 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Task-free Continual Learning by Distributionally Robust Memory Evolution
Jul 15, 2022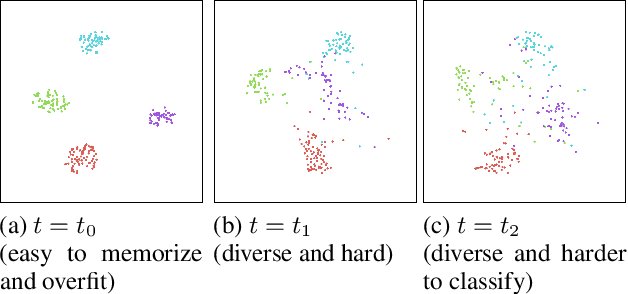
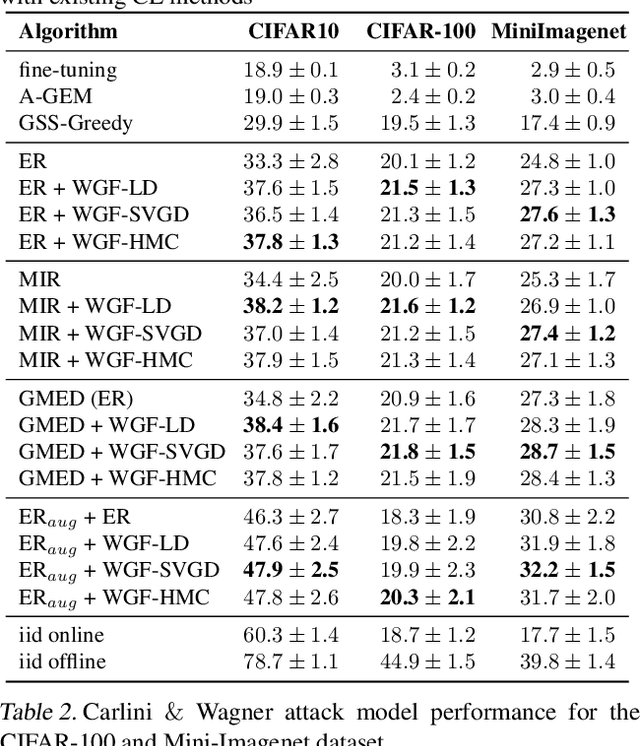
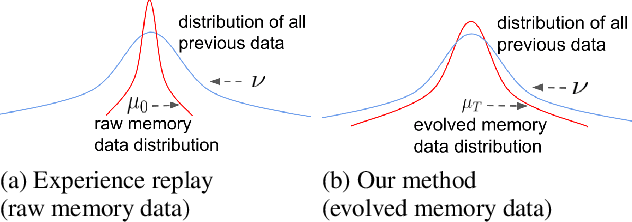
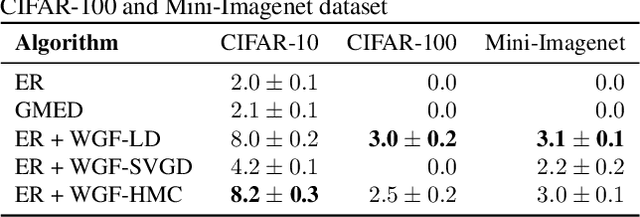
Task-free continual learning (CL) aims to learn a non-stationary data stream without explicit task definitions and not forget previous knowledge. The widely adopted memory replay approach could gradually become less effective for long data streams, as the model may memorize the stored examples and overfit the memory buffer. Second, existing methods overlook the high uncertainty in the memory data distribution since there is a big gap between the memory data distribution and the distribution of all the previous data examples. To address these problems, for the first time, we propose a principled memory evolution framework to dynamically evolve the memory data distribution by making the memory buffer gradually harder to be memorized with distributionally robust optimization (DRO). We then derive a family of methods to evolve the memory buffer data in the continuous probability measure space with Wasserstein gradient flow (WGF). The proposed DRO is w.r.t the worst-case evolved memory data distribution, thus guarantees the model performance and learns significantly more robust features than existing memory-replay-based methods. Extensive experiments on existing benchmarks demonstrate the effectiveness of the proposed methods for alleviating forgetting. As a by-product of the proposed framework, our method is more robust to adversarial examples than existing task-free CL methods.
A Bayesian Detect to Track System for Robust Visual Object Tracking and Semi-Supervised Model Learning
May 05, 2022
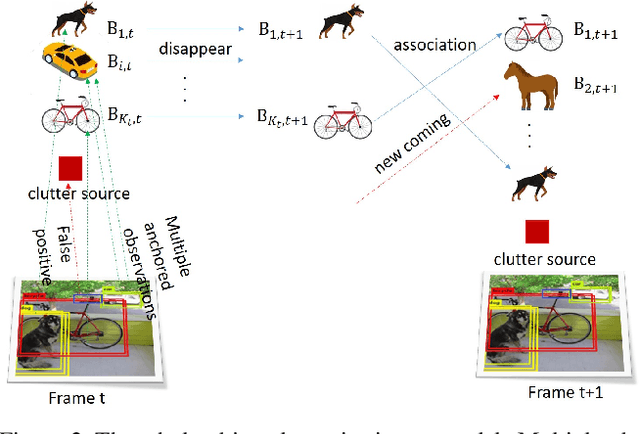
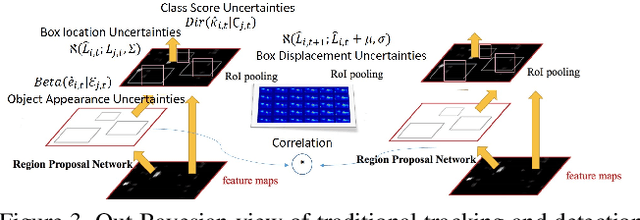
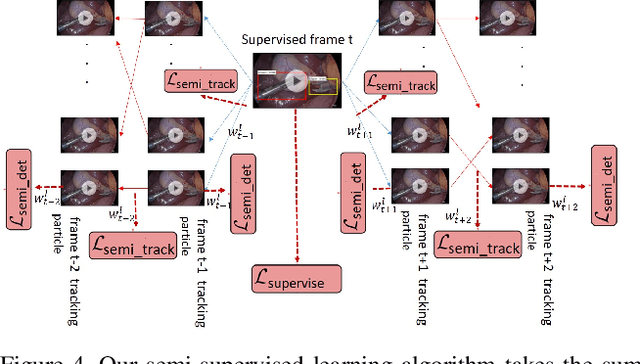
Object tracking is one of the fundamental problems in visual recognition tasks and has achieved significant improvements in recent years. The achievements often come with the price of enormous hardware consumption and expensive labor effort for consecutive labeling. A missing ingredient for robust tracking is achieving performance with minimal modification on network structure and semi-supervised learning intermittent labeled frames. In this paper, we ad-dress these problems in a Bayesian tracking and detection framework parameterized by neural network outputs. In our framework, the tracking and detection process is formulated in a probabilistic way as multi-objects dynamics and network detection uncertainties. With our formulation, we propose a particle filter-based approximate sampling algorithm for tracking object state estimation. Based on our particle filter inference algorithm, a semi-supervised learn-ing algorithm is utilized for learning tracking network on intermittent labeled frames by variational inference. In our experiments, we provide both mAP and probability-based detection measurements for comparison between our algorithm with non-Bayesian solutions. We also train a semi-supervised tracking network on M2Cai16-Tool-Locations Dataset and compare our results with supervised learning on fully labeled frames.
Learning Individual Interactions from Population Dynamics with Discrete-Event Simulation Model
May 04, 2022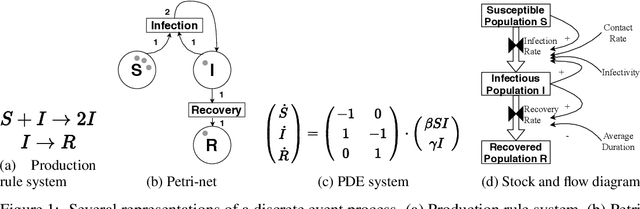
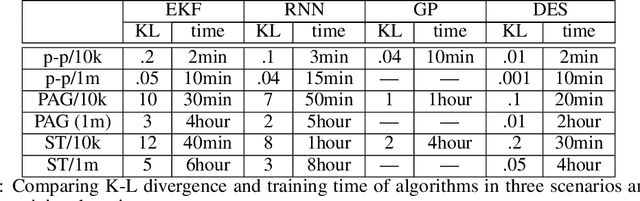
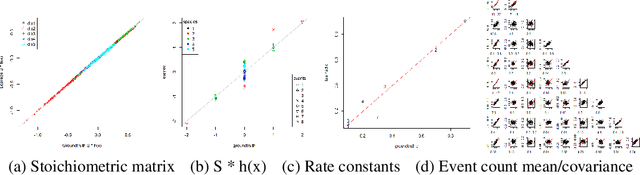
The abundance of data affords researchers to pursue more powerful computational tools to learn the dynamics of complex system, such as neural networks, engineered systems and social networks. Traditional machine learning approaches capture complex system dynamics either with dynamic Bayesian networks and state space models, which is hard to scale because it is non-trivial to prescribe the dynamics with a sparse graph or a system of differential equations; or a deep neural networks, where the distributed representation of the learned dynamics is hard to interpret. In this paper, we will explore the possibility of learning a discrete-event simulation representation of complex system dynamics assuming multivariate normal distribution of the state variables, based on the observation that many complex system dynamics can be decomposed into a sequence of local interactions, which individually change the system state only minimally but in sequence generate complex and diverse dynamics. Our results show that the algorithm can data-efficiently capture complex network dynamics in several fields with meaningful events.
Few-shot Learning as Cluster-induced Voronoi Diagrams: A Geometric Approach
Feb 05, 2022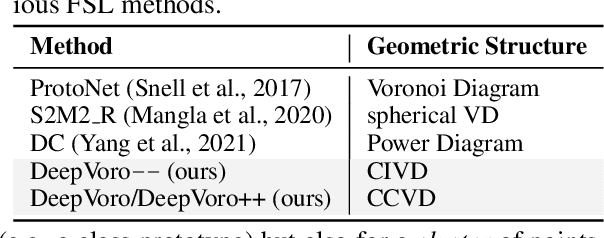
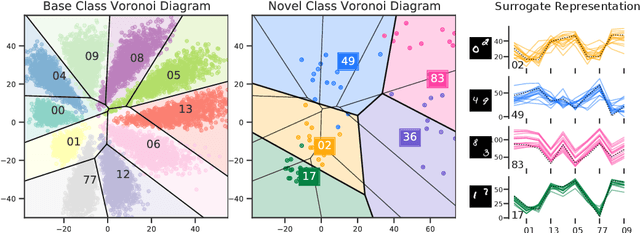
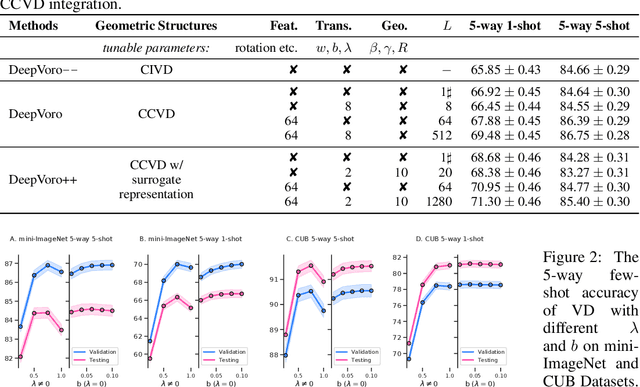
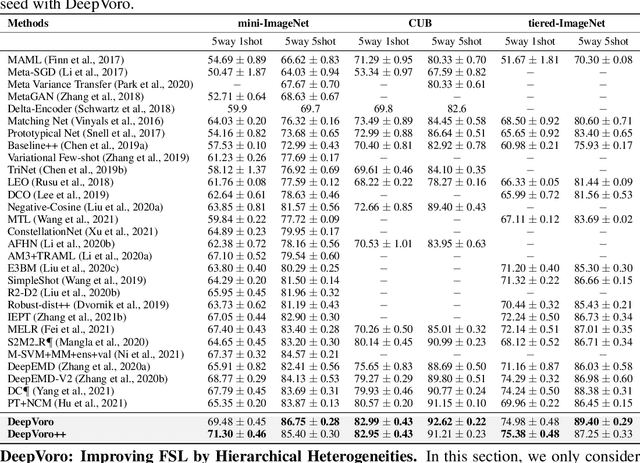
Few-shot learning (FSL) is the process of rapid generalization from abundant base samples to inadequate novel samples. Despite extensive research in recent years, FSL is still not yet able to generate satisfactory solutions for a wide range of real-world applications. To confront this challenge, we study the FSL problem from a geometric point of view in this paper. One observation is that the widely embraced ProtoNet model is essentially a Voronoi Diagram (VD) in the feature space. We retrofit it by making use of a recent advance in computational geometry called Cluster-induced Voronoi Diagram (CIVD). Starting from the simplest nearest neighbor model, CIVD gradually incorporates cluster-to-point and then cluster-to-cluster relationships for space subdivision, which is used to improve the accuracy and robustness at multiple stages of FSL. Specifically, we use CIVD (1) to integrate parametric and nonparametric few-shot classifiers; (2) to combine feature representation and surrogate representation; (3) and to leverage feature-level, transformation-level, and geometry-level heterogeneities for a better ensemble. Our CIVD-based workflow enables us to achieve new state-of-the-art results on mini-ImageNet, CUB, and tiered-ImagenNet datasets, with ${\sim}2\%{-}5\%$ improvements upon the next best. To summarize, CIVD provides a mathematically elegant and geometrically interpretable framework that compensates for extreme data insufficiency, prevents overfitting, and allows for fast geometric ensemble for thousands of individual VD. These together make FSL stronger.
FedMM: Saddle Point Optimization for Federated Adversarial Domain Adaptation
Oct 24, 2021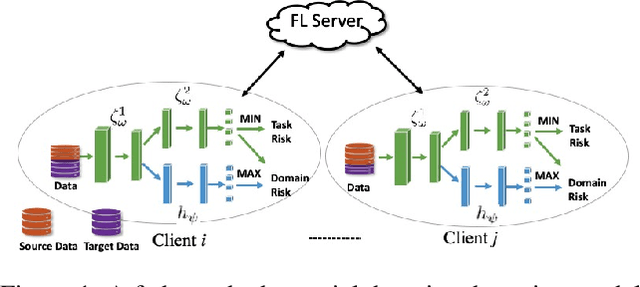
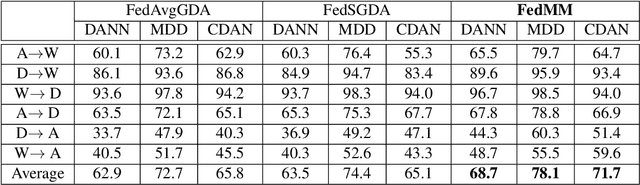
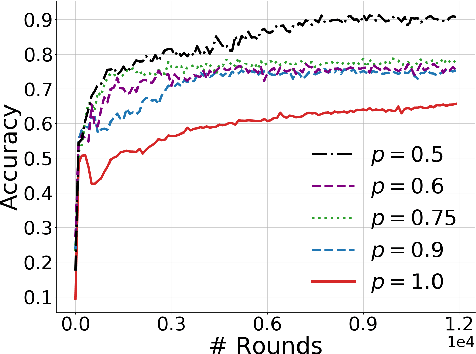
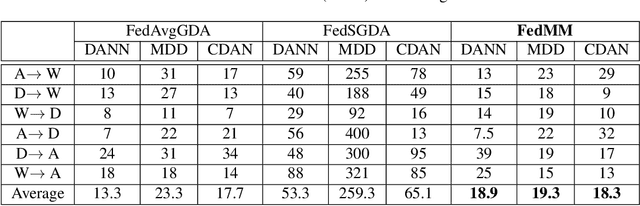
Federated adversary domain adaptation is a unique distributed minimax training task due to the prevalence of label imbalance among clients, with each client only seeing a subset of the classes of labels required to train a global model. To tackle this problem, we propose a distributed minimax optimizer referred to as FedMM, designed specifically for the federated adversary domain adaptation problem. It works well even in the extreme case where each client has different label classes and some clients only have unsupervised tasks. We prove that FedMM ensures convergence to a stationary point with domain-shifted unsupervised data. On a variety of benchmark datasets, extensive experiments show that FedMM consistently achieves either significant communication savings or significant accuracy improvements over federated optimizers based on the gradient descent ascent (GDA) algorithm. When training from scratch, for example, it outperforms other GDA based federated average methods by around $20\%$ in accuracy over the same communication rounds; and it consistently outperforms when training from pre-trained models with an accuracy improvement from $5.4\%$ to $9\%$ for different networks.
Meta Learning on a Sequence of Imbalanced Domains with Difficulty Awareness
Sep 29, 2021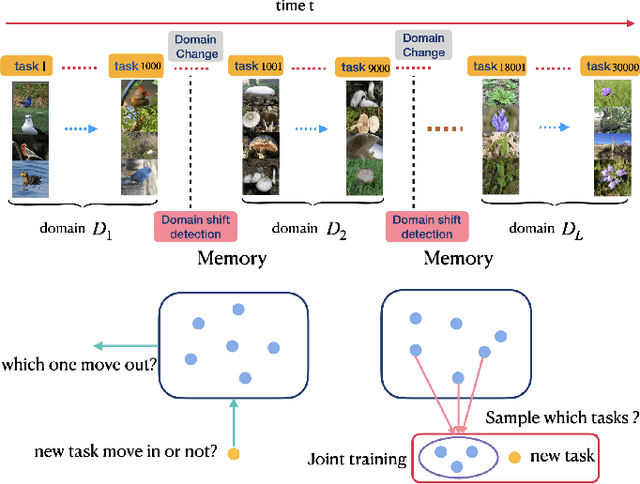
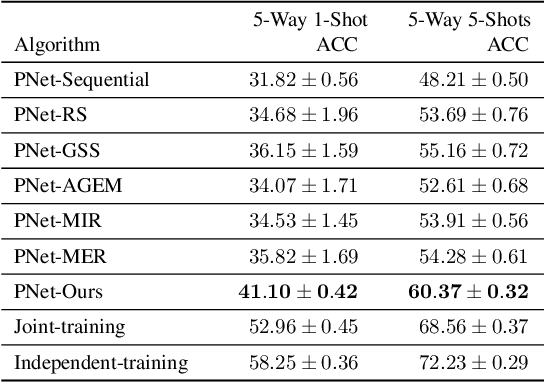
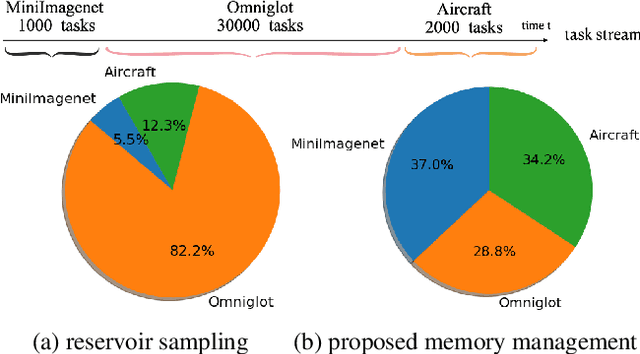
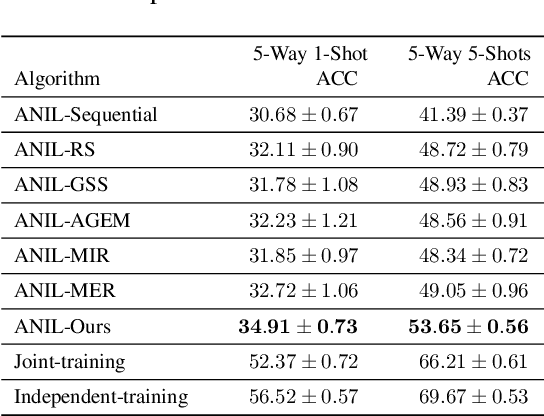
Recognizing new objects by learning from a few labeled examples in an evolving environment is crucial to obtain excellent generalization ability for real-world machine learning systems. A typical setting across current meta learning algorithms assumes a stationary task distribution during meta training. In this paper, we explore a more practical and challenging setting where task distribution changes over time with domain shift. Particularly, we consider realistic scenarios where task distribution is highly imbalanced with domain labels unavailable in nature. We propose a kernel-based method for domain change detection and a difficulty-aware memory management mechanism that jointly considers the imbalanced domain size and domain importance to learn across domains continuously. Furthermore, we introduce an efficient adaptive task sampling method during meta training, which significantly reduces task gradient variance with theoretical guarantees. Finally, we propose a challenging benchmark with imbalanced domain sequences and varied domain difficulty. We have performed extensive evaluations on the proposed benchmark, demonstrating the effectiveness of our method. We made our code publicly available.
Improving Joint Learning of Chest X-Ray and Radiology Report by Word Region Alignment
Sep 04, 2021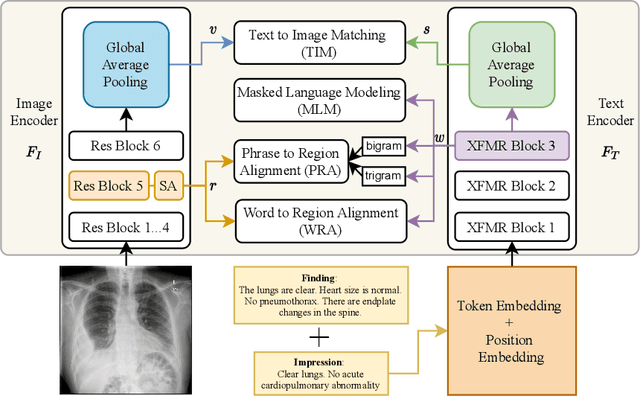
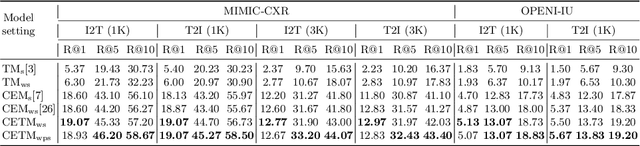
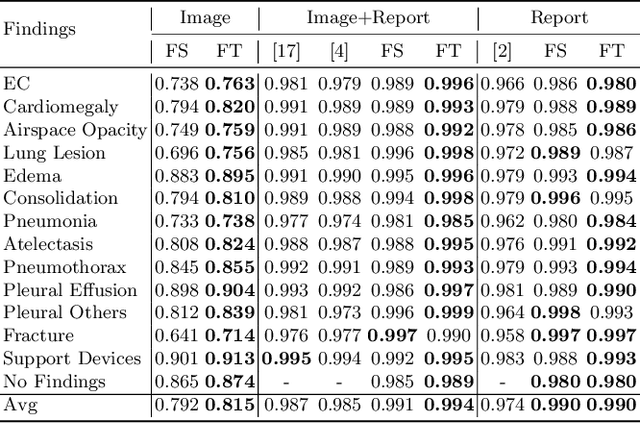
Self-supervised learning provides an opportunity to explore unlabeled chest X-rays and their associated free-text reports accumulated in clinical routine without manual supervision. This paper proposes a Joint Image Text Representation Learning Network (JoImTeRNet) for pre-training on chest X-ray images and their radiology reports. The model was pre-trained on both the global image-sentence level and the local image region-word level for visual-textual matching. Both are bidirectionally constrained on Cross-Entropy based and ranking-based Triplet Matching Losses. The region-word matching is calculated using the attention mechanism without direct supervision about their mapping. The pre-trained multi-modal representation learning paves the way for downstream tasks concerning image and/or text encoding. We demonstrate the representation learning quality by cross-modality retrievals and multi-label classifications on two datasets: OpenI-IU and MIMIC-CXR
LAViTeR: Learning Aligned Visual and Textual Representations Assisted by Image and Caption Generation
Sep 04, 2021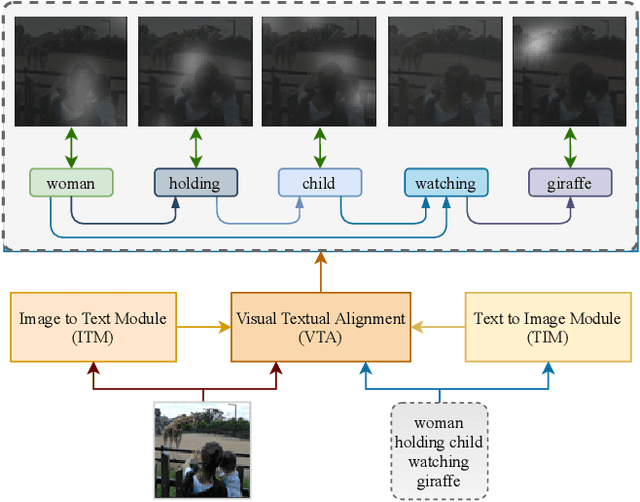
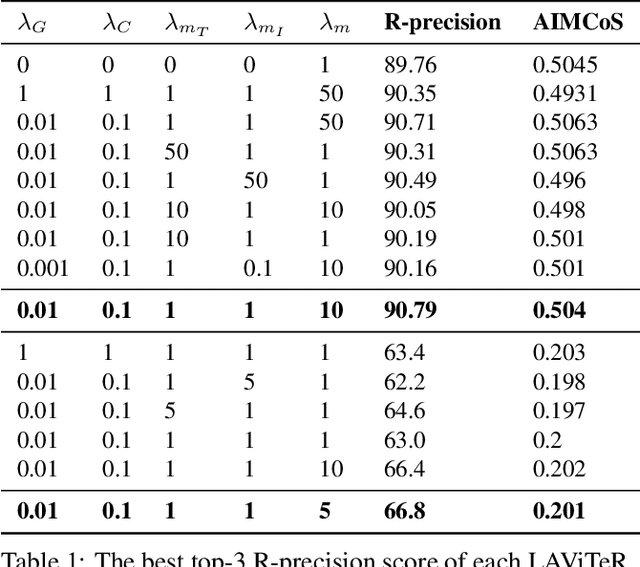
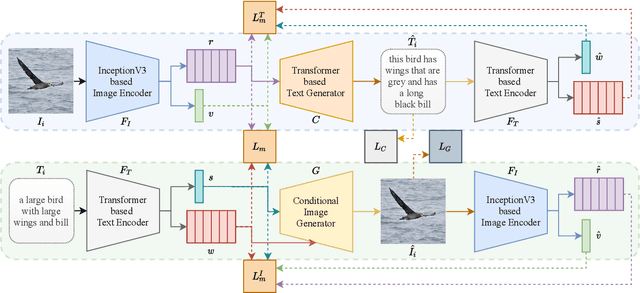
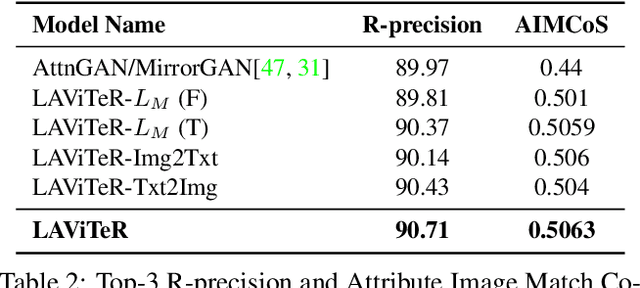
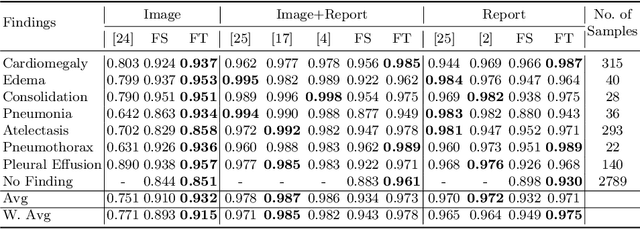
Pre-training visual and textual representations from large-scale image-text pairs is becoming a standard approach for many downstream vision-language tasks. The transformer-based models learn inter and intra-modal attention through a list of self-supervised learning tasks. This paper proposes LAViTeR, a novel architecture for visual and textual representation learning. The main module, Visual Textual Alignment (VTA) will be assisted by two auxiliary tasks, GAN-based image synthesis and Image Captioning. We also propose a new evaluation metric measuring the similarity between the learnt visual and textual embedding. The experimental results on two public datasets, CUB and MS-COCO, demonstrate superior visual and textual representation alignment in the joint feature embedding space
An End-to-End learnable Flow Regularized Model for Brain Tumor Segmentation
Sep 01, 2021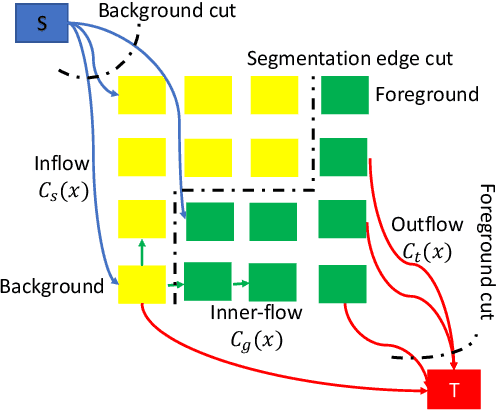
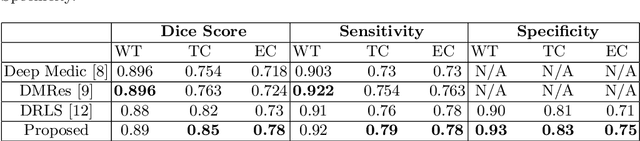
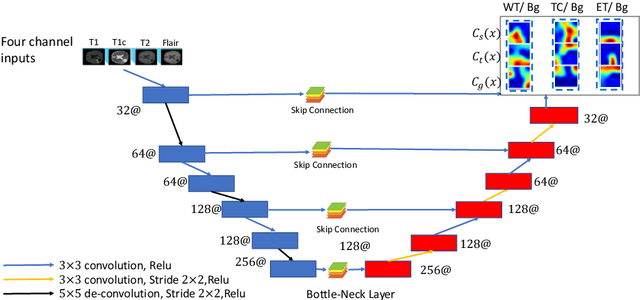
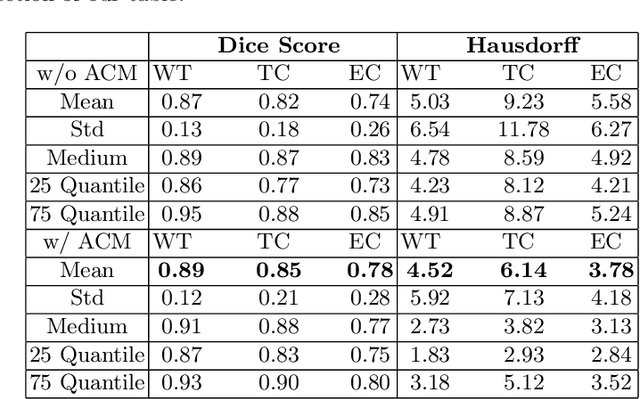
Many segmentation tasks for biomedical images can be modeled as the minimization of an energy function and solved by a class of max-flow and min-cut optimization algorithms. However, the segmentation accuracy is sensitive to the contrasting of semantic features of different segmenting objects, as the traditional energy function usually uses hand-crafted features in their energy functions. To address these limitations, we propose to incorporate end-to-end trainable neural network features into the energy functions. Our deep neural network features are extracted from the down-sampling and up-sampling layers with skip-connections of a U-net. In the inference stage, the learned features are fed into the energy functions. And the segmentations are solved in a primal-dual form by ADMM solvers. In the training stage, we train our neural networks by optimizing the energy function in the primal form with regularizations on the min-cut and flow-conservation functions, which are derived from the optimal conditions in the dual form. We evaluate our methods, both qualitatively and quantitatively, in a brain tumor segmentation task. As the energy minimization model achieves a balance on sensitivity and smooth boundaries, we would show how our segmentation contours evolve actively through iterations as ensemble references for doctor diagnosis.
Improving Uncertainty Calibration of Deep Neural Networks via Truth Discovery and Geometric Optimization
Jun 25, 2021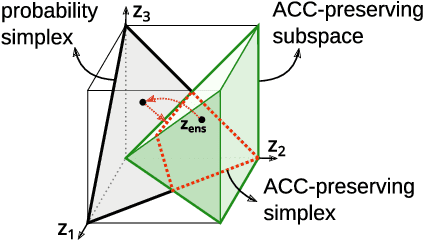
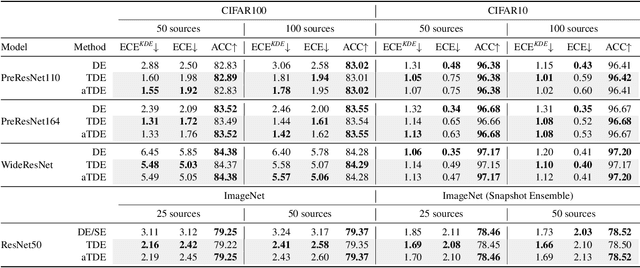
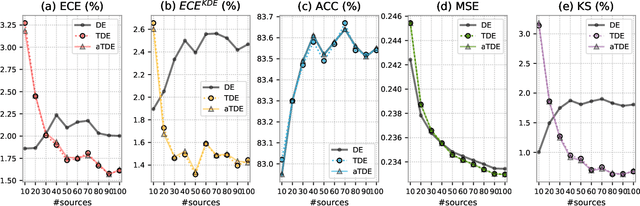
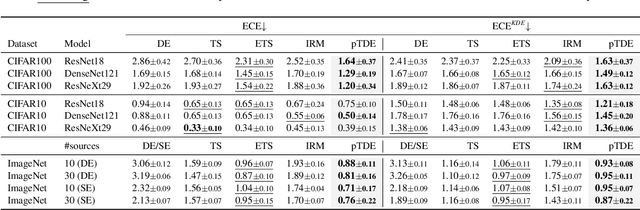
Deep Neural Networks (DNNs), despite their tremendous success in recent years, could still cast doubts on their predictions due to the intrinsic uncertainty associated with their learning process. Ensemble techniques and post-hoc calibrations are two types of approaches that have individually shown promise in improving the uncertainty calibration of DNNs. However, the synergistic effect of the two types of methods has not been well explored. In this paper, we propose a truth discovery framework to integrate ensemble-based and post-hoc calibration methods. Using the geometric variance of the ensemble candidates as a good indicator for sample uncertainty, we design an accuracy-preserving truth estimator with provably no accuracy drop. Furthermore, we show that post-hoc calibration can also be enhanced by truth discovery-regularized optimization. On large-scale datasets including CIFAR and ImageNet, our method shows consistent improvement against state-of-the-art calibration approaches on both histogram-based and kernel density-based evaluation metrics. Our codes are available at https://github.com/horsepurve/truly-uncertain.