 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Complementary&Competitive Influence Maximization with Concurrent Ally-Boosting and Rival-Preventing
Feb 19, 2023



In this paper, we propose a new influence spread model, namely, Complementary\&Competitive Independent Cascade (C$^2$IC) model. C$^2$IC model generalizes three well known influence model, i.e., influence boosting (IB) model, campaign oblivious (CO)IC model and the IC-N (IC model with negative opinions) model. This is the first model that considers both complementary and competitive influence spread comprehensively under multi-agent environment. Correspondingly, we propose the Complementary\&Competitive influence maximization (C$^2$IM) problem. Given an ally seed set and a rival seed set, the C$^2$IM problem aims to select a set of assistant nodes that can boost the ally spread and prevent the rival spread concurrently. We show the problem is NP-hard and can generalize the influence boosting problem and the influence blocking problem. With classifying the different cascade priorities into 4 cases by the monotonicity and submodularity (M\&S) holding conditions, we design 4 algorithms respectively, with theoretical approximation bounds provided. We conduct extensive experiments on real social networks and the experimental results demonstrate the effectiveness of the proposed algorithms. We hope this work can inspire abundant future exploration for constructing more generalized influence models that help streamline the works of this area.
Deep Learning-Based Rate-Splitting Multiple Access for Reconfigurable Intelligent Surface-Aided Tera-Hertz Massive MIMO
Sep 18, 2022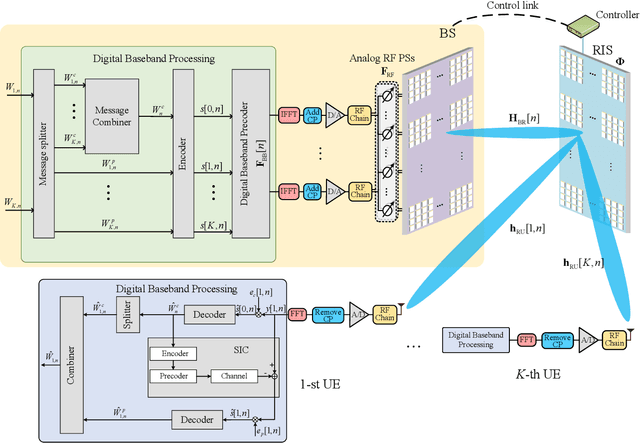
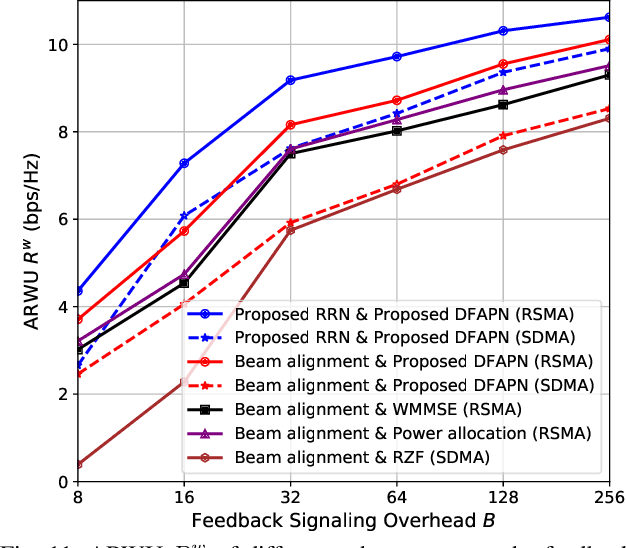
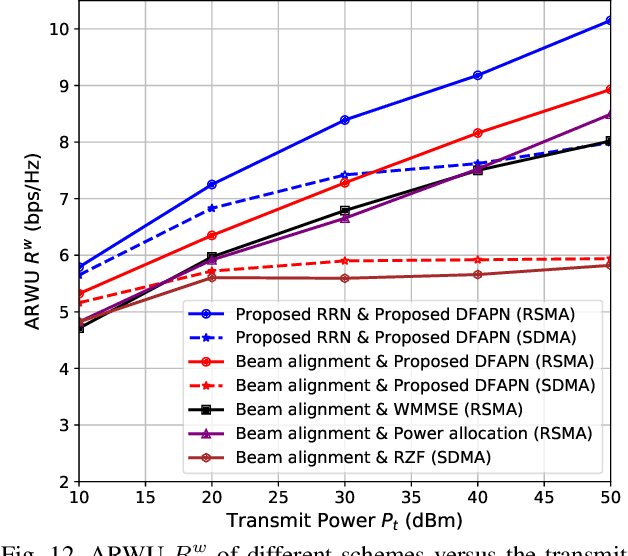

Reconfigurable intelligent surface (RIS) can significantly enhance the service coverage of Tera-Hertz massive multiple-input multiple-output (MIMO) communication systems. However, obtaining accurate high-dimensional channel state information (CSI) with limited pilot and feedback signaling overhead is challenging, severely degrading the performance of conventional spatial division multiple access. To improve the robustness against CSI imperfection, this paper proposes a deep learning (DL)-based rate-splitting multiple access (RSMA) scheme for RIS-aided Tera-Hertz multi-user MIMO systems. Specifically, we first propose a hybrid data-model driven DL-based RSMA precoding scheme, including the passive precoding at the RIS as well as the analog active precoding and the RSMA digital active precoding at the base station (BS). To realize the passive precoding at the RIS, we propose a Transformer-based data-driven RIS reflecting network (RRN). As for the analog active precoding at the BS, we propose a match-filter based analog precoding scheme considering that the BS and RIS adopt the LoS-MIMO antenna array architecture. As for the RSMA digital active precoding at the BS, we propose a low-complexity approximate weighted minimum mean square error (AWMMSE) digital precoding scheme. Furthermore, for better precoding performance as well as lower computational complexity, a model-driven deep unfolding active precoding network (DFAPN) is also designed by combining the proposed AWMMSE scheme with DL. Then, to acquire accurate CSI at the BS for the investigated RSMA precoding scheme to achieve higher spectral efficiency, we propose a CSI acquisition network (CAN) with low pilot and feedback signaling overhead, where the downlink pilot transmission, CSI feedback at the user equipments (UEs), and CSI reconstruction at the BS are modeled as an end-to-end neural network based on Transformer.
ProtoPFormer: Concentrating on Prototypical Parts in Vision Transformers for Interpretable Image Recognition
Aug 22, 2022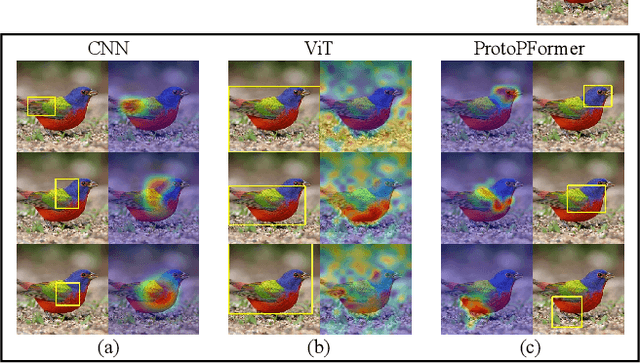
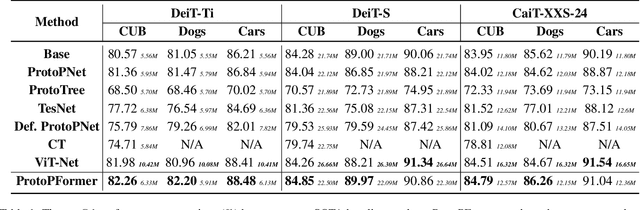
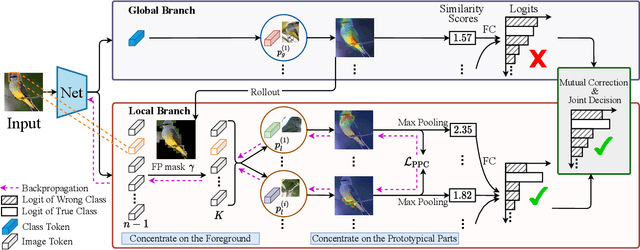
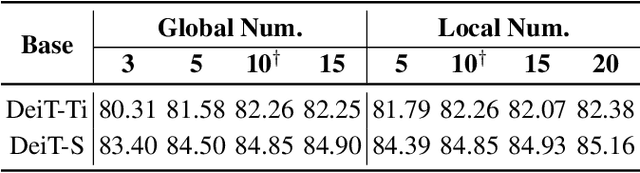
Prototypical part network (ProtoPNet) has drawn wide attention and boosted many follow-up studies due to its self-explanatory property for explainable artificial intelligence (XAI). However, when directly applying ProtoPNet on vision transformer (ViT) backbones, learned prototypes have a ''distraction'' problem: they have a relatively high probability of being activated by the background and pay less attention to the foreground. The powerful capability of modeling long-term dependency makes the transformer-based ProtoPNet hard to focus on prototypical parts, thus severely impairing its inherent interpretability. This paper proposes prototypical part transformer (ProtoPFormer) for appropriately and effectively applying the prototype-based method with ViTs for interpretable image recognition. The proposed method introduces global and local prototypes for capturing and highlighting the representative holistic and partial features of targets according to the architectural characteristics of ViTs. The global prototypes are adopted to provide the global view of objects to guide local prototypes to concentrate on the foreground while eliminating the influence of the background. Afterwards, local prototypes are explicitly supervised to concentrate on their respective prototypical visual parts, increasing the overall interpretability. Extensive experiments demonstrate that our proposed global and local prototypes can mutually correct each other and jointly make final decisions, which faithfully and transparently reason the decision-making processes associatively from the whole and local perspectives, respectively. Moreover, ProtoPFormer consistently achieves superior performance and visualization results over the state-of-the-art (SOTA) prototype-based baselines. Our code has been released at https://github.com/zju-vipa/ProtoPFormer.
Modeling Price Elasticity for Occupancy Prediction in Hotel Dynamic Pricing
Aug 11, 2022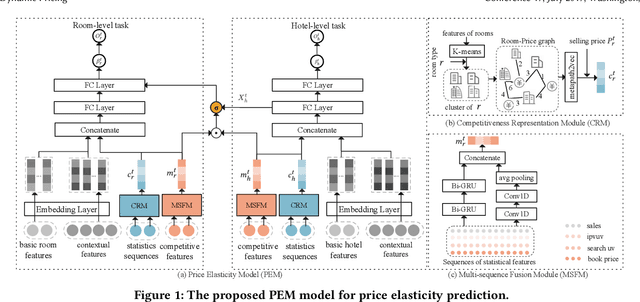
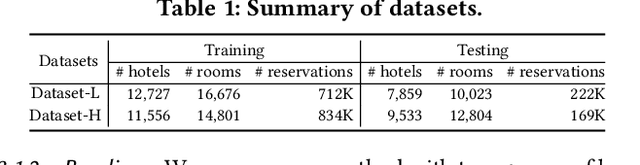
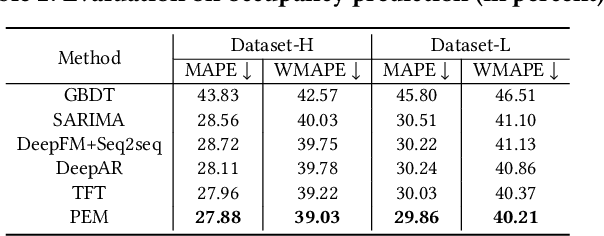

Demand estimation plays an important role in dynamic pricing where the optimal price can be obtained via maximizing the revenue based on the demand curve. In online hotel booking platform, the demand or occupancy of rooms varies across room-types and changes over time, and thus it is challenging to get an accurate occupancy estimate. In this paper, we propose a novel hotel demand function that explicitly models the price elasticity of demand for occupancy prediction, and design a price elasticity prediction model to learn the dynamic price elasticity coefficient from a variety of affecting factors. Our model is composed of carefully designed elasticity learning modules to alleviate the endogeneity problem, and trained in a multi-task framework to tackle the data sparseness. We conduct comprehensive experiments on real-world datasets and validate the superiority of our method over the state-of-the-art baselines for both occupancy prediction and dynamic pricing.
Improving Mandarin Speech Recogntion with Block-augmented Transformer
Jul 24, 2022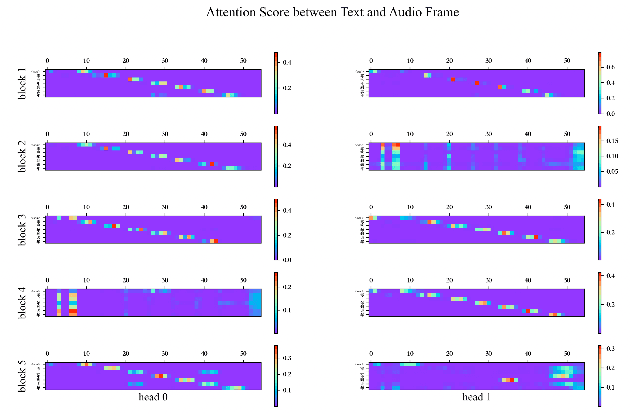
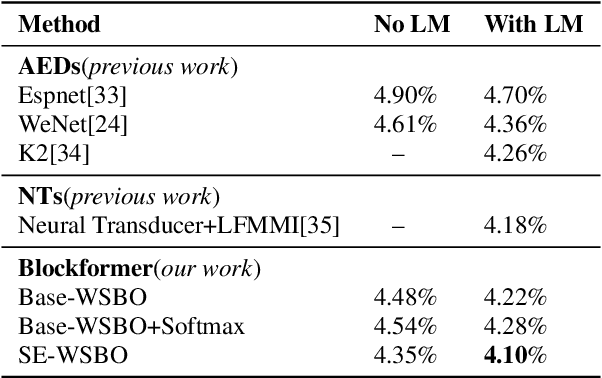
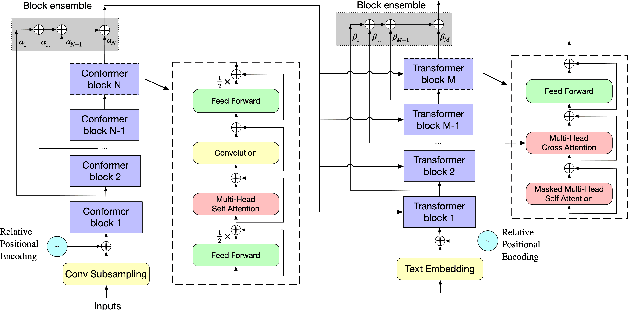

Recently Convolution-augmented Transformer (Conformer) has shown promising results in Automatic Speech Recognition (ASR), outperforming the previous best published Transformer Transducer. In this work, we believe that the output information of each block in the encoder and decoder is not completely inclusive, in other words, their output information may be complementary. We study how to take advantage of the complementary information of each block in a parameter-efficient way, and it is expected that this may lead to more robust performance. Therefore we propose the Block-augmented Transformer for speech recognition, named Blockformer. We have implemented two block ensemble methods: the base Weighted Sum of the Blocks Output (Base-WSBO), and the Squeeze-and-Excitation module to Weighted Sum of the Blocks Output (SE-WSBO). Experiments have proved that the Blockformer significantly outperforms the state-of-the-art Conformer-based models on AISHELL-1, our model achieves a CER of 4.35\% without using a language model and 4.10\% with an external language model on the testset.
Memory-Guided Multi-View Multi-Domain Fake News Detection
Jun 26, 2022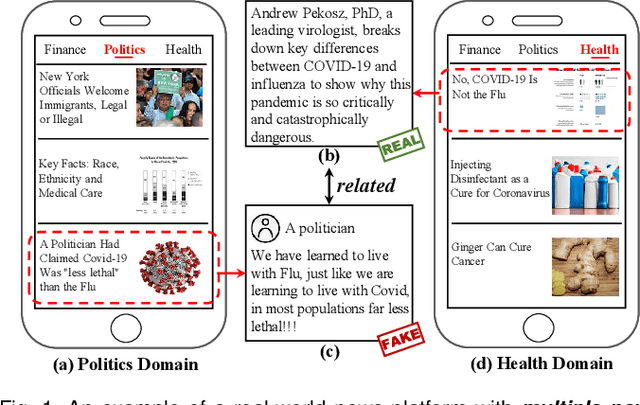
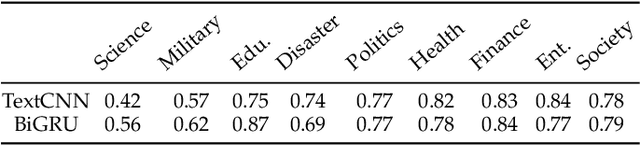
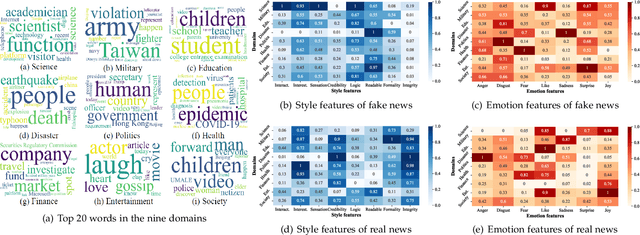
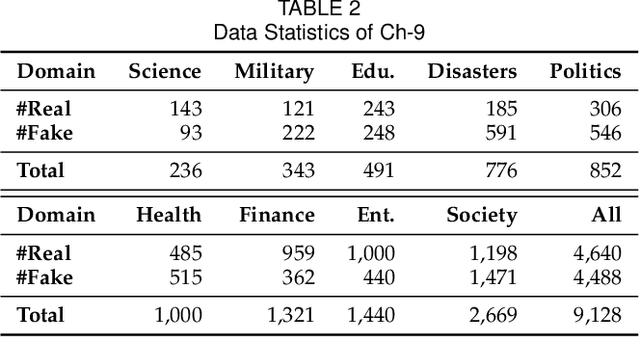
The wide spread of fake news is increasingly threatening both individuals and society. Great efforts have been made for automatic fake news detection on a single domain (e.g., politics). However, correlations exist commonly across multiple news domains, and thus it is promising to simultaneously detect fake news of multiple domains. Based on our analysis, we pose two challenges in multi-domain fake news detection: 1) domain shift, caused by the discrepancy among domains in terms of words, emotions, styles, etc. 2) domain labeling incompleteness, stemming from the real-world categorization that only outputs one single domain label, regardless of topic diversity of a news piece. In this paper, we propose a Memory-guided Multi-view Multi-domain Fake News Detection Framework (M$^3$FEND) to address these two challenges. We model news pieces from a multi-view perspective, including semantics, emotion, and style. Specifically, we propose a Domain Memory Bank to enrich domain information which could discover potential domain labels based on seen news pieces and model domain characteristics. Then, with enriched domain information as input, a Domain Adapter could adaptively aggregate discriminative information from multiple views for news in various domains. Extensive offline experiments on English and Chinese datasets demonstrate the effectiveness of M$^3$FEND, and online tests verify its superiority in practice. Our code is available at https://github.com/ICTMCG/M3FEND.
Adaptively Re-weighting Multi-Loss Untrained Transformer for Sparse-View Cone-Beam CT Reconstruction
Mar 23, 2022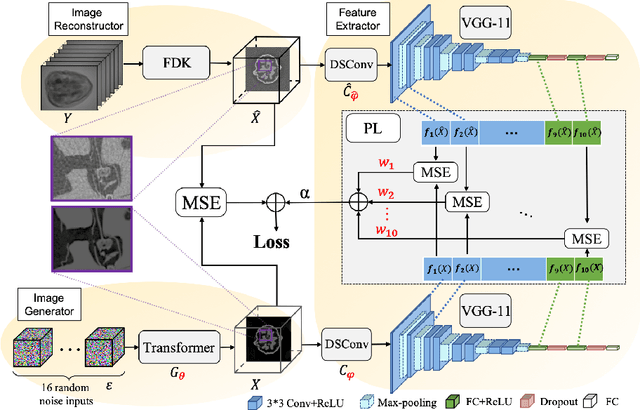
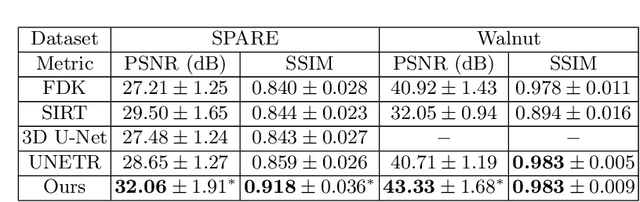
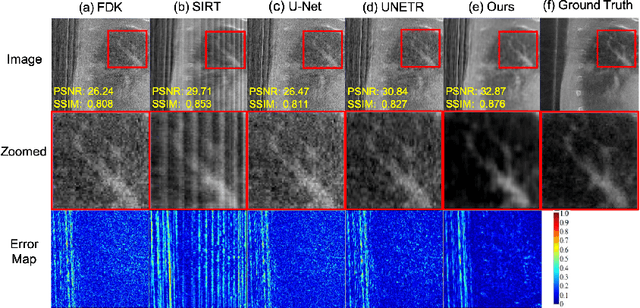
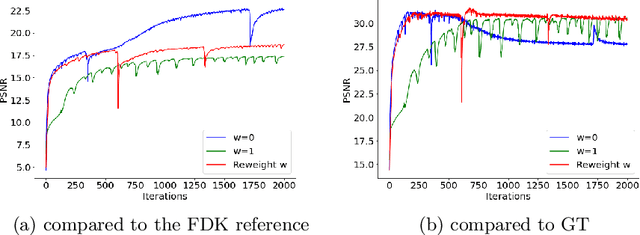
Cone-Beam Computed Tomography (CBCT) has been proven useful in diagnosis, but how to shorten scanning time with lower radiation dosage and how to efficiently reconstruct 3D image remain as the main issues for clinical practice. The recent development of tomographic image reconstruction on sparse-view measurements employs deep neural networks in a supervised way to tackle such issues, whereas the success of model training requires quantity and quality of the given paired measurements/images. We propose a novel untrained Transformer to fit the CBCT inverse solver without training data. It is mainly comprised of an untrained 3D Transformer of billions of network weights and a multi-level loss function with variable weights. Unlike conventional deep neural networks (DNNs), there is no requirement of training steps in our approach. Upon observing the hardship of optimising Transformer, the variable weights within the loss function are designed to automatically update together with the iteration process, ultimately stabilising its optimisation. We evaluate the proposed approach on two publicly available datasets: SPARE and Walnut. The results show a significant performance improvement on image quality metrics with streak artefact reduction in the visualisation. We also provide a clinical report by an experienced radiologist to assess our reconstructed images in a diagnosis point of view. The source code and the optimised models are available from the corresponding author on request at the moment.
How human-robot collaboration impacts construction productivity: an agent-based multi-fidelity modeling approach
Mar 04, 2022
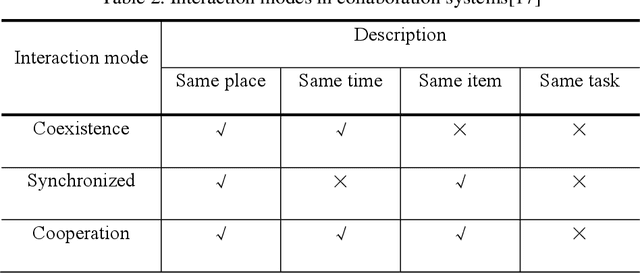
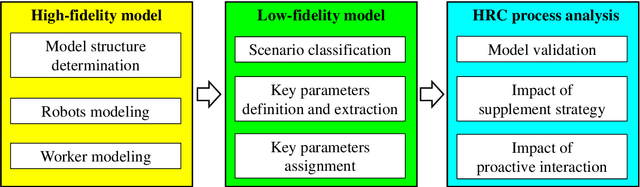
Though construction robots have drawn attention in research and practice for decades, human-robot collaboration (HRC) remains important to conduct complex construction tasks. Considering its complexity and uniqueness, it is still unclear how HRC process will impact construction productivity. To this end, an agent-based (AB) multi-fidelity modeling approach is introduced to simulate and evaluate how HRC influences construction productivity. A high-fidelity model is first proposed for a scenario with one robot. Then, a low-fidelity model is established to extract key parameters that capture the inner relationship among scenarios. The multi-fidelity models work together to simulate complex scenarios. Simulation and experiements show that: 1) the proposed approach is feasible and flexible for simulation of complex HRC processes, and can cover multiple collaboration and interaction modes; 2) the influence of the supplement strategy is simple when there is only one robot, where lower Check Interval (CI) and higher Supplement Limit (SL) will improve productivity. But the influence becomes much more complicated when there are more robots due to the internal competition among robots for the limited time of workers; 3) the productivity per robot improves when there are more robots and workers, even if the human-robot ratio remains the same; 4) introducing proactive interaction between robots and workers could improve productivity significantly, up to 22% in our experiments, which further depends on the supplement strategy and the human-robot ratio. Overall, this research contributes an integrated approach to simulate and evaluate HRC's impacts on productivity as well as valuable insights on how to optimize HRC for better performance.
Data-Driven Deep Learning Based Hybrid Beamforming for Aerial Massive MIMO-OFDM Systems with Implicit CSI
Feb 10, 2022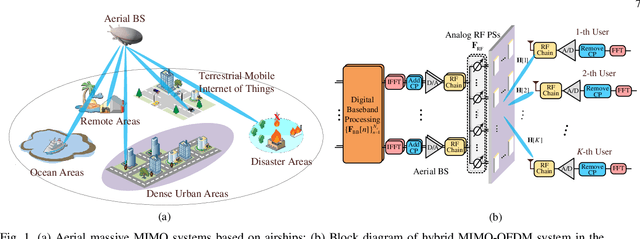
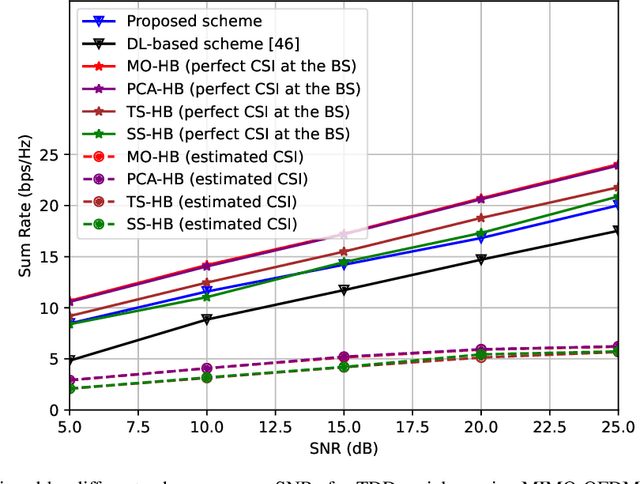
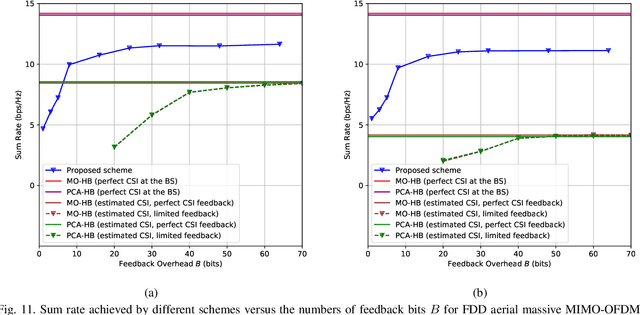
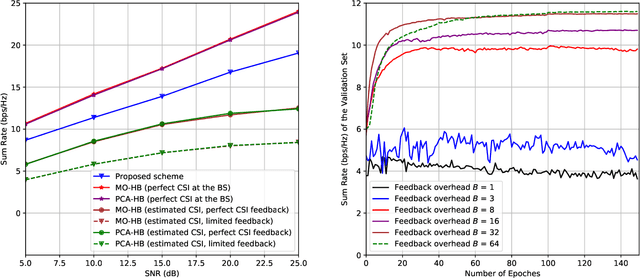
In an aerial hybrid massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) system, how to design a spectral-efficient broadband multi-user hybrid beamforming with a limited pilot and feedback overhead is challenging. To this end, by modeling the key transmission modules as an end-to-end (E2E) neural network, this paper proposes a data-driven deep learning (DL)-based unified hybrid beamforming framework for both the time division duplex (TDD) and frequency division duplex (FDD) systems with implicit channel state information (CSI). For TDD systems, the proposed DL-based approach jointly models the uplink pilot combining and downlink hybrid beamforming modules as an E2E neural network. While for FDD systems, we jointly model the downlink pilot transmission, uplink CSI feedback, and downlink hybrid beamforming modules as an E2E neural network. Different from conventional approaches separately processing different modules, the proposed solution simultaneously optimizes all modules with the sum rate as the optimization object. Therefore, by perceiving the inherent property of air-to-ground massive MIMO-OFDM channel samples, the DL-based E2E neural network can establish the mapping function from the channel to the beamformer, so that the explicit channel reconstruction can be avoided with reduced pilot and feedback overhead. Besides, practical low-resolution phase shifters (PSs) introduce the quantization constraint, leading to the intractable gradient backpropagation when training the neural network. To mitigate the performance loss caused by the phase quantization error, we adopt the transfer learning strategy to further fine-tune the E2E neural network based on a pre-trained network that assumes the ideal infinite-resolution PSs. Numerical results show that our DL-based schemes have considerable advantages over state-of-the-art schemes.