 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeRA: Label-Efficient Geometrically Regularized Alignment
Oct 07, 2023



Pretrained unimodal encoders incorporate rich semantic information into embedding space structures. To be similarly informative, multi-modal encoders typically require massive amounts of paired data for alignment and training. We introduce a semi-supervised Geometrically Regularized Alignment (GeRA) method to align the embedding spaces of pretrained unimodal encoders in a label-efficient way. Our method leverages the manifold geometry of unpaired (unlabeled) data to improve alignment performance. To prevent distortions to local geometry during the alignment process, potentially disrupting semantic neighborhood structures and causing misalignment of unobserved pairs, we introduce a geometric loss term. This term is built upon a diffusion operator that captures the local manifold geometry of the unimodal pretrained encoders. GeRA is modality-agnostic and thus can be used to align pretrained encoders from any data modalities. We provide empirical evidence to the effectiveness of our method in the domains of speech-text and image-text alignment. Our experiments demonstrate significant improvement in alignment quality compared to a variaty of leading baselines, especially with a small amount of paired data, using our proposed geometric regularization.
An Investigation of Representation and Allocation Harms in Contrastive Learning
Oct 02, 2023



The effect of underrepresentation on the performance of minority groups is known to be a serious problem in supervised learning settings; however, it has been underexplored so far in the context of self-supervised learning (SSL). In this paper, we demonstrate that contrastive learning (CL), a popular variant of SSL, tends to collapse representations of minority groups with certain majority groups. We refer to this phenomenon as representation harm and demonstrate it on image and text datasets using the corresponding popular CL methods. Furthermore, our causal mediation analysis of allocation harm on a downstream classification task reveals that representation harm is partly responsible for it, thus emphasizing the importance of studying and mitigating representation harm. Finally, we provide a theoretical explanation for representation harm using a stochastic block model that leads to a representational neural collapse in a contrastive learning setting.
Fusing Models with Complementary Expertise
Oct 02, 2023Training AI models that generalize across tasks and domains has long been among the open problems driving AI research. The emergence of Foundation Models made it easier to obtain expert models for a given task, but the heterogeneity of data that may be encountered at test time often means that any single expert is insufficient. We consider the Fusion of Experts (FoE) problem of fusing outputs of expert models with complementary knowledge of the data distribution and formulate it as an instance of supervised learning. Our method is applicable to both discriminative and generative tasks and leads to significant performance improvements in image and text classification, text summarization, multiple-choice QA, and automatic evaluation of generated text. We also extend our method to the "frugal" setting where it is desired to reduce the number of expert model evaluations at test time.
Large Language Model Routing with Benchmark Datasets
Sep 27, 2023



There is a rapidly growing number of open-source Large Language Models (LLMs) and benchmark datasets to compare them. While some models dominate these benchmarks, no single model typically achieves the best accuracy in all tasks and use cases. In this work, we address the challenge of selecting the best LLM out of a collection of models for new tasks. We propose a new formulation for the problem, in which benchmark datasets are repurposed to learn a "router" model for this LLM selection, and we show that this problem can be reduced to a collection of binary classification tasks. We demonstrate the utility and limitations of learning model routers from various benchmark datasets, where we consistently improve performance upon using any single model for all tasks.
Fairness Evaluation in Text Classification: Machine Learning Practitioner Perspectives of Individual and Group Fairness
Mar 01, 2023Mitigating algorithmic bias is a critical task in the development and deployment of machine learning models. While several toolkits exist to aid machine learning practitioners in addressing fairness issues, little is known about the strategies practitioners employ to evaluate model fairness and what factors influence their assessment, particularly in the context of text classification. Two common approaches of evaluating the fairness of a model are group fairness and individual fairness. We run a study with Machine Learning practitioners (n=24) to understand the strategies used to evaluate models. Metrics presented to practitioners (group vs. individual fairness) impact which models they consider fair. Participants focused on risks associated with underpredicting/overpredicting and model sensitivity relative to identity token manipulations. We discover fairness assessment strategies involving personal experiences or how users form groups of identity tokens to test model fairness. We provide recommendations for interactive tools for evaluating fairness in text classification.
Simple Disentanglement of Style and Content in Visual Representations
Feb 20, 2023



Learning visual representations with interpretable features, i.e., disentangled representations, remains a challenging problem. Existing methods demonstrate some success but are hard to apply to large-scale vision datasets like ImageNet. In this work, we propose a simple post-processing framework to disentangle content and style in learned representations from pre-trained vision models. We model the pre-trained features probabilistically as linearly entangled combinations of the latent content and style factors and develop a simple disentanglement algorithm based on the probabilistic model. We show that the method provably disentangles content and style features and verify its efficacy empirically. Our post-processed features yield significant domain generalization performance improvements when the distribution shift occurs due to style changes or style-related spurious correlations.
Calibrated Data-Dependent Constraints with Exact Satisfaction Guarantees
Jan 15, 2023



We consider the task of training machine learning models with data-dependent constraints. Such constraints often arise as empirical versions of expected value constraints that enforce fairness or stability goals. We reformulate data-dependent constraints so that they are calibrated: enforcing the reformulated constraints guarantees that their expected value counterparts are satisfied with a user-prescribed probability. The resulting optimization problem is amendable to standard stochastic optimization algorithms, and we demonstrate the efficacy of our method on a fairness-sensitive classification task where we wish to guarantee the classifier's fairness (at test time).
Sampling with Mollified Interaction Energy Descent
Oct 24, 2022Sampling from a target measure whose density is only known up to a normalization constant is a fundamental problem in computational statistics and machine learning. In this paper, we present a new optimization-based method for sampling called mollified interaction energy descent (MIED). MIED minimizes a new class of energies on probability measures called mollified interaction energies (MIEs). These energies rely on mollifier functions -- smooth approximations of the Dirac delta originated from PDE theory. We show that as the mollifier approaches the Dirac delta, the MIE converges to the chi-square divergence with respect to the target measure and the gradient flow of the MIE agrees with that of the chi-square divergence. Optimizing this energy with proper discretization yields a practical first-order particle-based algorithm for sampling in both unconstrained and constrained domains. We show experimentally that for unconstrained sampling problems our algorithm performs on par with existing particle-based algorithms like SVGD, while for constrained sampling problems our method readily incorporates constrained optimization techniques to handle more flexible constraints with strong performance compared to alternatives.
Outlier-Robust Group Inference via Gradient Space Clustering
Oct 13, 2022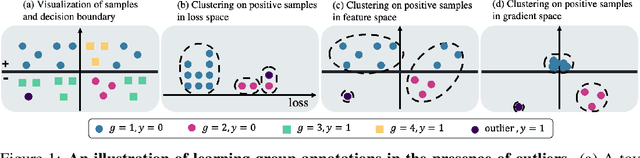
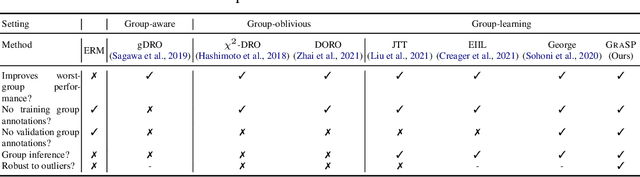

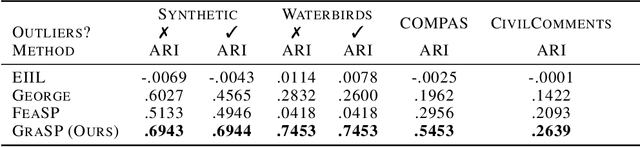
Traditional machine learning models focus on achieving good performance on the overall training distribution, but they often underperform on minority groups. Existing methods can improve the worst-group performance, but they can have several limitations: (i) they require group annotations, which are often expensive and sometimes infeasible to obtain, and/or (ii) they are sensitive to outliers. Most related works fail to solve these two issues simultaneously as they focus on conflicting perspectives of minority groups and outliers. We address the problem of learning group annotations in the presence of outliers by clustering the data in the space of gradients of the model parameters. We show that data in the gradient space has a simpler structure while preserving information about minority groups and outliers, making it suitable for standard clustering methods like DBSCAN. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art both in terms of group identification and downstream worst-group performance.
How does overparametrization affect performance on minority groups?
Jun 07, 2022
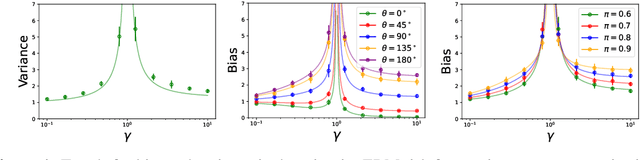
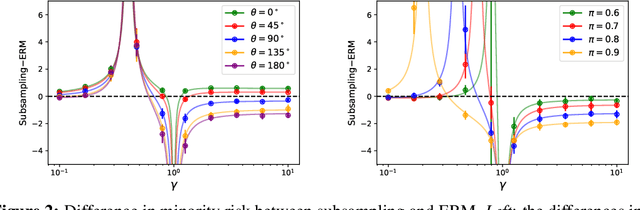
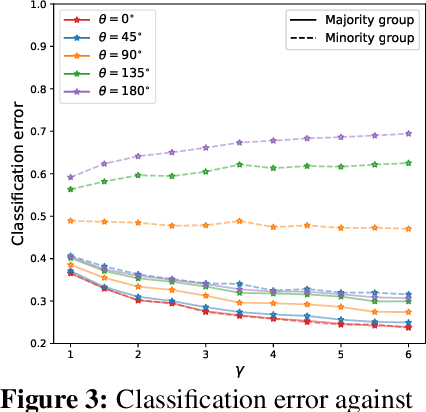
The benefits of overparameterization for the overall performance of modern machine learning (ML) models are well known. However, the effect of overparameterization at a more granular level of data subgroups is less understood. Recent empirical studies demonstrate encouraging results: (i) when groups are not known, overparameterized models trained with empirical risk minimization (ERM) perform better on minority groups; (ii) when groups are known, ERM on data subsampled to equalize group sizes yields state-of-the-art worst-group-accuracy in the overparameterized regime. In this paper, we complement these empirical studies with a theoretical investigation of the risk of overparameterized random feature models on minority groups. In a setting in which the regression functions for the majority and minority groups are different, we show that overparameterization always improves minority group performance.