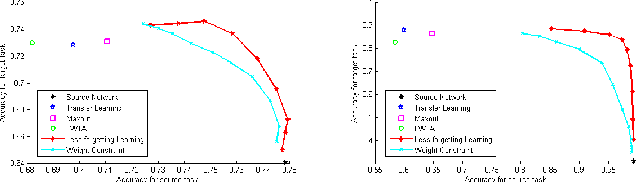
A catastrophic forgetting problem makes deep neural networks forget the previously learned information, when learning data collected in new environments, such as by different sensors or in different light conditions. This paper presents a new method for alleviating the catastrophic forgetting problem. Unlike previous research, our method does not use any information from the source domain. Surprisingly, our method is very effective to forget less of the information in the source domain, and we show the effectiveness of our method using several experiments. Furthermore, we observed that the forgetting problem occurs between mini-batches when performing general training processes using stochastic gradient descent methods, and this problem is one of the factors that degrades generalization performance of the network. We also try to solve this problem using the proposed method. Finally, we show our less-forgetting learning method is also helpful to improve the performance of deep neural networks in terms of recognition rates.
Achieving Synergy in Cognitive Behavior of Humanoids via Deep Learning of Dynamic Visuo-Motor-Attentional Coordination
Jul 09, 2015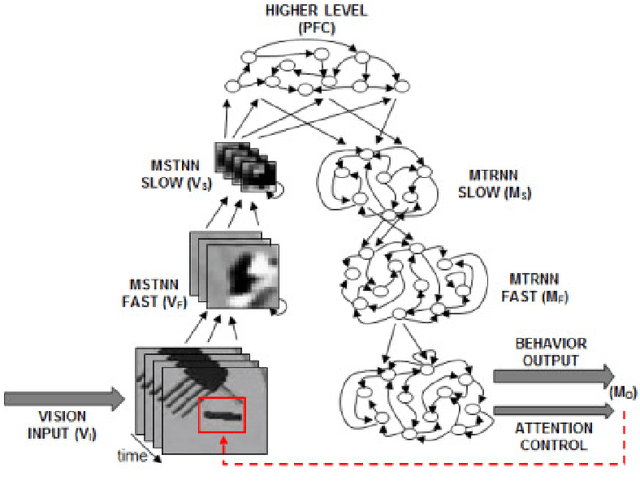
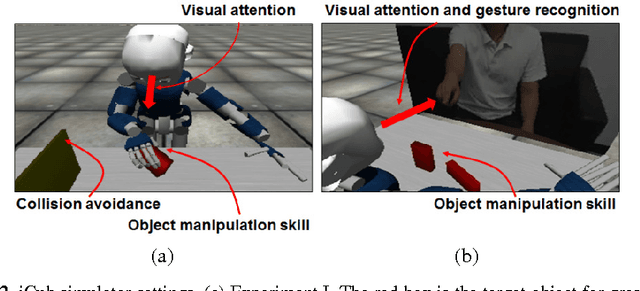

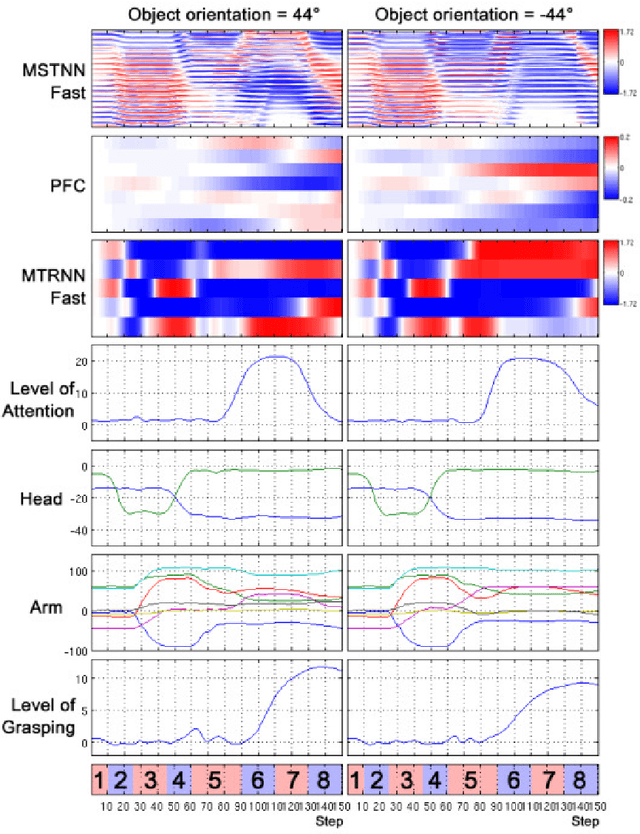
The current study examines how adequate coordination among different cognitive processes including visual recognition, attention switching, action preparation and generation can be developed via learning of robots by introducing a novel model, the Visuo-Motor Deep Dynamic Neural Network (VMDNN). The proposed model is built on coupling of a dynamic vision network, a motor generation network, and a higher level network allocated on top of these two. The simulation experiments using the iCub simulator were conducted for cognitive tasks including visual object manipulation responding to human gestures. The results showed that synergetic coordination can be developed via iterative learning through the whole network when spatio-temporal hierarchy and temporal one can be self-organized in the visual pathway and in the motor pathway, respectively, such that the higher level can manipulate them with abstraction.