 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrystaL: Spontaneous Emergence of Visual Latents in MLLMs
Feb 24, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable performance by integrating powerful language backbones with large-scale visual encoders. Among these, latent Chain-of-Thought (CoT) methods enable implicit reasoning in continuous hidden states, facilitating seamless vision-language integration and faster inference. However, existing heuristically predefined supervision signals in latent CoT provide limited guidance for preserving critical visual information in intermediate latent states. To address this limitation, we propose CrystaL (Crystallized Latent Reasoning), a single-stage framework with two paths to process intact and corrupted images, respectively. By explicitly aligning the attention patterns and prediction distributions across the two paths, CrystaL crystallizes latent representations into task-relevant visual semantics, without relying on auxiliary annotations or external modules. Extensive experiments on perception-intensive benchmarks demonstrate that CrystaL consistently outperforms state-of-the-art baselines, achieving substantial gains in fine-grained visual understanding while maintaining robust reasoning capabilities.
Decoupled Spatial Temporal Graphs for Generic Visual Grounding
Mar 18, 2021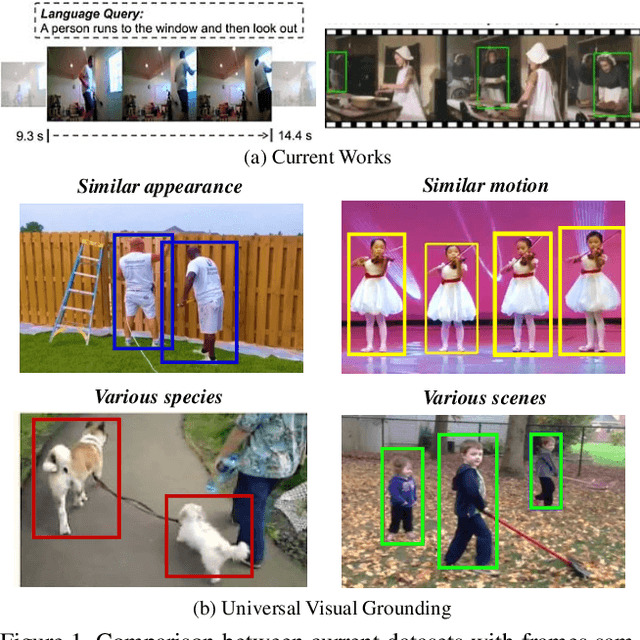



Visual grounding is a long-lasting problem in vision-language understanding due to its diversity and complexity. Current practices concentrate mostly on performing visual grounding in still images or well-trimmed video clips. This work, on the other hand, investigates into a more general setting, generic visual grounding, aiming to mine all the objects satisfying the given expression, which is more challenging yet practical in real-world scenarios. Importantly, grounding results are expected to accurately localize targets in both space and time. Whereas, it is tricky to make trade-offs between the appearance and motion features. In real scenarios, model tends to fail in distinguishing distractors with similar attributes. Motivated by these considerations, we propose a simple yet effective approach, named DSTG, which commits to 1) decomposing the spatial and temporal representations to collect all-sided cues for precise grounding; 2) enhancing the discriminativeness from distractors and the temporal consistency with a contrastive learning routing strategy. We further elaborate a new video dataset, GVG, that consists of challenging referring cases with far-ranging videos. Empirical experiments well demonstrate the superiority of DSTG over state-of-the-art on Charades-STA, ActivityNet-Caption and GVG datasets. Code and dataset will be made available.