 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerfect Clustering for Stochastic Blockmodel Graphs via Adjacency Spectral Embedding
Jan 15, 2015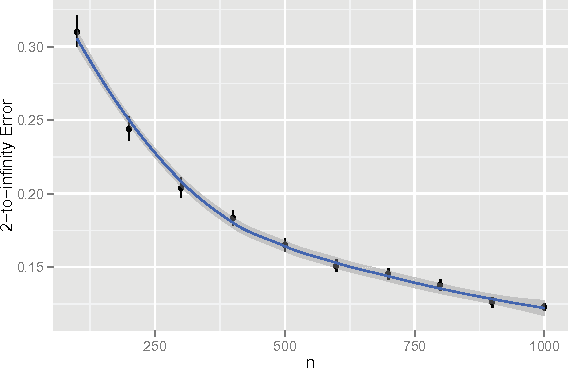
Vertex clustering in a stochastic blockmodel graph has wide applicability and has been the subject of extensive research. In thispaper, we provide a short proof that the adjacency spectral embedding can be used to obtain perfect clustering for the stochastic blockmodel and the degree-corrected stochastic blockmodel. We also show an analogous result for the more general random dot product graph model.
* 22 pages, including references; 2 figures
Statistical inference on errorfully observed graphs
Jul 21, 2014Statistical inference on graphs is a burgeoning field in the applied and theoretical statistics communities, as well as throughout the wider world of science, engineering, business, etc. In many applications, we are faced with the reality of errorfully observed graphs. That is, the existence of an edge between two vertices is based on some imperfect assessment. In this paper, we consider a graph $G = (V,E)$. We wish to perform an inference task -- the inference task considered here is "vertex classification". However, we do not observe $G$; rather, for each potential edge $uv \in {{V}\choose{2}}$ we observe an "edge-feature" which we use to classify $uv$ as edge/not-edge. Thus we errorfully observe $G$ when we observe the graph $\widetilde{G} = (V,\widetilde{E})$ as the edges in $\widetilde{E}$ arise from the classifications of the "edge-features", and are expected to be errorful. Moreover, we face a quantity/quality trade-off regarding the edge-features we observe -- more informative edge-features are more expensive, and hence the number of potential edges that can be assessed decreases with the quality of the edge-features. We studied this problem by formulating a quantity/quality tradeoff for a simple class of random graphs model, namely the stochastic blockmodel. We then consider a simple but optimal vertex classifier for classifying $v$ and we derive the optimal quantity/quality operating point for subsequent graph inference in the face of this trade-off. The optimal operating points for the quantity/quality trade-off are surprising and illustrate the issue that methods for intermediate tasks should be chosen to maximize performance for the ultimate inference task. Finally, we investigate the quantity/quality tradeoff for errorful obesrvations of the {\it C.\ elegans} connectome graph.
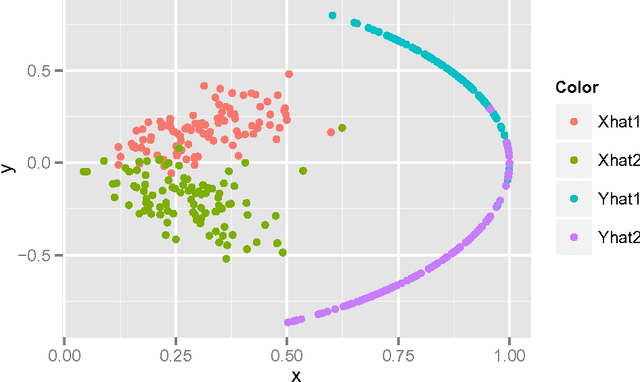
Generalized Canonical Correlation Analysis for Classification
Jun 26, 2014
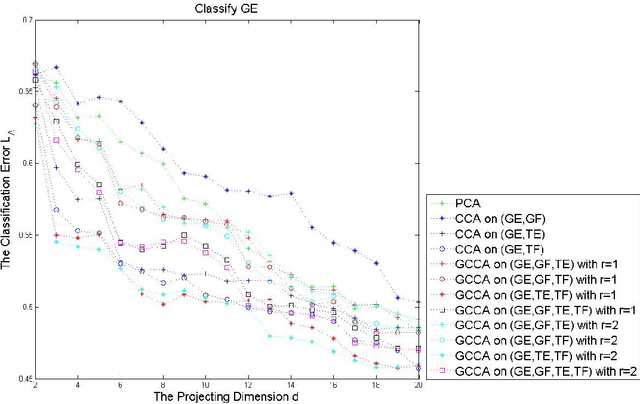

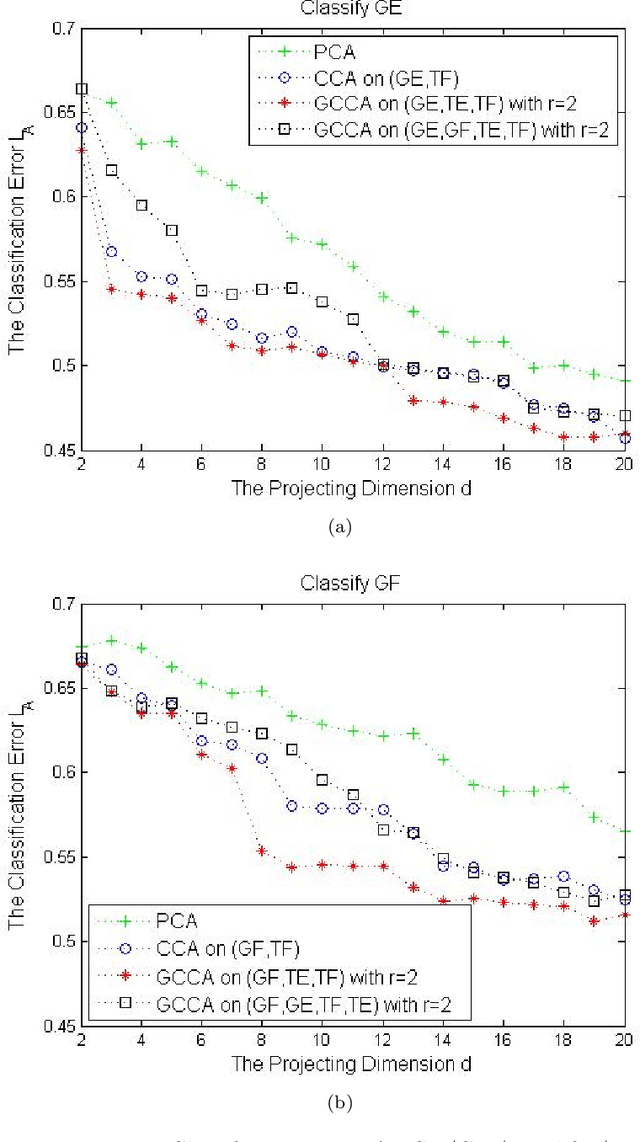
For multiple multivariate data sets, we derive conditions under which Generalized Canonical Correlation Analysis (GCCA) improves classification performance of the projected datasets, compared to standard Canonical Correlation Analysis (CCA) using only two data sets. We illustrate our theoretical results with simulations and a real data experiment.
* 28 pages, 3 figures, 7 tables
A central limit theorem for scaled eigenvectors of random dot product graphs
Dec 23, 2013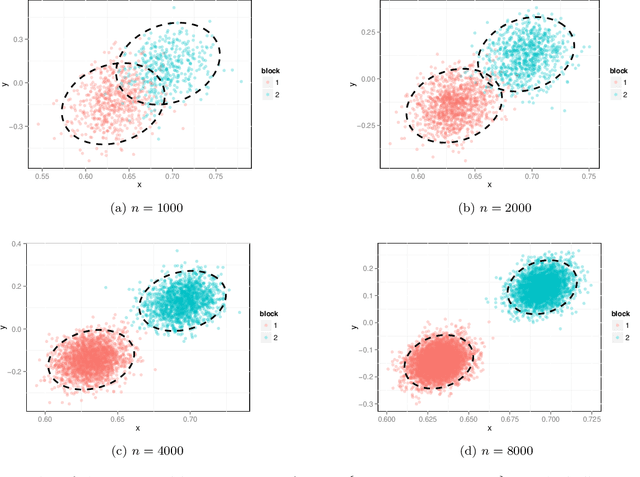
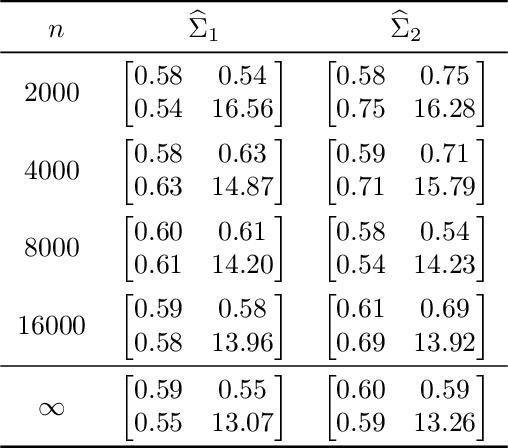
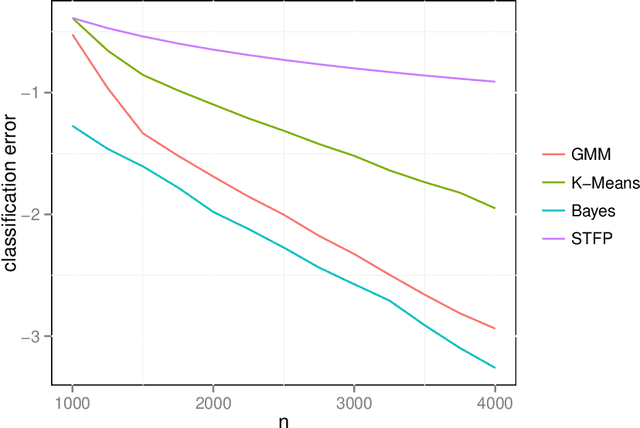
We prove a central limit theorem for the components of the largest eigenvectors of the adjacency matrix of a finite-dimensional random dot product graph whose true latent positions are unknown. In particular, we follow the methodology outlined in \citet{sussman2012universally} to construct consistent estimates for the latent positions, and we show that the appropriately scaled differences between the estimated and true latent positions converge to a mixture of Gaussian random variables. As a corollary, we obtain a central limit theorem for the first eigenvector of the adjacency matrix of an Erd\"os-Renyi random graph.
Universally consistent vertex classification for latent positions graphs
Aug 13, 2013In this work we show that, using the eigen-decomposition of the adjacency matrix, we can consistently estimate feature maps for latent position graphs with positive definite link function $\kappa$, provided that the latent positions are i.i.d. from some distribution F. We then consider the exploitation task of vertex classification where the link function $\kappa$ belongs to the class of universal kernels and class labels are observed for a number of vertices tending to infinity and that the remaining vertices are to be classified. We show that minimization of the empirical $\varphi$-risk for some convex surrogate $\varphi$ of 0-1 loss over a class of linear classifiers with increasing complexities yields a universally consistent classifier, that is, a classification rule with error converging to Bayes optimal for any distribution F.
* Published in at http://dx.doi.org/10.1214/13-AOS1112 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Out-of-sample Extension for Latent Position Graphs
May 21, 2013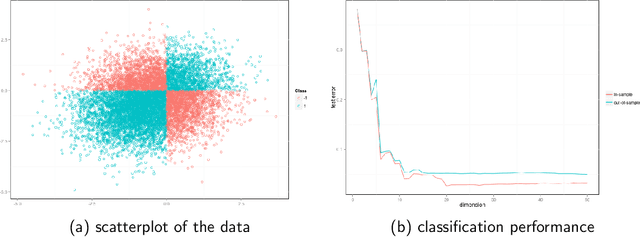
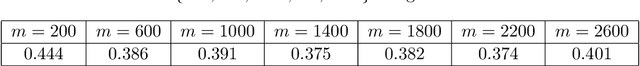
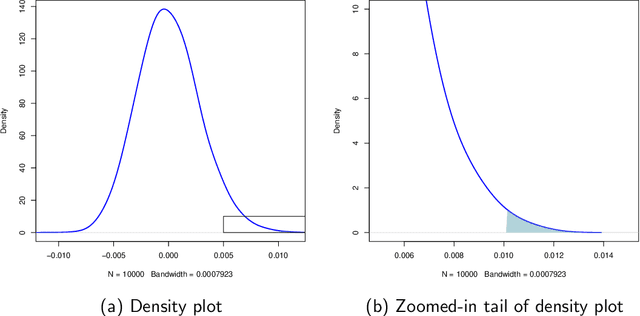
We consider the problem of vertex classification for graphs constructed from the latent position model. It was shown previously that the approach of embedding the graphs into some Euclidean space followed by classification in that space can yields a universally consistent vertex classifier. However, a major technical difficulty of the approach arises when classifying unlabeled out-of-sample vertices without including them in the embedding stage. In this paper, we studied the out-of-sample extension for the graph embedding step and its impact on the subsequent inference tasks. We show that, under the latent position graph model and for sufficiently large $n$, the mapping of the out-of-sample vertices is close to its true latent position. We then demonstrate that successful inference for the out-of-sample vertices is possible.
On latent position inference from doubly stochastic messaging activities
Apr 25, 2013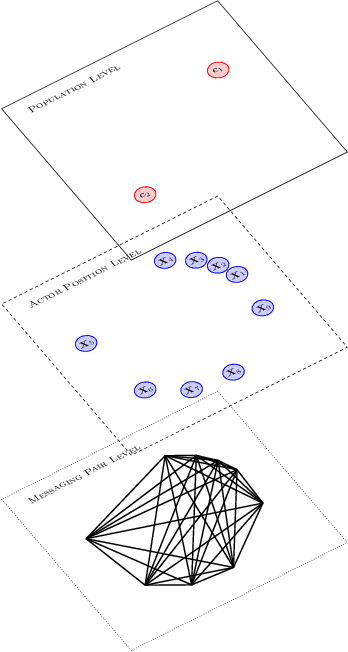
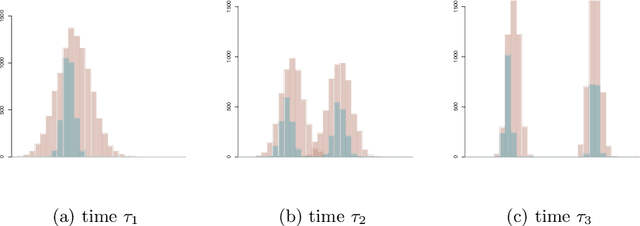
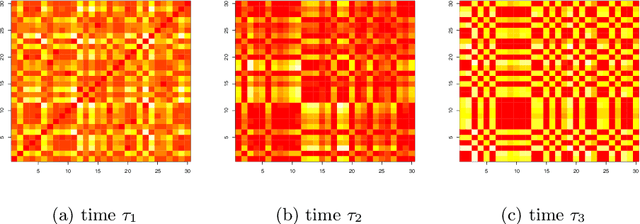
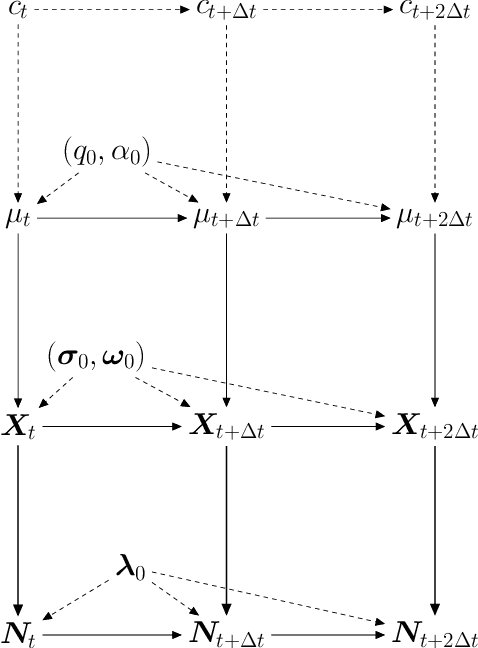
We model messaging activities as a hierarchical doubly stochastic point process with three main levels, and develop an iterative algorithm for inferring actors' relative latent positions from a stream of messaging activity data. Each of the message-exchanging actors is modeled as a process in a latent space. The actors' latent positions are assumed to be influenced by the distribution of a much larger population over the latent space. Each actor's movement in the latent space is modeled as being governed by two parameters that we call confidence and visibility, in addition to dependence on the population distribution. The messaging frequency between a pair of actors is assumed to be inversely proportional to the distance between their latent positions. Our inference algorithm is based on a projection approach to an online filtering problem. The algorithm associates each actor with a probability density-valued process, and each probability density is assumed to be a mixture of basis functions. For efficient numerical experiments, we further develop our algorithm for the case where the basis functions are obtained by translating and scaling a standard Gaussian density.
Generalized Canonical Correlation Analysis for Disparate Data Fusion
Sep 17, 2012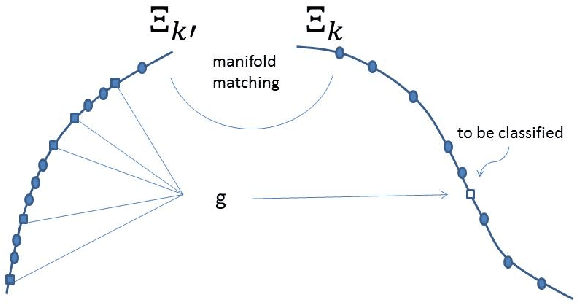
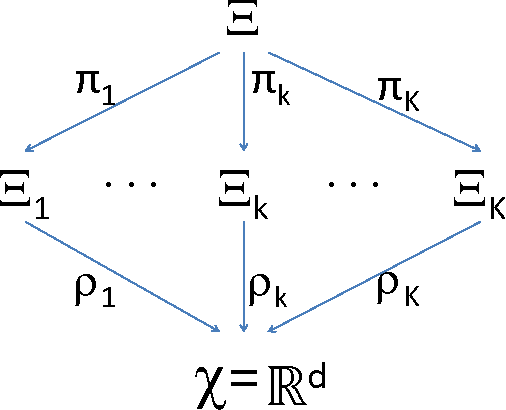
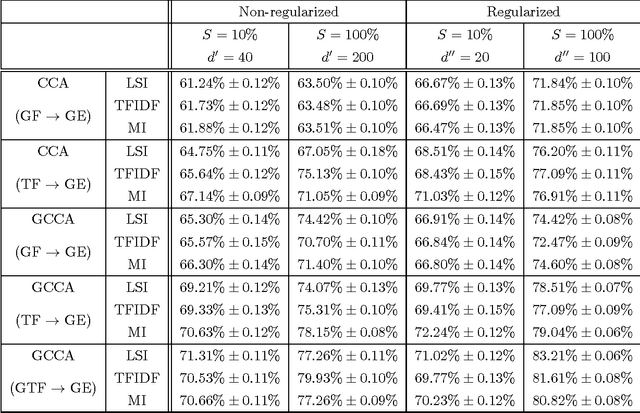
Manifold matching works to identify embeddings of multiple disparate data spaces into the same low-dimensional space, where joint inference can be pursued. It is an enabling methodology for fusion and inference from multiple and massive disparate data sources. In this paper we focus on a method called Canonical Correlation Analysis (CCA) and its generalization Generalized Canonical Correlation Analysis (GCCA), which belong to the more general Reduced Rank Regression (RRR) framework. We present an efficiency investigation of CCA and GCCA under different training conditions for a particular text document classification task.
Universally Consistent Latent Position Estimation and Vertex Classification for Random Dot Product Graphs
Jul 29, 2012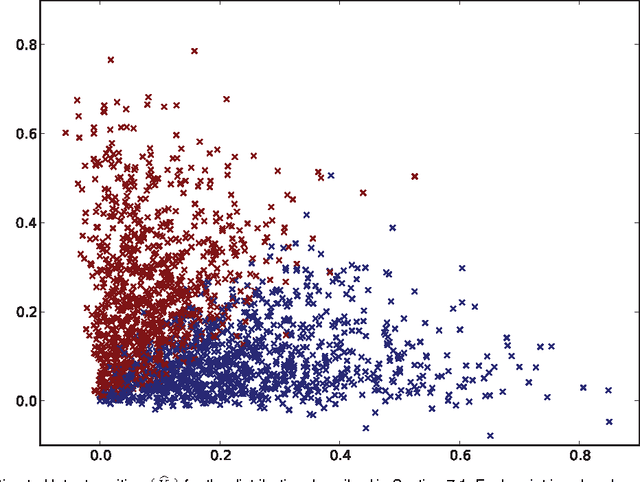
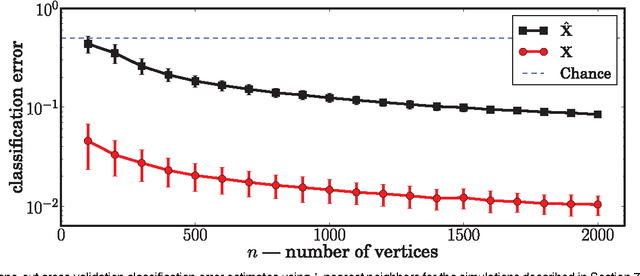
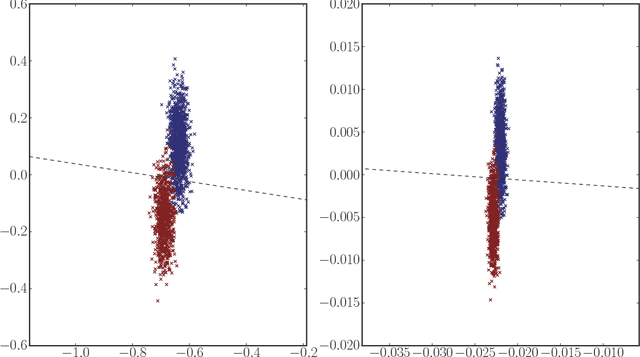
In this work we show that, using the eigen-decomposition of the adjacency matrix, we can consistently estimate latent positions for random dot product graphs provided the latent positions are i.i.d. from some distribution. If class labels are observed for a number of vertices tending to infinity, then we show that the remaining vertices can be classified with error converging to Bayes optimal using the $k$-nearest-neighbors classification rule. We evaluate the proposed methods on simulated data and a graph derived from Wikipedia.
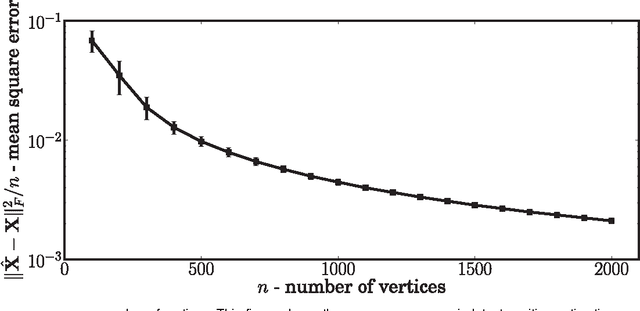
A consistent adjacency spectral embedding for stochastic blockmodel graphs
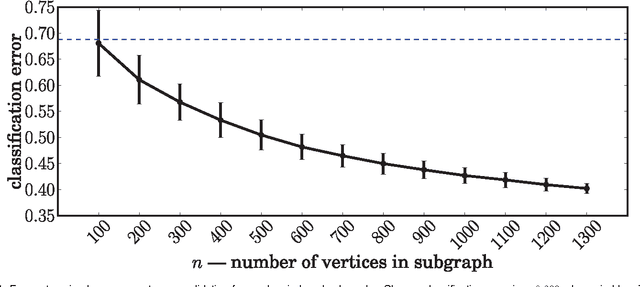
Apr 27, 2012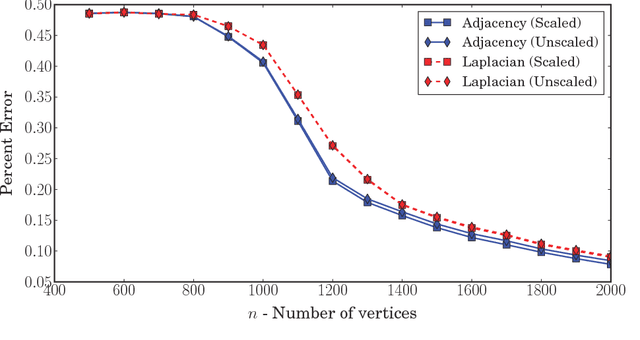

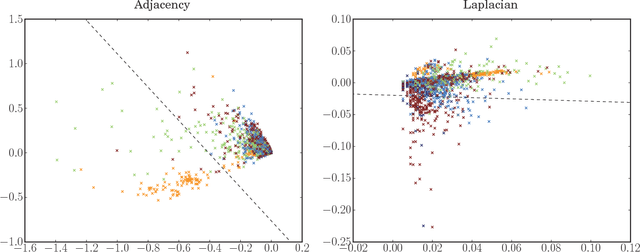
We present a method to estimate block membership of nodes in a random graph generated by a stochastic blockmodel. We use an embedding procedure motivated by the random dot product graph model, a particular example of the latent position model. The embedding associates each node with a vector; these vectors are clustered via minimization of a square error criterion. We prove that this method is consistent for assigning nodes to blocks, as only a negligible number of nodes will be mis-assigned. We prove consistency of the method for directed and undirected graphs. The consistent block assignment makes possible consistent parameter estimation for a stochastic blockmodel. We extend the result in the setting where the number of blocks grows slowly with the number of nodes. Our method is also computationally feasible even for very large graphs. We compare our method to Laplacian spectral clustering through analysis of simulated data and a graph derived from Wikipedia documents.